Nginx一篇从入门到实战
Nginx安装
Windows10 安装
Nginx官网:http://nginx.org/en/download.html
历史版本下载地址:http://nginx.org/download/
1、下载压缩包:nginx-1.8.0.zip
2、解压所下载的压缩包,并记住解压路径(D:\Environment\nginx\nginx-1.8.0)
3、打开控制台(cmd)进入Nginx安装包根路径(D:\Environment\nginx\nginx-1.8.0)
5、输入命令启动nginx服务:start nginx
6、在浏览器中访问localhost,便可看到nginx成功安装并运行的页面(默认监听端口80)
7、nginx命令
| 命令 | 描述 |
|---|---|
| start nginx | 开启nginx服务 |
| nginx.exe -s stop | 关闭nginx服务,快速停止nginx,可能并不保存相关信息 |
| nginx.exe -s quit | 关闭nginx服务,完整有序的停止nginx,并保存相关信息 |
| nginx.exe -s reload | 重启Nginx服务,一般修改了配置文件之后,使修改生效 |
| nginx -c </config_path> | 此命令参数指定新nginx配置文件来替换默认的nginx配置文件 |
| nginx -t </config_path> | 检查配置文件是否配置成功,在启动服务之前执行 |
| nginx -s reopen | 重新打开日志文件命令 |
| nginx -v | 只是简单显示nginx的版本信息(nginx version) |
| nginx -V | 不但显示nginx的版本信息,而且还显示nginx的配置参数信息 |
8、参数解读
-v 可查看nginx的版本。
-V 可查看nginx的详细信息,包括编译的参数。
-t 可用来测试nginx的配置文件的语法错误。
-T 可用来测试nginx的配置文件语法错误,同时还可以通过重定向备份nginx的配置文件。
-q 如果配置文件没有错误信息时,不会有任何提示,如果有错误,则提示错误信息,与-t配合使用。
-s 发送信号给master处理:
stop 立刻停止nginx服务,不管请求是否处理完
quit 优雅的退出服务,处理完当前的请求退出
reopen 重新打开日志文件,原日志文件要提前备份改名。
reload 重载配置文件
-p 设置nginx家目录路径,默认是编译时的安装路径
-c 设置nginx的配置文件,默认是家目录下的配置文件
-g 设置nginx的全局变量,这个变量会覆盖配置文件中的变量。
9、问题方案:关闭不了nginx?
- nginx -s stop:后用任务管理器看还有没有nginx.exe进程
- cmd命令行执行:netstat -ano|find "0:80" 看端口是否还开启
- cmd命令行执行:tasklist | findstr "nginx" 查看nginx进程是否还在运行
- 如果进程也没有,端口也没开启,说明你访问的是浏览器缓存,F5刷新就没有了
- window 下杀死所有nginx进程:taskkill /fi "imagename eq nginx.EXE" /f
- 强制关掉所有nginx可使用命令:taskkill /F /IM nginx.exe > nul (可能存在多开nginx的情况)
10、目录介绍
conf # 所有配置⽂件⽬录
nginx.conf # 默认的主要的配置⽂件
html # 这是编译安装时Nginx的默认站点⽬录
50x.html # 错误⻚⾯
index.html # 默认⾸⻚
logs # nginx默认的⽇志路径,包括错误⽇志及访问⽇志
access.log # nginx访问⽇志
error.log # 错误⽇志
nginx.pid # nginx启动后的进程id
nginx.exe # 启动命令
Linux 安装
安装环境:CentOS 7.X 64位 ,阿里云或者虚拟机都上都可以。
1、安装依赖:
yum -y install gcc zlib zlib-devel pcre-devel openssl openssl-devel wget
2、Nginx下载:
wget -P /opt/ http://nginx.org/download/nginx-1.18.0.tar.gz
3、Nginx解压进入目录:
tar -zxvf nginx-1.18.0.tar.gz
cd nginx-1.18.0
4、Nginx安装:
# ./configure --prefix=/usr/local/nginx --user=www --group=www
./configure
make && make install
5、安装完成后的路径为(默认):/usr/local/nginx
6、预编译:
# 预编译主要是用来检查系统环境是否满足安装软件包的条件,并生成makefile文件,该文件为编译、安装、升级nginx指明了相应参数。
./configure -h 可以查看编译参数
使用--prefix选项可以指定nginx编译安装的目录;
