
Lucene5.5.4入门以及基于Lucene实现博客搜索功能
前言
一直以来个人博客的搜索功能很蹩脚,只是自己简单用数据库的like %keyword%来实现的,所以导致经常搜不到想要找的内容,而且高亮显示、摘要截取等也不好实现,所以决定采用Lucene改写博客的搜索功能。先来看一下最终效果:
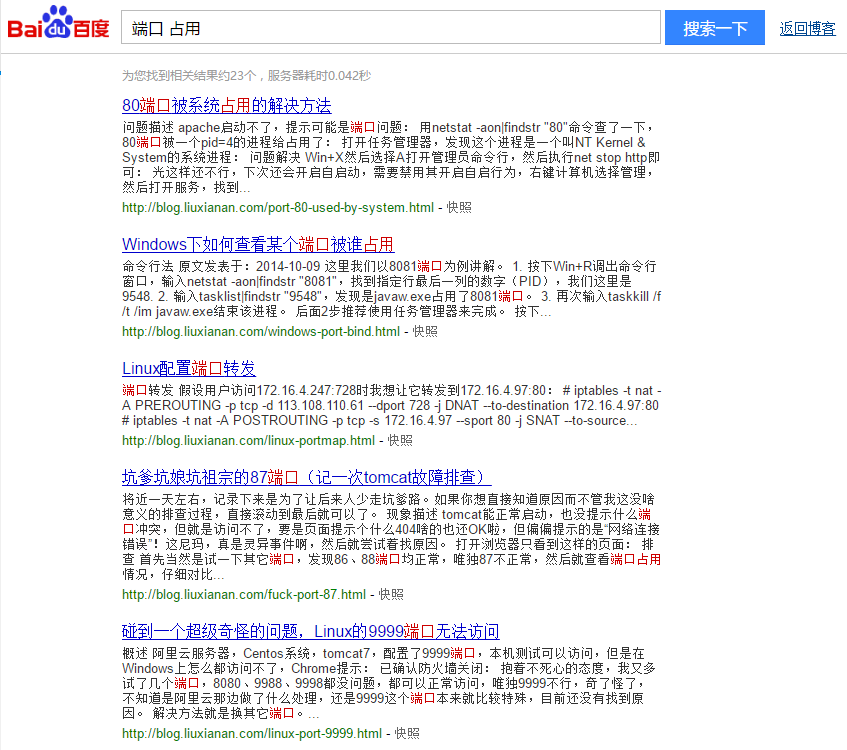
本文demo地址:https://github.com/liuxianan/lucene-demo (包括本文需要用到的jar包可以从这里面下载)
效果演示地址:http://blog.liuxianan.com/search?kw=端口 占用
Lucene 介绍
Lucene是一个用Java开发的开源全文检索引擎,官网是:http://lucene.apache.org/ ,Lucene不是一个完整的全文索引应用(与之对应的是solr),而是是一个用Java写的全文索引引擎工具包,它可以方便的嵌入到各种应用中实现针对应用的全文索引/检索功能,更多介绍大家自行搜索。
版本选择
目前最新版是6.5.1(截止到2017-05-04),本来想直接用最新版的,但是下载下来之后发现老是提示找不到某些类,可我直接找到对应的jar包下去看却是有的,不过却无法用jd-gui反编译,提示一个什么错误,盲目的我竟然以为是因为版本太新,apache在放出最新jar包时自己没测试,后来试了几个老一点的6.x版本发现都是这个错误,5.x就不会,好吧,这时才想起来应该是jdk版本不对,Lucene6.x需要jdk1.8以上,只能怪我太out了,毕竟确实好久没怎么写过Java代码了。
由于本地、线上都是使用的jdk1.7,不好为了一个Lucene就升级到1.8,所以决定改用5.5.4版本。
正式开始
下载
从网上下载的包一般比较大,有70多M(官网目前只能下载最新版的,5.x的估计要到其它地方下载),一般人只用下面这几个就够了:

也就是这几个:
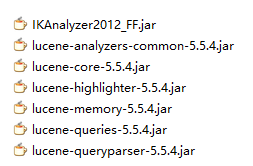
其中IKAnalyzer2012_FF.jar是一个国人写的中文分词工具,Lucene自带的分词对中文支持不好。注意,这个jar包网上比较乱,随便从网上下载的话可能不兼容,因为跟具体的Lucene版本有关,初学者建议直接用我demo里面整理好的jar包:https://github.com/liuxianan/lucene-demo/tree/master/WebContent/WEB-INF/lib
建立索引
特别注意,Lucene不同版本的API变化比较大,如果你用的是其它版本,注意代码可能要变。
其实代码比较简单,我们先来一个搜索文件的例子(下面的FileUtil可以自己简单实现)。
public static final String INDEX_PATH = "E:\\lucene"; // 存放Lucene索引文件的位置
public static final String SCAN_PATH = "E:\\text"; // 需要被扫描的位置,测试的时候记得多在这下面放一些文件
/**
* 创建索引
*/
public void creatIndex()
{
IndexWriter indexWriter = null;
try
{
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath(INDEX_PATH));
//Analyzer analyzer = new StandardAnalyzer();
Analyzer analyzer = new IKAnalyzer(true);
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
indexWriter = new IndexWriter(directory, indexWriterConfig);
indexWriter.deleteAll();// 清除以前的index
// 获取被扫描目录下的所有文件,包括子目录
List<File> files = FileUtil.listAllFiles(SCAN_PATH);
for(int i=0; i<files.size(); i++)
{
Document document = new Document();
File file = files.get(i);
document.add(new Field("content", FileUtil.readFile(file.getAbsolutePath()), TextField.TYPE_STORED));
document.add(new Field("fileName", file.getName(), TextField.TYPE_STORED));
document.add(new Field("filePath", file.getAbsolutePath(), TextField.TYPE_STORED));
document.add(new Field("updateTime", file.lastModified()+"", TextField.TYPE_STORED));
indexWriter.addDocument(document);
}
}
catch (Exception e)
{
e.printStackTrace();
}
finally
{
try
{
if(indexWriter != null) indexWriter.close();
