

1952年——2021年人口结构基本情况分析
一、选题背景
新中国成立前期,由于国际局势紧张和斗争带来的影响,我国鼓励生育,后来由于人口的过快增长给社会经济发展带来了严重影响,我国从1970年开始实施计划生育,人口自然增长率开始下降,到现代由于老龄化危机和人口增长跟不上经济发展需求,中国逐步放开二胎政策(全面二胎)。由此可以看出,人口问题是影响我国经济发展的重要因素之一,因此有必要研究在新形势下人口结构的基本情况。所以本次课程设计根据相关统计数据分析我国1952年-2021年的人口结构状况。
二、设计方案
1、通过爬取国家数据分析不同年份的人口结构,主要爬取的目标信息有总人口数、男性人口、女性人口、城镇人口、乡村人口、人口出生率、人口死亡率、人口自然增长率、0-14岁人口、15-64岁人口、65岁及其以上人口、总抚养比、少儿抚养比、老年抚养比。
2、爬取数据后将数据清洗为自己需要的数据然后保存到Excel中,然后从Excel中提取数据通过Python绘制图像。
三、网页结构
https://data.stats.gov.cn/easyquery.htm?cn=C01
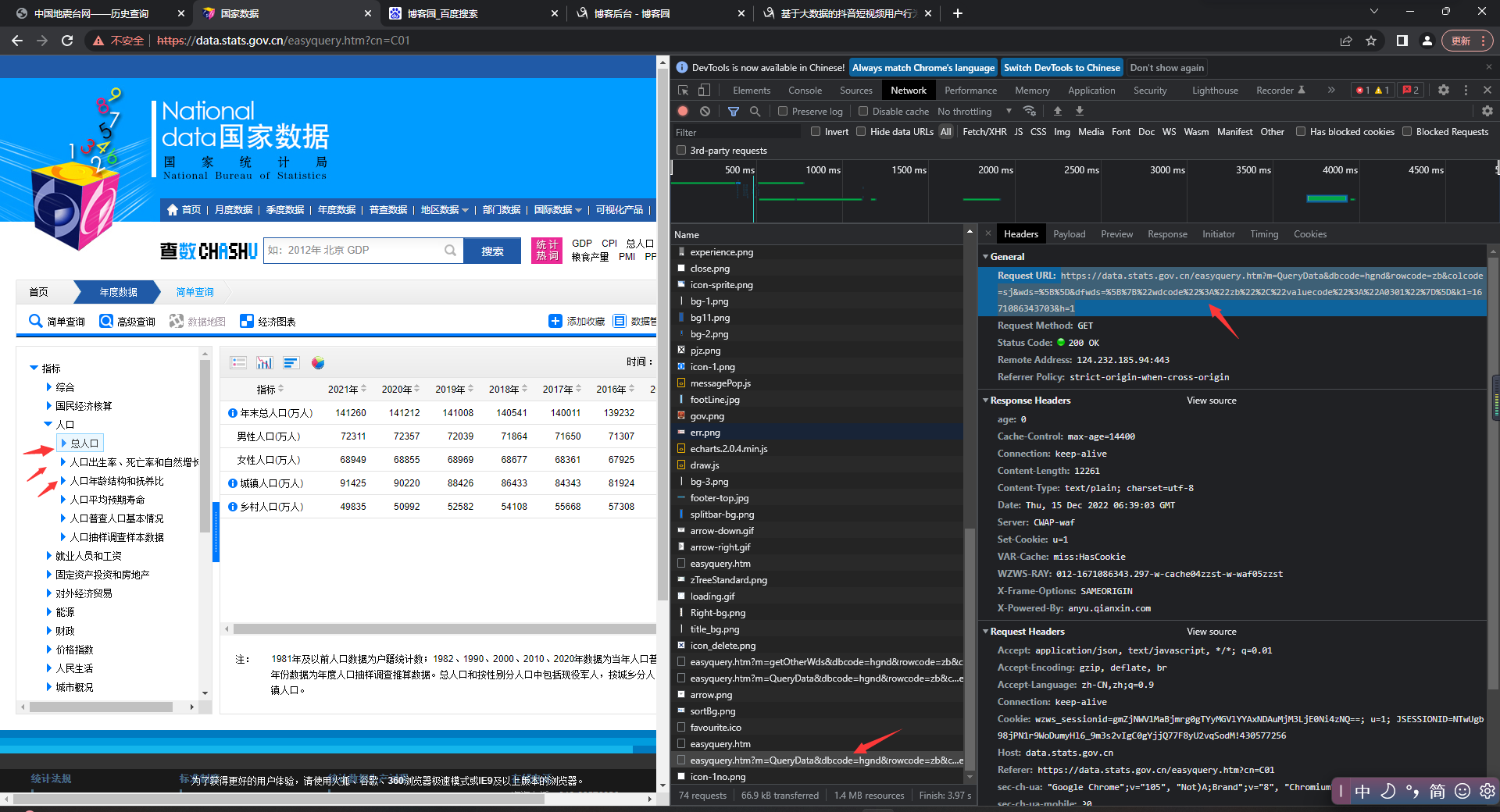
四、程序设计
1、获取1952——2021年的数据
def spider_population():
url = 'https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=zb&colcode=sj&wds=%5B%5D&dfwds=%5B%7B%22wdcode%22%3A%22zb%22%2C%22valuecode%22%3A%22A0301%22%7D%5D&k1=1670909912224&h=1'
response = requests.get(url,verify=False)
print(response.json())
spider_population()
def spider_population():
#获取近1952-2021年的人口信息
# 总人口
dfwds1 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0301"}]'
url = 'https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}'
response1 = requests.get(url.format(dfwds1),verify=False)
print(response1.json())
spider_population()
def spider_population():
dfwds1 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0301"}]'
# 增长率
dfwds2 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0302"}]'
# 人口结构
dfwds3 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0303"}]'
url = 'https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}'
response1 = requests.get(url.format(dfwds1),verify=False)
response2 = requests.get(url.format(dfwds2),verify=False)
response3 = requests.get(url.format(dfwds3),verify=False)
spider_population()
2、清洗数据保存到Excel中
import pandas as pd
import requests
# 人口数量excel文件保存路径
POPULATION_EXCEL_PATH = 'D:\\Users\\Rain\\Desktop\\python作业\\population.xlsx'
def spider_population():
"""
爬取人口数据
"""
# 请求参数 sj(时间),zb(指标)
# 总人口
dfwds1 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0301"}]'
# 增长率
dfwds2 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0302"}]'
# 人口结构
dfwds3 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0303"}]'
url = 'https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}'
# 将所有数据放这里,年份为key,值为各个指标值组成的list
# 因为 2019 年数据还没有列入到年度数据表里,所以根据统计局2019年经济报告中给出的人口数据计算得出
# 数据顺序为历年数据
population_dict = {
'2022': [2022, 141260, 72311, 68949, 91425, 49835, 10.48, 7.14, 3.34, 140005, 25061, 97341, 17603, 43.82942439,
25.74557483, 18.08384956]}
response1 = requests.get(url.format(dfwds1),verify=False)
get_population_info(population_dict, response1.json())
response2 = requests.get(url.format(dfwds2),verify=False)
get_population_info(population_dict, response2.json())
response3 = requests.get(url.format(dfwds3),verify=False)
get_population_info(population_dict, response3.json())
save_excel(population_dict)
return population_dict
def get_population_info(population_dict, json_obj):
"""
提取人口数量信息
"""
datanodes = json_obj['returndata']['datanodes']
for node in datanodes:
# 获取年份
year = node['code'][-4:]
# 数据数值
data = node['data']['data']
if year in population_dict.keys():
population_dict[year].append(data)
else:
population_dict[year] = [int(year), data]
return population_dict
def save_excel(population_dict):
"""
人口数据生成excel文件
"""
# .T 是行列转换
df = pd.DataFrame(population_dict).T[::-1]
df.columns = ['年份', '年末总人口(万人)', '男性人口(万人)', '女性人口(万人)', '城镇人口(万人)', '乡村人口(万人)', '人口出生率(‰)', '人口死亡率(‰)',
'人口自然增长率(‰)', '年末总人口(万人)', '0-14岁人口(万人)', '15-64岁人口(万人)', '65岁及以上人口(万人)', '总抚养比(%)',
'少儿抚养比(%)', '老年抚养比(%)']
writer = pd.ExcelWriter(POPULATION_EXCEL_PATH)
# columns参数用于指定生成的excel中列的顺序
df.to_excel(excel_writer=writer, index=False, encoding='utf-8', sheet_name='中国70年人口数据')
writer.save()
writer.close()
if __name__ == '__main__':
result_dict = spider_population()
# print(result_dict)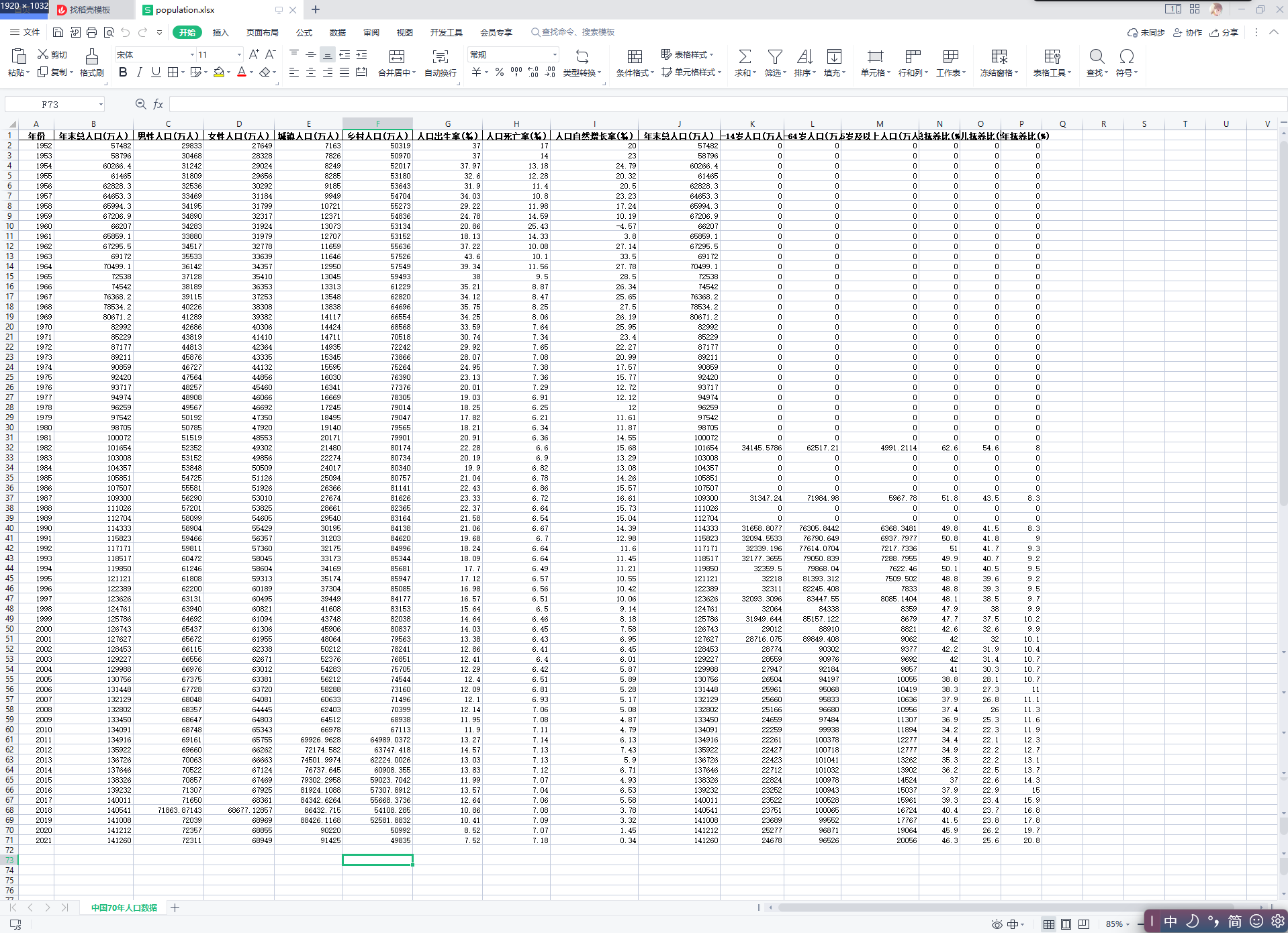
3、分析人口总数
def analysis_total():
"""
分析总人口
"""
# 1、分析总人口,画人口曲线图
# 1.1 处理数据
x_data = DF_STANDARD['年份']
# 将人口单位转换为亿
y_data = DF_STANDARD['年末总人口(万人)'].map(lambda x: "%.2f" % (x / 10000))