--user=*** 指定nginx的所属用户
--group=*** 指定nginx的所属组
--with-*** 指定编译某模块
--without-** 指定不编译某模块
--add-module 编译第三方模块
==============================================================
# 预编译完成之后,会生成一个Makefile文件,其中会定义make相关参数:
$ Z ls
auto CHANGES CHANGES.ru conf configure contrib html LICENSE Makefile man objs README src
$ cat Makefile
default: build
clean:
rm -rf Makefile objs
build:
$(MAKE) -f objs/Makefile
install:
$(MAKE) -f objs/Makefile install
modules:
$(MAKE) -f objs/Makefile modules
upgrade:
/usr/local/nginx/sbin/nginx -t
kill -USR2 `cat /usr/local/nginx/logs/nginx.pid`
sleep 1
test -f /usr/local/nginx/logs/nginx.pid.oldbin
kill -QUIT `cat /usr/local/nginx/logs/nginx.pid.oldbin`
====================================
make clean : 重新预编译时,通常执行这条命令删除上次的编译文件
make build : 编译,默认参数,可省略build参数
make install : 安装
make modules : 编译模块
make upgrade : 在线升级
7、Nginx命令
-
查询版本号:/usr/local/nginx/sbin/nginx -v
-
普通启动服务:/usr/local/nginx/sbin/nginx
-
配置文件启动:/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
-
暴力停止服务:/usr/local/nginx/sbin/nginx -s stop
-
优雅停止服务:/usr/local/nginx/sbin/nginx -s quit
-
检查默认配置:/usr/local/nginx/sbin/nginx -t
-
检查指定配置:/usr/local/nginx/sbin/nginx -t -c /usr/local/nginx/conf/nginx.conf
-
重新加载配置:/usr/local/nginx/sbin/nginx -s reload
-
查看相关进程:ps -ef | grep nginx
-
查看相关端口:lsof -i:80
-
杀掉相关进程:kill -9 PID
8、⽬录核⼼介绍
conf # 所有配置⽂件⽬录
nginx.conf # 默认的主要的配置⽂件
nginx.conf.default # 默认模板
html # 这是编译安装时Nginx的默认站点⽬录
50x.html # 错误⻚⾯
index.html # 默认⾸⻚
logs # nginx默认的⽇志路径,包括错误⽇志及访问⽇志
access.log # nginx访问⽇志
error.log # 错误⽇志
nginx.pid # nginx启动后的进程id
sbin # nginx命令的⽬录
nginx # 启动命令
Nginx卸载
1.首先输入命令 ps -ef | grep nginx检查一下nginx服务是否在运行。
2.停止Nginx服务
3.查找、删除Nginx相关文件
-
查看Nginx相关文件:
whereis nginx -
find查找相关文件:
find / -name nginx -
依次删除find查找到的所有目录:
rm -rf /usr/sbin/nginx
4.再使用yum清理:yum remove nginx
[root@localhost /]# yum remove nginx
依赖关系解决
======================================================================================================
Package 架构 版本 源 大小
======================================================================================================
正在删除:
nginx x86_64 1:1.12.2-3.el7 @epel 1.5 M
为依赖而移除:
nginx-all-modules noarch 1:1.12.2-3.el7 @epel 0.0
nginx-mod-http-geoip x86_64 1:1.12.2-3.el7 @epel 21 k
