

Sigmoid函数原型
sigmoid函数原型
对于分类任务来说,如果仅仅给出分类的结果,在某些场景下,提供的信息可能并不充足,这就会带来一定的局限。因此,我们建立分类模型,不仅应该能够进行分类,同时,也应该能够提供样本属于该类别的概率。这在现实中是非常实用的。例如,某人患病的概率,明天下雨概率等。因此,我们需要将z的值转换为概率值,逻辑回归使用sigmoid函数来实现转换。
什么是sigmoid函数?
Sigmoid函数是机器学习中比较常用的一个函数,在逻辑回归、人工神经网络中有着广泛的应用,Sigmoid函数是一个有着优美S形曲线的数学函数。
Sigmoid函数的表达式: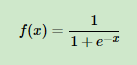
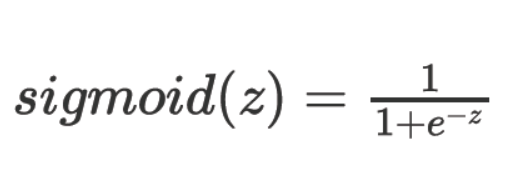
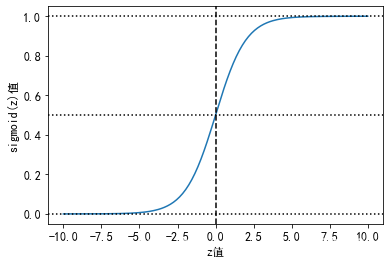
Sigmoid函数的图像:
在上图可以看出,Sigmoid函数连续,光滑,严格单调,是一个非常良好的阈值函数。当x趋近负无穷时,y趋近于0;趋近于正无穷时,y趋近于1;x=0时,y=0.5。当然,在x超出[-6,6]的范围后,函数值基本上没有变化,值非常接近,在应用中一般不考虑。Sigmoid函数的值域范围限制在(0,1)之间,这和概率值的范围[0,1]很接近,所以二分类的概率常常用这个函数。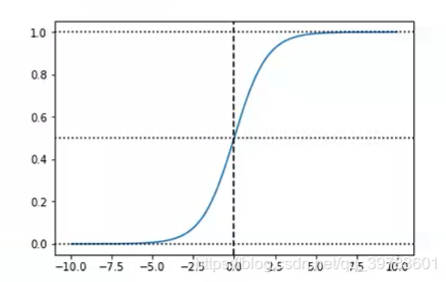
当z的值从-∞向+∞过渡时,sigmoid函数的取值范围为(0, 1),这正好是概率的取值范围,当z=0时,sigmoid(0)的值为0.5。因此,模型就可以将sigmoid的输出值 p 作为正例的概率,而 1-p 作为负例的概率。以阈值0.5作为两个分类的阈值,就是看 p 与 1-p 哪个类别的概率值更大,预测的结果就为哪个类别。
假设真实的分类的 y 值为1与0,则:

函数的基本性质:
- 定义域:(−∞,+∞)
- 值域:(−1,1)
- 函数在定义域内为连续和光滑函数
- 处处可导,导数为:f′(x)=f(x)(1−f(x))
Sigmoid函数与逻辑回归
Sigmoid函数之所以叫Sigmoid,是因为函数的图像很想一个字母S。这个函数是一个很有意思的函数,从图像上我们可以观察到一些直观的特性:函数的取值在0-1之间,且在0.5处为中心对称,并且越靠近x=0的取值斜率越大。
机器学习中一个重要的预测模型逻辑回归(LR)就是基于Sigmoid函数实现的。
LR模型的主要任务是给定一些历史的{X,Y},其中X是样本n个特征值,Y的取值是{0,1}代表正例与负例,通过对这些历史样本的学习,从而得到一个数学模型,给定一个新的X,能够预测出Y。
LR模型是一个二分类模型,即对于一个X,预测其发生或不发生。但事实上,对于一个事件发生的情况,往往不能得到100%的预测,因此LR可以得到一个事件发生的可能性,超过50%则认为事件发生,低于50%则认为事件不发生。
从LR的目的上来看,在选择函数时,有两个条件是必须要满足的:
取值范围在0~1之间。
对于一个事件发生情况,50%是其结果的分水岭,选择函数应该在0.5中心对称。
从这两个条件来看,Sigmoid很好的符合了LR的需求。关于逻辑回归的具体实现与相关问题,可看这篇文章(Logistic函数(sigmoid函数) - wenjun’s blog) ,在此不再赘述。
如何绘制sigmoid函数图像
我们通过Python程序来绘制sigmoid函数在[-10, 10]区间的图像。

import numpy as np import matplotlib.pyplot as plt plt.rcParams["font.family"] = "SimHei" plt.rcParams["axes.unicode_minus"] = False plt.rcParams["font.size"] = 12 # 定义sigmoid函数。 def sigmoid(z): return 1 / (1 + np.exp(-z)) z = np.linspace(-10, 10, 200) plt.plot(z, sigmoid(z)) # 绘制水平线与垂直线。 plt.axvline(x=0, ls="--", c="k") plt.axhline(ls=":", c="k") plt.axhline(y=0.5, ls=":", c="k") plt.axhline(y=1, ls=":", c="k") plt.xlabel("z值") plt.ylabel("sigmoid(z)值")


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程