踩坑记
2025-06-15 16:29:31
使用 python 的最好方法,就是
1. 安装 pyenv,然后 pyenv install 3.9.0
2. virtualenv .venv --python ~/.pyenv/versions/3.12.0/bin/python
3. 然后使用 uv 去管理依赖,假如一定要用 poetry,poetry 中的 1.1.15 是支持 python2 的分界点
2022-07-06 17:07:42
gdb python
install mysqldb for python 1、sudo apt-get install libmysqlclient-dev 2、pip install --no-cache mysqlclient install lxml for python3 如果pip3 install不行的话, 1、sudo apt-get install libxml2-dev libxslt-dev python-dev 2、sudo apt remove python3-lxml 再 install debug(gdb): https://drmingdrmer.github.io/tech/programming/2017/05/06/python-mem.html
2021-02-20 17:23:48
假如访问一个HTTP接口,本来是POST的去到哪里变GET了,可以认为是redirect导致的,因为redirect都只能是GET, 比如301
情况就是在HTTP访问,但是后台只希望HTTPS,就会发生301 redirect
2021-01-19 20:51:14
python的logging是进程不安全的,特别在文件自动rotate的时候
1. 文件名带上pid
2. 使用第三方管道链接吧 rotatelogs
2021-01-04 18:13:20:
头条中的thrift都是copy一份的,不知道为什么要深copy


# FAQs: # Q: 为什么这里的 base.thrift 与 service_rpc/idl/base.thrift 不一致? # A: service_rpc/idl/base.thrift 生成的 C++ 代码是无法编译通过的。 # TrafficEnv 使用相同的字段类型和字段名,C++ 中有名字冲突;Client 字段在 fbthrift 中是保留字。 # # Q: 使用这里的 base.thrift 与 service_rpc/idl/base.thrift 是否兼容? # A: 使用 BinaryProtocol 传输是完全兼容的,而你也不应该使用其他的 Protocol。 # # Q: golang 代码可以依赖这里的 base.thrift 吗? # A: 可以,golang 生成的代码大小写是依据 golang 的语法,而不是 idl 的定义。 # 但是基于 kite 和 data/idl 在路径约定方面的差异,可能你会碰到一些困难。 # # Q: python 代码可以依赖这里的 base.thrift 吗? # A: 可以。如果依赖了 data/idl 生成的 python 代码,后续要迁移到 pie 框架时需要注意字段名字的改变。 # 由于 python 不是编译执行的,这样的错误可能会发生在运行时。 # # Q: 我的 idl 既要在 C++ 中使用,又要在 python/golang 中使用,怎么办? # A: 既提交到 data/idl,又提交到 service_rpc/idl。在两个库中,依赖各自的 base.thrift。 # # Q: 为什么要维护两份 idl,不能统一吗? # A: 如果你尝试过然后失败了,请把下面的计数器 +1。 # 4
2020-12-28 18:34:09:
1. 在cronjob命令中,&>/tmp/log是没用的,因为cronjob用的是/bin/sh这个shell,而这个命令是用在/bin/bash
2. 在一些shell运行的后台命令中,我们应该重定向stdin(注意是stdin,不是stdout和stderr),因为怕这个进程开启一些子进程,然后这些子进程需要从terminal输入,这样就一直hang住了,所以需要加上
< /dev/null see more
3. python的print是有buffer的,可以用python -u处理Force the stdout and stderr streams to be unbuffered. This option has no effect on the stdin stream.
2020-08-03 20:25:23:
IO多路服用,就是用来检测IO是否可操作的一种机制。
1. 端口只有65535个,怎么维持百万的链接. fd可以有很多个(源ip, 目的ip, 源端口,目的端口,协议)
2. reactor/proactor
3. 网络模型
1. epoll + 多线程. (a & b)
a. read主线程,其他放去thread
b. 每一个fd可读,直接放去thread
2. epoll accept + 1:n 网络模型. accept + 8 * thread。强CPU处理
3. epoll n*accept + m*thread. 强接入能力
4. 所有的sockFD
1. listenfd -> accept
2. clientfd -> recv/send
2020-7-23 20:41:15:
协程就是一个轻微的调度单位,他希望有异步的效率,和同步的写法。
客户端的同步异步:
1. 同步:一个请求,一个相应。
2. 异步:一个请求,两个请求。一个相应,两个相应。
服务器的同步与异步:
1. 同步: 经过epoll_wait知道哪些fd可读后,单线程处理。
2. 异步:经过epoll_wait知道哪些fd可读后,多线程处理。这种方法麻烦,比如fd1正在处理,epoll又告诉了其他线程,fd1又有数据了,这样就多个线程共用一个fd的现象了.
同步的流程 改成 异步(提高效率):
1. commit
1.1: 创建好fd(就是socket)
1.2: 准备数据
1.3: send
1.4: 加入去epoll监听(epoll_ctl),准备callback
2. callback: 需要另外一个线程支持,相当于回调接口
2.1: epoll_wait()
3. create_context()
4. destroy_context()
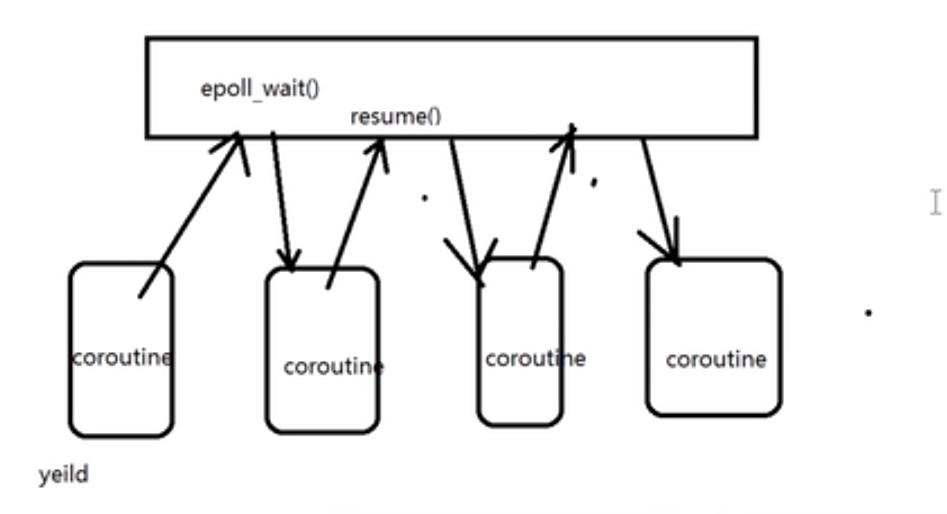
异步的会了,协程的写法是,放去epoll监听后,不要马上结束了,想同步得到数据,这样写起来舒服
所以需要:
1. yiled
2. resume
怎么实现?