nginx-mod-http-image-filter x86_64 1:1.12.2-3.el7 @epel 24 k
nginx-mod-http-perl x86_64 1:1.12.2-3.el7 @epel 54 k
nginx-mod-http-xslt-filter x86_64 1:1.12.2-3.el7 @epel 24 k
nginx-mod-mail x86_64 1:1.12.2-3.el7 @epel 99 k
nginx-mod-stream x86_64 1:1.12.2-3.el7 @epel 157 k
事务概要
======================================================================================================
移除 1 软件包 (+7 依赖软件包)
安装大小:1.9 M
是否继续?[y/N]:
Docker 安装
Docker 安装
# 1.下载nginx1.18的docker镜像
docker pull nginx:1.18
# 2.先运行一次容器(为了拷贝容器内nginx配置文件),:
docker run -itd -p 80:80 --name nginx --restart=always -e TZ="Asia/Shanghai" nginx:1.18
# 3.创建需要挂载的目录
# conf 目录用来存放nginx.conf配置文件
# conf.d 目录用来存放独立导入的conf(include /etc/nginx/conf.d/*.conf;)
# logs 用来存放日志文件的
# www 新建的,用来挂载后面新起的服务或者静态资源
# html nginx主页存放路径
mkdir -p /data/nginx/{conf,conf.d,logs,html,www}
# 4.拷贝配置文件
docker cp nginx:/etc/nginx/nginx.conf /data/nginx/conf/
docker cp nginx:/etc/nginx/conf.d/ /data/nginx/
# 5.删除容器
docker rm -f nginx
# 6.再次运行容器,并且挂载配置文件等目录
docker run -itd --name nginx -p 80:80 \
-v /data/nginx/conf/nginx.conf:/etc/nginx/nginx.conf \
-v /data/nginx/conf.d:/etc/nginx/conf.d \
-v /data/nginx/logs:/var/log/nginx \
-v /data/nginx/html:/usr/share/nginx/html \
-v /data/nginx/www:/usr/share/nginx/www \
nginx:1.18
Docker-compose安装
- 编写文件:docker-compose.yml
version: "3.1"
services:
nginx:
restart: always
container_name: nginx
image: daocloud.io/library/nginx:1.18.0
ports:
- 80:80
volumes:
- /opt/docker_nginx/conf.d:/etc/nginx/conf.d
附:Docker安装Nginx的核心目录及文件路径(主要为标记的 1-4)
/etc/nginx # 所有Nginx⽂件⽬录
=================================================
/etc/nginx/nginx.conf # Nginx配置文件(1)
/etc/nginx/conf.d/ # Nginx子配置文件目录(2)
*.conf # conf文件
/var/log/nginx/ # 日志文件存放目录(3)
access.log # nginx访问⽇志
error.log # 错误⽇志
/usr/share/nginx/html/ # 这是编译安装时Nginx的默认站点⽬录(4)
50x.html # 错误⻚⾯
index.html # 默认⾸⻚
=================================================
Nginx核心基础
默认配置文件详解
- 全局块配置
- events 块配置
- http 块配置
- server 主机设置
- location(URL匹配特定位置的设置)
- server 主机设置
- Nginx 配置文件结构
# 1.全局块
...
# 2.events块
events {
...
}
# 3.http块
http {
# 3.1 http全局块
...
# 3.2 虚拟主机server块
server {
# 1) server全局块
...
# 2) location块
location [PATTERN] {
...
}
location [PATTERN] {
...
}
...
}
server {
...
}
...