# 1.2 自定义曲线图
line = (
Line(init_opts=opts.InitOpts(bg_color=JsCode(background_color_js)))
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="总人口",
y_axis=y_data,
is_smooth=True,
is_symbol_show=True,
symbol="circle",
symbol_size=5,
linestyle_opts=opts.LineStyleOpts(color="#fff"),
label_opts=opts.LabelOpts(is_show=False, position="top", color="white"),
itemstyle_opts=opts.ItemStyleOpts(
color="red", border_color="#fff", border_width=1
),
tooltip_opts=opts.TooltipOpts(is_show=False),
areastyle_opts=opts.AreaStyleOpts(color=JsCode(area_color_js), opacity=1),
# 标出4个关键点的数据
markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(name="新中国成立(1949年)", coord=[0, y_data[0]], value=y_data[0]),
opts.MarkPointItem(name="计划生育(1980年)", coord=[31, y_data[31]], value=y_data[31]),
opts.MarkPointItem(name="放开二胎(2016年)", coord=[67, y_data[67]], value=y_data[67]),
opts.MarkPointItem(name="2021年", coord=[70, y_data[70]], value=y_data[70])
]
),
# markline_opts 可以画直线
# markline_opts=opts.MarkLineOpts(
# data=[[opts.MarkLineItem(coord=[39, y_data[39]]),
# opts.MarkLineItem(coord=[19, y_data[19]])],
# [opts.MarkLineItem(coord=[70, y_data[70]]),
# opts.MarkLineItem(coord=[39, y_data[39]])]],
# linestyle_opts=opts.LineStyleOpts(color="red")
# ),
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="新中国70年人口变化(亿人)",
pos_bottom="5%",
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(color="#fff", font_size=16),
),
# x轴相关的选项设置
xaxis_opts=opts.AxisOpts(
type_="category",
boundary_gap=False,
axislabel_opts=opts.LabelOpts(margin=30, color="#ffffff63"),
axisline_opts=opts.AxisLineOpts(is_show=False),
axistick_opts=opts.AxisTickOpts(
is_show=True,
length=25,
linestyle_opts=opts.LineStyleOpts(color="#ffffff1f"),
),
splitline_opts=opts.SplitLineOpts(
is_show=False, linestyle_opts=opts.LineStyleOpts(color="#ffffff1f")
),
),
# y轴相关选项设置
yaxis_opts=opts.AxisOpts(
type_="value",
position="left",
axislabel_opts=opts.LabelOpts(margin=20, color="#ffffff63"),
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(width=0, color="#ffffff1f")
),
axistick_opts=opts.AxisTickOpts(
is_show=True,
length=15,
linestyle_opts=opts.LineStyleOpts(color="#ffffff1f"),
),
splitline_opts=opts.SplitLineOpts(
is_show=False, linestyle_opts=opts.LineStyleOpts(color="#ffffff1f")
),
),
# 图例配置项相关设置
legend_opts=opts.LegendOpts(is_show=False),
)
)
# 2、分析计划生育执行前后增长人口
# 2.1 数据处理
total_1952 = DF_STANDARD[DF_STANDARD['年份'] == 1952]['年末总人口(万人)'].values
total_1979 = DF_STANDARD[DF_STANDARD['年份'] == 1979]['年末总人口(万人)'].values
total_2006 = DF_STANDARD[DF_STANDARD['年份'] == 2006]['年末总人口(万人)'].values
total_2021 = DF_STANDARD[DF_STANDARD['年份'] == 2021]['年末总人口(万人)'].values
increase_1952_1979 = '%.2f' % (int(total_1979 - total_1952) / 10000)
increase_1979_2006 = '%.2f' % (int(total_2006 - total_1979) / 10000)
increase_2006_2021 = '%.2f' % (int(total_2021 - total_2006) / 10000)
# 2.2 画柱状图
bar = (
Bar(init_opts=opts.InitOpts(bg_color=JsCode(background_color_js)))
.add_xaxis([''])
.add_yaxis("计划生育29年:1952-1979", [increase_1952_1979], color=JsCode(area_color_js),
label_opts=opts.LabelOpts(color='white', font_size=16))
.add_yaxis("计划生育后:1979-2006", [increase_1979_2006], color=JsCode(area_color_js),
label_opts=opts.LabelOpts(color='white', font_size=16))
.add_yaxis("开放二胎后:2006-2021", [increase_2006_2021], color=JsCode(area_color_js),
label_opts=opts.LabelOpts(color='white', font_size=16))
.set_global_opts(
title_opts=opts.TitleOpts(
title="计划生育执行前29年(1952-1979)与后27年(1979-2006)以及二胎开放(2006-2021)增加人口总数比较(亿人)",
pos_bottom="5%",
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(color="#fff", font_size=16)
),
xaxis_opts=opts.AxisOpts(
# 隐藏x轴的坐标线
axisline_opts=opts.AxisLineOpts(is_show=False),
),
yaxis_opts=opts.AxisOpts(
# y轴坐标数值
axislabel_opts=opts.LabelOpts(margin=20, color="#ffffff63"),
# y 轴 轴线
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(width=0, color="#ffffff1f")
),
# y轴刻度横线
axistick_opts=opts.AxisTickOpts(
