
k8s基础概念及术语
上一篇简单介绍了一下k8s是什么以及如何使用kubeadm快捷安装,今儿来聊一下k8s的几个基础概念及术语。k8s中的资源都可以使用yaml文件进行描述。(文章内容来源于《kubernetes权威指南 第四版》)
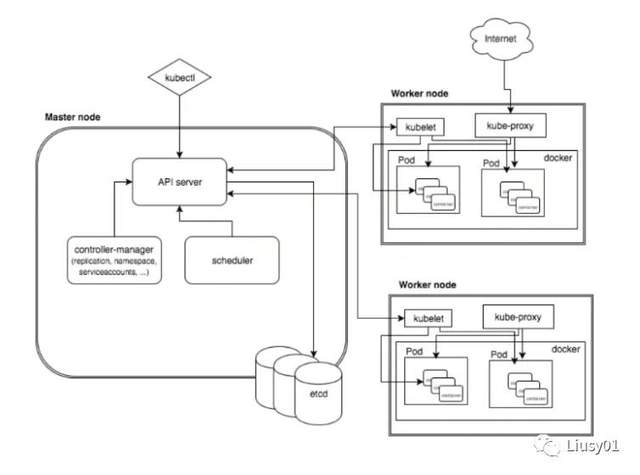
Master
集群控制节点,负责整个集群的管理和控制,负责命令的执行过程,运行着以下四个关键进程。
(1)Kubernetes API Service(Kube-apiservice):提供了Http Rest 接口的关键服务进程,是K8s里所有资源的CRUD的唯一操作入口,也是集群控制的入口进程。
(2)Kubernetes Controller Manager(Kube-controller-manager):K8s中所有资源对象的自动化控制中心,资源对象的大总管。controller用于监控容器健康状态,controller manager监控controller的健康状态。
(3)Kubernetes Scheduler(Kube-scheduler):先做预选,筛选有哪些Node符合,然后做优选最佳的节点。负责资源调度(Pod调度)的进程。
(4)etcd server:保存所有资源对象的数据。当数据发生变化时,etcd 会快速地通知 Kubernetes 相关组件。
Node
工作负载节点,每个Node都会被Master分配工作负载(Docker容器),当某个Node宕机时,其上的工作负载会被Master自动转移到其他节点上。每个Node节点都运行着以下一组进程。
(1)kubelet:负责Pod对应的容器创建、启停等任务,同时与Master密切协作,实现集群管理的基本功能。
(2)kube-proxy:实现K8s service的通信和负载均衡机制的重要组件。
(3)Docker Enginer:Docker引擎,负责本机的容器创建和管理工作。
Node节点可在运行时动态增加到集群中,默认情况下kubelet会向Master注册自己。会定时汇报自身信息,比如Docker版本、CPU、内存、运行哪些Pod等。这样Master可以熟知Node节点的信息,实现高效均衡的资源调度策略,在指定时间内没上报,会被Master判断为失联,进行工作负载转移。
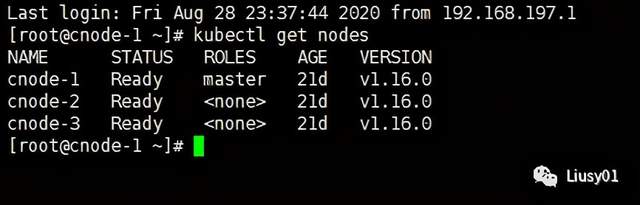
~可通过如下命令查看集群中节点
kubectl get nodes
~可通过如下命令查看节点详细信息
kubectl describe nodes/节点名称
Pod
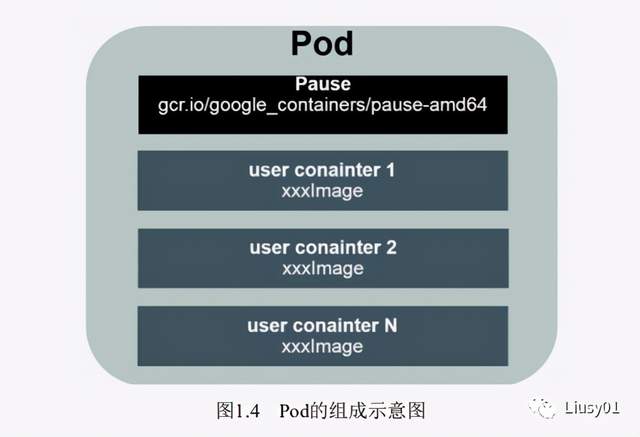
根容器Pause,作为业务无关并不易死亡的Pause容器,它的状态代表了整个容器组的状态,可以简单有效判断容器是否已死。
Pod里多个业务容器共享Pause容器的IP和Volume,简化了业务容器之间的通信问题,也解决了文件共享问题。
k8s为每个Pod分配了一个唯一的IP地址,简称Pod IP,Pod里面的容器可以共享IP,采用虚拟二层网络技术实现集群内任意两个Pod之间可以直接进行TCP/IP通信。
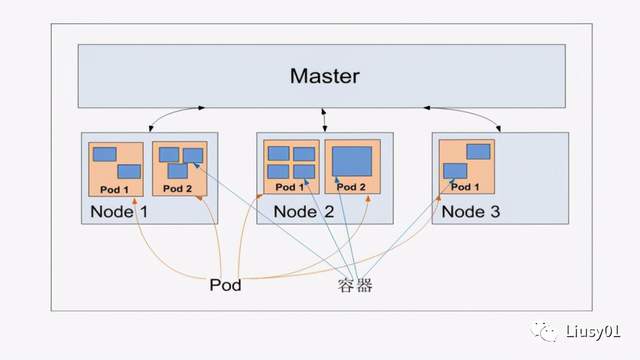
Pod有两种类型:普通Pod和静态Pod,静态Pod并不存放在etcd存储里,而是存放在某个具体的Node里的一个具体文件中,并且只在此Node上运行。普通Pod创建之后就会被放在etcd中存储,随后被Master调度到某个Node上并进行绑定,被Node上kubelet进程实例化成一组相关的Docker容器并启动。默认情况下,Pod某个容器停止 时,k8s会自动检测并重启此Pod,如果所在的Node宕机,则会将所有Pod重新调度到其他节点上。
每个Pod都可以对其能使用的服务器上的计算资源设置限额,当前可以设置限额的计算资源有cpu和memory两种,其中cpu的资源单位以cpu的数量,是一个绝对值而非相对值。