}
- 默认的nginx.conf 文件:
# 每个配置项由配置指令和指令参数 2 个部分构成
# user nobody; # 指定Nginx Worker进程运⾏以及⽤户组
worker_processes 1;
#error_log logs/error.log; # 错误日志的存放路径 和错误日志
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid; # 进程PID存放路径
# 事件模块指令,用来指定Nginx的IO模型,
# Nginx支持的有select、poll、kqueue、epoll 等。
# 不同的是epoll用在Linux平台上,而kqueue用在BSD系统中,对于Linux系统,epoll工作模式是首选
events {
use epoll;
# 定义Nginx每个进程的最大连接数, 作为服务器来说: worker_connections * worker_processes,
# 作为反向代理来说,最大并发数量应该是worker_connections * worker_processes/2。
#因为反向代理服务器,每个并发会建立与客户端的连接和与后端服务的连接,会占用两个连接
worker_connections 1024;
}
# 设定http服务器,利用它的反向代理功能提供负载均衡支持
http {
# 设定mime类型,类型由mime.type文件定义
include mime.types;
default_type application/octet-stream;
# $remote_addr与$http_x_forwarded_for用以记录客户端的ip地址;
# $remote_user:用来记录客户端用户名称;
# $time_local: 用来记录访问时间与时区;
# $request: 用来记录请求的url与http协议;
# $status: 用来记录请求状态;成功是200,
# $body_bytes_sent :记录发送给客户端文件主体内容大小;
# $http_referer:用来记录从那个页面链接访问过来的;
# $http_user_agent:记录客户浏览器的相关信息;
# 日志格式设置:
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
# 定义日志输出的路径和模板
#access_log logs/access.log main;
# 是否开启高效传输模式 on开启 off关闭
sendfile on;
# 减少网络报文段的数量
#tcp_nopush on;
# 客户端连接保持活动的超时时间,超过这个时间之后,服务器会关闭该连接
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
# 虚拟主机的配置
server {
listen 80; # 虚拟主机的服务端口
server_name aabbcc.com; # 用来指定IP地址或域名,多个域名之间用空格分开
#charset koi8-r;
# 虚拟主机使用的日志路径和模板
#access_log logs/host.access.log main;
# URL地址匹配
location / {
root html; # 服务默认启动目录
index index.html index.htm; # 默认访问文件,按照顺序找
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html; # 错误状态码的显示页面
location = /50x.html {
root html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
server {
listen 80;
server_name aabbccdd.com;
location / {
root html;
index xdclass.html;
}
}
# another virtual host using mix of IP-, name-, and port-based configuration
#
#server {
# listen 8000;
# listen somename:8080;
# server_name somename alias another.alias;
# location / {
# root html;
# index index.html index.htm;
# }
#}
# HTTPS server
#
#server {
# listen 443 ssl;
# server_name localhost;
# ssl_certificate cert.pem;
# ssl_certificate_key cert.key;
# ssl_session_cache shared:SSL:1m;
# ssl_session_timeout 5m;
# ssl_ciphers HIGH:!aNULL:!MD5;
# ssl_prefer_server_ciphers on;
# location / {
# root html;
# index index.html index.htm;
# }
#}
}
反向代理与动静分离
反向代理服务器
- 什么是虚拟主机( server{} )
- 指在一台物理主机服务器上划分出多个磁盘空间,每个磁盘空间都是一个虚拟主机,每台虚拟主机都可以对外提供Web服务,并且互不干扰,就类似虚拟机
- 利用虚拟主机把多个不同域名的网站部署在同一台服务器上,节省了服务器硬件成本和相关的维护费用
- 案例一:通过建通不同的域名和端口号访问不同的server 和 本地不同的html
# 访问http://aabbcc.com 返回的是 aabbcc.html
server {
listen 80;
server_name aabbcc.com;
# 访问本地绝对路径下的静态html
location / {
root /usr/local/nginx/html;
index aabbcc.html;
}
}