}
catch (Exception e)
{
e.printStackTrace();
}
}
}
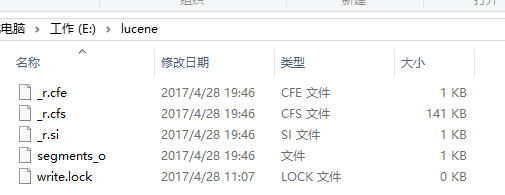
执行完之后就在指定目录新建了索引文件,以后的搜索就靠他们了:
简单的搜索
代码比较简单,具体可以看注释,这里就不详述了。
/**
* 搜索
*/
public void search(String keyWord)
{
DirectoryReader directoryReader = null;
try
{
// 1、创建Directory
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath(INDEX_PATH));
// 2、创建IndexReader
directoryReader = DirectoryReader.open(directory);
// 3、根据IndexReader创建IndexSearch
IndexSearcher indexSearcher = new IndexSearcher(directoryReader);
// 4、创建搜索的Query
// Analyzer analyzer = new StandardAnalyzer();
Analyzer analyzer = new IKAnalyzer(true); // 使用IK分词
// 简单的查询,创建Query表示搜索域为content包含keyWord的文档
//Query query = new QueryParser("content", analyzer).parse(keyWord);
String[] fields = {"fileName", "content"}; // 要搜索的字段,一般搜索时都不会只搜索一个字段
// 字段之间的与或非关系,MUST表示and,MUST_NOT表示not,SHOULD表示or,有几个fields就必须有几个clauses
BooleanClause.Occur[] clauses = {BooleanClause.Occur.SHOULD, BooleanClause.Occur.SHOULD};
// MultiFieldQueryParser表示多个域解析, 同时可以解析含空格的字符串,如果我们搜索"上海 中国"
Query multiFieldQuery = MultiFieldQueryParser.parse(keyWord, fields, clauses, analyzer);
// 5、根据searcher搜索并且返回TopDocs
TopDocs topDocs = indexSearcher.search(multiFieldQuery, 100); // 搜索前100条结果
System.out.println("共找到匹配处:" + topDocs.totalHits); // totalHits和scoreDocs.length的区别还没搞明白
// 6、根据TopDocs获取ScoreDoc对象
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
System.out.println("共找到匹配文档数:" + scoreDocs.length);
QueryScorer scorer = new QueryScorer(multiFieldQuery, "content");
// 自定义高亮代码
SimpleHTMLFormatter htmlFormatter = new SimpleHTMLFormatter("<span style=\"backgroud:red\">", "</span>");
Highlighter highlighter = new Highlighter(htmlFormatter, scorer);
highlighter.setTextFragmenter(new SimpleSpanFragmenter(scorer));
for (ScoreDoc scoreDoc : scoreDocs)
{
// 7、根据searcher和ScoreDoc对象获取具体的Document对象
Document document = indexSearcher.doc(scoreDoc.doc);
//TokenStream tokenStream = new SimpleAnalyzer().tokenStream("content", new StringReader(content));
//TokenSources.getTokenStream("content", tvFields, content, analyzer, 100);
//TokenStream tokenStream = TokenSources.getAnyTokenStream(indexSearcher.getIndexReader(), scoreDoc.doc, "content", document, analyzer);
//System.out.println(highlighter.getBestFragment(tokenStream, content));
System.out.println("-----------------------------------------");
System.out.println(document.get("fileName") + ":" + document.get("filePath"));
