linux内存映射
内存管理分为对连续物理内存区管理和非连续内存区管理,本文主要讲解连续的物理内存区管理的技术中所涉及到的内核线性地址空间映射的相关知识。涉及到的东西有:页框,管理区(高端内存,低端内存),高端内存映射等,这些知识是掌握伙伴系统算法和slab分配器的基础。
一、页框
页框为物理内存分配的基本单元,现代32位计算机一般设置为4KB(见上文计算机内存寻址)。内核必须记录每个页框的当前状态,例如:页框属于哪个经常的页,哪些页框抱哈的是内核代码或内核数据等,由此linux定义了一个页框的描述符:page。linux用page来保存页框的状态信息,所有的page都存放在mem_map数组中,以便管理内存。
二、管理区
很显然,如果计算机对内存的使用没有区别,那么直接使用页框管理内存是最为方便的。但是,由于计算机体系结构的的硬件限制:
(1)ISA总线的直接内存存取(DMA)处理器只能对随机存储器(RAM)的前16MB寻址。
(2)具有大容量的RAM的32位计算机中,CPU不能直接访问所有的物理内存!
所以,由于上述的原因,Linux将物理内存划分为3个管理区:
(1)ZONE_DMA:包含低于16M的内存页框,只有它能够作用于DMA;
(2)ZONE_NORMAL:包含高于16M且低于896M的内存页框;
(3)ZONE_HIGHMEM:包含从896M开始高于896M的内存页框。
ZONE_DMA和ZONE_NORMAL我们一般称之为低端内存(896MB),ZONE_HIGHMEM称之为高端内存。高、低端内存的分类主要在于区分物理内存地址是否可以直接映射到内核线性地址空间中。问题来了,高、低端内存和内核的线性空间的映射是什么样的呢?
在32位系统中,线性地址空间是4G,其中规定3~4G的范围是内核空间(1G),0~3G是用户空间(3G)。如果把这1G的内核线性地址空间全部拿来直接一一映射物理内存的话,在内核态的所有进程(线程)能使用的物理内存总共最多只有1G,很显然,如果你有4G内存,3G都不能用来做内核空间,太浪费了!
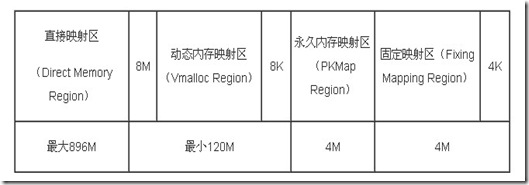
为了能使在内核态的所有进程能使用更多的物理内存,linux采取了一种变通的形式:它将1G内核线性地址空间分为2部分,第一部分为1G的前896M,这部分内核线性空间与物理内存的0~896M一一映射,第二部分为1G的后128M的线性空间,拿来动态映射剩下的所有物理内存。
看到这里应该几乎懂了为什么要有高端内存和低端内存的区分了!内核线性地址空间的前896M映射的就是我们的低端页框内存(ZONE_DMA和ZONG_NORMAL),而且是直接映射;内核线性地址空间的后128M映射的是我们的高端页框内存(ZONG_HIGHMEME)。
上述的三个管理区,每个管理区都有自己的管理区描述符,管理区描述符的地址存放在zone_table数组中。内核调用一个内存分配函数时,必须指明请求页框所在的管理区。
为满足内存分配请求,内存管理区使用两种方式来保证:
(1)当空闲内存不足时,发出请求的内核控制路径阻塞,知道有内存释放,才分配。
(2)如果内核控制路径不能被阻塞(原子内存分配请求),就从页框池中分配内存。
页框池为内存保留的内存,由ZONE_DMA和ZONE_NORMAL来共同分配,分配的页框池大小为:sqrt(16*直接映射内存) KB
三、高端内存页框的内核映射
在前面有提到,内核线性地址空间的最后128M用来映射高端内存页框,其方式有三种:永久内核映射,临时内核映射,非连续内存分配。由于本文只讲连续内存分配,最后一种映射方式就在下一篇blog中讲。
1、永久内核映射
永久内核映射允许内核建立高端页框到内核地址空间的长期映射。他使用主内核页表中一个专门的页表,其页表地址存放在pkmap_page_table中,页表包含512项或1024项,因此,内核一次最多访问2M或4M的高端内存(地址范围是 4G-8M 到 4G-4M 之间,这个地址空间起叫“内核永久映射空间”或者“永久内核映射空间”)。
永久内核映射通过kmap()函数建立,代码:


1 void *kmap(struct page* page)
2 {
3 if(!PageHighMem(page))//判断是否是高端内存
4 return page_address(page);
5 return kmap_high(page);
6 }
7
8 void *kmap_high(struct page *page)
9 {
10 unsigned long vaddr;
11 spin_lock(&kmap_lock);//自旋锁
12 vaddr = (unsigned long) page_address(page);
13 if(vaddr)
14 vaddr = map_new_virtual(page);