# 访问http://aabbccdd.com 返回的是 aabbccdd.html
server {
listen 80;
server_name aabbccdd.com;
# 访问本地相对路径下的静态html
location / {
root html;
index aabbccdd.html;
}
}
- 案例二:通过不同server监听不同的域名和端口叫跳转不同的资源(或local/path 监听不同的/path 范访问不同的资源)
# 访问:127.0.0.1:82 将访问CSDN
server {
listen 81;
server_name 127.0.0.1;
location ~ /csdn/ {
proxy_pass https://www.csdn.net/;
}
}
# 访问:127.0.0.1:82 将访问百度
server {
listen 82;
server_name 127.0.0.1;
location ~ /baidu/ {
proxy_pass https://www.baidu.com/;
}
}
server {
listen 80;
server_name 127.0.0.1;
# 访问:127.0.0.1/csdn/ 将访问CSDN
location ~ /csdn/ {
proxy_pass https://www.csdn.net/;
}
# 访问:127.0.0.1/baidu/ 将访问百度
location ~ /baidu/ {
proxy_pass https://www.baidu.com/;
}
}
静态资源服务器
- 文件图片服务器
- Web项目图片基本都是上传到项目本身,这种方式现在项目中很少用了
- 现在公司一般会使用图片服务器 或者 云厂商提供的CDN
- 使用流程:前端提交图片->后端处理->存储到图片服务器->拼接好访问路径存储到数据库和范围前端
server {
listen 80;
server_name localhost;
# 访问本地相对路径下的静态html
location / {
# root D:/nginx/www;
root www;
index index.html index.htm;
}
# 对静态资源进行映射,访问路径拼接 upload 访问本地绝对路径下的某图片
location /upload/ {
alias /usr/local/software/img/;
autoindex on; # 开启目录文件列表
}
}
注:root与alias的使用区别
1、root访问的资源路径为 root指定地址+location访问地址,alias访问的资源路径为 alias指定路径;
2、alias只能用于location中,但root在server、http以及location中都能使用;
3、alias后面指定路径必须以 " / " 结尾,是一个文件夹,但root可以不要"/"结尾。
# 用户访问地址:http://location/images/login.jpg
# root模式下:访问的资源路径为: E:/public/images/login.jpg
location /images/ {
root E:/public;
}
# alias模式下:访问的资源路径为: E:/public/login.jpg
location /images/ {
alias E:/public/;
}
开启网站目录浏览
1、开启全站目录浏览功能:nginx.conf,在http下面添加以下内容:
http {
autoindex on; # 开启目录文件列表
autoindex_exact_size on; # 显示出文件的确切大小,单位是bytes(KB)
autoindex_localtime on; # 显示文件修改时间为服务器本地时间,否则以gmt时间显示
charset utf-8,gbk,gb2312; # 避免中文乱码
add_header Content-Disposition attachment; # 文件下载(可以不开启该功能)
# ...
}
2、开启网站部分目录浏览功能:nginx.conf ,在server {} 模块或者 localtion 模块下加入以下内容:
# server {}
server {
autoindex on; # 开启目录文件列表
autoindex_exact_size on; # 显示出文件的确切大小,单位是bytes
autoindex_localtime on; # 显示的文件时间为文件的服务器时间
charset utf-8,gbk,gb2312; # 避免中文乱码
}
# localtion下
server {
location / {
root E:/public;
alias /usr/local/nginx/logs/;# 需要访问的目录
autoindex on; # 开启目录文件列表
autoindex_exact_size on; # 显示出文件的确切大小,单位是bytes
autoindex_localtime on; # 显示的文件时间为文件的服务器时间
charset utf-8,gbk,gb2312; # 避免中文乱码
}
}
目录访问加密
这个功能特性是由ngx_http_auth_basic_module提供的,默认编译nginx时会编译好,主要有以下两个指令。
Syntax: auth_basic string | off;
Default:
auth_basic off;
Context: http, server, location, limit_except
Syntax: auth_basic_user_file file;
Default: —
Context: http, server, location, limit_except
-
认证的配置可以在http指令块,server指令块,location指令块配置。
-
auth_basic string :定义认证的字符串,会通过响应报文返给客户端,也可以通过这个指令关闭认证。
-
auth_basic_user_file file :定义认证文件。
实例:
# 对匹配目录加密:
location /img {