在k8s中,通常以千分之一的CPU配额为最小单位,用m来表示,Memory配额也是一个绝对值,单位时内存字节数。
在K8s中,一个计算资源进行配额限定需要设定以下两个参数:
Requests:最小申请量,必须满足此要求。
Limits:最大允许使用量,不能被突破,当容器试图突破时,会被kill掉然后重启。
例如:在声明某个Pod或Service时可以在spec中进行设置
spec:
container:
- name: db
image: mysql
imagePullPolixy: IfNotPresent
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
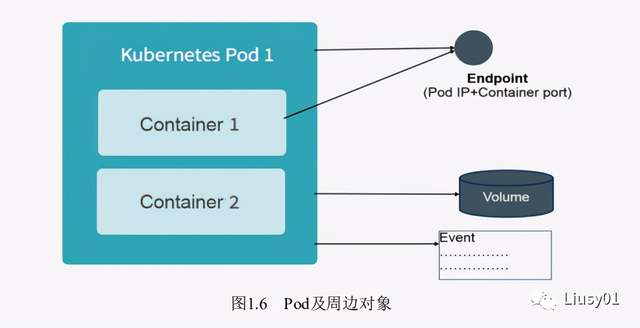
Event是一个事件的记录,记录了事件的最早发生时间、最后重现时间、重复次数、发起者、类型,以及导致此事件的原因等。
可使用如下命令在资源的详细描述中看到
kubectl describe 资源类型 资源名称
例如:kubectl describe nodes cnode-1

Label
标签信息,kv键值对,可附加到各种资源对象上,例如Node,Pod,Service,RC等,一个资源对象可以定义多个Label,一个Label可以被添加到多个资源上,通常在资源定义时确定,也可在在对象创建后动态添加或删除。
可通过Label Selector查询和筛选拥有某些Label的资源对象。当前有 两种Label Selector的表达式,基于等式和基于集合。
例如:name=redis
env != dev
name in (a,b)
name not in (a,b)
当需要多个实现复杂选择的时候,可以用逗号分隔,表示And的关系。
Label Selector使用场景:
(1)Kube-controller通过RC上定义的Label Selector来 筛选要监控的Pod副本数量,从而实现Pod副本的数量始终符合预期设定的全自动监控流程。
(2)kube-proxy通过Service的Label Selector来选择对应的Pod,自动建立起每个Service到对象Pod的请求转发路由表,从而实现Service的智能负载均衡机制。
(3)Kube-schedule通过Label,并且在Pod定义文件中使用NodeSelector这种标签调度策略,实现Pod定向调度的特性。
Replication Controller
RC定义了一个期望的场景,声明某个Pod的数量在任意时刻都符合某个预期值,RC的定义包括如下几个部分:
(1)Pod期待的副本数
(2)用于筛选目标Pod的Label Selector
(3)当Pod的副本数量小于预期数量时,用创建新Pod的Pod模板创建足够的Pod
例如:希望一个redis保持3个实例
apiVersion: v1
kind: ReplicationController
metadata:
name: redis
labels:
name: redis
spec:
replicas: 3
selector:
name: redis
template:
metadata:
name: redis
labels:
name: redis
spec:
containers:
- name: redis
image: redis
imagePullPolicy: IfNotPresent
ports:
- containerPort: 6379
Master会根据RC定期巡检系统中存活的目标Pod,并确保目标Pod实例数量刚好等于RC的期望值。
可通过如下命令动态修改RC中的副本值,可使用此命令进行集群的扩容和缩容。
kubectl scale rc rc-name --replicas=4
特性和作用:
(1)通过定义RC实现Pod的创建过程及副本数量的自动控制。