is_show=True,
length=15,
linestyle_opts=opts.LineStyleOpts(color="#ffffff1f"),
),
),
legend_opts=opts.LegendOpts(is_show=False)
)
)
# 3、渲染图像,将多个图像显示在一个html中
# DraggablePageLayout表示可拖拽
page = Page(layout=Page.DraggablePageLayout)
page.add(line)
page.add(bar)
page.render('D:\\Users\\Rain\\Desktop\\python作业\\人口分析.html')
analysis_total()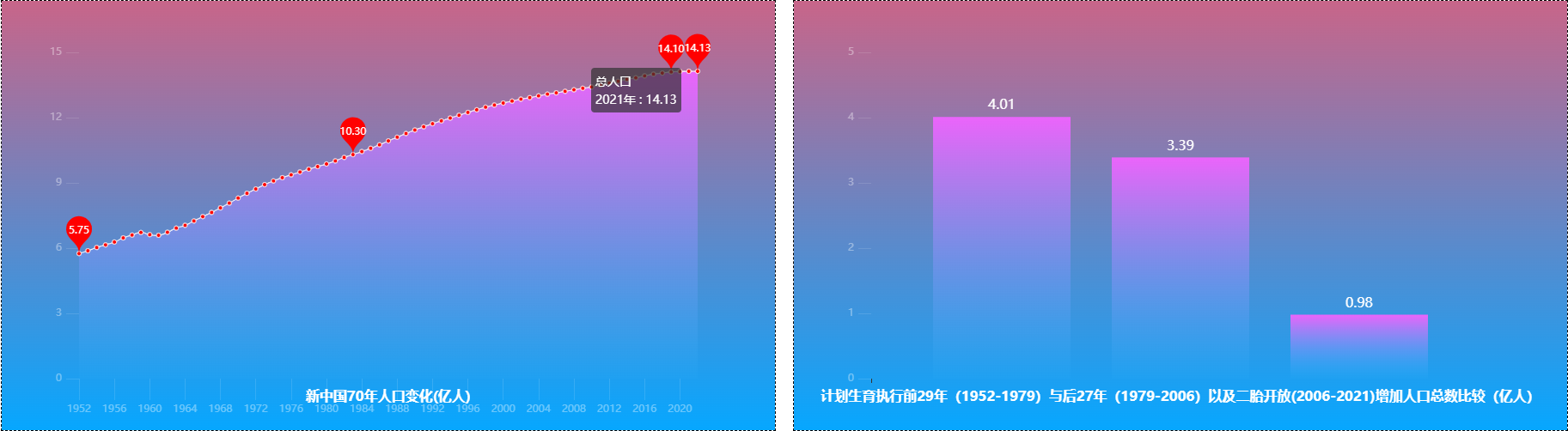
4、分析人口城镇化
def analysis_urbanization():
"""
分析人口城镇化
"""
# 年份
x_data_year = DF_STANDARD['年份']
# 2021年我国人口城镇化
urbanization_2021 = DF_STANDARD[DF_STANDARD['年份'] == 2021][['城镇人口(万人)', '乡村人口(万人)']]
pie = (
Pie()
.add("", [list(z) for z in zip(['城镇人口', '乡村人口'], np.ravel(urbanization_2021.values))])
.set_global_opts(title_opts=opts.TitleOpts(title="2021中国城镇化比例", pos_bottom="bottom", pos_left="center", ),
legend_opts=opts.LegendOpts(is_show=False))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"))
)
# 2、城镇化比例曲线
y_data_city = DF_STANDARD['城镇人口(万人)'] / 10000
y_data_countryside = DF_STANDARD['乡村人口(万人)'] / 10000
line1 = (
Line()
.add_xaxis(x_data_year)
.add_yaxis("城镇人口", y_data_city)
.add_yaxis(series_name="乡村人口", y_axis=y_data_countryside,
# 标记线
markline_opts=opts.MarkLineOpts(
# 去除标记线的箭头
symbol='none',
label_opts=opts.LabelOpts(font_size=16),
data=[[opts.MarkLineItem(coord=[46, 0]),
opts.MarkLineItem(name='1995', coord=[46, y_data_countryside[46]])],
[opts.MarkLineItem(coord=[61, 0]),
opts.MarkLineItem(name='2010', coord=[61, y_data_countryside[61]])]],
# opacity不透明度 0 - 1
linestyle_opts=opts.LineStyleOpts(color="red", opacity=0.3)
),
# 标出关键点的数据
markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(name="1995年", coord=[46, y_data_countryside[46]],
value="%.2f" % (y_data_countryside[46])),
opts.MarkPointItem(name="2010年", coord=[61, y_data_countryside[61]],
value="%.2f" % (y_data_countryside[61]))]
)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="中国70年(1952-2021)城乡人口曲线(亿人)", pos_left="center", pos_top="bottom"),
xaxis_opts=opts.AxisOpts(type_="category")
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
# 3、城镇化曲线
y_data_urbanization = (DF_STANDARD['城镇人口(万人)'] / DF_STANDARD['年末总人口(万人)']).map(lambda x: "%.2f" % (x * 100))
line2 = (
Line()
.add_xaxis(x_data_year)
.add_yaxis(
series_name="中国人口城镇化比例曲线",
y_axis=y_data_urbanization.values,
markline_opts=opts.MarkLineOpts(symbol='none', data=[opts.MarkLineItem(y=30), opts.MarkLineItem(y=70)])
)
.set_global_opts(
title_opts=opts.TitleOpts(title="中国(1952-2021)人口城镇化比例曲线", pos_left="center", pos_top="bottom"),
xaxis_opts=opts.AxisOpts(type_="category"),
# y轴显示百分比,并设置最小值和最大值
yaxis_opts=opts.AxisOpts(type_="value", max_=100, min_=10,
axislabel_opts=opts.LabelOpts(formatter='{value} %')),
legend_opts=opts.LegendOpts(is_show=False),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
# 4、渲染图像,将多个图像显示在一个html中
page = Page(layout=Page.DraggablePageLayout)
page.add(pie)
page.add(line1)
page.add(line2)
page.render('D:\\Users\\Rain\\Desktop\\python作业\\人口城镇化.html')
analysis_urbanization()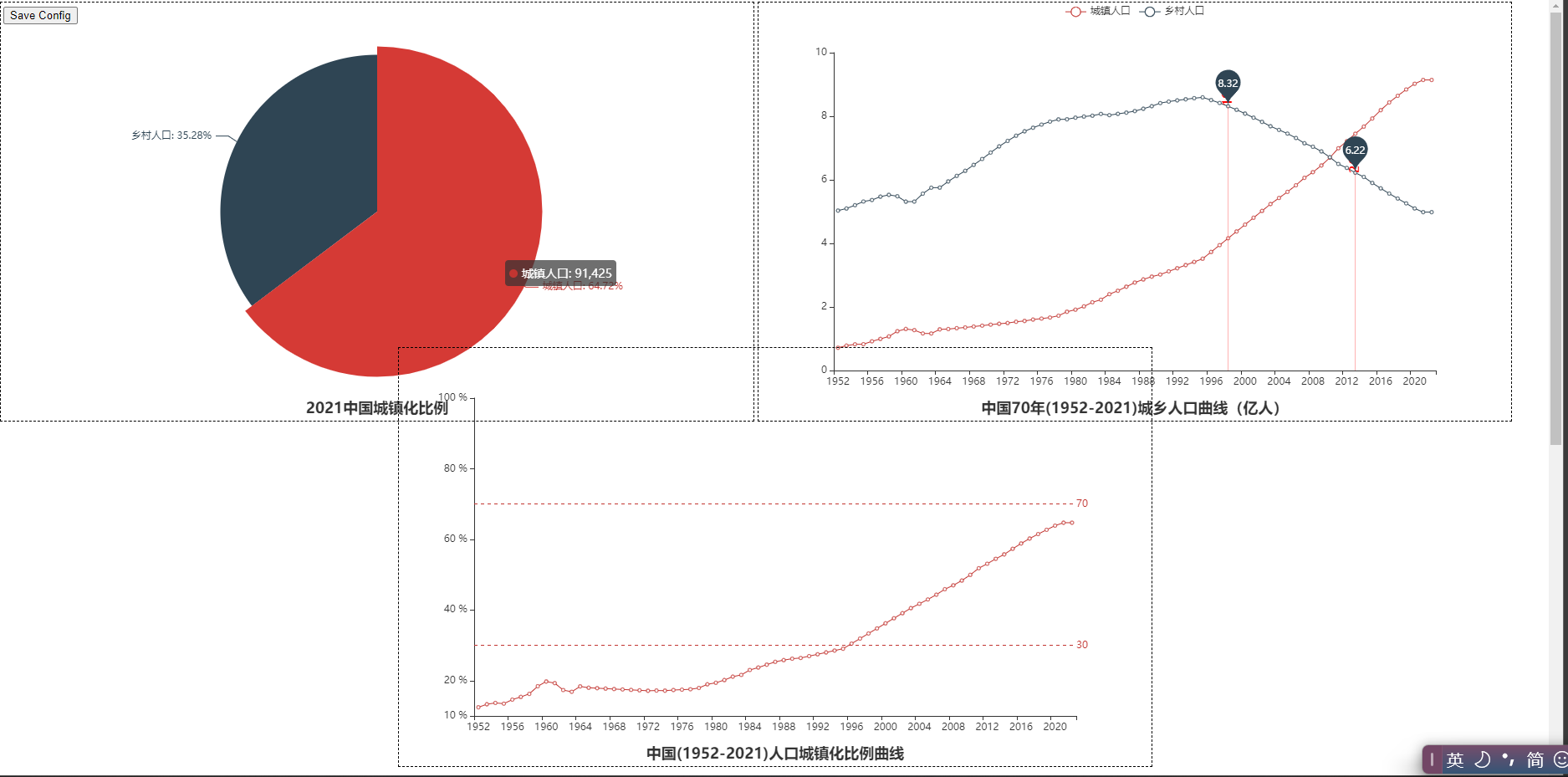
5、人口增长率
def analysis_growth():
"""
分析人口增长率
"""
# 1、三条曲线
x_data_year = DF_STANDARD['年份']
y_data_birth = DF_STANDARD['人口出生率(‰)']
y_data_death = DF_STANDARD['人口死亡率(‰)']
y_data_growth = DF_STANDARD['人口自然增长率(‰)']
line1 = (
Line()
.add_xaxis(x_data_year)
.add_yaxis("人口出生率", y_data_birth)
.add_yaxis("人口死亡率", y_data_death)
.add_yaxis("人口自然增长率", y_data_growth)
.set_global_opts(
# y轴显示百分比,并设置最小值和最大值
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter='{value} ‰')),
title_opts=opts.TitleOpts(title="中国70年(1952-2021)出生率、死亡率及增长率变化", subtitle="1952-2021年,单位:‰",
pos_left="center",
pos_top="bottom"),
xaxis_opts=opts.AxisOpts(type_="category"),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
# 2、渲染图像,将两个图像显示在一个html中
page = Page(layout=Page.DraggablePageLayout)
page.add(line1)
page.render('D:\\Users\\Rain\\Desktop\\python作业\\人口增长率分析.html')
analysis_growth()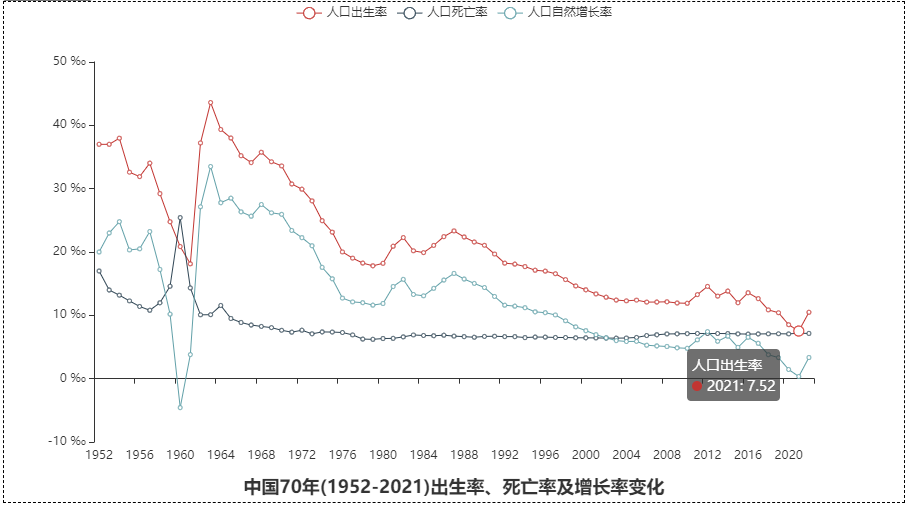
6、年龄结构
def analysis_age():
"""
