RGW之DataProcessor
前置知识
rgw_max_chunk_sizeThe chunk size is the size of RADOS I/O requests that RGW sends when accessing data objects.
RGW read and write operation will never request more than this amount in a single request.
This also defines the rgw object head size, as head operations need to be atomic, and anything larger than this would require more than a single operation.rgw_obj_stripe_sizeThe size of an object stripe for RGW objects.
This is the maximum size a backing RADOS object will have. RGW objects that are larger than this will span over multiple objects.
如何理解这两个配置项,上面的英文其实已经解释的很清楚了,结合其实《ceph 设计与实现》中的介绍:
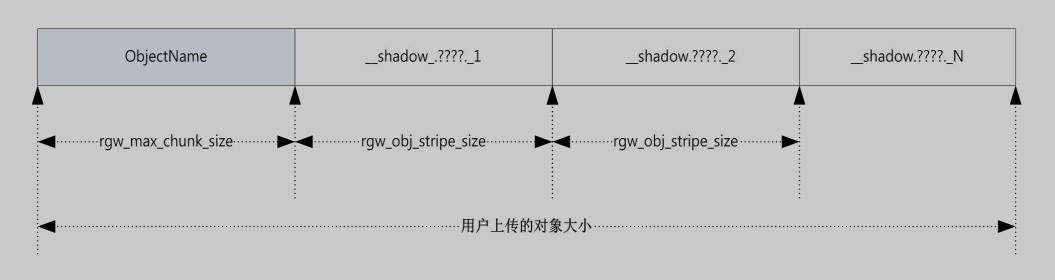
rgw_max_chunk_size:
- 定义了rgw 对象分片时首对象的大小
- 定义了rgw RADOS I/O的最大大小。
举个例子,rgw_max_chunk_size=2M,rgw_obj_stripe_size=5M,对象大小为9M。需要多少次RADOS I/O呢?- 首对象 2M 1次I/O
- 条带1 5M 3次I/O,分别写入 2M/2M/1M
- 条带尾部 2M 1次I/O
rgw_obj_stripe_size
- 定义RGW对象分片后非首对象的最大大小。
RADOS 单个对象的最大size是多少?经过测试,答案是128M,该数值由
osd_max_object_size进行配置。
DataProcessor
src/rgw/rgw_putobj.h!
RGW在对象上传过程中,需要经过一个DataProcessor链的处理。DataProcessor仅提供一个纯虚函数process,具体的处理逻辑交由子类处理。从类图可以看出,RGW提供了两种处理器:
ChunkProcessor, 块处理器StripeProcessor, 条带处理器
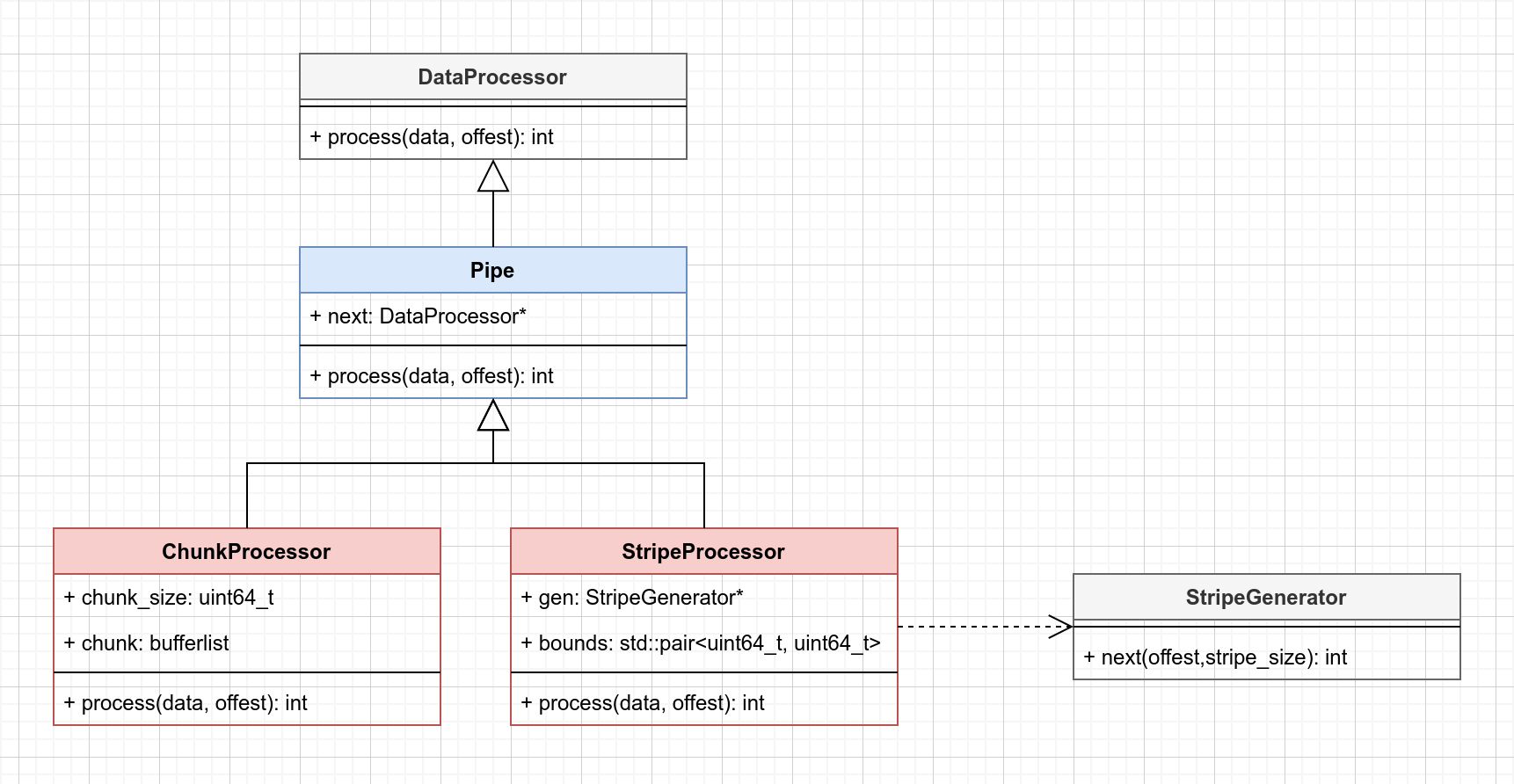
首先,我们结合UT 用例来熟悉这两种处理器的使用方式。
src/test/rgw/test_rgw_putobj.cc
ChunkProcessor
//首先,data就是我们需要处理的数据, offest 表示其从什么位置开始写入。
int ChunkProcessor::process(bufferlist&& data, uint64_t offset)
{
//chunk是 ChunkProcessor 的成员变量,保存一个块的数据
ceph_assert(offset >= chunk.length());
//如果 chunk.length() 大于0,说明上一次处理时剩余不足 chunk_size的数据~,此处相当于调整 pos
uint64_t position = offset - chunk.length();
//当data为空时,表示flush
const bool flush = (data.length() == 0);
if (flush) {
if (chunk.length() > 0) {
//大于0,交由下一个DataProcessor处理。
int r = Pipe::process(std::move(chunk), position);
if (r < 0) {
return r;
}
}
//这一行是否有必要呢?直接return就行了吧应该?
return Pipe::process({}, offset);
}
//将data的数据添加到 chunk中
chunk.claim_append(data);
// write each full chunk
while (chunk.length() >= chunk_size) {
bufferlist bl;
//从chunk中截取chunk_size的数据到bl中。
chunk.splice(0, chunk_size, &bl);
//交由下一个 DataProcessor处理数据
int r = Pipe::process(std::move(bl), position);
if (r < 0) {
return r;
}
position += chunk_size;