(2)RC里包括完成的Pod定义模板
(3)RC通过Label Selector机制实现对Pod副本的自动控制。
(4)通过改变RC中的Pod副本数量,可以实现对Pod的扩容或缩容功能。
(5)通过改变RC中的镜像版本,实现Pod的滚动升级功能。
Deployment
常见Pod控制器如下:
控制器名称作用Deployment声明式更新控制器,用于发布无状态应用ReplicaSet副本集控制器,用于对Pod进行副本规模的扩大或者裁剪StatefulSet有状态副本集,用于发布有状态应用DaemonSet
在K8s集群每一个Node上运行一个副本,
用于发布监控和日志收集类等应用
Job运行一次性作业任务CronJob运行周期性作业任务
Deploymen内部使用Replica Set实现,Replica Set是下一代的RC,支持使用基于集合的Label Selector,这也是与Replication Controller唯一的区别。
使用场景:
(1)创建一个Deplayment来生成对应的Replica Set并完成副本的创建过程
(2)检查Deplayment的状态来看部署动作是否完成
(3)更新Deplayment来创建新的Pod
(4)如果当前Deplayment不稳定,则回滚到一个早前的版本。
(5)挂起或恢复一个Deplayment。
(6)扩展Deployment以应对高负载。
(7)清理不再需要的旧版本ReplicaSets。
Deployment的声明的api是extensions/v1betal,其他的使用与RC并无区别
apiVersion: extensions/v1betasStatefulSet
有很多服务是有状态的,特别是一些中间件集群,例如MySQL集群、MongoDB集群、Akka集 群、ZooKeeper集群等,这些应用集群都有以下几个共同点,
(1)每个节点都有固定的身份ID,通过这个ID,集群中的成员可 以相互发现并通信。
(2)集群的规模是比较固定的,集群规模不能随意变动。
(3)集群中的每个节点都是有状态的,通常会持久化数据到永久 存储中。
(4)如果磁盘损坏,则集群里的某个节点无法正常运行,集群功 能受损
如果使用RC或Deployment的话,就会发现第一点无法满足,因为其的Pod名称都是随机生成的,并且不固定,重启之后又是另外一个名、IP等。
StatefulSet可以解决上述问题:
(1)StatefulSet里的每个Pod都有稳定、唯一的网络标识,可以用来 发现集群内的其他成员。假设StatefulSet的名称为kafka,那么第1个Pod 叫kafka-0,第2个叫kafka-1,以此类推。
(2) StatefulSet控制的Pod副本的启停顺序是受控的,操作第n个Pod 时,前n-1个Pod已经是运行且准备好的状态。
(3) StatefulSet里的Pod采用稳定的持久化存储卷,通过PV或PVC来 实现,删除Pod时默认不会删除与StatefulSet相关的存储卷(为了保证数 据的安全)。
StatefulSet除了要与PV卷捆绑使用以存储Pod的状态数据,还要与 Headless Service配合使用,即在每个StatefulSet定义中都要声明它属于 哪个Headless Service。Headless Service与普通Service的关键区别在于, 它没有Cluster IP,如果解析Headless Service的DNS域名,则返回的是该 Service对应的全部Pod的Endpoint列表。StatefulSet在Headless Service的 基础上又为StatefulSet控制的每个Pod实例都创建了一个DNS域名,这个 域名的格式为:
${podname}.${handless service name}比如一个3节点的Kafka的StatefulSet集群对应的Headless Service的名 称为kafka,StatefulSet的名称为kafka,则StatefulSet里的3个Pod的DNS 名称分别为kafka-0.kafka、kafka-1.kafka、kafka-3.kafka。
Job
Job与其他Pod控制器不同的是,Job控制的容器仅运行一次,当所有Pod副本结束,Job也就运行结束了,Job生成的副本不能自动重启,对应Pod的Restart Policy设置为Never。
同时,k8s提供了CronJob,解决某些任务需要定时反复执行的问题。
Horizontal Pod Autoscaler
Pod横向自动扩容,通过追踪分析RC控制的所有目标Pod的负载变化情况,来确定是否需要针对性的调整目标Pod的副本数。
HPA可以有两种方式作为Pod负载的度量指标:
(1)CPUUtilizationPercentage
算术平均值,目标Pod所有副本自身的CPU利用率的一分钟内的平均值,是当前cpu使用量除于Requests值,如果超过自定义比例,例如80%,则需要动态扩容
例如:声明一个HPA对name为test的Deployment在cpu利用率达到90%进行扩容,最多为10个
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: test
namespace: default
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
kind: Deployment
name: test
targetCPUUtilizationPercentage: 90
也可以通过如下命令创建HPA
kubectl autoscale deployment app-name --cpu-percent=90 --min=1 --max=1
(2)应用程序自定义的度量指标,例如TPS或QPS(每秒内的请求数)
Service
K8s中的Service定义了一个服务的访问入口地址,前端应用可以通过这个入口地址访问其背后一组由Pod副本组成的集群实例,Service与其后端的Pod副本集群之间是通过Label Selector来实现连接的。
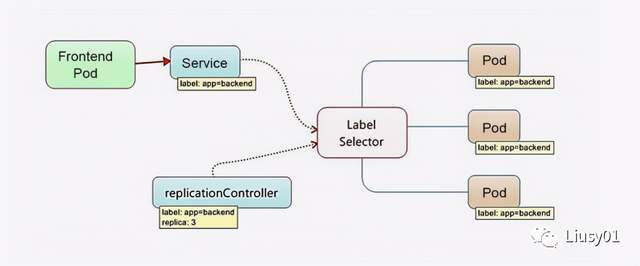
运行在每个Node节点上的kube-proxy进程其实就是一个智能的负载均衡器,负责把对Service的请求转发到后端的Pod上,并在内部实现负载均衡和会话保持机制,每个Service都被分配了一个全局唯一的虚拟IP,成为Cluster-IP,在Service生命周期中,Cluster IP不会改变,但是Pod实例重启之后ip就会变,所以Service的Cluster IP就可以解决此问题。
通过如下命令可以查看service的详细信息
kubelet get svc service-name -o yaml
例如:
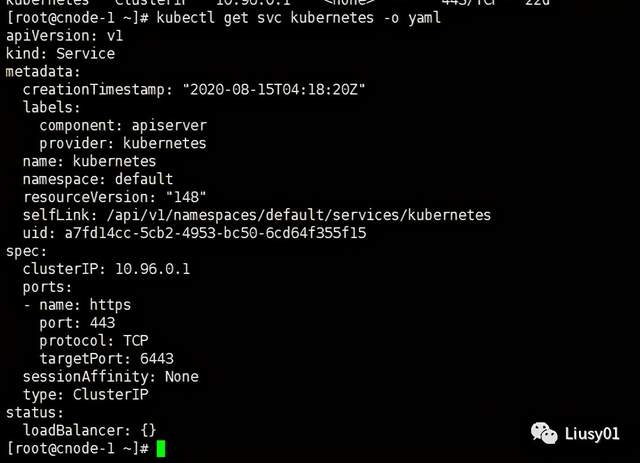
在spec.port中,targetPort表示容器所暴露的端口,port是Service提供的虚端口,如果未指定targetPort,则默认targetPort与port一致。
Service提供支持多个Endpoint,在此情况下,每个Endpoint需定义一个名字区分,例如:
apiVersion: v1
kind: Service
metadata:
name: tomcat-test
spec:
selector:
name: tomcat-test
ports:
- port: 8080
name: service-port1
- port: 8081
name: service-port2
(1)k8s的服务发现机制
K8S中的Service都有一个唯一的Cluster IP和唯一的名字,通过Add-On增值包的方式引入DNS系统,把服务名作为域名,程序就可以直接使用服务名来建立通信连接了。