1. setJump/longJump
2. uContext
3. 自己实现,汇编操作
线程怎么调度,以X86为例子,有15个寄存器,一个running的线程,save好所有寄存器,然后其他线程的,load去现在的cpu
yeild到epoll_wait中
resume到一个协程
yeild到epoll_wait中 resume到一个协程 if (fd不可写) { yeild } my_send(fd) yield if (fd不可读) { yeild } my_recv(fd) // 下面是业务流程 struct Scheduler { struct CO* current; // 用来切换, 换出时间片的. } struct CO { // 线程的状态 new, ready, running, block, dead, unsigned int status; // ready, running, defer(sleep), wait(IO wait). int fd; Context context; // cpu 切换 void* callbackfunc(void* data) void* params void* stack; // 后面rsp所指向的地方,就是函数调用一样 size_t stack_size; // ready 队列,只保存队列的node指针就好,不要保存prev, next,这样好扩展 ready_queue(CO) ready_node; // defer node, key是时间戳,假如有重复就加1ns rbtree_node(CO) defer_node; // wait node,IO也不是一直等待的,有超时时间,用timestamp + wait_time作为key. rbtree_node(CO) wait_node; }
AIO异步IO 和IO异步操作的区别
1. 他们没可比性,AIO不是一个操作。IO异步操作就是服务器的异步操作。
2. AIO,内核提供的一种,在内核态里面,假如IO有数据了,(io_setup)回调用户态的东西。
3. 思考题:为什么有了AIO,服务器编程还是不用呢?因为它是内核态阻塞的
2020-07-17 11:20:14:
nginx顶在前面意味着对于后端python来说是低并发高频率的请求
1. 吞吐率: 总请求数 / 所用时间
2. 并发连接数: 某个时刻服务器最大并发
3. 并发用户数:注意,一个用户可能很多个连接
4. 用户平均等待时间:所有请求所用时间 / 总请求数 / 用户量
5. 服务器平均处理时间:所有请求所用时间 / 总请求数
输入命令
ab -n 100 -c 10 http://test.com/
其中-n表示请求数,-c表示并发数
top, htop命令中的
1. VIRT: 虚拟内存大小
2. RES: 常驻内存大小
3. SHR: 共享内存大小
阻塞IO: 发起一个recvfrom,内核会挂起直到有数据得到。
非阻塞IO:发起一个recvfrom,如果没有数据就会返回EWOULDBLOCK状态码,应用要一直读。
IO复用模型:如果用第一种,N个请求需要N的线程一直询问。浪费太多线程了,然后这种用select(一个线程去询问),有数据后callback原来的线程(或者有数据后再起一个线程去跑)(起可以是用线程池的,不需要真的起)。
信号驱动IO模型: select还是在应用层轮询,现在这个交给内核做。内核返回可读了给应用线程。
异步IO:这个内核有数据,直接复制好数据,然后通知应用线程。
同步和异步永远都是一个宏观的概念,阻塞非阻塞是微观的,就是细节化是不是应该一直等待
1. 同步阻塞,就是requests
2. 同步非阻塞,就是request一个task,然后一直轮询这个task
3. 异步没有阻塞
4. 异步非阻塞,就是有结果,他们再来一个callback
为什么多线程访问同一个变量需要加锁?
因为有高速缓存这个东西,内存相对于cpu来说太慢了,所以cpu会把值读入cpu的高速缓存,然后来操作,最后再覆盖原来那个值。所以就会出现冲突。
解决方法1:
cpu总线锁,锁住cpu去那块内存拿值。但是上面的方式会有一个问题,由于在锁住总线期间,其他CPU无法访问内存,导致效率低下。
解决方法2:
内存一致性协议,比如我写下去了,然后就标志一个位置说明他是写过了,以后别人读或者写都要重新load之类的。
我们需要保证的是:
有序性:
有指令重排序风险
线程1:
isTrue = True
线程2:
while isTrue:
do。。。
这样是不安全的,可能有先while,后赋值的风险。
需要用lock来保证。
可见性:
用volatile修饰的东西,马上会写进去主存,就是没有了高速缓存这个概念了。
原子性:
需要用lock来保证。
2020-04-29 18:34:41:
dd if=/dev/urandom of=1GB.bin bs=4G iflag=fullblock
2020-04-25 14:26:29:
py
decode和encode不同:
>>> b = b"\347\262\244A B223\350\257\225" >>> b.decode("utf-8") '粤A B223试' >>> b.decode("utf-8").encode("utf-8") b'\xe7\xb2\xa4A B223\xe8\xaf\x95'
2020-04-14 23:30:41:
在netstat -apn | grep -i 3000如果出现下面情况,其实是只有247那个是本机的,下面那个是其他container的,只是通过某个东西链接起来了。
tcp 0 0 0.0.0.0:3000 0.0.0.0:* LISTEN 247/nc tcp 0 0 0.0.0.0:3000 0.0.0.0:* LISTEN -
2020-04-14 11:23:55:
1. docker run --rm busybox nslookup archive.ubuntu.com 100.100.2.136
2. 在本机中: nslookup archive.ubuntu.com 是可以的。
2020-04-13 22:54:02:
HTTP要做到安全,两条路:
1、加密通讯隧道本身
这种就是SSL
1.1: 相当于是有身份证
2、加密通讯信息:
2.1: 这个做法是防止不了篡改的。
2.1.1: 无法确定请求的目标主机,是否真的是那台,不然就可能是肉鸡。
2.1.2: 无法确定返回请求的是否真实的客户端,这样就可能是假的客户端。(配合肉鸡,使得服务器也发现不了。
总结就是无法确认通信的双方。
2020-04-04 20:10:18:
比如设计一个汽车:
汽车--》车身(就是车的framework)--》底盘(bottom) --》 轮胎(wheel)
如果这样设计,car = new Car()
如果我需要改变轮胎大小呢?就需要 car = new Car(wheel_size=20),然后不断传递下去。。。就会经历很多层。这个做法叫做下层控制上层。
怎么处理呢?
