

tokenizer.encode和tokenizer.tokenize
一个是返回token,一个是返回其在字典中的id,如下

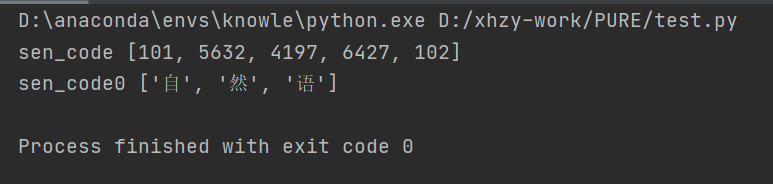
def bert_(): model_name = 'bert-base-chinese' MODEL_PATH = 'D:/xhzy-work/PURE/models/bert-base-chinese/' # a.通过词典导入分词器 tokenizer = BertTokenizer.from_pretrained(model_name) # b. 导入配置文件 model_config = BertConfig.from_pretrained(model_name) # 修改配置 model_config.output_hidden_states = True model_config.output_attentions = True # 通过配置和路径导入模型 bert_model = BertModel.from_pretrained(MODEL_PATH, config=model_config) #sen_code = tokenizer.encode_plus('我不喜欢这世界', '我只喜欢你') sen_code = tokenizer.encode("自然语") print("sen_code",sen_code) sen_code0=tokenizer.tokenize("自然语") print("sen_code0", sen_code0) # input_ids = torch.tensor(tokenizer.encode("自然语")).unsqueeze(0) # print("input_ids",input_ids) # outputs = bert_model(input_ids) # print("outputs",outputs) # sequence_output = outputs[0] # pooled_output = outputs[1] # print("outputs",outputs) # print("sequence_output",sequence_output.shape) ## 字向量 # print("pooled_output",pooled_output.shape) ## 句向量 # print('tokenizer.cls_token',tokenizer.cls_token) if __name__ == '__main__': bert_()