分析年龄结构
"""
new_df = DF_STANDARD[DF_STANDARD['0-14岁人口(万人)'] != 0][['年份', '0-14岁人口(万人)', '15-64岁人口(万人)', '65岁及以上人口(万人)']]
x_data_year = new_df['年份']
y_data_age_14 = new_df['0-14岁人口(万人)']
y_data_age_15_64 = new_df['15-64岁人口(万人)']
y_data_age_65 = new_df['65岁及以上人口(万人)']
line1 = (
Line()
.add_xaxis(x_data_year)
.add_yaxis("0-14岁人口", y_data_age_14)
.add_yaxis("15-64", y_data_age_15_64)
.add_yaxis("65岁及以上人口", y_data_age_65)
.set_global_opts(
# y轴显示百分比,并设置最小值和最大值
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter='{value}万')),
title_opts=opts.TitleOpts(title="中国人口年龄结构变化图(万人)",
pos_left="center",
pos_top="bottom"),
xaxis_opts=opts.AxisOpts(type_="category"),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
# 2、2000年龄结构与2021年龄结构
age_2000 = DF_STANDARD[DF_STANDARD['年份'] == 2000][['0-14岁人口(万人)', '15-64岁人口(万人)', '65岁及以上人口(万人)']]
age_2021 = DF_STANDARD[DF_STANDARD['年份'] == 2021][['0-14岁人口(万人)', '15-64岁人口(万人)', '65岁及以上人口(万人)']]
pie = (
Pie()
.add(
"2000",
[list(z) for z in zip(['0-14', '15-64', '65'], np.ravel(age_2000.values))],
center=["20%", "50%"],
radius=[60, 80],
)
.add(
"2021",
[list(z) for z in zip(['0-14', '15-64', '65'], np.ravel(age_2021.values))],
center=["55%", "50%"],
radius=[60, 80],
)
.set_series_opts(label_opts=opts.LabelOpts(position="top", formatter="{b}: {d}%"))
.set_global_opts(
title_opts=opts.TitleOpts(title="中国2000~2021年年龄结构对比图", pos_left="center",
pos_top="bottom"),
legend_opts=opts.LegendOpts(
type_="scroll", pos_top="20%", pos_left="80%", orient="vertical"
),
)
)
# 3、抚养比曲线
new_df = DF_STANDARD[DF_STANDARD['总抚养比(%)'] != 0][['年份', '总抚养比(%)', '少儿抚养比(%)', '老年抚养比(%)']]
x_data_year2 = new_df['年份']
y_data_all = new_df['总抚养比(%)']
y_data_new = new_df['少儿抚养比(%)']
y_data_old = new_df['老年抚养比(%)']
line2 = (
Line()
.add_xaxis(x_data_year2)
.add_yaxis(series_name="总抚养比", y_axis=y_data_all, markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(name="1995年", coord=[22, y_data_all.values[22]],
value="%.2f" % (y_data_all.values[22]))
]
))
.add_yaxis("少儿抚养比", y_data_new)
.add_yaxis("老年抚养比", y_data_old)
.set_global_opts(
# y轴显示百分比,并设置最小值和最大值
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter='{value}%')),
title_opts=opts.TitleOpts(title="中国抚养比变化曲线图",
pos_left="center",
pos_top="bottom"),
xaxis_opts=opts.AxisOpts(type_="category"),
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
# 4、渲染图像,将两个图像显示在一个html中
page = Page(layout=Page.DraggablePageLayout)
page.add(line1)
page.add(line2)
page.add(pie)
page.render('D:\\Users\\Rain\\Desktop\\python作业\\人口结构.html')
analysis_age()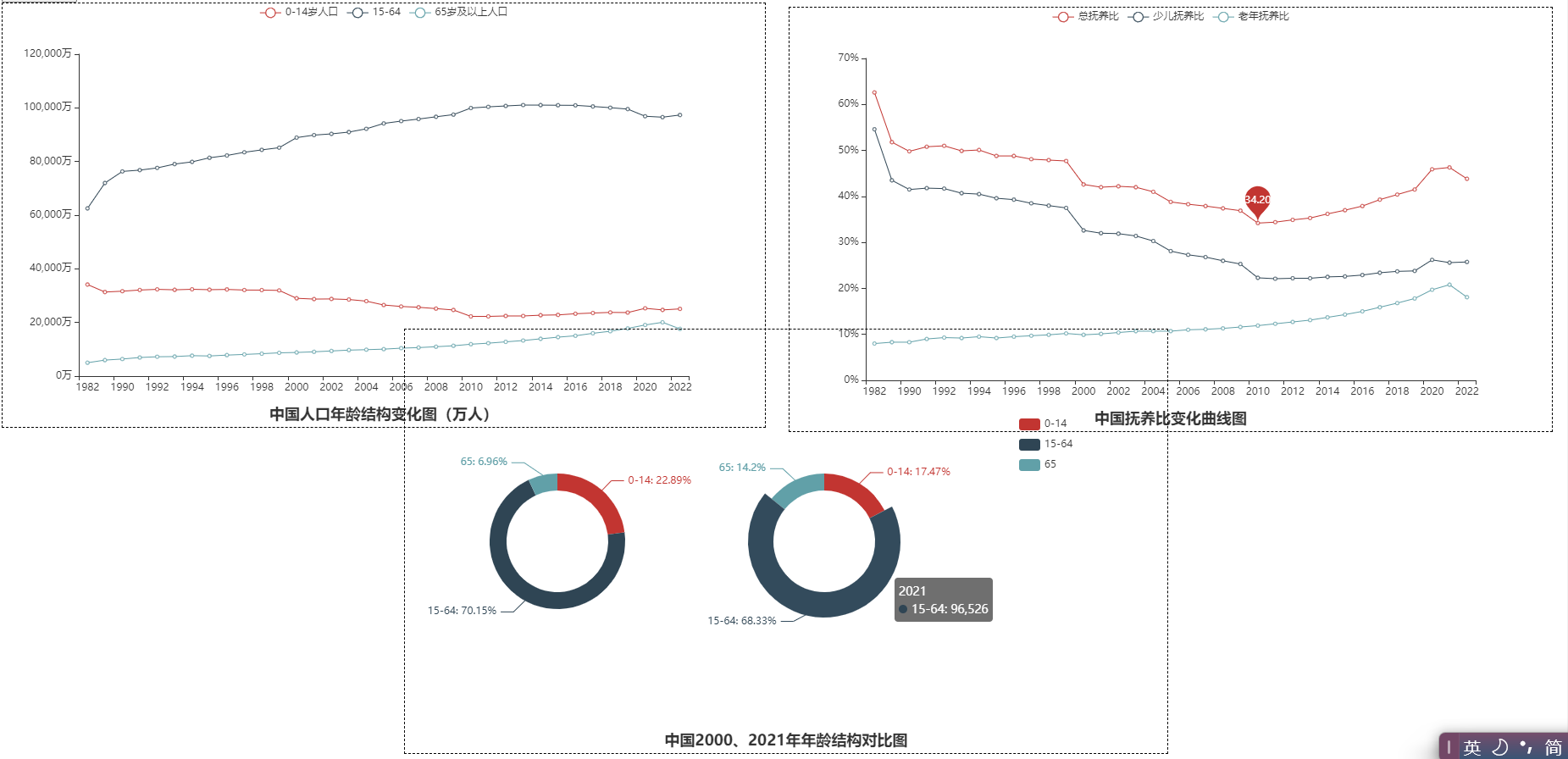
5、附上完整代码

def spider_population(): url = 'https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=zb&colcode=sj&wds=%5B%5D&dfwds=%5B%7B%22wdcode%22%3A%22zb%22%2C%22valuecode%22%3A%22A0301%22%7D%5D&k1=1670909912224&h=1' response = requests.get(url,verify=False) print(response.json()) spider_population() def spider_population(): #获取近70年的人口信息 # 总人口 dfwds1 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0301"}]' url = 'https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}' response1 = requests.get(url.format(dfwds1),verify=False) print(response1.json()) spider_population() def spider_population(): dfwds1 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0301"}]' # 增长率 dfwds2 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0302"}]' # 人口结构 dfwds3 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0303"}]' url = 'https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}' response1 = requests.get(url.format(dfwds1),verify=False) response2 = requests.get(url.format(dfwds2),verify=False) response3 = requests.get(url.format(dfwds3),verify=False) spider_population() import pandas as pd import requests # 人口数量excel文件保存路径 POPULATION_EXCEL_PATH = 'D:\\Users\\Rain\\Desktop\\python作业\\population.xlsx' def spider_population(): """ 爬取人口数据 """ # 请求参数 sj(时间),zb(指标) # 总人口 dfwds1 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0301"}]' # 增长率 