1. 其实是new Car的时候,需要传入更多的参数,就是用DI的思想。
size = 40 wheel = new Wheel(40) bottom = new Bottom(wheel) framework = new Framework(bottom) car = new Car(framework)
这样更改大小,就需要更改wheel类而已。
2. 当然还可以用getter、setter
IOC container: 就是把上面new的过程,用xml写好,后面写文件直接生成。这样后面的人写代码的时候,不需要知道这个service具体是怎么创建的,只需要知道他的config就ok了。
2020-03-31 00:54:25:
1、go mod init github.com/vinsia/fly
2、using ./script/setup.sh
#!/bin/bash export GOPROXY=https://goproxy.io export GO111MODULE=on # please make sure running this script using ./script/setup.sh go run main-server/web-crawler.go
2020-03-30 16:11:51:
1、std::unique_ptr 解决的问题就是防止两个地方指向同一个内存,然后主动析构就GG了,如果不析构,内存又一直在。std::unique_ptr禁止使用=符号,每次移动都要用std::move,然后原来那个就失败了。
2、std::shared_ptr 就是用引用计数然后释放内存。
3、
拷贝构造函数
Person(const Person& p) = delete;
2020-03-29 12:03:57:
npm不支持socks5代理,但是有一个工具可以把http代理转发到socks代理。
2020-03-28 01:58:41:
如果某个网站有些按钮登陆不上,比如google登陆账号登陆不上,按next没反应。
可以试试关掉vpn,改变dns。
2020-03-08 17:39:53:
ulimit -a
1. 系统设置的最大fd数量会影响并发数。
2. nginx作为http服务器最大并发是, min(work_connections, linux_max_fd) * process_num,但是作为反向服务器要除以2,因为作为upstream的它需要和后台建立连接,会消耗多一个。
3. nginx怎么处理:“抢了连接,但是其实这个进程是没时间处理他的呢”? 1/8 * used - free,值越大,就不抢,同时值 -1, 为了以后抢。
4. 确认长连接:
而http请求是请求应答式的,如果我们能知道每个请求头与响应体的长度,那么我们是可以在一个连接上面执行多个请求的,这就是所谓的长连接,但前提条件是我们先得确定请求头与响应体的长度。
5. lingering_timeout: nginx close的时候,先关闭写,再关闭读。等待一段时间,就继续关闭读。因为怕别人还没读,不能立马关闭。
2020-02-26 23:01:16:
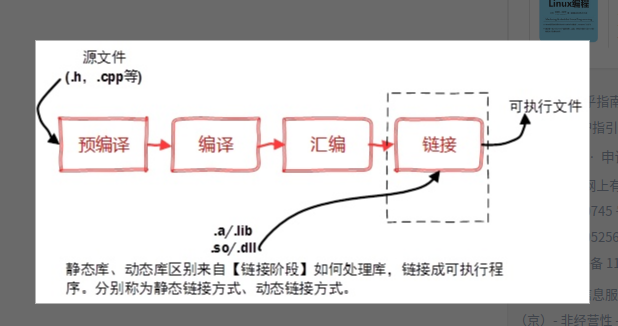
1. 选项 -c 用来告诉编译器编译源代码但不要执行链接,输出结果为对象文件。 输出为: xx.o
2. g++ --std=c++11 main.cpp -o main得到的就是main一个可执行文件,如果不加-o,得到的就是a.out这个可执行文件。
3. 所谓静态编译,就是将 xx.a 和 目标文件一起连接打入到可执行文件中。使用ar工具,可以编译出静态库。
静态编译的弊端:
1. 文件大。银盘要的大
2. 全量更新。
2020-02-26 17:51:30:
查看一个函数是否协程:
import inspect
if inspect.isgeneratorfunction(func):
2020-02-13 11:55:26:
59.43是CN2路线
2020-02-12 21:34:01:
DHCP(动态主机配置协议):
1. 就是一台机器维护一段IP,客户端登录一下就能获得自己的IP地址和子网掩码。类似于docker的deamon,控制container的ip。
2020-02-12 16:50:35:
神坑的crontab,读取的环境变量是读/etc/enviroment里面的,这个是系统级别的环境变量,比如你还没登录用户的时候,显示的是英文还是中文的欢迎界面呢,就是这个决定的。
2020-2-9 22:57:41:
1、HTTP的TCP的连接什么时候会断开?HTTP1.0默认对开,服务器可以设置connection: keep-alive,初始化连接+ssl开销消失了,证明是同一个TCP连接。HTTP1.1默认开启,除非header中明确connection:close.
2、一个TCP连接可以对应多少个HTTP请求?多个。
3、单个TCP连接可以同时发送多少个请求呢?HTTP1.1中只能一个。一个request一个response,虽然有piplining试图解决(发送多个,不等待返回,服务器按顺序返回),但是浏览器关闭的。因为有很多问题:
3.1、proxy不能正确处理。
3.2、正确的流水线实现是复杂的。
但是HTTP2.0提供了multiplexing,可以做到。
4、为什么有时候刷新不需要建立ssl。TCP会被维持一段时间。
5、浏览器对同一个host建立的TCP连接,有没有限制。chrome限制6个。
6、返回的HTML里面的图片是怎么下载的,什么协议,什么顺序,建立了多少连接。
6.1、如果是https的话,先ssl,然后鞋上是否能使用HTTP2.0,否则就用HTTP1.1,连接数量取决于浏览器。
2020-02-05 19:05:59:
How to write hard to test code.
1、单例模式,global state。
2、太多静态方法。This can not be overwritten.
4、doing work in the constructor is bad, 因为他不能重写
5、不要在类中new其他类的实例,使用依赖注入,不然很难做单元测试。比如传入一个证书去new一个client,我传一个证书入去,里面new,就很不好了。因为我想做的是直接mock那个client。
2020-01-21 13:36:42:
访问网站时:
1、如果浏览器配置hsts,就默认https,用来防止攻击。
2、首先访问http,看看返回头有没hsts和重定向。
2020-01-18 14:20:29:
1、timeout
2、retry
3、exception
4、logging.
