


RemoteDisconnected: Remote end closed connection without response的解决方法
原文链接:
参考链接:https://blog.csdn.net/goodnameused/article/details/80246331
参考链接:https://blog.csdn.net/u010883226/article/details/80183366
这个问题说的就是我们写的网络爬虫爬取第三方的时候,第三方不愿意被爬从而拒绝链接,解决这个的思路大概就是伪装浏览器来处理,单也不可避免还是会被拒,暂时只能勤换header的内容
在写爬虫的时候遇到了问题,网站是asp.net写的
1 requests.exceptions.ConnectionError: 2 ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',))
于是就抓包分析,发现只要加了’Accept-Language’就好了。。。
1 'Accept-Language':'zh-CN,zh;q=0.9'
方法二:
根据各位大神的解释是UA(User-Agent)出现问题了,
1 headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'} 2 req = request.Request(url, headers=headers)
1 html = request.urlopen(req).read()
需要模拟浏览器来解决。但是有好多网上的UA都不能用,应该这种UA爬取东西过多,直接被网站记录了黑名单,需要更改为自己的UA。一般在浏览器的地址栏输入: about:version
获得本机的UA,然后或者得到不同人的UA,使用random来规避一些网站的反爬措施,
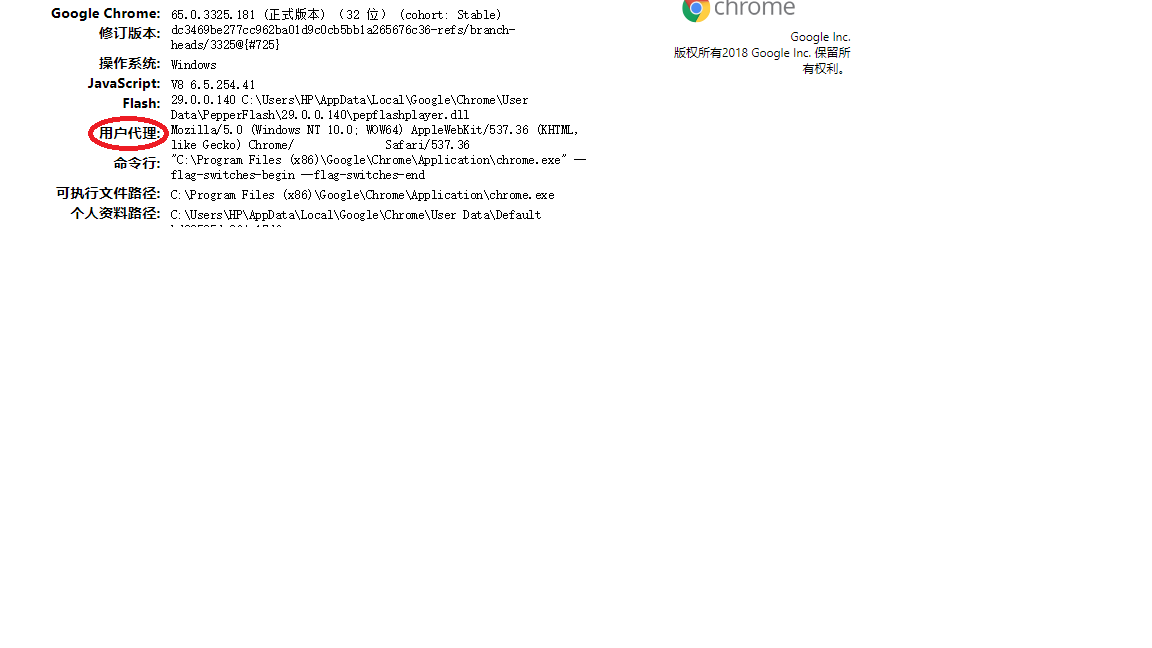
如何使用涉及代码:第16、17、22、35行
1 import os 2 import urllib.request 3 import json 4 from urllib import request 5 6 import pytest 7 import requests 8 from bs4 import BeautifulSoup 9 import ssl 10 ssl._create_default_https_context = ssl._create_unverified_context 11 #写入User-Agent,采用字典形式 12 # head={} 13 # head['User-Agent']='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' 14 15 16 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 17 'Chrome/51.0.2704.63 Safari/537.36', 'Accept-Language':'zh-CN,zh;q=0.9'} 18 #根据学名搜索页面 19 def apiSerch(xueming): 20 apiUrl = "https://api.ebird.org/v2/ref/taxon/find?locale=zh_CN&cat=species&limit=150&key=jfekjedvescr&q="+xueming 21 # 调用api 匹配学名 22 resp = requests.get(apiUrl, headers=headers) 23 print(resp.text) 24 25 # resp = '[{"code": "apubrf1", "name": "Apurimac Brushfinch - Atlapetes forbesi"}]' 26 data = json.loads(resp.text) 27 # print(data2['code'],data2['name']) 28 #如果未查询到则返回空串 29 if (len(data) == 0): 30 return '' 31 print(data[0]['code']) 32 # 根据学名的code值搜索 获取目标页面 33 searchUrl = "https://ebird.org/species/" 34 # 创建headers伪装浏览器 35 shtml = requests.get(searchUrl + data[0]['code'] + "/", headers=headers) 36 #print(shtml.text) 37 return shtml