alias /usr/local/nginx/logs/;
auth_basic "User Auth";
auth_basic_user_file /usr/local/nginx/conf/auth.passwd;
}
auth_basic:设置名字auth_basic_user_file:用户认证文件放置路径
生成认证文件:
# 安装工具
$ yum install -y httpd-tools
# 输入两次密码确定。
$ htpasswd -c /usr/local/nginx/conf/auth.passwd admin
重启服务后,访问验证:
会弹出弹窗,需要输入账号/密码。它不仅可以设置访问指定目录时认证还可以直接在访问首页时认证。
如果需要关闭可以使用auth_basic off,或者直接将这两段注释掉。
htpasswd命令工具:
htpasswd(选项)(参数)
选项
-c:创建一个加密文件;
-n:不更新加密文件,只将加密后的用户名密码显示在屏幕上;
-m:默认采用MD5算法对密码进行加密;
-d:采用CRYPT算法对密码进行加密;
-p:不对密码进行进行加密,即明文密码;
-s:采用SHA算法对密码进行加密;
-b:在命令行中一并输入用户名和密码而不是根据提示输入密码;
-D:删除指定的用户。
# 添加用户名及密码:
htpasswd -b /usr/local/nginx/conf/auth.passwd liusx password
# 更新密码:
htpasswd -D /usr/local/nginx/conf/auth.passwd liusx
htpasswd -b /usr/local/nginx/conf/auth.passwd liusx liusx666
Nginx日志挖掘
Nginx访问日志详解
-
access.log日志作用:
- 统计站点访问ip来源、某个时间段的访问频率
- 查看访问最频的页面、Http响应状态码、接口性能
- 接口秒级访问量、分钟访问量、小时和天访问量
- ......等等
-
默认配置解析
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
- 案例:access.log
122.70.148.18 - - [04/Aug/2020:14:46:48 +0800] "GET /user/api/v1/product/order/query_state?product_id=1&token=xdclasseyJhbGciOJE HTTP/1.1" 200 48 "https://xdclass.net/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
- 解析
# 用以记录客户端的ip地址
$remote_addr 对应的是真实日志里的122.70.148.18,即客户端的IP。
# 即记录客户端用户名称
$remote_user 对应的是第二个中杠“-”,没有远程用户,所以用“-”填充。
# 用来记录访问时间与时区
[$time_local]对应的是[04/Aug/2020:14:46:48 +0800]。
# 用来记录请求的url与http协议
“$request”对应的是"GET /user/api/v1/product/order/query_state?product_id=1&token=xdclasseyJhbGciOJE HTTP/1.1"。
# 用来记录请求状态
$status对应的是200状态码,200表示正常访问。
# 记录发送给客户端文件主体内容大小
$body_bytes_sent对应的是48字节,即响应body的大小。
# 用来记录从那个页面链接访问过来的
“$http_referer” 对应的是”https://xdclass.net/“,若是直接打开域名浏览的时,referer就会没有值,为”-“。
# 记录客户浏览器的相关信息
“$http_user_agent” 对应的是”Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:56.0) Gecko/20100101 Firefox/56.0”。
# 用以记录客户端的ip地址
“$http_x_forwarded_for” 对应的是”-“或者空。
# 通常web服务器放在反向代理的后面,这样就不能获取到客户的IP地址了,通过$remote_addr拿到的IP地址是反向代理服务器的iP地址。反向代理服务器在转发请求的http头信息中,可以增加x_forwarded_for信息,用以记录原有客户端的IP地址和原来客户端的请求的服务器地址。
Nginx日志实战统计
1、Nginx统计站点访问量、高频url统计
- 查看访问最频繁的前100个IP
# 查看访问最频繁的前100个IP
awk '{print $1}' access_temp.log | sort -n |uniq -c | sort -rn | head -n 100
# 统计访问最多的url 前20名
cat access_temp.log |awk '{print $7}'| sort|uniq -c| sort -rn| head -20 | more
- 基础
awk 是文本处理工具,默认按照空格切分,$N 是第切割后第N个,从1开始
sort命令用于将文本文件内容加以排序,-n 按照数值排,-r 按照倒序来排
案例的sort -n 是按照第一列的数值大小进行排序,从小到大,倒序就是 sort -rn
uniq 去除重复出现的行列, -c 在每列旁边显示该行重复出现的次数。
2、自定义日志格式,统计接口响应耗时:
- 日志格式增加 $request_time
从接受用户请求的第一个字节到发送完响应数据的时间,即包括接收请求数据时间、程序响应时间、输出响应数据时间
$upstream_response_time:指从Nginx向后端建立连接开始到接受完数据然后关闭连接为止的时间
$request_time一般会比upstream_response_time大,因为用户网络较差,或者传递数据较大时,前者会耗时大很多
- 配置自定义日志格式