dfwds2 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0302"}]' # 人口结构 dfwds3 = '[{"wdcode": "sj", "valuecode": "LAST70"}, {"wdcode":"zb","valuecode":"A0303"}]' url = 'https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgnd&rowcode=sj&colcode=zb&wds=[]&dfwds={}' # 将所有数据放这里,年份为key,值为各个指标值组成的list # 因为 2019 年数据还没有列入到年度数据表里,所以根据统计局2019年经济报告中给出的人口数据计算得出 # 数据顺序为历年数据 population_dict = { '2022': [2022, 141260, 72311, 68949, 91425, 49835, 10.48, 7.14, 3.34, 140005, 25061, 97341, 17603, 43.82942439, 25.74557483, 18.08384956]} response1 = requests.get(url.format(dfwds1),verify=False) get_population_info(population_dict, response1.json()) response2 = requests.get(url.format(dfwds2),verify=False) get_population_info(population_dict, response2.json()) response3 = requests.get(url.format(dfwds3),verify=False) get_population_info(population_dict, response3.json()) save_excel(population_dict) return population_dict def get_population_info(population_dict, json_obj): """ 提取人口数量信息 """ datanodes = json_obj['returndata']['datanodes'] for node in datanodes: # 获取年份 year = node['code'][-4:] # 数据数值 data = node['data']['data'] if year in population_dict.keys(): population_dict[year].append(data) else: population_dict[year] = [int(year), data] return population_dict def save_excel(population_dict): """ 人口数据生成excel文件 :param population_dict: 人口数据 :return: """ # .T 是行列转换 df = pd.DataFrame(population_dict).T[::-1] df.columns = ['年份', '年末总人口(万人)', '男性人口(万人)', '女性人口(万人)', '城镇人口(万人)', '乡村人口(万人)', '人口出生率(‰)', '人口死亡率(‰)', '人口自然增长率(‰)', '年末总人口(万人)', '0-14岁人口(万人)', '15-64岁人口(万人)', '65岁及以上人口(万人)', '总抚养比(%)', '少儿抚养比(%)', '老年抚养比(%)'] writer = pd.ExcelWriter(POPULATION_EXCEL_PATH) # columns参数用于指定生成的excel中列的顺序 df.to_excel(excel_writer=writer, index=False, encoding='utf-8', sheet_name='中国70年人口数据') writer.save() writer.close() if __name__ == '__main__': result_dict = spider_population() # print(result_dict) import numpy as np import pandas as pd import pyecharts.options as opts from pyecharts.charts import Line, Bar, Page, Pie from pyecharts.commons.utils import JsCode # 人口数量excel文件保存路径 POPULATION_EXCEL_PATH = 'D:\\Users\\Rain\\Desktop\\python作业\\population.xlsx' # 读取标准数据 DF_STANDARD = pd.read_excel(POPULATION_EXCEL_PATH) # 自定义pyecharts图形背景颜色js background_color_js = ( "new echarts.graphic.LinearGradient(0, 0, 0, 1, " "[{offset: 0, color: '#c86589'}, {offset: 1, color: '#06a7ff'}], false)" ) # 自定义pyecharts图像区域颜色js area_color_js = ( "new echarts.graphic.LinearGradient(0, 0, 0, 1, " "[{offset: 0, color: '#eb64fb'}, {offset: 1, color: '#3fbbff0d'}], false)" ) def analysis_total(): """ 分析总人口 """ # 1、分析总人口,画人口曲线图 # 1.1 处理数据 x_data = DF_STANDARD['年份'] # 将人口单位转换为亿 y_data = DF_STANDARD['年末总人口(万人)'].map(lambda x: "%.2f" % (x / 10000)) # 1.2 自定义曲线图 line = ( Line(init_opts=opts.InitOpts(bg_color=JsCode(background_color_js))) .add_xaxis(xaxis_data=x_data) .add_yaxis( series_name="总人口", y_axis=y_data, is_smooth=True, is_symbol_show=True, symbol="circle", symbol_size=5, linestyle_opts=opts.LineStyleOpts(color="#fff"), label_opts=opts.LabelOpts(is_show=False, position="top", color="white"), itemstyle_opts=opts.ItemStyleOpts( color="red", border_color="#fff", border_width=1 ), tooltip_opts=opts.TooltipOpts(is_show=False), areastyle_opts=opts.AreaStyleOpts(color=JsCode(area_color_js), opacity=1), # 标出4个关键点的数据 markpoint_opts=opts.MarkPointOpts( data=[opts.MarkPointItem(name="新中国成立(1949年)", coord=[0, y_data[0]], value=y_data[0]), opts.MarkPointItem(name="计划生育(1980年)", coord=[31, y_data[31]], value=y_data[31]), opts.MarkPointItem(name="放开二胎(2016年)", coord=[67, y_data[67]], value=y_data[67]), opts.MarkPointItem(name="2021年", coord=[70, y_data[70]], value=y_data[70]) ] ), # markline_opts 可以画直线 # markline_opts=opts.MarkLineOpts( # data=[[opts.MarkLineItem(coord=[39, y_data[39]]), # opts.MarkLineItem(coord=[19, y_data[19]])], # [opts.MarkLineItem(coord=[70, y_data[70]]), # opts.MarkLineItem(coord=[39, y_data[39]])]], # linestyle_opts=opts.LineStyleOpts(color="red") # ), ) .set_global_opts( title_opts=opts.TitleOpts( title="新中国70年人口变化(亿人)", pos_bottom="5%", pos_left="center", title_textstyle_opts=opts.TextStyleOpts(color="#fff", font_size=16), ), # x轴相关的选项设置 xaxis_opts=opts.AxisOpts( type_="category", boundary_gap=False, axislabel_opts=opts.LabelOpts(margin=30, color="#ffffff63"), axisline_opts=opts.AxisLineOpts(is_show=False), axistick_opts=opts.AxisTickOpts( is_show=True, length=25, linestyle_opts=opts.LineStyleOpts(color="#ffffff1f"), ), splitline_opts=opts.SplitLineOpts( is_show=False, linestyle_opts=opts.LineStyleOpts(color="#ffffff1f") ), ), # y轴相关选项设置 yaxis_opts=opts.AxisOpts( type_="value", position="left", axislabel_opts=opts.LabelOpts(margin=20, color="#ffffff63"), axisline_opts=opts.AxisLineOpts( linestyle_opts=opts.LineStyleOpts(width=0, color="#ffffff1f") ), axistick_opts=opts.AxisTickOpts( is_show=True, length=15, linestyle_opts=opts.LineStyleOpts(color="#ffffff1f"), ), splitline_opts=opts.SplitLineOpts( is_show=False, linestyle_opts=opts.LineStyleOpts(color="#ffffff1f") ), ), # 图例配置项相关设置 legend_opts=opts.LegendOpts(is_show=False), ) ) # 2、分析计划生育执行前后增长人口 # 2.1 数据处理 total_1952 = DF_STANDARD[DF_STANDARD['年份'] == 1952]['年末总人口(万人)'].values total_1979 = DF_STANDARD[DF_STANDARD['年份'] == 1979]['年末总人口(万人)'].values total_2006 = DF_STANDARD[DF_STANDARD['年份'] == 2006]['年末总人口(万人)'].values total_2021 = DF_STANDARD[DF_STANDARD['年份'] == 2021]['年末总人口(万人)'].values increase_1952_1979 = '%.2f' % (int(total_1979 - total_1952) / 10000) increase_1979_2006 = '%.2f' % (int(total_2006 - total_1979) / 10000) increase_2006_2021 = '%.2f' % (int(total_2021 - total_2006) / 10000) # 2.2 画柱状图 bar = ( Bar(init_opts=opts.InitOpts(bg_color=JsCode(background_color_js))) .add_xaxis(['']) .add_yaxis("计划生育29年:1952-1979", [increase_1952_1979], color=JsCode(area_color_js), label_opts=opts.LabelOpts(color='white', font_size=16)) .add_yaxis("计划生育后:1979-2006", [increase_1979_2006], color=JsCode(area_color_js), label_opts=opts.LabelOpts(color='white', font_size=16)) .add_yaxis("开放二胎后:2006-2021", [increase_2006_2021], color=JsCode(area_color_js), label_opts=opts.LabelOpts(color='white', font_size=16)) .set_global_opts( title_opts=opts.TitleOpts( title="计划生育执行前29年(1952-1979)与后27年(1979-2006)以及二胎开放(2006-2021)增加人口总数比较(亿人)", pos_bottom="5%", pos_left="center", title_textstyle_opts=opts.TextStyleOpts(color="#fff", font_size=16) ), xaxis_opts=opts.AxisOpts( # 隐藏x轴的坐标线 axisline_opts=opts.AxisLineOpts(is_show=False), ), yaxis_opts=opts.AxisOpts( # y轴坐标数值 axislabel_opts=opts.LabelOpts(margin=20, color="#ffffff63"), # y 轴 轴线 axisline_opts=opts.AxisLineOpts( linestyle_opts=opts.LineStyleOpts(width=0, color="#ffffff1f") ), # y轴刻度横线 axistick_opts=opts.AxisTickOpts( is_show=True, length=15, linestyle_opts=opts.LineStyleOpts(color="#ffffff1f"), ), ), legend_opts=opts.LegendOpts(is_show=False) ) ) # 3、渲染图像,将多个图像显示在一个html中 # DraggablePageLayout表示可拖拽 page = Page(layout=Page.DraggablePageLayout) page.add(line) page.add(bar) page.render('D:\\Users\\Rain\\Desktop\\python作业\\人口分析.html') analysis_total() def analysis_sex(): """ 分析男女比 """ # 年份 x_data_year = DF_STANDARD['年份'] # 1、2021年男女比饼图 sex_2021 = DF_STANDARD[DF_STANDARD['年份'] == 2021][['男性人口(万人)', '女性人口(万人)']] pie = ( Pie() .add("", [list(z) for z in zip(['男', '女'], np.ravel(sex_2021.values))]) .set_global_opts(title_opts=opts.TitleOpts(title="2021中国男女比", pos_bottom="bottom", pos_left="center")) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")) ) # 2、历年男性占总人数比曲线 # (男性数/总数)x 100 ,然后保留两位小数 man_percent = (DF_STANDARD['男性人口(万人)'] / DF_STANDARD['年末总人口(万人)']).map(lambda x: "%.2f" % (x * 100)) line1 = ( Line() .add_xaxis(x_data_year) .add_yaxis( series_name="男性占总人口比", y_axis=man_percent.values, # 标出关键点的数据 markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="min"), opts.MarkPointItem(type_="max")]), # 画出平均线 markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]) ) .set_global_opts( title_opts=opts.TitleOpts(title="中国70年(1952-2021)男性占总人数比", pos_left="center", pos_top="bottom"), xaxis_opts=opts.AxisOpts(type_="category"), # y轴显示百分比,并设置最小值和最大值 yaxis_opts=opts.AxisOpts(type_="value", max_=52, min_=50, axislabel_opts=opts.LabelOpts(formatter='{value} %')), legend_opts=opts.LegendOpts(is_show=False), ) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) ) # 3、男女折线图 # 历年男性人口数 y_data_man = DF_STANDARD['男性人口(万人)'] # 历年女性人口数 y_data_woman = DF_STANDARD['女性人口(万人)'] line2 = ( Line() .add_xaxis(x_data_year) .add_yaxis("女性", y_data_woman) .add_yaxis("男性", y_data_man) .set_global_opts( title_opts=opts.TitleOpts(title="中国70年(1952-2021)男女人口数(万人)", pos_left="center", pos_top="bottom"), xaxis_opts=opts.AxisOpts(type_="category"), ) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) ) # 4、男女人口差异图 # 两列相减,获得新列 y_data_man_woman = DF_STANDARD['男性人口(万人)'] - DF_STANDARD['女性人口(万人)'] line3 = ( Line() .add_xaxis(x_data_year) .add_yaxis( series_name="男女差值", y_axis=y_data_man_woman.values, # 标出关键点的数据 markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="min"), opts.MarkPointItem(type_="max"), opts.MarkPointItem(type_="average")]), markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]) ) .set_global_opts( title_opts=opts.TitleOpts(title="中国70年(1952-2021)男女差值(万人)", pos_left="center", pos_top="bottom"), xaxis_opts=opts.AxisOpts(type_="category"), legend_opts=opts.LegendOpts(is_show=False), ) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) ) # 5、渲染图像,将多个图像显示在一个html中 page = Page(layout=Page.DraggablePageLayout) page.add(pie) page.add(line1) page.add(line2) page.add(line3) page.render('D:\\Users\\Rain\\Desktop\\python作业\\男女比例.html') analysis_sex() def analysis_sex(): """ 分析男女比 """ # 年份 x_data_year = DF_STANDARD['年份'] # 1、2021年男女比饼图 sex_2021 = DF_STANDARD[DF_STANDARD['年份'] == 2021][['男性人口(万人)', '女性人口(万人)']] pie = ( Pie() .add("", [list(z) for z in zip(['男', '女'], np.ravel(sex_2021.values))]) .set_global_opts(title_opts=opts.TitleOpts(title="2021中国男女比", pos_bottom="bottom", pos_left="center")) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")) ) # 2、历年男性占总人数比曲线 # (男性数/总数)x 100 ,然后保留两位小数 man_percent = (DF_STANDARD['男性人口(万人)'] / DF_STANDARD['年末总人口(万人)']).map(lambda x: "%.2f" % (x * 100)) line1 = ( Line() .add_xaxis(x_data_year) .add_yaxis( series_name="男性占总人口比", y_axis=man_percent.values, # 标出关键点的数据 markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="min"), opts.MarkPointItem(type_="max")]), # 画出平均线 markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]) ) .set_global_opts( title_opts=opts.TitleOpts(title="中国70年(1952-2021)男性占总人数比", pos_left="center", pos_top="bottom"), xaxis_opts=opts.AxisOpts(type_="category"), # y轴显示百分比,并设置最小值和最大值 yaxis_opts=opts.AxisOpts(type_="value", max_=52, min_=50, axislabel_opts=opts.LabelOpts(formatter='{value} %')), legend_opts=opts.LegendOpts(is_show=False), ) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) ) # 3、男女折线图 # 历年男性人口数 y_data_man = DF_STANDARD['男性人口(万人)'] # 历年女性人口数 y_data_woman = DF_STANDARD['女性人口(万人)'] line2 = ( Line() .add_xaxis(x_data_year) .add_yaxis("女性", y_data_woman) .add_yaxis("男性", y_data_man) .set_global_opts( title_opts=opts.TitleOpts(title="中国70年(1952-2021)男女人口数(万人)", pos_left="center", pos_top="bottom"), xaxis_opts=opts.AxisOpts(type_="category"), ) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) ) # 4、男女人口差异图 # 两列相减,获得新列 y_data_man_woman = DF_STANDARD['男性人口(万人)'] - DF_STANDARD['女性人口(万人)'] line3 = ( Line() .add_xaxis(x_data_year) .add_yaxis( series_name="男女差值", y_axis=y_data_man_woman.values, # 标出关键点的数据 markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="min"), opts.MarkPointItem(type_="max"), opts.MarkPointItem(type_="average")]), markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]) ) .set_global_opts( title_opts=opts.TitleOpts(title="中国70年(1952-2021)男女差值(万人)", pos_left="center", pos_top="bottom"), xaxis_opts=opts.AxisOpts(type_="category"), legend_opts=opts.LegendOpts(is_show=False), ) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) ) # 