5、module communication
2020-01-16 21:20:23:
1、stateless or 原子。尽量不要改class的静态成员。
2、操作数据库one by one。如果需要一次更改很多个东西的,考虑抽成一张表。
3、操作exception的时候慎重。
2020-01-04 11:37:38:
2、
2020-01-02 14:59:21:
1>/proc/1/fd/1 2>&1
可以解释为stdout输出去了/proc/1/fd/1文件,stderr紧随其后给了stdout
但是:2>&1 1>/proc/1/fd/1 是不行的。
因为1>/proc/1/fd/1是把标准输出搞去文件哪里了。`2>&1`相当于复制了标准输出的行为,但是这个时候标准输出还是在终端,没有拷贝到。先改(\)后复制(\\)。而不是,先复制(/),后改(/\)
tricket方法:
1、&>/proc/1/fd/1,就是把stdout和stderr都搞去哪里了,就不用管顺序。
2、2>&1 1>&/proc/1/fd/1,其实也是,为什么不加&呢。这样也不用官顺序。
2019-12-31 20:24:38:
1、SSH的原理和HTTPS不同,HTTPS通过证书信任机制来确保安全。SSH只能自己信任验证。叫做口令登录。
2、过程:
2.1、口令登录:远程主机把他的公钥发过来,口令登录信任风险后,添加到know_host,下次验证可以跳过口令登录,直接输密码。用远程主机的公钥保护住你的密码,实现的登录。
2.2、公钥登录:把自己的公钥给远程主机,连接的时候远程主机发一个随机串给本机,本机用私钥发回去,远程用我们的公钥解密,如果一样,登录成功。这样就免密码了。
github的登录,用ssh就是可以免去了密码来认证你这个用户,https做不到,但是如果有二次验证,就还是需要一直输入二次验证的code。方法是一个access token解决问题。
HTTPS = HTTP + 认证 + 加密 + 完整性保护。
公开秘钥: 就是一个公钥,一个私钥的。
共享秘钥: 就是一个token
3、HTTPS其实和SSH差一步,就是SSH给过来的公开秘钥,我怎么证明他是真的是他呢?不然又会有中间人劫持了,这一步就是认证,公开秘钥是解决了通信加密问题。怎么认证呢,用证书。
服务器会发送:服务器的公开秘钥 + CA(就是用权威机构的秘钥来加密服务器公钥的一个东西),然后客户端用CA的公钥来解开服务器的公开秘钥,判断是否相等。中间人能攻击吗?可以的。
步骤就是:(首先对于域名做的证书,应该是全球唯一的
1、我自签一个证书给这个域名。
2、chrome是会调用系统的证书的,我安装这个软件的时候,安装这个证书。
这样访问 global:zhihu.com --> my:zhihu.com,chrome还是不会报错。
这叫劫持根证书。
客户端就没必要SSLL:
1、每个客户端就用不同证书的,麻烦 + 不是人人都会。
2、如果我拿到这个证书,那就无敌了。(图解HTTP P159)
2019-12-25 11:19:26:
1. 使用adduser,不要用useradd
3. 添加用户去sudo组。usermod -aG sudo vimi
2. 更改密码
2.1 在当前用户下使用passwd更改密码,需要输入原来密码。
2.2 在当前用户下使用sudo passwd vimi更改密码,不需要输入原来密码。
2.3 在root用户下使用passwd vimi更改密码,直接输入新密码。
2019-12-24 15:25:34:
linux希望多进程,进程间通信。
1、很多工具需要用多进程,比较编译,但是windows对于多进程支持十分不好。
UbuntuLinux:耗时 0.8 秒
Windows7:耗时 79.8 秒
2、服务器,某些服务器框架依靠大量创建进程来干活,甚至是对每个用户请求就创建一个进程。
3、现在的多核心,如果多线程,线程之间的数据共享。资源必须从一个核心搬去另一个,这里消耗了。
2019-12-22 10:57:10:
操作系统为什么要有用户态和内核态:
答案是为了安全,计算机就五个基本组成模块,输入设备、输出设备,计算器,控制器,存取器。
其中只有存取器是有状态而言,其他都是直接读取存取器拿值然后工作的,所以能改变存取器就是可以改变计算机的运行状态。这个东西不能随便让人改。
进入内核态的条件:
1、系统调用。
2、中断。
3、异常。
2019-12-22 02:07:14:
1、避免线程切换带来的的大额开销。效率对比
1.1、省了进入内核态,但是进入内核态一般是200ns,线程的上下文切换是3-5us,所以上下文切换还是大头。对于无栈,就没有上下文切换,对于有栈,还是有协程的上下文切换的。
1.2、golang的协程上下文切换,仅需120ns,比进入内核态还低。详情见上面连接。是普通线程切换的1/30,因为协程需要的栈才2KB,但是线程需要的会去到10MB,why?
2、把异步的逻辑同步化。
协程:
无栈:(async,await)
这种是完全是用户态调度,需要一协全协,对于老代码,根本上就是重构。但是无须存储上下文,所以不需要栈,减少消耗。(yield出去的时候相当于在哪里变成调用其他函数)
有栈:(golang)
比线程开销少(TODO:WHY)。
有栈协成还分为用户调度,还是语言上就有了调度器(golang)
1、如果语言上有了调度器,用起来就和线程差不多。这样就是异步的操作了,怎么写成同步化呢?用channel通信就可以。
2、如果没,用起来就和async,await一样。还是要自己yeild,这是何苦呢,就是省了进入内核态?
很多服务都是:
1、高并发。
2、重IO,mysql和redis,或者network
3、低计算。
4、需要延迟低。每个用户处理耗时越短越好,经常是ms级别的
没有协程之前,就用异步非阻塞 + callback来实现高并发。 但是这种对于开发人员非常不友好。
2019-12-03 10:47:45:
RLock只是说单个线程可以重复拿锁,其他和lock没其他不同
2019-12-02 20:06:36:
是所有logs都是放去stderr的。
docker logs -f 默认输出到标准错误,然后用管道 + grep是不行的,因为管道默认是拿程序的标准输出作为自己的标准输入。
可以这样,docker logs -f vc-server 2>&1 | grep -i -E 'insert'
2019-11-29 17:21:34:
定时器实现方案:
1、while True, 然后time.sleep,什么线程都不用。这样有个问题就是如果做两个任务,是无法保证他是定时1s的,因为上一个任务执行也要时间。
2、用py的timer,每个都开一个线程,怎么控制关闭和线程池呢。
3、schedule 配合 BoundedSemaphore
2019-11-28 16:31:02:
如果要上传一些数据给别人的服务,那么我们要怎么设计。
1、原有的服务(数据来源),加一个接口,然后设置一个agent定时读。
2、原有的服务(数据来源),然后设置一个agent定时读原有数据的db。
3、最差的设计,设置一个新的服务,在原有的数据服务中,有更新就post过去新的服务。因为本来的服务不应该知道有其他服务的存在。又不是新的微服务。这样设计耦合太大了。
but 第一和第二的设计写起来没第三种方便。实时性应该也没那么好,也耗cpu?其实web服务怎么知道请求来了呢,中断?
其实第一第二种也不是实时性没那么好,是微服务设置错了,应该做成推送的形式,而不是轮训。比如comet延迟回答(但是需要占用一个handler,websocket不用?)
2019-11-25 21:42:41:
redis的cache,原本是更新数据库,删除redis。下次就能直接得到最新的。现在问题是更新数据库后redis没删除成功怎么办。为redis数据加一个过期时间。(hit:是不是什么都应该加一个时间?)
2019-11-22 21:49:18:
1、互斥
2、可重入(同一个线程可以多次得到这个锁),这个用+1,-1
3、锁超时
4、高效,高可用。
5、支持阻塞,非阻塞
6、支持公平、非公平。
2019-11-21 00:18:22:
步骤是:
slam:
1.客户端访问server,server重定向去idp。
2.客户端去新页面填写用户密码,按一下会去idp得到token,然后其实在新页面会带着一个token访问server。这个时候server又叫你redirect回去一开始的页面。
这里也可以选择redirect,但是redirect的url限制比较多,不能太长,放不下token。(redirect后可以用js的路由,在原来的页面做同样的事情,其实就是拿着token去server登录。)
bug1,app端不能够这样做,因为app离开程序,去了自带流浪器里面,
虽然 POST 的 url 可以拉起应用,但是手机应用无法解析 POST 的内容,我们也就无法读取 SAML Token
这个时候只能写一个in app的页面嵌套了。
sso:
1.客户端访问server,server重定向去idp
2.客户端去新页面填写密码,得到code,然后redirect回去client。因为是code,所以可以redirect。
3.客户端再去server根据code拿token,server会给他assess_token和refresh_token.