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for" $request_time';
server {
listen 80;
server_name localhost;
location / {
root /usr/local/nginx/html;
index .html;
}
# 使用自定义日志模板
access_log logs/host.access.log main;
}
- 统计耗时接口, 列出传输时间超过 2 秒的接口,显示前5条
# 备注:$NF 表示最后一列, awk '{print $NF}'
cat time_temp.log|awk '($NF > 2){print $7}'|sort -n|uniq -c|sort -nr|head -5
Nginx日志切割
nginx日志文件没有rotate功能,不能编写每天生成一个日志,所以我们可以写一个shell脚本定时切割日志文件
需求:
- nginx的日志文件路径
- 每天0点对nginx 的access与error日志进行切割
- 以前一天的日期为命名
步骤:
- 重命名日志文件
- 向nginx主进程发送USR1信号
新建shell脚本:
vim /opt/nginx/nginx_log.sh
脚本内容:
#!/bin/bash
# 设置日志文件存放目录
LOG_PATH="/usr/local/nginx/logs"
# 备分文件名称
YesterDay="$(date -d yesterday +%Y%m%d%H%M)"
# 重命名日志文件
mv ${LOG_PATH}/access.log ${LOG_PATH}/access_${YesterDay}.log
mv ${LOG_PATH}/error.log ${LOG_PATH}/error_${YesterDay}.log
# 向nginx主进程发信号重新打开日志
# nginx -s reopen 等同于 kill -USR1 `cat /usr/local/nginx/logs/nginx.pid`
# /usr/local/nginx/sbin/nginx -s reopen
# kill -USR1 $(cat /usr/local/nginx/logs/nginx.pid)
kill -USR1 `cat /usr/local/nginx/logs/nginx.pid`
配置crontab定时任务:
# 编辑并且添加一行新的任务:
crontab -e
# 每天0时0分进行日志分割(建议在02-04点之间,系统负载小)
00 00 * * * /opt/nginx/nginx_log.sh
# 重启Linux定时任务
systemctl restart crond.service
- 附1:定时删除Nginx 7天前日志
$ pwd
/usr/local/nginx/sh
$ vim delete_nginx_logs.sh
# 添加脚本内容内容
# /usr/local/nginx/logs/ 目录下
# -mtime +7 :7天前的文件
# -name "access_*.log":文件名称匹配access_*.log
# -exec rm -rf 强制删除,包含目录
find /usr/local/nginx/logs/ -mtime +7 -name "access_*.log" -exec rm -rf {} \;
# 添加定时任务,
$ crontab -e
# 每天10时0分进删除
10 0 * * * /bin/sh /usr/local/nginx/sh/delete_nginx_logs.sh > /dev/null 2>&1
- 附2:常用定时任务命令:
systemctl start crond.service # 启动
systemctl stop crond.service # 停止
systemctl restart crond.service # 重新启动
systemctl status crond.service # 查看状态
systemctl reload crond.service # 重新载入配置
# 语法:crontab 【选项】
crontab -l # 列出crontab有哪些任务
crontab -e # 编辑crontab任务
crontab -r # 删除crontab里的所有任务
# 内容格式:
* * * * * 级别 命令
分 时 日 月 周
Nginx集群-负载均衡
Java环境搭建
安装JDK8环境
- 官方地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
- 本地上传JDK1.8到服务器,配置全局环境变量
- 解压:
tar -zxvf jdk-8u171-linux-x64.tar.gz - 移动并重命名:
mv jdk1.8.0_181 /usr/local/software/jdk/jdk8 - 配置环境变量:
vim /etc/profile
JAVA_HOME=/usr/local/software/jdk/jdk8
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
- 环境变量立刻生效:
source /etc/profile - 查看安装情况:
java -version
上传jar包
- 启动应用:
nohup java -jar BiuBiuBiu.jar >/dev/null 2>&1 & - 关闭应用:
kill -9 PID - 查看应用:
ps -ef | grep javalsof -i:portjps
SpringBoot后端集群
SpringBoot应用和接口说明
-
Linux服务器需要安装JDK8
-
准备两个一样的Jar包,或者一个jar包动态指定端口启动
- demo-1.jar监听8080端口
-
demo-2.jar监听8081端口
2.动态指定端口:
- 在命令行中指定启动端口(
--server.port必须放在 xx.jar包后面):
java -jar test.jar --server.port=8080
- 传入虚拟机系统属性:(
-D一般在xx.jar之前)