System.out.println(highlighter.getBestFragment(analyzer, "content", document.get("content")));
System.out.println("");
}
}
catch (Exception e)
{
e.printStackTrace();
}
finally
{
try
{
if(directoryReader != null) directoryReader.close();
}
catch (Exception e)
{
e.printStackTrace();
}
}
}
测试:
public static void main(String args[])
{
FileSearchDemo demo = new FileSearchDemo();
demo.creatIndex();
demo.search("读取 导出");
}
稍微复杂一点的搜索
很多时候搜索时可能需要多个条件配合,就像我们的SQL查询一样,不然无法满足我们的业务。Lucene可以将多个query通过BooleanQuery进行与或非处理得到最终的query。其实再复杂一点的我也没试过,下面只是一个简单的示例:
String[] fields = {"fileName", "content"}; // 要搜索的字段,一般搜索时都不会只搜索一个字段
// 字段之间的与或非关系,MUST表示and,MUST_NOT表示not,SHOULD表示or,有几个fields就必须有几个clauses
BooleanClause.Occur[] clauses = {BooleanClause.Occur.SHOULD, BooleanClause.Occur.SHOULD};
// MultiFieldQueryParser表示多个域解析, 同时可以解析含空格的字符串,如果我们搜索"上海 中国"
Query multiFieldQuery = MultiFieldQueryParser.parse(keyWord, fields, clauses, analyzer);
Query termQuery = new TermQuery(new Term("content", keyWord));// 词语搜索,完全匹配,搜索具体的域
Query wildqQuery = new WildcardQuery(new Term("content", keyWord));// 通配符查询
Query prefixQuery = new PrefixQuery(new Term("content", keyWord));// 字段前缀搜索
Query fuzzyQuery = new FuzzyQuery(new Term("content", keyWord));// 相似度查询,模糊查询比如OpenOffica,OpenOffice
BooleanQuery.Builder queryBuilder = new BooleanQuery.Builder();
queryBuilder.add(multiFieldQuery, BooleanClause.Occur.SHOULD);
queryBuilder.add(termQuery, BooleanClause.Occur.SHOULD);
queryBuilder.add(wildqQuery, BooleanClause.Occur.SHOULD);
queryBuilder.add(prefixQuery, BooleanClause.Occur.SHOULD);
queryBuilder.add(fuzzyQuery, BooleanClause.Occur.SHOULD);
BooleanQuery query = queryBuilder.build(); // 这才是最终的query
TopDocs topDocs = indexSearcher.search(query, 100); // 搜索前100条结果
复杂的搜索还有可能涉及多个索引目录的搜索,不同结果的权重分配、排序,近义词搜索,等等,这里就不多说了,本文只是入门而已。
数据库搜索
其实和文件搜索差不多,只不过建立索引时是从数据库读取内容,我也写了一个简单的数据库搜索示例,可以从前面提到的demo找到(https://github.com/liuxianan/lucene-demo/blob/master/src/com/test/DbSearchDemo.java ),这里不细述。
运行效果如下:
共找到匹配处:1
共找到匹配文档数:1
-----------------------------------------
文章标题:Android原生与JS交互总结
文章地址:http://blog.liuxianan.com/android-native-js-interactive.html
文章内容:
test.testBoolean(false); // 输出"boolean:null"
可以发现,如果<span style="backgroud:red">Android</span>这边参数使用了包装类型会导致参数接收不到,必须使用基本类型,把上面的
基于Lucene实现博客搜索功能
前面都只是例子,下面要试着把它用于正式的项目中。
创建索引的时机
首先写一个LuceneService类,这里面只有2个方法,一个是创建索引,一个是搜索,那么在什么时候创建索引呢?