4.后面客户端就可以搞事情了。
因为是code,解决了app的问题。就是redirect的时候,那个url的schema可以自己定义,手机可以解析到那段url。
3、Authentication(身份验证,也就是验证)、Authorisation(授权)
3.1、认证:验证你是否是合法用户。
3.2、授权:决定你有那些权限,是否可以访问yyy资源。
2019-11-13 22:04:57:
1、mysql如果一次锁多行,并不是原子的。所以如果有两个事物一起进入锁多行,就会GG。所以在design的时候不能不能让后台update list。要设计好,让粒度改成单个。粒度只能是单个。delete和like不知道,反正select list for update 有bug。
2、user_tag设计,要设计去另外一个表,然后user表存这个表的id:如果直接存在user表,有问题,
2.1 怎么判重,要先把所有user_tag选出来,还要锁表,不然的话请求1过来判断不存在,请求2也判断不存在,然后在同一个用户add了两个相同的tag name了。
2.2 如果新开一个表,就直接判,不用加锁。。不过要在tag_name加上Unique Key
3、mysql什么时候用for update:
3.1 好像如果是直接update User set name = 'vimi' where id = input_id 这种,select出来无须for update吧,而且他根本不需要select啊。
3.2 其他的,判断机器状态(或者其他字段是否为xxx的),需要用for update
2019-11-12 18:01:25:
前端get请求传数组:
1、a=1,2,3 这种后台难处理。前端容易。
2、a=1&a=2&a=3, 据说后台天然能适应。(这个还是有点看语言)
3、protobuf,最好拉。
2019-11-09 15:51:46:
mysql改了时区,需要重新连接。也就是要重启server.
所以,假如mysql有时区。
1、mysql改了时区,重新链接,server收到的结果会变,时区是+8,就会+8。这个是根据trip的时间,本来utc创建的trip,改了后 + 8小时了。
这是因为,mysql拿的结果本来就是CST,然后给这个timestamp前端,前端又转了一次。所以+8.
2、mysql改了时区,重新链接,新写进去的还是utc,用了datetime.datetime.utcfromtimestamp(),然后再根据mysql里面的时区,再转了一下。相当于UTC再减去了8
这个和mysqldump出来的数据不同,mysqldump出来的数据是不带时区的,再restorage也是不带时区的,因为在dump出来的文件里面已经提前设置好了time_zone 是00:00的。
mysqldump可以设置不用UTC,默认都是用UTC的。--skip-tz-utc
3、time_update有点问题,用了server_default, func.now(),用的应该是中国时区????。
4、mysqldump有点厉害,没改时区前的数据,他会正确根据以前的时区转回去UTC,改了的那些,他也会根据改了的时区,转回去UTC。注意time_update,搞不懂。又没事了
2019-11-04 09:49:19:
mock in frontend
async getVehicleUsage() { const sleep = (second) => new Promise((resolve, reject) => { setTimeout(() => { resolve(new VehicleUsages()); }, second); }); const response = await sleep(2000); return await response; }
2019-11-03 01:06:11:
沐足+https
要解决http带来的问题,就要引入加密(非对称加密)以及身份验证机制(证书机制)。
过程:
1、服务器证明自己是可靠的。其实这个是建立链接的时候,服务器要给一个公开秘钥我们,但是怎么证明这个公开秘钥是对的呢,就是怎么证明这个公开秘钥就是那个服务器的,就需要证书认证。同理客户端给服务器的。图解HTTP P156
1.1 服务器告诉客户端 我是xxx(比如s1是我的师傅)
1.2 客户端找到s1并且确认,就认为服务器可靠。
1.3 如果s1说不认识,那么就去找s1的师傅s2,一直找到root,只要有一个能证明服务器是正确的,就可以信任。
这些s1和s1的师傅s2是什么呢,就是权威机构的公开秘钥,怎么找到呢,一般植入浏览器,为什么要植入呢,因为如果你通过网路传输,又陷入死循环,就是我怎么证明他是权威的呢。没有被黑客入侵呢。p156
2、信任后,得到
2019-10-27 23:54:14:
同步、异步:说的是后台方面的,异步相当于带提醒功能的水壶,同步不带。
阻塞、非阻塞:说的是客户端方面的,选择等待水开,还是水开提醒你(就算是同步的后台,也可以用非租塞,定时去看就行了)
Java三种IO模型:
BIO:同步阻塞IO
NIO:同步非阻塞IO
AIO:异步非阻塞IO
2019-10-22 13:22:48:【TODO】
时区,都是应用层面上的东西,后台mysql肯定要存一个无时区的东西,backend应用也不应该有时区这个概念,应该相信app给你的肯定是UTC,就按UTC存。不然的话,前端给你一个timestamp,后台一转成date对象(date对象方便用)就GG了,因为转的时候又会根据你的时区 +- 8,前端应该清楚考虑时区问题。
2019-10-21 23:14:26:
1、bridge模式,普通的一种模式。在docker0中分配一个子网给container,veth pair,一端放去container里面,一端放去主机中,实现通信。docker实际是在iptables做了DNAT规则,实现端口转发功能。可以使用iptables -t nat -vnL查看。
2、host模式,直接和eth0共用网段。不生成多余的网卡。
3、container模式,容器b join去容器a,他们两个通过lo网卡通信,也是生成一个veth pair。
4、none模式,什么都没有的模式。container里面没有网卡、ip、路由等信息,需要自己配置,适合用来做离线任务。
5、
2019-10-15 16:28:55:
改东西需要先加proto,等两边合完了,再做需求。不然的话有个问题:
1、先不考虑用很旧很旧的binary的问题。
2、可能用了release,然后后台上了,还是用了旧的release,就会解析不成功。因为这个时候binary已经定死了的。
思考:
1、兼容?如果别人用旧的binary中,proto不对,也可以兼容。这样的话是可以的。【现在是因为text_format没有设置ignore_unknown_field.
2、fail了他,这个应该比较好,提示用户应该怎么改。
2019-10-12 11:10:02:
关于前端验证,见下文。
思考:如果一个应用依赖的服务突然不行了,debug方法:
1、ping那个服务,看看是否能ping通。
1.1 如果没有显示ip,证明本地的dns服务都不行了,是本地的问题。这个时候,不能断定应用出bug,因为可能应用像浏览器一样cache了,所以可能应用正常的。
1.2 如果有ip,但是ping不通,那是服务的问题,但是还是不能证明本地没问题,因为可能应用cache了一个旧的ip,一直访问他,
1.3 如果能ping通,就是本地应用问题了。可能cache了ip
2019-10-09 15:13:30:
protobuf定义的时候不要使用复数,因为转去其他语言的时候是不确定的,有可能是xxxList的(比如js),那就回usersList.
