

ceph学习二之基本操作
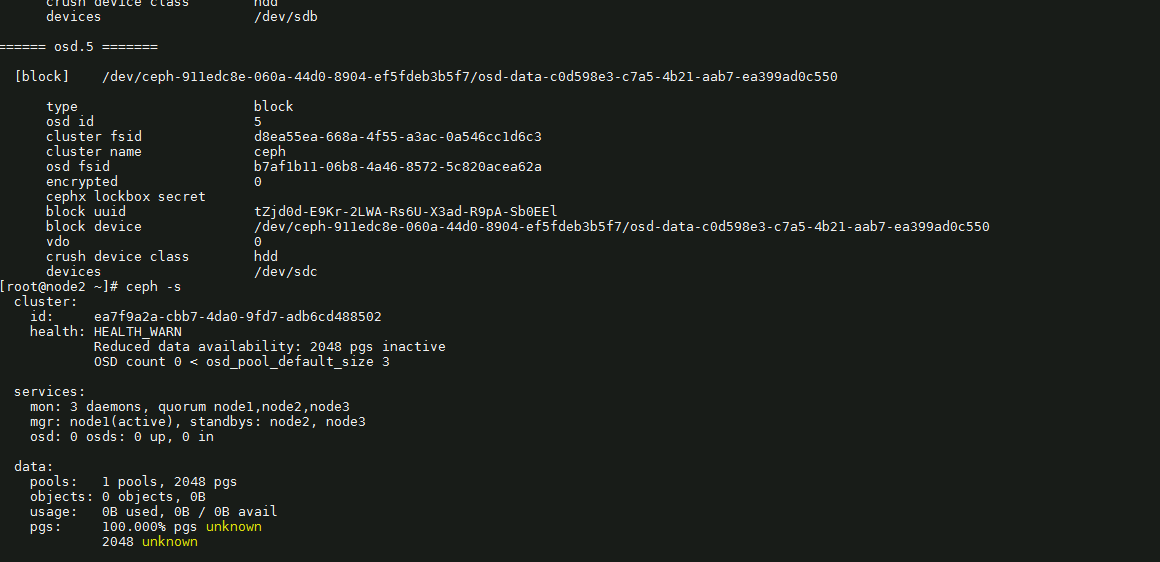
ceph-volume lvm list
通过clusterid 和cluster的fsid可以知道他不属于这个集群,这个盘是不干净的
查看rbd image在哪里节点上:
rbd status ssdpool/kubernetes-dynamic-pvc-bb02f1ff-a832-4bf0-be28-8cae66c0cf76
Watchers:
watcher=10.210.141.95:0/24607170 client.54111 cookie=18446462598732840975
vgdisplay命令用于显示LVM卷组的信息;
ceph osd lspools # 来查看当前存储的存储池
ceph pg stat # pg的状态
ceph osd tree # osd的分布
ceph osd pool create {pool-name} {pg-num} {pgp-num} # 创建存储池
ceph df # 查看存储池统计信息
ceph osd df # 查看osd使用情况
rados lspools #查看有哪些pool
rbd ls poolname #查看pool里有哪些image
rbd snap create --snap mysnap ssdpool/image_name 备份
rbd snap ls ssdpool/image_name查看
ceph osd pool set {pool-name} {key} {value} # 调整存储池的选项值
有关image创建和查看的操作:
rbd create pool/image1 --size 1024 --image-format 2 # 在pool存储池中创建1GB大小的image
rbd ls pool-name # 查看pool-name存储池中的image
rbd info pool-name/image1 # 查看image1的详细信息
rbd rm pool-name/image1 # 删除image1
查看pool中对象
rados -p ${poolname} ls
删除OSD:
systemctl list-units|grep ceph # 查看服务
systemctl stop ceph-osd@5.service
ceph osd out 5
ceph osd crush remove osd.5
ceph auth del osd.5
ceph osd rm 5
# 批量删除脚本
loop=0; while [ "$loop" -lt 7 ]; do
systemctl stop ceph-osd@${loop}.service
ceph osd out ${loop}
ceph osd crush remove osd.${loop}
ceph auth del osd.${loop}
ceph osd rm ${loop}
echo "finsh $loop "
loop=$((loop + 1))
done
想看刚才删除的OSD对应的哪个盘符,并且格式化磁盘:
lvs

记录下VGID a12开头
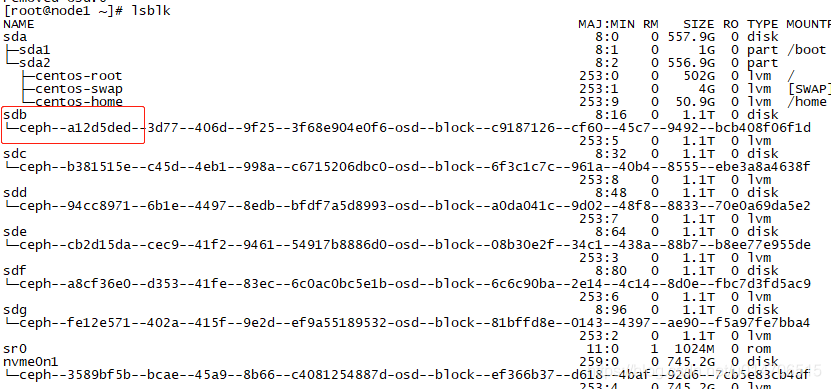
可以看到对应的就是sdb
然后用vgremove 删掉vg就可以完成硬盘的格式化
创建完pool,记得enable rbd
|
ceph osd pool application enable images rbd ceph osd pool application enable compute rbd ceph osd pool application enable volumes rbd
|
导出编辑测试crush map
|
ceph osd getcrushmap -o /home/ttt.x # 导出二进制crushmap crushtool -d ttt.t -o ttt.txt # 反编译crushmap为文本 crushtool -c ttt.txt -o ttt.x # 编译crushmap crushtool -i ttt.x --test --min-x 0 --max-x 9 --num-rep 3 --ruleset 0 --show_mappings # 测试 crushtool -i ttt.x --test --min-x 0 --max-x 100000 --num-rep 3 --ruleset 0 --show_utilization # 测试分布 ceph osd setcrushmap -i ttt.x # 注入集群crushmap,使之生效 |
删除pool
首先打开ceph.conf中:
[mon]
mon allow pool delete = true
执行
ceph osd pool delete test test --yes-i-really-really-mean-it
向ceph中放入数据
|
echo {Test-data} > testfile.txt rados put test-object-1 testfile.txt --pool=images ceph osd map images test-object-1 |
移除缓冲池
|
ceph osd tier remove-overlay images ceph osd tier remove images images-cache |
查看object位置
|
ceph osd map images test-object-1 |
尝试刷新缓存区到数据区
|
rados -p images-cache cache-try-flush-evict-all |
强制刷新缓存区到数据区
|
rados -p images-cache cache-flush-evict-all |
批量插入数据脚本
|
touch /home/file dd if=/dev/zero of=/home/file bs=1M count=128
loop=0; while [ "$loop" -lt 40 ]; do rados put objectx2-${loop} /home/file --pool=images loop=$((loop + 1)) echo "finsh $loop " done |
新加入一个OSD
|
# 这里以sdb举例 ceph-volume lvm zap /dev/sdb ceph-volume lvm create --data /dev/sdb ceph-volume lvm activate --all # 新加入的osd一般不在crushmap中,请按照实际情况重新编辑导入crushmap,使之生效 |
参考:https://blog.csdn.net/u014706515/article/details/100586141