我在SpringMVC的监听器里面加入了段代码,在系统启动时主动创建一次索引,另外每24小时再自动更新一次,防止万一。为保证实时更新,添加文章、修改文章、删除文章之后也都立即更新一次索引。
/**
* 更新Lucene索引
* @param event
*/
public void updateLuceneIndex(final ServletContextEvent event)
{
luceneTimer = new Timer("Lucene索引定时构建任务", true);
log.debug("启动Lucene索引构建定时任务!");
ApplicationContext context = WebApplicationContextUtils.getWebApplicationContext(event.getServletContext());
final LuceneService luceneService = context.getBean(LuceneService.class);
// 系统启动1分钟之后主动建立一次Lucene索引
luceneTimer.schedule(new TimerTask()
{
@Override
public void run()
{
luceneService.updateIndex(event.getServletContext());
}
}, 1000 * 60, 1000 * 60 * 60 * 24);
}
必须要开新线程执行
经过测试对于博文内容不是很多的情况下,一般建立索引都在数秒之内,虽然比较快,但还是要避免阻塞主线程,这里我偷懒简单的用new Thread来实现:
/**
* 创建索引,发布文章、修改文章、删除文章之后都应记得更新索引
*/
public void updateIndex(final ServletContext application)
{
new Thread(new Runnable()
{
@Override
public void run()
{
try
{
Thread.sleep(3000); // 由于新增、修改文章之后立即更新索引可能太数据库还未写入,所以延迟一段时间执行
}
catch (InterruptedException e)
{
e.printStackTrace();
}
// 创建索引一般需要数秒种,为避免阻塞主线程影响业务,开启新线程执行
createIndexSingleThread(application);
}
}).start();
}
如何搜索HTML或markdown
由于我的数据库存放的是markdown,这里着重考虑一下后面这个问题,虽然markdown已经和纯文本差不多了,但是在搜索摘要里面显示一大堆类似# 这是一级标题这样的东西也是不爽的,我没有找到合适的将markdown过滤为纯文本的工具类,只能自己简单写一个,真的是太简单,简单到我的博客里面主要哪种类型的markdown标记,我就过滤什么样的标记,其它都没管,这个方法肯定还有很多问题,目前只要能满足我的需求就足够了,如果有谁有好的工具欢迎推荐。另外一个就是注意替换HTML的<>标签:
/**
* 简单地过滤markdown标记使之成为纯文本,主要用在摘要和搜索的场景
* @param md
* @return
*/
public static String markdownToText(String md)
{
if(StringUtil.isEmpty(md)) return "";
md = md.replaceAll("(^|\n|\r\n)#{1,6} *", "$1"); // 去除 #
md = md.replaceAll("(^|\n|\r\n)\\* *", "$1"); // 去除 *
md = md.replaceAll("(^|\n|\r\n)> *", "$1"); // 去除 > (引用)
md = md.replaceAll("(^|\n|\r\n)```\\w*?(\n|\r\n)([\\s\\S]+?)```", "$2$3"); // 去除代码块
md = md.replaceAll("`([^`]+?)`", "$1"); // 去除行内 `code`
md = md.replaceAll("!\\[(.*?)\\]\\(.+?\\)", "$1"); // 去除 img
md = md.replaceAll("\\[(.*?)\\]\\(.+?\\)", "$1"); // 去除 超链接
md = md.replaceAll("<", "<");
md = md.replaceAll(">", ">"); // 替换HTML标签
return md;
}
如果是数据库存放的是HTML,可以用一些开源库把它转换成纯文本再建立索引,比如jsoup。
分页
官方建议一次性全部查出来,然后再自己分页,而且如果你要知道总页数,也只能这么干。虽然还有一个searchAfter方法,但是对于这里没啥用。
不同用户显示不同内容
比如有一些仅自己可见的文章,我希望当我登录了时可以被搜索到,没有登录时不能搜索,可以这样实现:
BooleanQuery.Builder queryBuilder = new BooleanQuery.Builder();
queryBuilder.add(multiFieldQuery, BooleanClause.Occur.MUST);
if(user == null)
{
// 未登录用户只能查询公开的文章
Query termQuery = new TermQuery(new Term("permission", "pub")); // term表示准确搜索
queryBuilder.add(termQuery, BooleanClause.Occur.MUST);
}
BooleanQuery query = queryBuilder.build();
效果体验
可以访问我的博客 http://blog.liuxianan.com 然后双击Ctrl即可搜索。
结束语
由于时间匆忙,目前草草地实现了搜索功能,后续发现问题再慢慢优化吧,毕竟这不是主业(已转前端),没那么多时间搞这东西。
搜索效果文章最前面已经给出了,仿百度做的,哈哈!
本文是面向入门级别的,想深入学习可以参考这位仁兄的系列文章:
http://blog.csdn.net/wuyinggui10000/article/category/3173543

github:https://github.com/sxei
博客园:http://www.cnblogs.com/liuxianan
copyright ©2012-2020 小茗同学
【转载文章务必保留出处和署名,谢谢!】



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· 展开说说关于C#中ORM框架的用法!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?