(2)外部系统访问Service
三种IP:
1、Node IP:Node节点的IP
节点物理网卡的IP地址,真实存在的物理网络,K8s集群之外的节点访问集群,必须通过Node IP进行通信。
2、Pod IP:Pod的IP
是Docker Engine根据docker0的网桥的IP地址段进行分配的,虚拟的二层网络,
3、Cluster IP:Service的IP
仅仅作用于Service这个对象,由K8S管理和分配IP地址。无法被PING。只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备TCP/IP通信的基础。
如果需要集群外的节点访问集群,解决方案就是使用NodePort,例如:
apiVersion: v1
kind: Service
metadata:
name: tomcat-service
spec:
type: NodePort
selector:
name: tomcat
ports:
- port: 8080
nodePort: 30001
上例中将spec.type指定为NodePort,然后在ports中指定nodePort,也就是宿主机的端口号。
如果不指定NodePort,K8S会自动分配一个可用端口。
NodePort的实现方式是在K8S集群中的每个Node上为需要外部访问的Service开启一个对应的TCP监听端口,外部系统只需要任意一个Node的IP地址+具体NodePort的端口即可访问服务。
Volume
Volume是Pod中能够被多个容器访问的共享目录,k8s的Volume定义在Pod上,然后被Pod的多个容器挂载到具体的文件目录下;与Pod的生命周期相同,与容器的生命周期无关,当容器终止或重启时,Volume中的数据也不会丢失,支持多种类型的Volume,例如G`lusterFS等文件系统。
使用:
先在Pod上声明一个Volume,然后在容器中引用该Volume并Mount到容器中的某个目录上,例如:增加一个名为datavol的Volume,并Mount到容器的/mydata-data目录上。
spec:
volumes:
- name: datavol
emptyDir: {}
containers:
- name: test-volume
image: tomcat
volumeMounts:
- mountPath: /mydata-data
name: datavol
k8s提供了丰富的volume类型:
(1)emptyDir
在Pod分配到Node时创建的,初始内容为空,无需指定宿主机上对应的目录文件,K8S自动分配,当Pod从Node上移除时,emptyDir中的数据也会被永久删除。
用途:
1、临时空间
2、长时间任务的中间过程CheckPoint的临时保存目录
3、一个容器需要从另一个容器中获取数据的目录(多容器共享目录)
volumes:
- name: emptyDir
emptyDir: {}
(2)hostPath
在Pod上挂载宿主机上的文件或目录,可用于以下几个方面:
1、容器生成的日志需要永久保存时
2、需要访问宿主机上的Docker引擎内部数据结构的容器应用时,可以通过定义hostPath为宿主机/var/lib/docker目录,使容器内部应用可以直接访问Docker的文件系统。
需注意:
1、在不同的Node上具有相同配置的Pod可能会因为宿主机上的目录和文件不同而导致对Volume上目录和文件的访问结果不一致。
2、如果使用了资源配额管理,则K8s无法将hostPath在宿主机上使用的资源纳入管理。
volumes:
- name: hostpath
hostpath:
path: "/path"
(3)gcePersistentDisk
使用谷歌公有云提供的永久磁盘(Persistent Disk,PD)存放Volume的数据,PD上的内容会永久保存,当Pod被删除时,PD只是被卸载(Unmount),不会被删除,需要先创建一个永久磁盘(PD),才能使用gcePersistentDisk。