2019-10-09 13:49:43:
一开始从db找出所有active的东西,返回第一个active的并且更改为assign,那肯定不希望锁全部啊。所以第一次select不会锁。
希望的是for一次,然后重新select,这个时候for update,看看那个东西是不是还是active,如果还是active的,就是他了,更改他。
但是这个是有bug的,因为在第三种模式,可重复读下,再次select,其实结果是一样的。需要先commit上一个事务。在python里面就是Database.refresh(xxx, with_for_update=True)
错了,即使在第三种模式下,select * for update还是会读到最新的。
2019-10-09 13:48:034:
https://superuser.com/questions/1490269/http-response-time/1490356#1490356
curl -I 只是读取头部
所有语言的http库,response回来只是说头部第一字节回来,或者body第一字节回来,并不是所有body都回来了。如果所有body都回来的话就需要很大内存,是一开始握手的时候协商好size_window,然后雍塞控制。
2019-10-08 19:00:56:
mainService {
LoginService;
InitService;
MessageService;
}
主service中有很多sub-service的问题,问题是如果每个sub-service都是自己管自己,这样他们就不能和其他service通信。和调用。解决方法:
1、使用context, 在主service上有一个全局的context
2、sub-service应该是有input output并且stateless, 【比较推荐】
3、context的话有个问题,就是怎么和mainServiceTwo通信,这个时候需要用接口。
2019-10-08 18:30:25:
找出文件行数 >= 300的 find . -iname "*" | xargs wc -l *.py | awk '$1>=300 {print $1, $2, NR}' | grep -v wc
2019-09-30 15:58:44:
防抖(debounce)
1. search搜索联想,用户在不断输入值时,用防抖来节约请求资源。
2.window触发resize的时候,不断的调整浏览器窗口大小会不断的触发这个事件,用防抖来让其只触发一次
节流(throttle)
1.鼠标不断点击触发,mousedown(单位时间内只触发一次)
2.监听滚动事件,比如是否滑到底部自动加载更多,用throttle来判断
2019-09-29 22:06:57:
go channel,为什么说go有channel是好的呢?就是说他在语言层面实现了一个消费队列,channel里面是自带锁机制,里面也保存了那一个goruntime调用了这个channel,所以挂起的时候,再复活就会通知其他channel起来。
其实就是语言层面上支持了kfaka做的东西。
不要随便定义type,if err == typeA,这样会麻烦会造成循环引用。。 应用判断他是什么属性,而不是判断他是否什么。。。if err.isTypeA()
2019-09-29 11:18:15:
是这样的 null是一个value undefined的意思是没有value
js主要是要处理后端数据 后端数据里面的null在前端就是一个value 为了和自己的没有value做区分 所以发明了这个东西
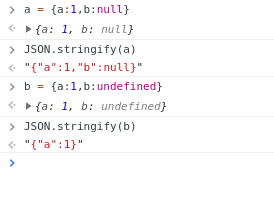
bug:
比如后端要求你给我post,{a:any,b:any} 我就给你返回{a:value, b:value},{a:any} 我就给你返回{a:value}
2019-09-29 09:29:42:
关于时间戳,UTC时间戳单位是秒的,如果想用时间戳做服务器自增id,需要用到微妙级别的时间戳,比如python中的 int(time.time() * 1000000),不然一个for循环一次生成多个会重复。
1:IOS端最多处理10位的时间戳(也就是秒级别。
然后据说没有网络,时间戳会有点变化?因为不能同步时间。
2019-09-26 16:13:23:
坑:需要默认显示用户已经输入的东西,就需要有inputValue={previous}等,然后这样的话,每个change都要render一次,不然用户的那个对象还是哪里,前端就一直显示不变。
2019-08-26 14:04:28:
同源定义:需要 协议 + 域名 + 端口号 相同
跨域都是流浪器帮忙的限制,后台需要加上,好像还需要加上vary: Origin.
Access-order-allow: * 好像已经被禁止了,说这样太多了。
流浪器上确实需要限制跨域请求。原因有二:
1、从DOM角度说,用了iframe去调用了其他网站的页面,如果没限制,就可以控制它的DOM,然后用户输入密码的时候,就可以get到了。Document.getElementById之类的。
2、从cookies角度说,流浪器会自动帮我们发送cookies的,那么访问A网站后有了cookies,再访问B网站,难道发送A网站的cookies过去?B网站随便做一层转去A网站,就相当于你访问了A网站.
def parse_access(allow_origin = "*", allow_methods = "PUT,GET,POST,DELETE,OPTIONS", allow_headers = "Referer,Accept,Origin,User-Agent,Content-Type"): def decorator(func): @functools.wraps(func) def wrapper_func(*args, **kwargs): resp = make_response(func(*args, **kwargs)) resp.headers['Access-Control-Allow-Origin'] = request.headers.get('Origin') resp.headers['Access-Control-Allow-Methods'] = allow_methods resp.headers['Access-Control-Allow-Headers'] = allow_headers resp.headers['Access-Control-Allow-Credentials'] = "true" # allow send cookies return resp return wrapper_func return decorator
坑点,由于分为简单请求和非简单请求,非简单需要发送options请求,所以需要确保后台实现了options请求。。。
注意,所有的这些东西,都是流浪器搞得,直接用curl是没问题的。
2019-08-22 17:36:58:
new Date(1568822212221) Wed Sep 18 2019 23:56:52 GMT+0800 (China Standard Time) {} ms: 13位。
2019-08-17 23:47:39:
在proto里面的字段
发送有,解析没有的都是可以的,是可以理解的,因为是根据 名字的id来判断的。不要随便改id。
要验证的话,不能单单反序列化出来可以了就行,需要序列化,看看能不能。
optaional:
1、发送有,解析没有 : 可以的。
2、发送没,解析有 : 可以的,只是没有哪一列的值。
required:
1、发送有,解析没有 : 可以的,就是没有了那个required哪行。
2、发送没,解析有 : 不行,required的不必须有。
2019-08-14 15:01:47:
不能依赖前端做URL校验吧,需求是在前端就判断这个东西在不在本地的storage server上面,因为api server只有一个,所以如果把这个url放去api server上面验证,就不知道是广州还是北京的请求,从而无法校验。
所以思路就是在前端判断嘛,因为前端的dns server解析到的肯定是本地的路径。但是有如下三个问题:
1、前端流浪器dns缓存?比如我北京的人,来了广州出差,以前访问的网站会不会已经被流浪器缓存着了,所以这个时候检验就失败了。(广州的用了北京的校验)
(上面那个是不会的,1、关闭流浪器,cache就消失。2、同事一去到广州连接上网咯,路由表就会被更新,dns服务器配置也会被更新)
2、linux里面的dns服务器被改了,这个时候同理。(这个是有可能的)
3、其他服务的dns被改了,去了其他地方下载(虽然这个东西有点少出现)
2019-08-10 00:27:58:
写alembic的时候不能使用orm,因为这样和model层就强绑定了,或者你不要全部列都select出来,不然以后别人加多一列(应该是你这个orm用了一些列,但是这些列被delete了,特别是那些xxx_old那些临时咧),这个alembic直接跑不了 。
2019-08-04 12:44:24:(系统会主动告诉你的)
IO多路复用就是提供epoll那些o1监听时间变化,读的时候还是需要使用非阻塞IO,就是read的时候加一些参数的,没有就返回error_code,因为epoll通知你有东西读了,但是,可能被其他人读了(指针搞走了?)或者系统已经废弃。
2019-08-02 14:44:02:
函数curry化 https://llh911001.gitbooks.io/mostly-adequate-guide-chinese/content/ch4.html,regionEnumToRegionName这些,很好用。
2019-08-02 13:48:40:
写东西需要兼容,比如proto的cache,如果proto格式改了怎么办?try catch,不符合也不能蹦。
2019-07-29 22:34:54:
HTTP一个从1.0 --- 2.0的过程其实是越来越二进制化了,HTTP2.0的头部都是用bitstring
2019-07-29 22:32:35:
有时候dockerfile里面创建文件夹不能带有 '%'或者其他字符,或者不能使用 `source ~/.zshrc`,那是因为dockerfile里面默认使用 '/bin/sh',可以使用RUN ["/bin/bash", "-c", "mkdir -p aaa/ttt/222%aaa"]来代替
但是还是创建不了带有 %的,然后试过创建一个假的,然后mv成带有%的,还是不行。。。结果是把它改成用 ln软链接过去改名,就ok了。