}
return 0;
}
这里,Pipe::process :
// passes the data on to the next processor
int process(bufferlist&& data, uint64_t offset) override {
return next->process(std::move(data), offset);
}
所以我们需要自定义一个 DataProcessor 的子类用于将数据落盘,在RGW源码中,该子类对应 RadosWriter。
在UT中,这里就是我们的Hook点,实现一个MockProcessor:
struct Op {
std::string data;
uint64_t offset;
};
struct MockProcessor : rgw::putobj::DataProcessor {
std::vector<Op> ops;
int process(bufferlist &&data, uint64_t offset) override {
ops.push_back({data.to_str(), offset});
return {};
}
};
每一次的落盘操作,都会创建一个Op对象保存在MockProcessor::ops中,我们通过判断每一个Op是否符合预期来对对象上传进行UT测试。
分析一下rgw 单元测试代码:
TEST(PutObj_Chunk, FlushHalf) {
MockProcessor mock;
rgw::putobj::ChunkProcessor chunk(&mock, 4);
//块大小为4,buffer为2,不会写入
ASSERT_EQ(0, chunk.process(string_buf("22"), 0));
ASSERT_TRUE(mock.ops.empty()); // no writes
// flush,这里会调用两次 MockProcessor::process
ASSERT_EQ(0, chunk.process({}, 2)); // flush
ASSERT_EQ(2u, mock.ops.size());
EXPECT_EQ(Op({"22", 0}), mock.ops[0]);
EXPECT_EQ(Op({"", 2}), mock.ops[1]);
}
TEST(PutObj_Chunk, One) {
MockProcessor mock;
rgw::putobj::ChunkProcessor chunk(&mock, 4);
//一次写入一个块大小,调用一次MockProcessor::process
ASSERT_EQ(0, chunk.process(string_buf("4444"), 0));
ASSERT_EQ(1u, mock.ops.size());
EXPECT_EQ(Op({"4444", 0}), mock.ops[0]);
//flush,并且 chunk中无剩余数据,只会调用一次MockProcessor::process
ASSERT_EQ(0, chunk.process({}, 4)); // flush
ASSERT_EQ(2u, mock.ops.size());
EXPECT_EQ(Op({"", 4}), mock.ops[1]);
}
TEST(PutObj_Chunk, OneAndFlushHalf) {
MockProcessor mock;
rgw::putobj::ChunkProcessor chunk(&mock, 4);
//不足chunk_size,不会调用 MockProcessor::process, chunk中有2字节数据
ASSERT_EQ(0, chunk.process(string_buf("22"), 0));
ASSERT_TRUE(mock.ops.empty());
//从 offest == 2位置写入 4字节, 此时chunk.length() == 6,调用一次MockProcessor::process
ASSERT_EQ(0, chunk.process(string_buf("4444"), 2));
ASSERT_EQ(1u, mock.ops.size());
EXPECT_EQ(Op({"2244", 0}), mock.ops[0]);
//chunk中剩余2字节数据,flush, 调用两次 MockProcessor::process
ASSERT_EQ(0, chunk.process({}, 6)); // flush
ASSERT_EQ(3u, mock.ops.size());
EXPECT_EQ(Op({"44", 4}), mock.ops[1]);
EXPECT_EQ(Op({"", 6}), mock.ops[2]);
}
TEST(PutObj_Chunk, Two) {
MockProcessor mock;