限制条件:
Node需要GCE虚拟机
这些虚拟机需要与PD存在与相同的GCE项目和zone中。
通过gcloud命令可创建一个PD
gcloud compute disks create --size=500GB --zone=us-centrall-a my-data-diskvolumes:
- name: gcePersistentDiskTest
gcePersistentDisk:
pdName: my-data-disk
fsType: ext4
(4)awsElasticBlockStore
使用亚马逊公有云提供的EBS Volume存储数据,需要先创建一个EBS Volume才能使用
限制条件:
Node节点需要AWS EC2实例
AWS EC2实例需要与EBS Volume存在于相同的region和availability-zone中
EBS只支持单个EC2实例mount一个Volume
volumes:
- name: awsElasticBlockStoreTest
awsElasticBlockStore:
volumeId: aws://<availability-zone>/<volume-id>
fsType: ext4
(5)NFS
使用NFS网络文件系统提供的共享目录存储数据时,需在系统中部署一个NFS Server
volumes:
- name: nfs
nfs:
server: nfs服务器地址
path: "/"
Persistent Volume
Persistent Volume(PV)和与之关联的Persistent Volume Claim(PVC)是一块网络存储,挂接到虚机上的‘网盘’。网络存储是相对独立于计算资源而存在的一种实体资源。
PV是K8s集群中某个网络存储中对应的的一块存储,与Volume相似,但有以下区别:
(1)PV只能是网络存储,不属于任何Node,但可以在任何Node上访问。
(2)PV并不是定义在Pod上的,而是独立于Pod之外定义的。
(3)PV目前只有几种类型:GCE Persistent Disks、NFS、RBD、iSCSCI、AWS ElasticBlockStore、GlusterFS
例如:定义一个NFS类型的PV
apiVersion: v1
kind: PersistentVolume
metadata:
name: pvtest
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
nfs:
server: nfs地址
path: /path
重点是PV的accessModes属性,目前有以下几种类型:
(1)ReadWriteOnce:读写权限,并且只能被单个Node挂载
(2)ReadOnlyMany:只读权限,允许被多个Node挂载
(3)ReadWriteMany:读写权限,允许被多个Node挂载
如果某个Pod想申请某种条件的PV,则首先需要定义一个Persistent Volume Claim(PVC)对象
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
然后,在Pod的Volume定义中引用上述PVC即可
volumes:
- name: pvtest
persistentVolumeClaim:
claimName: myclaim
PV有以下几种状态:
(1)Available:空闲状态
(2)Bound:已经绑定到某个PVC上
(3)Released:对应的PVC已经删除,但资源还没有被集群回收
(4)Failed:PV自动回收失败。
Namespace
用于实现多租户的资源隔离,通过将集群内部的资源对象“分配”到不同的Namespace中,形成逻辑上分组的不同项目、小组或用户组,便于不同的分组在共享使用整个集群的资源的同时还能被分别管理。