15 pkmap_count[(vaddr - PKMAP_BASE) >> PAGE_SHIFT]++;//pkamp_count数组包含LAST_PKAMP个计数器
16 spin_unlock(&kmap_lock);
17 return (void *) vaddr;
18 }
对于不使用的的 page,及应该时从这个空间释放掉(也就是解除映射关系),通过 kunmap() ,可以把一个 page 对应的线性地址从这个空间释放出来。
2、临时内核映射
临时内核映射可用在中断处理程序和可延迟函数的内部,它从不阻塞当前进程。
内核在 FIXADDR_START 到 FIXADDR_TOP 之间保留了一些线性空间用于特殊需求。这个空间称为“固定映射空间”,在这个空间中,有一部分用于高端内存的临时映射。这块空间具有如下特点:
(1) 每个 CPU 占用一块空间;
(2) 在每个 CPU 占用的那块空间中,又分为多个小空间,每个小空间大小是 1 个 page,每个小空间用于一个目的,这些目的定义在 kmap_types.h 中的km_type 中。
当要进行一次临时映射的时候,需要指定映射的目的,根据映射目的,可以找到对应的小空间,然后把这个空间的地址作为映射地址。这意味着一次临时映射会导致以前的映射被覆盖。
通过 kmap_atomic() 可实现临时映射。代码
1 view plaincopy to clipboardprint?用数学公式来避免混乱,他空间有限且虚拟地址固定,这意味着他映射的内存空间不能被 2 长时间占用,而不被unmap,在效率上比kmap提升不少,然而他和kmap不是用于统一 3 场合的, 4 **/ 5 void *kmap_atomic(struct page *page, enum km_type type) 6 { 7 return kmap_atomic_prot(page, type, kmap_prot); 8 } 9 用数学公式来避免混乱,他空间有限且虚拟地址固定,这意味着他映射的内存空间不能被 10 长时间占用,而不被unmap,在效率上比kmap提升不少,然而他和kmap不是用于统一 11 场合的, 12 **/ 13 void *kmap_atomic(struct page *page, enum km_type type) 14 { 15 return kmap_atomic_prot(page, type, kmap_prot); 16 }view plaincopy to clipboardprint?/* 17 * kmap_atomic/kunmap_atomic is significantly faster than kmap/kunmap because 18 * no global lock is needed and because the kmap code must perform a global TLB 19 * invalidation when the kmap pool wraps. 20 * 21 * However when holding an atomic kmap it is not legal to sleep, so atomic 22 * kmaps are appropriate for short, tight code paths only. 23 */ 24 void *kmap_atomic_prot(struct page *page, enum km_type type, pgprot_t prot) 25 { 26 enum fixed_addresses idx; 27 unsigned long vaddr; 28 29 /* even !CONFIG_PREEMPT needs this, for in_atomic in do_page_fault */ 30 /**原子映射是基于每个cpu的,因此在当前cpu上应用抢占,直到unmap的时候才 31 开启,这样不会导致原子映射的重入了, 32 */ 33 pagefault_disable(); 34 35 if (!PageHighMem(page)) 36 return page_address(page); 37 38 /* 递增type,保证下面公式起作用 */ 39 debug_kmap_atomic(type); 40 /* 41 kernel可以在多个cpu上同时运行不同的task,然而他们共同使用一个内存地址空间, 42 也就是说,内存空间对于多个cpu看到的是同一个,该函数使用的是地址空间中顶部的 43 一小段地址空间,也就是临时映射区,内核逻辑将这一小段地址空间分成若干各节 44 每一节的大小是一个页面的大小,可以映射一个页面,根据公用地址空间的原理 45 所有的cpu共同使用这些节,因此如何能保证N个cpu调用此函数不会将page映射到 一个地址呢,这就是这个数学公式所起到的作用 