5、渲染图像,将多个图像显示在一个html中 page = Page(layout=Page.DraggablePageLayout) page.add(pie) page.add(line1) page.add(line2) page.add(line3) page.render('D:\\Users\\Rain\\Desktop\\python作业\\男女比例.html') analysis_sex() def analysis_growth(): """ 分析人口增长率 """ # 1、三条曲线 x_data_year = DF_STANDARD['年份'] y_data_birth = DF_STANDARD['人口出生率(‰)'] y_data_death = DF_STANDARD['人口死亡率(‰)'] y_data_growth = DF_STANDARD['人口自然增长率(‰)'] line1 = ( Line() .add_xaxis(x_data_year) .add_yaxis("人口出生率", y_data_birth) .add_yaxis("人口死亡率", y_data_death) .add_yaxis("人口自然增长率", y_data_growth) .set_global_opts( # y轴显示百分比,并设置最小值和最大值 yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter='{value} ‰')), title_opts=opts.TitleOpts(title="中国70年(1952-2021)出生率、死亡率及增长率变化", subtitle="1952-2021年,单位:‰", pos_left="center", pos_top="bottom"), xaxis_opts=opts.AxisOpts(type_="category"), ) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) ) # 2、渲染图像,将两个图像显示在一个html中 page = Page(layout=Page.DraggablePageLayout) page.add(line1) page.render('D:\\Users\\Rain\\Desktop\\python作业\\人口增长率分析.html') analysis_growth() def analysis_age(): """ 分析年龄结构 """ new_df = DF_STANDARD[DF_STANDARD['0-14岁人口(万人)'] != 0][['年份', '0-14岁人口(万人)', '15-64岁人口(万人)', '65岁及以上人口(万人)']] x_data_year = new_df['年份'] y_data_age_14 = new_df['0-14岁人口(万人)'] y_data_age_15_64 = new_df['15-64岁人口(万人)'] y_data_age_65 = new_df['65岁及以上人口(万人)'] line1 = ( Line() .add_xaxis(x_data_year) .add_yaxis("0-14岁人口", y_data_age_14) .add_yaxis("15-64", y_data_age_15_64) .add_yaxis("65岁及以上人口", y_data_age_65) .set_global_opts( # y轴显示百分比,并设置最小值和最大值 yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter='{value}万')), title_opts=opts.TitleOpts(title="中国人口年龄结构变化图(万人)", pos_left="center", pos_top="bottom"), xaxis_opts=opts.AxisOpts(type_="category"), ) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) ) # 2、1982年龄结构与2019年龄结构 age_2000 = DF_STANDARD[DF_STANDARD['年份'] == 2000][['0-14岁人口(万人)', '15-64岁人口(万人)', '65岁及以上人口(万人)']] age_2021 = DF_STANDARD[DF_STANDARD['年份'] == 2021][['0-14岁人口(万人)', '15-64岁人口(万人)', '65岁及以上人口(万人)']] pie = ( Pie() .add( "2000", [list(z) for z in zip(['0-14', '15-64', '65'], np.ravel(age_2000.values))], center=["20%", "50%"], radius=[60, 80], ) .add( "2021", [list(z) for z in zip(['0-14', '15-64', '65'], np.ravel(age_2021.values))], center=["55%", "50%"], radius=[60, 80], ) .set_series_opts(label_opts=opts.LabelOpts(position="top", formatter="{b}: {d}%")) .set_global_opts( title_opts=opts.TitleOpts(title="中国2000~2021年年龄结构对比图", pos_left="center", pos_top="bottom"), legend_opts=opts.LegendOpts( type_="scroll", pos_top="20%", pos_left="80%", orient="vertical" ), ) ) # 3、抚养比曲线 new_df = DF_STANDARD[DF_STANDARD['总抚养比(%)'] != 0][['年份', '总抚养比(%)', '少儿抚养比(%)', '老年抚养比(%)']] x_data_year2 = new_df['年份'] y_data_all = new_df['总抚养比(%)'] y_data_new = new_df['少儿抚养比(%)'] y_data_old = new_df['老年抚养比(%)'] line2 = ( Line() .add_xaxis(x_data_year2) .add_yaxis(series_name="总抚养比", y_axis=y_data_all, markpoint_opts=opts.MarkPointOpts( data=[opts.MarkPointItem(name="1995年", coord=[22, y_data_all.values[22]], value="%.2f" % (y_data_all.values[22])) ] )) .add_yaxis("少儿抚养比", y_data_new) .add_yaxis("老年抚养比", y_data_old) .set_global_opts( # y轴显示百分比,并设置最小值和最大值 yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter='{value}%')), title_opts=opts.TitleOpts(title="中国抚养比变化曲线图", pos_left="center", pos_top="bottom"), xaxis_opts=opts.AxisOpts(type_="category"), ) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) ) # 4、渲染图像,将两个图像显示在一个html中 page = Page(layout=Page.DraggablePageLayout) page.add(line1) page.add(line2) page.add(pie) page.render('D:\\Users\\Rain\\Desktop\\python作业\\人口结构.html') analysis_age()
6、结论
1.总人口:我国总人口稳步增长,但在2016年之后逐渐放缓特别是疫情的情况的,出生率并没有随着二胎和三胎政策的开发二得到提升,反而成下降趋势。
2、人口城镇化:城镇化逐年稳步提升
3、人口增长率:人口的出生率持续走弟2021年的出生率达到新底。
4、年龄结构:65岁以上逐步增长 0-14岁的新生儿和青年开始逐渐减少。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix