

PostgreSQL(一)教程 -----SQL语言
一、概念
PostgreSQL是一种关系型数据库管理系统 (RDBMS)。这意味着它是一种用于管理存储在关系中的数据的系统。关系实际上是表的数学术语。 今天,把数据存储在表里的概念已经快成了固有的常识了, 但是还有其它的一些方法用于组织数据库。在类 Unix 操作系统上的文件和目录就形成了一种层次数据库的例子。 更现代的发展是面向对象数据库。
每个表都是一个命名的行集合。一个给定表的每一行由同一组的命名列组成,而且每一列都有一个特定的数据类型。虽然列在每行里的顺序是固定的, 但一定要记住 SQL 并不对行在表中的顺序做任何保证(但你可以为了显示的目的对它们进行显式地排序)。
表被分组成数据库,一个由单个PostgreSQL服务器实例管理的数据库集合组成一个数据库集簇。
二、创建一个新表
你可以通过指定表的名字和所有列的名字及其类型来创建表∶
CREATE TABLE weather (
city varchar(80),
temp_lo int, -- 最低温度
temp_hi int, -- 最高温度
prcp real, -- 湿度
date date
);
你可以在psql输入这些命令以及换行符。psql可以识别该命令直到分号才结束。
你可以在 SQL 命令中自由使用空白(即空格、制表符和换行符)。 这就意味着你可以用和上面不同的对齐方式键入命令,或者将命令全部放在一行中。两个划线("--")引入注释。
任何跟在它后面直到行尾的东西都会被忽略。SQL 是对关键字和标识符大小写不敏感的语言,只有在标识符用双引号包围时才能保留它们的大小写(上例没有这么做)。
varchar(80)指定了一个可以存储最长 80 个字符的任意字符串的数据类型。int是普通的整数类型。real是一种用于存储单精度浮点数的类型。date类型应该可以自解释(没错,类型为date的列名字也是date。 这么做可能比较方便或者容易让人混淆 — 你自己选择)。
PostgreSQL支持标准的SQL类型int、smallint、real、double precision、char(N)、varchar(N)、date、time、timestamp和interval,还支持其他的通用功能的类型和丰富的几何类型。PostgreSQL中可以定制任意数量的用户定义数据类型。因而类型名并不是语法关键字,除了SQL标准要求支持的特例外。
第二个例子将保存城市和它们相关的地理位置:
CREATE TABLE cities (
name varchar(80),
location point
);
类型point就是一种PostgreSQL特有数据类型的例子。
最后,我们还要提到如果你不再需要某个表,或者你想以不同的形式重建它,那么你可以用下面的命令删除它:
DROP TABLE tablename;
三、在表中 增加行
INSERT语句用于向表中添加行:
INSERT INTO weather VALUES ('San Francisco', 46, 50, 0.25, '1994-11-27');
请注意所有数据类型都使用了相当明了的输入格式。那些不是简单数字值的常量通常必需用单引号(')包围,就象在例子里一样。date类型实际上对可接收的格式相当灵活,不过在本教程里,我们应该坚持使用这种清晰的格式。
point类型要求一个座标对作为输入,如下:
INSERT INTO cities VALUES ('San Francisco', '(-194.0, 53.0)');
到目前为止使用的语法要求你记住列的顺序。一个可选的语法允许你明确地列出列:
INSERT INTO weather (city, temp_lo, temp_hi, prcp, date)
VALUES ('San Francisco', 43, 57, 0.0, '1994-11-29');
如果你需要,你可以用另外一个顺序列出列或者是忽略某些列, 比如说,我们不知道降水量:
INSERT INTO weather (date, city, temp_hi, temp_lo)
VALUES ('1994-11-29', 'Hayward', 54, 37);
许多开发人员认为明确列出列要比依赖隐含的顺序是更好的风格。
请输入上面显示的所有命令,这样你在随后的各节中才有可用的数据。
你还可以使用COPY从文本文件中装载大量数据。这种方式通常更快,因为COPY命令就是为这类应用优化的, 只是比 INSERT少一些灵活性。比如:
COPY weather FROM '/home/user/weather.txt';
这里源文件的文件名必须在运行后端进程的机器上是可用的, 而不是在客户端上,因为后端进程将直接读取该文件。
四、查询一个表
要从一个表中检索数据就是查询这个表。SQL的SELECT语句就是做这个用途的。 该语句分为选择列表(列出要返回的列)、表列表(列出从中检索数据的表)以及可选的条件(指定任意的限制)。比如,要检索表weather的所有行,键入:
SELECT * FROM weather;
这里*是"所有列"的缩写。因此相同的结果应该这样获得:
SELECT city, temp_lo, temp_hi, prcp, date FROM weather;
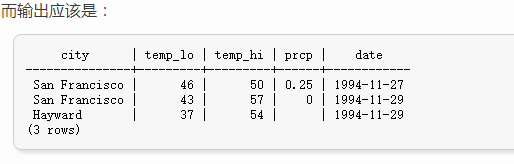
你可以在选择列表中写任意表达式,而不仅仅是列的列表。比如,你可以:
SELECT city, (temp_hi+temp_lo)/2 AS temp_avg, date FROM weather;
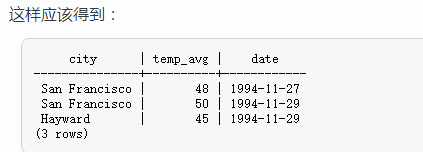
请注意这里的AS子句是如何给输出列重新命名的(AS子句是可选的)。
一个查询可以使用WHERE子句"修饰",它指定需要哪些行。WHERE子句包含一个布尔(真值)表达式,只有那些使布尔表达式为真的行才会被返回。在条件中可以使用常用的布尔操作符(AND、OR和NOT)。 比如,下面的查询检索旧金山的下雨天的天气:
SELECT * FROM weather
WHERE city = 'San Francisco' AND prcp > 0.0;
你可以要求返回的查询结果是排好序的:
SELECT * FROM weather
ORDER BY city;

在这个例子里,排序的顺序并未完全被指定,因此你可能看到属于旧金山的行被随机地排序。但是如果你使用下面的语句,那么就总是会得到上面的结果:
SELECT * FROM weather
ORDER BY city, temp_lo;
你可以要求在查询的结果中消除重复的行:
SELECT DISTINCT city
FROM weather;
再次声明,结果行的顺序可能变化。你可以组合使用DISTINCT和ORDER BY来保证获取一致的结果
SELECT DISTINCT city
FROM weather
ORDER BY city;
五、在表之间的连接
到目前为止,我们的查询一次只访问一个表。查询可以一次访问多个表,或者用这种方式访问一个表而同时处理该表的多个行。 一个同时访问同一个或者不同表的多个行的查询叫连接查询。举例来说,比如你想列出所有天气记录以及相关的城市位置。要实现这个目标,我们需要拿 weather表每行的city列和cities表所有行的name列进行比较, 并选取那些在该值上相匹配的行对。
SELECT *
FROM weather, cities
WHERE city = name;

观察结果集的两个方面:
-
没有城市Hayward的结果行。这是因为在cities表里面没有Hayward的匹配行,所以连接忽略 weather表里的不匹配行。我们稍后将看到如何修补它。
-
有两个列包含城市名字。这是正确的, 因为weather和cities表的列被串接在一起。不过,实际上我们不想要这些, 因此你将可能希望明确列出输出列而不是使用*:
SELECT city, temp_lo, temp_hi, prcp, date, location FROM weather, cities WHERE city = name;这个语法并不象上文的那个那么常用,我们在这里写出来是为了让你更容易了解后面的主题。
现在我们将看看如何能把Hayward记录找回来。我们想让查询干的事是扫描weather表, 并且对每一行都找出匹配的cities表行。如果我们没有找到匹配的行,那么我们需要一些"空值"代替cities表的列。 这种类型的查询叫外连接 (我们在此之前看到的连接都是内连接)。这样的命令看起来象这样:
SELECT * FROM weather LEFT OUTER JOIN cities ON (weather.city = cities.name); city | temp_lo | temp_hi | prcp | date | name | location ---------------+---------+---------+------+------------+---------------+----------- Hayward | 37 | 54 | | 1994-11-29 | | San Francisco | 46 | 50 | 0.25 | 1994-11-27 | San Francisco | (-194,53) San Francisco | 43 | 57 | 0 | 1994-11-29 | San Francisco | (-194,53) (3 rows)这个查询是一个左外连接, 因为在连接操作符左部的表中的行在输出中至少要出现一次, 而在右部的表的行只有在能找到匹配的左部表行是才被输出。 如果输出的左部表的行没有对应匹配的右部表的行,那么右部表行的列将填充空值(null)。
还有右外连接和全外连接。
我们也可以把一个表和自己连接起来。这叫做自连接。 比如,假设我们想找出那些在其它天气记录的温度范围之外的天气记录。这样我们就需要拿 weather表里每行的temp_lo和temp_hi列与weather表里其它行的temp_lo和temp_hi列进行比较。我们可以用下面的查询实现这个目标:
SELECT W1.city, W1.temp_lo AS low, W1.temp_hi AS high,
W2.city, W2.temp_lo AS low, W2.temp_hi AS high
FROM weather W1, weather W2
WHERE W1.temp_lo < W2.temp_lo
AND W1.temp_hi > W2.temp_hi;
city | low | high | city | low | high
---------------+-----+------+---------------+-----+------
