
中文分词算法总结
中文分词技术属于自然语言处理技术范畴,对于一句话,人可以通过自己的知识来明白哪些是词,哪些不是词,但如何让计算机也能理解?其处理过程就是分词算法。现有的分词算法可分为三大类:基于词典的分词方法、基于统计的方法、基于规则的方法。
1 基于词典的分词方法(字符串匹配,机械分词方法)
定义:按照一定策略将待分析的汉字串与一个“大机器词典”中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。
按照扫描方向的不同:正向匹配和逆向匹配
按照长度的不同:最大匹配和最小匹配
1.1 正向最大匹配思想(MM)
- 从左向右取待切分汉语句的m个字符作为匹配字段,m为大机器词典中最长词条个数。
- 查找大机器词典并进行匹配。若匹配成功,则将这个匹配字段作为一个词切分出来。
若匹配不成功,则将这个匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配,重复以上过程,直到切分出所有词为止。
1.2 逆向最大匹配算法(RMM)
该算法是正向最大匹配的逆向思维,匹配不成功,将匹配字段的最前一个字去掉,实验表明,逆向最大匹配算法要优于正向最大匹配算法。
1.3 双向最大匹配法(Bi-directction Matching method,BM)
双向最大匹配法是将正向最大匹配法得到的分词结果和逆向最大匹配法的到的结果进行比较,从而决定正确的分词方法。据SunM.S. 和 Benjamin K.T.(1995)的研究表明,中文中90.0%左右的句子,正向最大匹配法和逆向最大匹配法完全重合且正确,只有大概9.0%的句子两种切分方法得到的结果不一样,但其中必有一个是正确的(歧义检测成功),只有不到1.0%的句子,或者正向最大匹配法和逆向最大匹配法的切分虽重合却是错的,或者正向最大匹配法和逆向最大匹配法切分不同但两个都不对(歧义检测失败)。这正是双向最大匹配法在实用中文信息处理系统中得以广泛使用的原因所在。
1.4 设立切分标志法
收集切分标志,在自动分词前处理切分标志,再用MM、RMM进行细加工。
1.5 最佳匹配(OM,分正向和逆向)
对分词词典按词频大小顺序排列,并注明长度,降低时间复杂度。
优点:易于实现
缺点:匹配速度慢。对于未登录词的补充较难实现。缺乏自学习。
2 基于统计的分词(无字典分词)
主要思想:上下文中,相邻的字同时出现的次数越多,就越可能构成一个词。因此字与字相邻出现的概率或频率能较好的反映词的可信度。
主要统计模型为:N元文法模型(N-gram)、隐马尔科夫模型(Hidden Markov Model, HMM)
2.1 N-gram模型思想
模型基于这样一种假设,第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。
我们给定一个词,然后猜测下一个词是什么。当我说“艳照门”这个词时,你想到下一个词是什么呢?我想大家很有可能会想到“陈冠希”,基本上不会有人会想到“陈志杰”吧。N-gram模型的主要思想就是这样的。
对于一个句子T,我们怎么算它出现的概率呢?假设T是由词序列W1,W2,W3,…Wn组成的,那么P(T)=P(W1W2W3…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
但是这种方法存在两个致命的缺陷:一个缺陷是参数空间过大,不可能实用化;另外一个缺陷是数据稀疏严重。
为了解决这个问题,我们引入了马尔科夫假设:一个词的出现仅仅依赖于它前面出现的有限的一个或者几个词。
如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为bigram。即
P(T) = P(W1W2W3…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
≈P(W1)P(W2|W1)P(W3|W2)…P(Wn|Wn-1)
如果一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为trigram。
在实践中用的最多的就是bigram和trigram了,而且效果很不错。高于四元的用的很少,因为训练它需要更庞大的语料,而且数据稀疏严重,时间复杂度高,精度却提高的不多。
设w1,w2,w3,...,wn是长度为n的字符串,规定任意词wi 只与它的前两个相关,得到三元概率模型
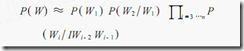
以此类推,N元模型就是假设当前词的出现概率只同它前面的N-1个词有关。
2.2 隐马尔科夫模型思想
3 基于规则的分词(基于语义)
通过模拟人对句子的理解,达到识别词的效果,基本思想是语义分析,句法分析,利用句法信息和语义信息对文本进行分词。自动推理,并完成对未登录词的补充是其优点。不成熟.