2019-07-26 19:57:10:
https://dev.mysql.com/doc/refman/8.0/en/innodb-locking.html
share lock:锁行的,保证读正确 select ... for share
exclusive lock: 锁行的,保证写和删正确。 TODO(新增怎么保证?新增算不存在的行,怎么锁) select ... for update.
①、意图锁,intention locks: 是一种表的lock,分为is,ix。表的共享和排它锁。会为每一行加上s、x。他只用来表明这个表有人用锁了(锁了一行还是xxx),不是真正的锁。以后别人判断这个表是否存在一行被锁了,快一点。
②、记录锁,Record Locks:这个是用来锁索引的,官方说防止别人更改了那一个值(select where id = xxxx),才出现的。注意的是:假如那个东西不存在索引,官方有一个默认索引给他。让他锁着。
③、gap locks,就是一个范围锁,别人用了 select between 10..20,不让别人插入。如果有unique index,就不用gap locks
④、Next-Key Locks,record lock + gap lock,把数据库的东西连成一段一段来锁。
⑤、Insert Intention Locks,插入意向锁,用来两个事务同时插入,但是只要主键不冲突就可以插入的。
⑥、AUTO-INC Locks,这个是一个表锁,所以这样插入数据会使得表锁了。
2019-07-25 20:16:17:
创建子进程要为他创建一个特别的pgid,这样就可以删除这个子进程的时候,把所有他可能生成出来的进程也杀掉,就不会有孤儿进程了。
2019-07-24 17:50:01:
如果新加功能,参数不搞默认值,就很容易有坑了。。xxx can not be null.
2019-07-23 19:50:10:
> select trip_id from detail where task_type='UPLOAD' and host='data-uploader-letianyungu-001' limit 1; 这样不行的? 因为用了单引号,以后和cpp统一,能用双引号的就用双引号
2019-07-15 16:27:28:不要使用email作为判断用户的标识,因为这样在设计URL的时候很麻烦。因为restful是这样设计,但是url上不能有@,(虽然有也是可以但是不推荐),所以这样就gg了。
因为前端输入一个邮箱+密码作为用户,发起http请求的时候又要截断?这样不方便,后端也要做兼容本来就是email详细地址的url、
http://api.example.com/device-management/managed-devices
http://api.example.com/device-management/managed-devices/{device-id}
http://api.example.com/user-management/users/
http://api.example.com/user-management/users/{id}
2019-07-11 19:12:47:如果你有一堆time.time()这样的timestamp,但是在grafra这样的东西里面转换成时间的时候不成功,可以考虑下是单位错了,有些东西是接受ms的,所以需要*1000
另外,转换出来的时间应该是1971..年左右,可以用来debug
1、proxychains
sudo apt-get install proxychains
sudo vim /etc/proxychains.conf
# proxychains.conf VER 3.1 # # HTTP, SOCKS4, SOCKS5 tunneling proxifier with DNS. # # The option below identifies how the ProxyList is treated. # only one option should be uncommented at time, # otherwise the last appearing option will be accepted # #dynamic_chain # # Dynamic - Each connection will be done via chained proxies # all proxies chained in the order as they appear in the list # at least one proxy must be online to play in chain # (dead proxies are skipped) # otherwise EINTR is returned to the app # dynamic_chain # # Strict - Each connection will be done via chained proxies # all proxies chained in the order as they appear in the list # all proxies must be online to play in chain # otherwise EINTR is returned to the app # #random_chain # # Random - Each connection will be done via random proxy # (or proxy chain, see chain_len) from the list. # this option is good to test your IDS :) # Make sense only if random_chain #chain_len = 2 # Quiet mode (no output from library) #quiet_mode # Proxy DNS requests - no leak for DNS data proxy_dns 8.8.8.8 # Some timeouts in milliseconds tcp_read_time_out 15000 tcp_connect_time_out 8000 # ProxyList format # type host port [user pass] # (values separated by 'tab' or 'blank') # # # Examples: # # socks5 192.168.67.78 1080 lamer secret # http 192.168.89.3 8080 justu hidden # socks4 192.168.1.49 1080 # http 192.168.39.93 8080 # # # proxy types: http, socks4, socks5 # ( auth types supported: "basic"-http "user/pass"-socks ) # [ProxyList] # defaults set to "tor" socks5 127.0.0.1 1080
记得,最后面的那个socks5,不能写成 --> SOCKS5
2、
docker 的 COPY ./app /tmp/ 然后去到里面是/tmp/....里面都是app下面的内容
linux 的 cp ./app /tmp/ 去到里面就是/tmp/app
3、
前端的
let value of arr,只能用在arr,不能用object,然后取出的是arr元素的值。不是idx
setTimeout 后来发现setTimeout的第一个参数必须是需要编译的代码或者是一个函数方法,而如果直接传入一行可执行代码,那么抱歉,这里会立即执行,没有延迟效果。
4、数据库表如果用了user_id的,另外一个blog表不要用user_id,因为要很多都是根据username,userid不外放,每次查来查去,直接用username
5、js中的print()是打印的意思。
6、mysql中的mysqldump,会把原来的sql文件中有
`comment` text NOT NULL DEFAULT '',
他导出来,后面的DEFAULT就会不见了的。
-- MySQL dump 10.13 Distrib 5.7.11, for Linux (x86_64) -- -- Host: 127.0.0.1 Database: dev -- ------------------------------------------------------ -- Server version 5.7.24 /*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */; /*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */; /*!40101 SET NAMES utf8 */; /*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */; /*!40103 SET TIME_ZONE='+00:00' */; /*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */; /*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */; /*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */; /*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */; -- -- Table structure for table `blog` -- DROP TABLE IF EXISTS `blog`; /*!40101 SET @saved_cs_client = @@character_set_client */; /*!40101 SET character_set_client = utf8 */; CREATE TABLE `blog` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_blog_id` int(11) NOT NULL, `user_id` int(11) NOT NULL, `title` json DEFAULT