rgw::putobj::ChunkProcessor chunk(&mock, 4);
//一次写入2倍chunk_size,调用两次 MockProcessor::process ,chunk中无剩余数据
ASSERT_EQ(0, chunk.process(string_buf("88888888"), 0));
ASSERT_EQ(2u, mock.ops.size());
EXPECT_EQ(Op({"8888", 0}), mock.ops[0]);
EXPECT_EQ(Op({"8888", 4}), mock.ops[1]);
//flush,并且 chunk中无剩余数据,只会调用一次MockProcessor::process
ASSERT_EQ(0, chunk.process({}, 8)); // flush
ASSERT_EQ(3u, mock.ops.size());
EXPECT_EQ(Op({"", 8}), mock.ops[2]);
}
TEST(PutObj_Chunk, TwoAndFlushHalf) {
MockProcessor mock;
rgw::putobj::ChunkProcessor chunk(&mock, 4);
//不足chunk_size,不会调用 MockProcessor::process, chunk中有2字节数据
ASSERT_EQ(0, chunk.process(string_buf("22"), 0));
ASSERT_TRUE(mock.ops.empty());
//从 offest == 2位置写入 8字节, 此时chunk.length() == 10,调用2次MockProcessor::process
ASSERT_EQ(0, chunk.process(string_buf("88888888"), 2));
ASSERT_EQ(2u, mock.ops.size());
EXPECT_EQ(Op({"2288", 0}), mock.ops[0]);
EXPECT_EQ(Op({"8888", 4}), mock.ops[1]);
//flush,chunk中剩余 2字节,调用两次 MockProcessor::process
ASSERT_EQ(0, chunk.process({}, 10)); // flush
ASSERT_EQ(4u, mock.ops.size());
EXPECT_EQ(Op({"88", 8}), mock.ops[2]);
EXPECT_EQ(Op({"", 10}), mock.ops[3]);
}
至此,ChunkProcessor 的工作方式分析完毕。
StripeProcessor
int StripeProcessor::process(bufferlist&& data, uint64_t offset)
{
ceph_assert(offset >= bounds.first);
const bool flush = (data.length() == 0);
if (flush) {
return Pipe::process({}, offset - bounds.first);
}
auto max = bounds.second - offset;
while (data.length() > max) {
if (max > 0) {
bufferlist bl;
data.splice(0, max, &bl);
int r = Pipe::process(std::move(bl), offset - bounds.first);
if (r < 0) {
return r;
}
offset += max;
}
// flush the current chunk
int r = Pipe::process({}, offset - bounds.first);
if (r < 0) {
return r;
}
// generate the next stripe
uint64_t stripe_size;
r = gen->next(offset, &stripe_size);
if (r < 0) {
return r;
}
ceph_assert(stripe_size > 0);
bounds.first = offset;
bounds.second = offset + stripe_size;
max = stripe_size;
}
if (data.length() == 0) { // don't flush the chunk here
return 0;
}
return Pipe::process(std::move(data), offset - bounds.first);
}
TODO:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号