San Francisco | 43 | 57 | San Francisco | 46 | 50
Hayward | 37 | 54 | San Francisco | 46 | 50
(2 rows)
在这里我们把weather表重新标记为W1和W2以区分连接的左部和右部。你还可以用这样的别名在其它查询里节约一些敲键,比如:
SELECT *
FROM weather w, cities c
WHERE w.city = c.name;
六、聚集函数
和大多数其它关系数据库产品一样,PostgreSQL支持聚集函数。 一个聚集函数从多个输入行中计算出一个结果。 比如,我们有在一个行集合上计算count(计数)、sum(和)、avg(均值)、max(最大值)和min(最小值)的函数。
比如,我们可以用下面的语句找出所有记录中最低温度中的最高温度:
SELECT max(temp_lo) FROM weather; max ----- 46 (1 row)
如果我们想知道该读数发生在哪个城市,我们可以用:
SELECT city FROM weather WHERE temp_lo = max(temp_lo); 错误
不过这个方法不能运转,因为聚集max不能被用于WHERE子句中(存在这个限制是因为WHERE子句决定哪些行可以被聚集计算包括;因此显然它必需在聚集函数之前被计算)。 不过,我们通常都可以用其它方法实现我们的目的;这里我们就可以使用子查询:
SELECT city FROM weather
WHERE temp_lo = (SELECT max(temp_lo) FROM weather);
city
---------------
San Francisco
(1 row)
这样做是 OK 的,因为子查询是一次独立的计算,它独立于外层的查询计算出自己的聚集。
聚集同样也常用于和GROUP BY子句组合。比如,我们可以获取每个城市观测到的最低温度的最高值:
SELECT city, max(temp_lo)
FROM weather
GROUP BY city;
city | max
---------------+-----
Hayward | 37
San Francisco | 46
(2 rows)
这样给我们每个城市一个输出。每个聚集结果都是在匹配该城市的表行上面计算的。我们可以用HAVING 过滤这些被分组的行:
SELECT city, max(temp_lo)
FROM weather
GROUP BY city
HAVING max(temp_lo) < 40;
city | max
---------+-----
Hayward | 37
(1 row)
这样就只给出那些所有temp_lo值曾都低于 40的城市。最后,如果我们只关心那些名字以"S"开头的城市,我们可以用:
SELECT city, max(temp_lo)
FROM weather
WHERE city LIKE 'S%'
GROUP BY city
HAVING max(temp_lo) < 40;
LIKE操作符进行模式匹配
理解聚集和SQL的WHERE以及HAVING子句之间的关系对我们非常重要。WHERE和HAVING的基本区别如下:WHERE在分组和聚集计算之前选取输入行(因此,它控制哪些行进入聚集计算), 而HAVING在分组和聚集之后选取分组行。因此,WHERE子句不能包含聚集函数; 因为试图用聚集函数判断哪些行应输入给聚集运算是没有意义的。相反,HAVING子句总是包含聚集函数(严格说来,你可以写不使用聚集的HAVING子句, 但这样做很少有用。同样的条件用在WHERE阶段会更有效)。
在前面的例子里,我们可以在WHERE里应用城市名称限制,因为它不需要聚集。这样比放在HAVING里更加高效,因为可以避免那些未通过 WHERE检查的行参与到分组和聚集计算中。
七、更新
你可以用UPDATE命令更新现有的行。假设你发现所有 11 月 28 日以后的温度读数都低了两度,那么你就可以用下面的方式改正数据:
UPDATE weather
SET temp_hi = temp_hi - 2, temp_lo = temp_lo - 2
WHERE date > '1994-11-28';
看看数据的新状态:
SELECT * FROM weather;
city | temp_lo | temp_hi | prcp | date
---------------+---------+---------+------+------------
San Francisco | 46 | 50 | 0.25 | 1994-11-27
San Francisco | 41 | 55 | 0 | 1994-11-29
Hayward | 35 | 52 | | 1994-11-29
(3 rows)
八、删除
数据行可以用DELETE命令从表中删除。假设你对Hayward的天气不再感兴趣,那么你可以用下面的方法把那些行从表中删除:
DELETE FROM weather WHERE city = 'Hayward';
所有属于Hayward的天气记录都被删除。
我们用下面形式的语句的时候一定要小心
DELETE FROM tablename;
如果没有一个限制,DELETE将从指定表中删除所有行,把它清空。做这些之前系统不会请求你确认!

