
【论文笔记】Social network structure and the achievement of consensus
摘要
人们普遍认为,将持有不同意见的各方聚集在一起讨论其分歧,既有助于取得共识,也有助于确保这一共识接近真相。本文利用两个数学模型和计算机仿真模型对这一假设进行了研究。归根结底,这些模型表明,加强接触可以有助于确保共识和真理,但这并不总是有益的。这表明,如果一个人试图提高群体的认知能力,就不应该在没有资格的情况下,支持增加人际接触的政策。
现代社会的中心问题之一是决定如何最好地整合关于几乎任何话题的各种各样的观点。在政治上,成功地整合人们在再分配和社会正义问题上的不同意见是至关重要的。务实地说,各组织必须采取适当行动,综合这些组织成员的意见。从科学上讲,我们希望找到研究人员汇集意见的最佳方式,这种方式能够最有效地引导我们得出真实的结论。
个人有意识或无意识地(在某种程度上)整合来自他人的信息。“社会影响”的过程已经被社会心理学家广泛地研究过,它的存在是无可争议的。早期著名的社会影响实验家所罗门·阿斯克(Solomon Asch)认为,社会影响的极端性令人严重关切。根据Asch(1955:34):
共识要有成效,就要求每个人都能独立地根据自己的经验和见解作出贡献。当一致性处于一致性的支配之下时,社会进程就会受到污染,同时个人也会放弃他作为一种感觉和思维存在所依赖的力量。我们发现,在我们的社会中,从众的倾向如此强烈,以至于相当聪明和善意的年轻人愿意称之为白人黑人,这是一个值得关注的问题。它提出了关于我们的教育方式和指导我们行为的价值观的问题。
然而,还不清楚社会影响是否有害于我们作为社会存在的功能。它允许形成共识,并可能代表一种方式,我们可以集成有关特定情况的各种数据快速和容易。在之前的一篇文章(Zollman,2010b)中,我建议这个过程可能有助于使个人社区更加可靠。利用一个社会影响的数学模型,我说明了被告知(带有噪音)某些特定事实的个人社区如何比个人本身更可靠。
我还谈到了另一个重要的问题:鉴于社会影响很可能是人类社会交往的一个必然特征,那么这种融合的最佳形式是什么?人们与更多或更少的人接触更好吗?
后面的问题很重要。有许多政治运动的目的是使更多的人彼此接触,以便就一个或另一个问题加强对话。我们正在提高科学家通过互联网和更多的期刊和会议相互联系的程度。组织经常试图促进成员之间的互动。所有这些政策都有一个默契的假设,即一个群体通过增加互动而变得更好
不加批判地认为增加互动总是有益的,这是错误的。信仰变迁等社会过程无疑是一个复杂的系统。这在该词的口语意义(即复杂)和技术意义(即表现出非线性、对初始条件的敏感性以及循环或混沌行为)上都是正确的。由于信仰形成中的社会互动表现出复杂系统的某些特性,我们不能仅仅从反思中理解它们。我们也不能从几个实证案例中归纳出来。复杂系统的那些使它们在数学上有趣的特性阻碍了从有限的情况下进行归纳。因此,人们必须使用数学或计算机模拟技术来研究这些系统
利用这类模型,我以前的研究表明,社会互动是否有效取决于潜在的学习情况。当个人积极参与测试不同选择(例如不同的技术或不同的药物治疗)的过程时,令人惊讶的是,增加的社会互动会非常有害(Bala和Goyal,1998年;Ellison和Fudenberg,1995年;Zollman,2007年、2009年、2010年)。这是因为当个人必须寻找证据时,意见的多样性会带来一些好处,因为这会导致群体寻找不同的证据。1拥有高度连接的社交网络往往会阻碍这种多样性,因此会产生明显的负面影响。
但是,当所有可用的信息在任何社交互动发生之前到达时,增加的互动可能会有帮助(Zollman,2010b)。随着潜在互动次数的增加,群体倾向于改善。这个后来的数学模型受到两方面的限制。首先,它只涉及可以被表示为两种状态之一的信念:要么我相信一个命题,要么不相信。其次,它只考虑了三种潜在的社会互动结构。本文试图通过提供另一个模型来弥补这一缺陷,该模型允许考虑更丰富的信仰集和更潜在的社会互动结构。本文中的模型更好地表示政治观点、概率判断或任何可以用连续谱上的点表示的判断。
但归根结底,我们的问题是一样的:什么是社会影响力的最佳形式?社会影响力是多是少?所有试图通过增加团队内部互动的数量来获得可靠共识的政策是否都有可能成功实现其目标?
视情况而定,人们可能有兴趣实现两个目标中的一个。在许多政治局势中,人们可能对协商一致感到满意,而不考虑哪一种意见构成了这种协商一致。这里没有“正确性”的外部判断。然而,在其他情况下,我们可能不仅希望达成共识,而且希望达成接近事实的共识。在接下来的讨论中,我将考虑这两种适当的措施。
本文提供了两个社会影响的数学模型,这将使我们能够比较不同类型的社会安排,以确保(正确)共识的能力。第一个模型称为“线性池”,见第1节。第二个模型是第一个模型的推广,在第2节中介绍。这两种模型的局限性将在第3节和第4节的结论中讨论。
要找到一个社会影响力的最佳表达形式,如何达成共识,增加网络中个体的互动可以有助于达成共识?如果希望共识接近正确性那么要怎么办?
1Linear pooling
也许最直接的社会影响下的信仰改变模式是由French(1956)设计的。French假设每个人在某个区间内都有一个实数表示的观点(这里我们将使用[0,1])。每个个体在一定程度上也会受到另一个个体的影响,也可以用一些非负数来表示。然后,个人通过将自己的信念与所有对自己有影响力的人平均起来来更新自己的信念。所有的人都会同时这样做,从而产生新的信仰。这个过程被重复,直到最终社会影响的力量达到平衡,没有人再改变他们的信仰。
个人可以通过简单地与周围的人分开来平均他们的信仰(更正式地说,通过采用朋友信仰的算术平均值)。或者,个人可以采用加权平均,其中一些人对他们的新信仰的影响比其他人更大。
1.1Mere consensus
在什么样的条件下,我们应该期望这样一个群体能够达成共识?假设我们通过社交网络来表达影响力。每个个体都由一个点(或顶点)表示,如果个体i受个体j的影响程度大于零,我们将画一个从i开始到j结束的箭头。
一旦我们对每个个体都这样做了,我们就有了一个有向图。如果这个图是连通的(也就是说,我们可以从任何个体开始,按照箭头的方向,以一定的步骤到达任何其他个体),如果至少有一个人受到自己的影响,那么整个群体将在极限内收敛到单一的一致意见(DeGroot,1974)。(虽然足够,但这不是必要条件。其他一些网络结构会收敛,如果初始信念具有适当的结构,其他网络结构也会收敛(见Berger,1981)
举个简单的例子。假设一个由三个人组成的社区:卡洛斯、朱莉和香农。卡洛斯受香农的影响,但不受朱莉的影响。朱莉受卡洛斯的影响,香农也受朱莉和卡洛斯的影响。这一组如图1所示。你可以看到,一个人可以通过跟随箭头从任何一个人到任何其他人。因此,这一群体将达成共识。最终的共识是由每个个体受其他个体影响的程度决定的,但可以通过一个相对简单的数学程序来计算。这个程序的细节可以在附录中找到。
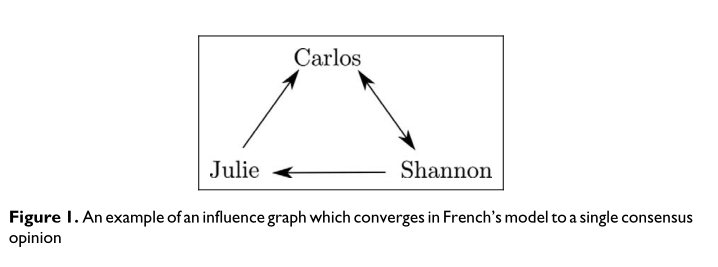
如果我们的兴趣是建立共识,这告诉我们什么?如果我们有两个小组似乎不一致,我们想让他们接触。一个群体中有一个人受到另一个群体中一个人的影响就足够了,但更多的人也可以。这样,F的模式就为那些相信我们的政治体制将通过加强沟通而得到改善的人提供了保障。
1.2 correct consensus
对于某些决定,我们可能只关心协商一致。例如,在一些民主决策中,一个决策的“正确性”可能仅仅取决于它是每个人(或至少是大多数人)都同意的选择。4在这种情况下,我们所希望的是建立一个达成共识的局面.
然而,在许多情况下,有一个独立的真相需要追踪。我们不仅要创造一种达成共识的局面,而且要创造一种共识尽可能接近真相的局面。在这种情况下,我们需要在French的模型中添加一些细节,以便使分析更易于处理。首先,我们将限制我们的社会影响观念。我们将施加一些限制,而不是允许任意程度的影响。假设每个人都有一群朋友,假设每个人都受到她所有朋友的同样程度的影响。5这允许我们将社会影响表示为一个无向图,如图2所示
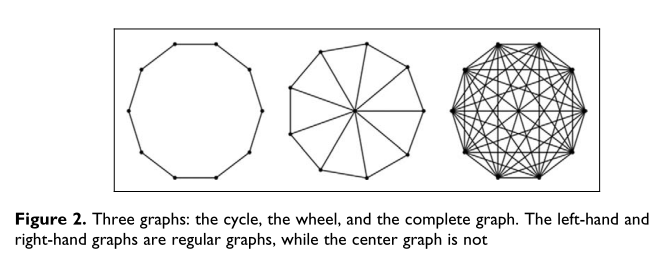
现在假设每个个体都得到了一些关于某个参数真实值的初始“信号”。也许每个人都进行一个独立的实验来估计某个分布的平均值,或者也许他们每个人都得到了关于某个潜在概率的实际值的不同信息。无论模拟的是什么样的情况,我们都会假设每个人的期望值是真实的.
鉴于这种模式,我们现在可以问,什么样的社会影响结构产生了最接近事实的共识。如果每个人都同样可靠,那么社会影响力的结构应该是有规律的,也就是说,每个人的朋友数量应该与其他人完全相同(证据可以在附录中找到,另见DeMarzo等人。(2003)以及Golub和Jackson(2010))。6这确保了没有任何人对最终的共识估计有不当影响。考虑图2中的三个图。这里的左手图和右手图都是正则的。左边的图表是一个循环,每个人只有两个朋友(加上她自己)。右边的图是完整的图,每个人都把其他人当作朋友。令人惊讶的是,从最终的共识来看,这两个属性都同样好。这与图2中的中间图形成了对比,图中的轮子是每个人的朋友。在这里,中间的人对最终的一致意见施加了不成比例的影响,因此不适当地将结果偏向她自己的意见。
循环图和完整图之间有一个重要的区别。完整的图表在达成共识方面要快得多——它是一步到位的。另一方面,这个循环图实际上需要永远才能达成共识,尽管它在每一步上都越来越接近。因此,如果一个人不仅关心最终的共识,而且关心速度,那么他可能更喜欢完整的图表(Harray,1959)
这些结果对第1.1节的结论作出了重要的限定。在那里,任何新朋友的加入都不会损害达成共识,但在这里,显然会造成损害。如果一个人从一个按周期排列的组开始,通过介绍两个新的人来添加一个链接,那么现在一个人已经使这个组不那么可靠了。这表明,如果我们有一个关于真相的想法,我们希望这个团体朝着这个目标努力,那么让每个人彼此接触不应该被视为总是有成效的。
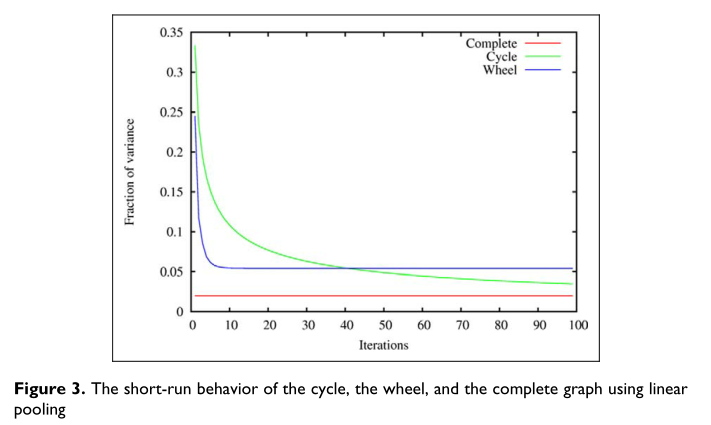
图3比较了这两个图的短期和长期行为。这里,x轴表示平均过程的迭代次数,y轴表示(平均)最终判断离事实有多远。仅观察非常短期的行为(在图的最左边),添加边有助于即使它降低了图的规则性。但是,在足够长的时间之后,车轮中连接数的不相等导致对真相的估计比接近完整图可靠性的循环更为偏斜。
如果个人不平等地可靠呢?也许给一个人两个信号或者一个更大的样本。在这种情况下,我们希望友谊属性代表信息质量的这种差异。如果一个人的可靠度是其他人的两倍,我们希望他有两倍的朋友(算上她自己)。图4中有三个示例。在每一个例子中,添加任何数量的边都会降低组的可靠性。再说一次,我们可能不想在这里介绍两个新人。
有人可能会认为,要求所有的朋友都受到平等对待太过严格,因为人们受到不同朋友不同程度的影响。空间阻止了对这种情况的详细讨论,但是感兴趣的读者应该咨询Golub和Jackson(2010)以及Hartmann等人。(2009),谁考虑的正是这一点。
2
3
4
5
6
