
AdaBoost 算法原理及推导
AdaBoost(Adaptive Boosting):自适应提升方法。
1、AdaBoost算法介绍
AdaBoost是Boosting方法中最优代表性的提升算法。该方法通过在每轮降低分对样例的权重,增加分错样例的权重,使得分类器在迭代过程中逐步改进,最终将所有分类器线性组合得到最终分类器,Boost算法框架如下图所示:

图1.1 Boost分类框架(来自PRML)
2、AdaBoost算法过程:
1)初始化每个训练样例的权值,共N个训练样例。
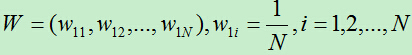
2)共进行M轮学习,第m轮学习过程如下:
A)使用权值分布为Wm的训练样例学习得到基分类器Gm。
B)计算上一步得到的基分类器的误差率:(此公式参考PRML,其余的来自统计学习方法)
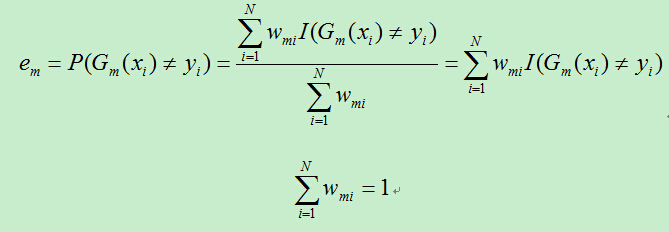
C)计算Gm前面的权重系数:
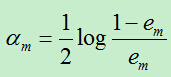
D)更新训练样例的权重系数,
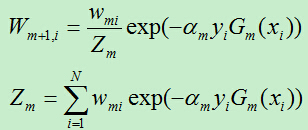
E)重复A)到D)。得到一系列的权重参数am和基分类器Gm
4)将上一步得到的基分类器根据权重参数线性组合,得到最终分类器:
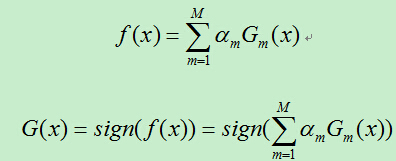
3、算法中的两个权重分析:
1)关于基分类器权重的分析
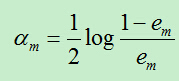
上面计算的am表示基分类器在最终的分类器中所占的权重,am的计算根据em而得到,由于每个基分类器的分类性能要好于随机分类器,故而误差率em<0.5.(对二分类问题)
当em<0.5时,am>0且am随着em的减小而增大,所以,分类误差率越小的基分类器在最终的分类器中所占的权重越大。
注:此处的所有am之后并不为1。
2)训练样例的权重分析
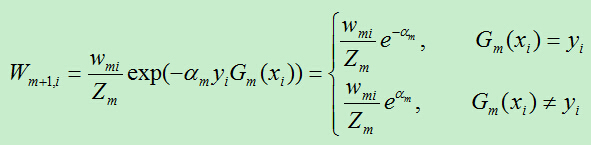
根据公式可知,样例分对和分错,权重相差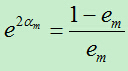 倍(统计学习方法上此公式有误)。
倍(统计学习方法上此公式有误)。
由于am>0,故而exp(-am)<1,当样例被基本分类器正确分类时,其权重在减小,反之权重在增大。
通过增大错分样例的权重,让此样例在下一轮的分类器中被重点关注,通过这种方式,慢慢减小了分错样例数目,使得基分类器性能逐步改善。
4、训练误差分析
关于误差上界有以下不等式,此不等式说明了Adaboost的训练误差是以指数的速度下降的,
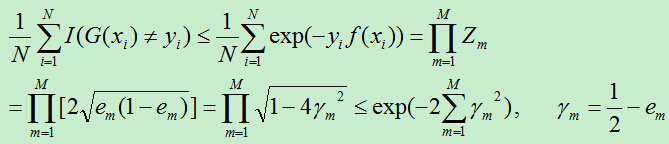
推导过程用到的公式有:
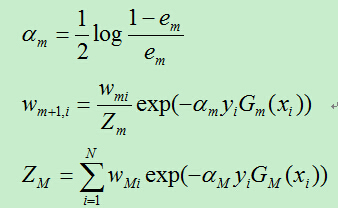
具体推导过程请看统计学习方法课本!
5、AdaBoost算法推导过程
AdaBoost算法使用加法模型,损失函数为指数函数,学习算法使用前向分步算法。
其中加法模型为:
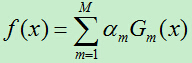
损失函数为指数函数:

我们的目标是要最小化损失函数,通过最小化损失函数来得到模型中所需的参数。而在Adaboost算法中,每一轮都需要更新样例的权重参数,故而在每一轮的迭代中需要将损失函数极小化,然后据此得到每个样例的权重更新参数。这样在每轮的迭代过程中只需要将当前基函数在训练集上的损失函数最小即可。
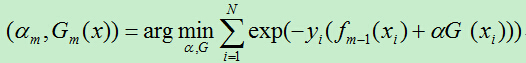
现在我们需要通过极小化上面的损失函数,得到a,G。
设:
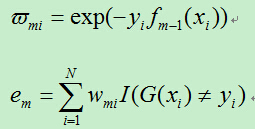
于是有:

为了方便下面推导,我们将:
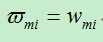
这样,我们就有:

正式推导过程如下:
设: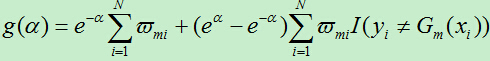
对g(a)求导得:

令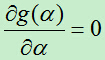 ,得到:
,得到:

其中,在计算过程中用到的em为:
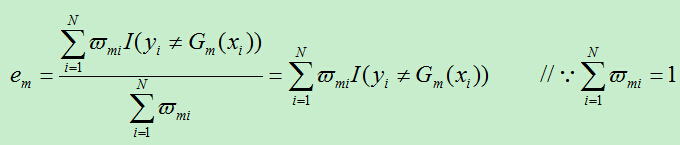
由于 ,所以得到新的损失为:
,所以得到新的损失为:
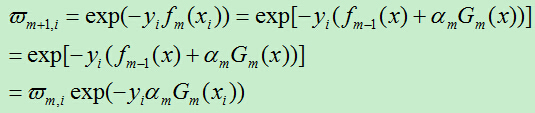
最终的wmi通过规范化得到:
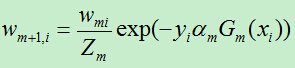
其中规范化因子为:
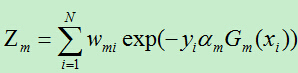
参考文献:
[1] 李航,统计学习方法。
[2] Bishop, Pattern Recognition and Machine Learning

 浙公网安备 33010602011771号
浙公网安备 33010602011771号