
深入学习垃圾kafka
背景:
1. kafka是一个分布式、高吞吐率的消息系统
---- 早期版本
---- 重点在日志处理
2. kafka是一个分布式、流式平台
---- 0.10
---- 天然支持stream处理
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
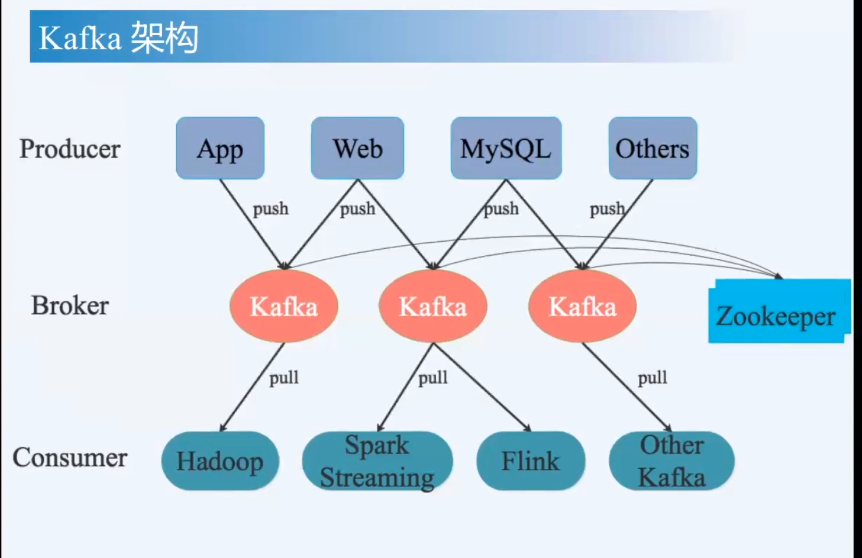

名词解释
- producer
- broker(中间人),依赖ZK,存储一些元信息 + 领导选举之类的
- consumer
- 细分
- Record(每一条数据)
- key-value
- timestmap
- Topic(一个消息类别)
- 逻辑概念
- 发布-订阅基于topic
- Partition(分布在不同的broker中)
- 物理概念
- 一个Topic包含多个partition
- 每个partition物理上对应一个文件夹
- Segment
- 是文件,一个partition下的多个文件
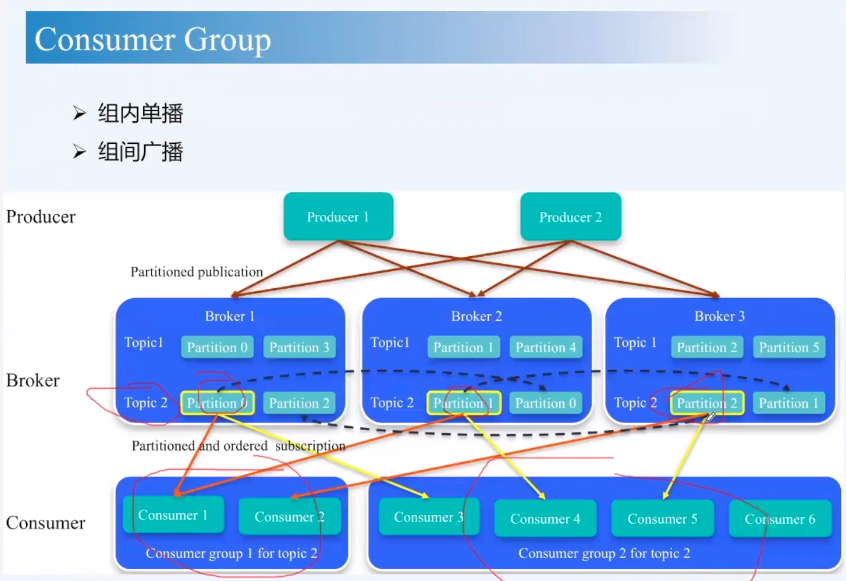
- Consumer group
- 就是指定N:M,N个consumer消费M个partition
- Record(每一条数据)
关键点
- consumer使用pull机制而不用push机制(GO语言的NS-queue采用push),原因可以防止producer产生数据太快,但是consumer消费不过来一直积压
- broker里面的数据是持久化的,consumer处理慢不会影响数据丢失
- pull方式会比push方式慢一点,因为不会一直pull数据,中间有一个时间间隔,或者使用long pulling也行但是还是没push高
- producer需要使用SDK发送数据,SDK有内部数据队列,会有丢弃数据风险(可以用立马flush,变成同步模型)
- 写数据(append only),顺序写
- 什么时候删数据?只需要删除最老的segment即可
- 默认SDK发送会有多条TCP链接,这样会导致发送顺序乱掉,解决方法是设置TCP连接数为1
- consumer group是如何reblance的?(集中式rebalance)
- coordinator决定
- ISR复制模式 (In Sync Replace,每次都是一批一批数据过来的)
- 发送数据去partition的leader
- follower有两个容忍
- 接受K条消息落后,超过踢掉(旧版本)
- 接受K秒消息落后,超过踢掉
- 假如leader挂了,就会在ISR里面宿便选一个
- 如何实现exactly once
- 两阶段提交
- 幂等接口
- offset和数据库放在同一个事务
既然选择了远方,就要风雨兼程~
posted on 2021-02-25 16:04 stupid_one 阅读(138) 评论(1) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号