NULL, `content` json DEFAULT NULL, `love` int(11) NOT NULL DEFAULT '0', `comment` text NOT NULL DEFAULT '', `create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`), KEY `USERBLOGID_TO_BLOG` (`user_blog_id`) ) ENGINE=InnoDB AUTO_INCREMENT=29 DEFAULT CHARSET=utf8; /*!40101 SET character_set_client = @saved_cs_client */; -- -- Table structure for table `comment` -- DROP TABLE IF EXISTS `comment`; /*!40101 SET @saved_cs_client = @@character_set_client */; /*!40101 SET character_set_client = utf8 */; CREATE TABLE `comment` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` int(11) NOT NULL, `comment` json DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=52 DEFAULT CHARSET=utf8; /*!40101 SET character_set_client = @saved_cs_client */; -- -- Table structure for table `user` -- DROP TABLE IF EXISTS `user`; /*!40101 SET @saved_cs_client = @@character_set_client */; /*!40101 SET character_set_client = utf8 */; CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(20) DEFAULT NULL, `password` varchar(20) DEFAULT NULL, `avatar` mediumtext, PRIMARY KEY (`id`), KEY `USERNAME_TO_USERID` (`username`) ) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8; /*!40101 SET character_set_client = @saved_cs_client */; /*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */; /*!40101 SET SQL_MODE=@OLD_SQL_MODE */; /*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */; /*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */; /*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */; /*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */; /*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */; /*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */; -- Dump completed on 2019-01-31 21:21:53
8、js中的每一个文件可以有一个export default xxx = () => {},导入可以直接 import xxx from 'yyy.js'
其他的只能用 export const xxx = () => {},只能用这个箭头函数,导入需要 import {xxx} from 'yyy.js'
const 和 default不冲突
9、主动关闭的时候,自己出现Time_wait,会自己消失
所以过程是这样:
客户端发起关闭tcp <FIN>M请求,服务器进入CLOSE_WAIT状态,然后发送<ACK>M+1告诉客户端,我知道你关闭了,客户端进入FIN_WAIT_1,然后到
服务器发送关闭tcp <FIN>N请求,服务器进入LAST_ACK状态,客户端进如FIN_WAIT_2状态,发送<ACK>N+1给服务器,服务器进入CLOSED
客户端进入TIME_WAIT,过一段时间后自己消失。
10、js生成随机数用这个 window.crypto.getrandomvalues
11、写前端的定时器的话,要记得如果有其他界面铺在上面了,是不是考虑取消一下定时器。或者不做事情
12、materialui如果不能scroll,可以试试fullwidth后,也可以试试display: grid
13、mysql中表、字段都可以有字符集,而且target这些默认变量名就不能做字段名,不然desc不了这个table,还有mysql-client的时候也需要设置字符集去读取。--default-character-set=utf8
14、show CREATE TABLE User
15、Python3中使用mysql-db,
①、pip3 install --upgrade steuptools
②、sudo apt-get install libmysqlclient-dev
③、pip3 install mysqlclient
16、又一次,mysql用不了中文的话,其实是链接的时候那个url没写?charset=utf8
17、mysql终端输入不了中文的话,其实是那个环境变量没设置好,locale - LANG=C.UTF-8
17... ➜ ~ docker exec -it -e LANG=C.UTF-8 vc-mysql bash
18、python可以用[].extend()来添加一个list
19、js中,如果有定时任务,每次去fetch一下请求的,记得记得带上response id
function()
requestSeq += 1
const seq = requestSeq;
// api....doing....
if (responseSeq > seq) return;
responseSeq = seq;
20、暴露一个redis的connection,还要想到如果没连接上,那怎么办。可以考虑用get_set函数
21、
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import json from lxml import etree import requests from lib.re_util import ReUtil from common.lib.logger import log from models.douban.dianying import Dianying from request_client.base import BaseApi from .programming_config import cookies_str base_programming_url = 'https://medium.com/topic/programming' popular_in_programmer = '//*[@id="root"]/div/section/section[2]/div/div[9]' proxy = '127.0.0.1:1080' proxies = { 'http': 'socks5://' + proxy, 'https': 'socks5://' + proxy } class web_crawler_medium_programming(BaseApi): def __init__(self): super().__init__() @classmethod def get_cookies(cls): return cookies_str @classmethod def get_headers(cls): return None @classmethod def do(cls): response = cls.get('https://ip.cn/', proxies=proxies) print(response.text) # root = etree.HTML(response.text) # div_list_popluar = root.xpath(popular_in_programmer) # print(div_list_popluar)
22、sqlalchemy,事物级别:可重复读
session中,add了的,没commit,进程结束后没写入数据库
session中,同一个事物,add后,可以query出来
session中,可以query出来localhost链接insert的东西
session中,一定是commit才能结束一个事物,但是close的话,对象的方法都会用不了的。
23、chrome快捷键配置
1、想要删除联想的路径,可以移动到那个东西,然后shift + delete.
2、chrome://extensions/shortcuts 这里可以更改chrome extensions的快捷键。
24、zshrc中的东西,如果你写路径是这样的 file_path = '~/aaa/vimi',然后拼接路径 new_path = ${file_path}/new_path,这样cd ${new_path}是不行的,正确应该 file_path=~/aaaa/vimi,不加引号。
tcp 0 0 0.0.0.0:3000 0.0.0.0:* LISTEN 247/nc
tcp 0 0 0.0.0.0:3000 0.0.0.0:* LISTEN -
但是上面的方式会有一个问题,由于在锁住总线期间,其他CPU无法访问内存,导致效率低下。
yeild到epoll_wait中resume到一个协程
posted on 2019-01-05 18:09 stupid_one 阅读(1113) 评论(4) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号