46 */ 47 idx = type + KM_TYPE_NR*smp_processor_id(); 48 vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx); 49 /*这里为什么是减法 50 越靠前的枚举项对应的线性地址越靠后*/ 51 BUG_ON(!pte_none(*(kmap_pte-idx))); 52 /*设置pte*/ 53 set_pte(kmap_pte-idx, mk_pte(page, prot)); 54 55 return (void *)vaddr; 56 } 57 /* 58 * kmap_atomic/kunmap_atomic is significantly faster than kmap/kunmap because 59 * no global lock is needed and because the kmap code must perform a global TLB 60 * invalidation when the kmap pool wraps. 61 * 62 * However when holding an atomic kmap it is not legal to sleep, so atomic 63 * kmaps are appropriate for short, tight code paths only. 64 */ 65 void *kmap_atomic_prot(struct page *page, enum km_type type, pgprot_t prot) 66 { 67 enum fixed_addresses idx; 68 unsigned long vaddr; 69 70 /* even !CONFIG_PREEMPT needs this, for in_atomic in do_page_fault */ 71 /**原子映射是基于每个cpu的,因此在当前cpu上应用抢占,直到unmap的时候才 72 开启,这样不会导致原子映射的重入了, 73 */ 74 pagefault_disable(); 75 76 if (!PageHighMem(page)) 77 return page_address(page); 78 79 /* 递增type,保证下面公式起作用 */ 80 debug_kmap_atomic(type); 81 /* 82 kernel可以在多个cpu上同时运行不同的task,然而他们共同使用一个内存地址空间, 83 也就是说,内存空间对于多个cpu看到的是同一个,该函数使用的是地址空间中顶部的 84 一小段地址空间,也就是临时映射区,内核逻辑将这一小段地址空间分成若干各节 85 每一节的大小是一个页面的大小,可以映射一个页面,根据公用地址空间的原理 86 所有的cpu共同使用这些节,因此如何能保证N个cpu调用此函数不会将page映射到 一个地址呢,这就是这个数学公式所起到的作用 87 */ 88 idx = type + KM_TYPE_NR*smp_processor_id(); 89 vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx); 90 /*这里为什么是减法 91 越靠前的枚举项对应的线性地址越靠后*/ 92 BUG_ON(!pte_none(*(kmap_pte-idx))); 93 /*设置pte*/ 94 set_pte(kmap_pte-idx, mk_pte(page, prot)); 95 96 return (void *)vaddr; 97 }view plaincopy to clipboardprint?#define __fix_to_virt(x) (FIXADDR_TOP - ((x) << PAGE_SHIFT)) 98 #define __fix_to_virt(x) (FIXADDR_TOP - ((x) << PAGE_SHIFT))
最后,给一张页框页管理区的图,加深内核线性地址空间映射的印象:
参考:
1、深入理解Linux内核
2、Linux 内存管理 -- 高端内存的映射方式 http://blog.csdn.net/chenziwen/article/details/5932396
3、Linux内核--内核地址空间分布和进程地址空间 http://www.360doc.com/content/12/1022/13/6828497_243054228.shtml
4、linux内存管理浅析 http://hi.baidu.com/_kouu/item/4c73532902a05299b73263d0


 浙公网安备 33010602011771号
浙公网安备 33010602011771号