K8S集群启动之后,会创建一个名为default的Namespace,可以通过如下命令查看
kubectl get namespace 或 kubectl get ns
如果在资源定义的时候不指定Namespace,则用户创建的Pod、Service、RC都将会创建到default的Namespace中。
Namespace的定义:
apiVersion: v1 kind: Namespace metadata: name: my-ns
将Pod定义在这个Namespace中
apiVersion: v1
kind: Pod
metadata:
name: my-pod
namespace: my-ns
labels:
name: my-pod
spec:
containers:
- name: my-pod
image: imageName
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
使用kubectl get pods是只能看到default命名空间的Pod,如果需要看到其他Namespace的资源,需要指定Namespace。
kubectl get pods --namespace=my-ns 或者 kubectl get pods -n my-ns
当给不同租户创建一个Namespace实现多租户的资源隔离时,能结合k8s的资源配额管理,限定不同租户能占用的资源,例如CPU使用量,内存使用量等。
Annotation
使用key/value键值对的形式进行定义,与Label类似,不同的是Label具有严格的命名规则,定义的是资源对象的元数据,并用于Label Selector,而Annotation则是任意定义的附加信息,以便于外部工具进行查找,K8s会通过此方式标记资源对象的一些特殊信息。
用Annotation来记录的信息如下:
(1)build信息,release信息,Docker镜像信息等,例如时间戳、release id号、镜像hash值、docker registry地址等
(2)日志库、监控库、分析库等资源库的信息
(3)程序调试工具信息,例如工具名称、版本号等
(4)团队的联系信息、例如电话号码、负责人信息等。
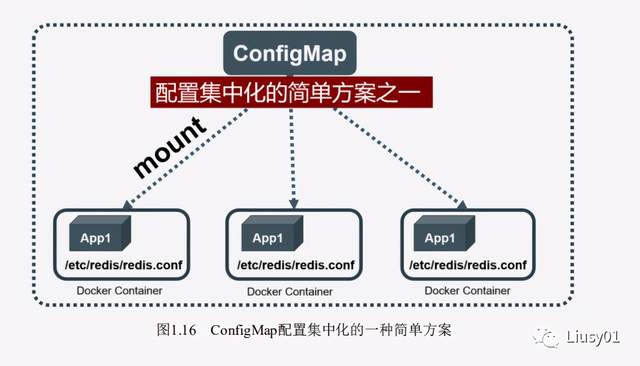
ConfigMap
Docker容器提供了两种方式在运行期间修改配置文件中的参数。
(1)在运行时通过容器的环境变量来传递参数;
(2)通过Docker Volume将容器外的配置文件映射到容器内。
大多数情况下使用的是第二种方式,但这种方式需要先在宿主机下创建配置文件进行映射,在分布式情况下,修改多台服务器的某个配置文件,都是比较麻烦的。
所以,ConfigMap就出现了,所有的配置项都是kv类型的,v也可以是某个文件的路径,例如username=abc,这些配置项可以作为Map中的一个项,整个Map的数据可以被持久化存储在 Kubernetes的Etcd数据库中,然后提供API以方便Kubernetes相关组件或 客户应用CRUD操作这些数据。
k8s提供了一种机制,将存储在etcd中的 ConfigMap通过Volume映射的方式变成目标Pod内的配置文件,不管目标Pod被调度到哪台服务器上,都会完成自动映射。进一步地,如果 ConfigMap中的key-value数据被修改,则映射到Pod中的“配置文件”也会 随之自动更新。
===============================
我是Liusy,一个喜欢健身的程序员。
欢迎关注微信公众号【Liusy01】,一起交流Java技术及健身,获取更多干货,领取Java进阶干货,领取最新大厂面试资料,一起成为Java大神。
来都来了,关注一波再溜呗。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号