具体概念:有限状态机\语法约束矩阵\特征词库
4 基于字标注的中文分词方法
以往的分词方法,无论是基于规则的还是基于统计的,一般都依赖于一个事先编制的词表(词典)。自动分词过程就是通过词表和相关信息来做出词语切分的决策。与此相反,基于字标注的分词方法实际上是构词方法。即把分词过程视为字在字串中的标注问题。由于每个字在构造一个特定的词语时都占据着一个确定的构词位置(即词位),假如规定每个字最多只有四个构词位置:即B(词首),M (词中),E(词尾)和S(单独成词),那么下面句子(甲)的分词结果就可以直接表示成如(乙)所示的逐字标注形式:
(甲)分词结果:/上海/计划/N/本/世纪/末/实现/人均/国内/生产/总值/五千美元/
(乙)字标注形式:上/B海/E计/B划/E N/S 本/s世/B 纪/E 末/S 实/B 现/E 人/B 均/E 国/B 内/E生/B产/E总/B值/E 五/B千/M 美/M 元/E 。/S
首先需要说明,这里说到的“字”不只限于汉字。考虑到中文真实文本中不可避免地会包含一定数量的非汉字字符,本文所说的“字”,也包括外文字母、阿拉伯数字和标点符号等字符。所有这些字符都是构词的基本单元。当然,汉字依然是这个单元集合中数量最多的一类字符。
把分词过程视为字的标注问题的一个重要优势在于,它能够平衡地看待词表词和未登录词的识别问题。在这种分词技术中,文本中的词表词和未登录词都是用统一的字标注过程来实现的。在学习架构上,既可以不必专门强调词表词信息,也不用专门设计特定的未登录词(如人名、地名、机构名)识别模块。这使得分词系统的设计大大简化。在字标注过程中,所有的字根据预定义的特征进行词位特性的学习,获得一个概率模型。然后,在待分字串上,根据字与字之间的结合紧密程度,得到一个词位的标注结果。最后,根据词位定义直接获得最终的分词结果。总而言之,在这样一个分词过程中,分词成为字重组的简单过程。然而这一简单处理带来的分词结果却是令人满意的。
5 分词中的难题
有了成熟的分词算法,是否就能容易的解决中文分词的问题呢?事实远非如此。中文是一种十分复杂的语言,让计算机理解中文语言更是困难。在中文分词过程中,有两大难题一直没有完全突破。
1、歧义识别
歧义是指同样的一句话,可能有两种或者更多的切分方法。例如:表面的,因为“表面”和“面的”都是词,那么这个短语就可以分成“表面 的”和“表 面的”。这种称为交叉歧义。像这种交叉歧义十分常见,前面举的“和服”的例子,其实就是因为交叉歧义引起的错误。“化妆和服装”可以分成“化妆 和 服装”或者“化妆 和服 装”。由于没有人的知识去理解,计算机很难知道到底哪个方案正确。
交叉歧义相对组合歧义来说是还算比较容易处 理,组合歧义就必需根据整个句子来判断了。例如,在句子“这个门把手坏了”中,“把手”是个词,但在句子“请把手拿开”中,“把手”就不是一个词;在句子 “将军任命了一名中将”中,“中将”是个词,但在句子“产量三年中将增长两倍”中,“中将”就不再是词。这些词计算机又如何去识别?
如 果交叉歧义和组合歧义计算机都能解决的话,在歧义中还有一个难题,是真歧义。真歧义意思是给出一句话,由人去判断也不知道哪个应该是词,哪个应该不是词。 例如:“乒乓球拍卖完了”,可以切分成“乒乓 球拍 卖 完 了”、也可切分成“乒乓球 拍卖 完 了”,如果没有上下文其他的句子,恐怕谁也不知道“拍卖”在这里算不算一个词。
2、新词识别
新词,专业术语称为未登 录词。也就是那些在字典中都没有收录过,但又确实能称为词的那些词。最典型的是人名,人可以很容易理解句子“王军虎去广州了”中,“王军虎”是个词,因为 是一个人的名字,但要是让计算机去识别就困难了。如果把“王军虎”做为一个词收录到字典中去,全世界有那么多名字,而且每时每刻都有新增的人名,收录这些 人名本身就是一项巨大的工程。即使这项工作可以完成,还是会存在问题,例如:在句子“王军虎头虎脑的”中,“王军虎”还能不能算词?
新词中除了人名以外,还有机构名、地名、产品名、商标名、简称、省略语等都是很难处理的问题,而且这些又正好是人们经常使用的词,因此对于搜索引擎来说,分词系统中的新词识别十分重要。目前新词识别准确率已经成为评价一个分词系统好坏的重要标志之一。
6 中文分词的应用
目前在自然语言处理技术中,中文处理技术比西文处理技术要落后很大一段距离,许多西文的处理方法中文不能直接采用,就是因为中文必需有分词这道工序。中文分词是其他中文信息处理的基础,搜索引擎只是中文分词的一个应用。其他的比如机器翻译(MT)、语音合成、自动分类、自动摘要、自动校对等等,都需要用到分词。因为中文需要分词,可能会影响一些研究,但同时也为一些企业带来机会,因为国外的计算机处理技术要想进入中国市场,首先也是要解决中文分词问题。在中文研究方面,相比外国人来说,中国人有十分明显的优势。
分词准确性对搜索引擎来说十分重要,但如果分词速度太慢,即使准确性再高,对于搜索引擎来说也是不可用的,因为搜索引擎需要处理数以亿计的网页,如果分 词耗用的时间过长,会严重影响搜索引擎内容更新的速度。因此对于搜索引擎来说,分词的准确性和速度,二者都需要达到很高的要求。目前研究中文分词的大多是科研院校,清华、北大、中科院、北京语言学院、东北大学、IBM研究院、微软中国研究院等都有自己的研究队伍,而真正专业研究中文分词的商业公司除了海量科技以外,几乎没有了。科研院校研究的技术,大部分不能很快产品化,而一个专业公司的力量毕竟有限,看来中文分词技术要想更好的服务于更多的产品,还有很长一段路。
参考:
https://www.jianshu.com/p/e978053b0b95
https://blog.csdn.net/mandagod/article/details/97106717