java -Dserver.port=8081 -jar test.jar
注意:两种方式可以同时配置并且属性一样,有优先级区分
# 最后 name 值为 Spring!
java -Dname="Dname" -jar app.jar --name="Spring!"
-
接口说明
- 接口一
- GET请求,返回json数据,控制输出日志
- http://127.0.0.1:8080/api/v1/pub/info/check
- 接口二
- 返回HTML页面,两个jar返回的HTML内容不一样,方便区分访问的是哪个jar
- http://localhost:8080/api/v1/pub/web
- 接口一
-
直接启动
java -jar demo.jar --server.port=8080
java -jar demo.jar --server.port=8081
- 守护进程方式
nohup java -jar demo.jar --server.port=8080 &
nohup java -jar demo.jar --server.port=8081 &
Nginx负载均衡-upstream
简介:Nginx的upstream模板介绍
-
负载均衡(Load Balance)
- 分布式系统中一个非常重要的概念,当访问的服务具有多个实例时,需要根据某种“均衡”的策略决定请求发往哪个节点,这就是所谓的负载均衡,
- 原理是将数据流量分摊到多个服务器执行,减轻每台服务器的压力,从而提高了数据的吞吐量
-
负载均衡的种类
- 通过硬件来进行解决,常见的硬件有NetScaler、F5、Radware和Array等商用的负载均衡器,但比较昂贵的
- 通过软件来进行解决,常见的软件有LVS、Nginx等,它们是基于Linux系统并且开源的负载均衡策略
- 目前性能和成本来看,Nginx是目前多数公司选择使用的
-
配置案例
# 集群服务配置
upstream lbs {
server localhost:8080;
server localhost:8081;
}
server {
....
location /api/ {
proxy_pass http://lbs;
proxy_redirect default;
}
}
server-静态模拟集群
# 集群服务配置
upstream lbs {
server localhost:8080;
server localhost:8081;
}
# 配置需要访问集群代理的入口
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://lbs;
proxy_redirect default;
}
}
# 模拟后端服务1
server {
listen 8080;
server_name localhost;
location / {
default_type text/html ;
return 200 '===== 8080 =====';
}
location /api {
default_type text/html ;
return 200 '===== api-8080 =====';
}
}
# 模拟后端服务2
server {
listen 8081;
server_name localhost;
location / {
default_type text/html ;
return 200 '===== 8081 =====';
}
location /api {
default_type text/html ;
return 200 '===== api-8081 =====';
}
}
- 测试:
$ curl localhost
===== 8080 =====
$ curl localhost
===== 8081 =====
$ curl localhost/api
===== api-8080 =====
$ curl localhost/api
===== api-8081 =====
备注:如果是Docker安装的Nginx,nginx -s reload 是没用的,需要重启Nginx服务:docker restart nginx
负载均衡策略解析
Nginx常见的负载均衡策略
-
节点轮询(默认)
- 简介:每个请求按顺序分配到不同的后端服务器
- 场景:会造成可靠性低和负载分配不均衡,适合静态文件服务器
-
weight(权重配置)
- 简介:weight和访问比率成正比,数字越大,分配得到的流量越高
- 场景:服务器性能差异大的情况使用
upstream lbs { server 192.168.159.133:8080 weight=5; server 192.168.159.133:8081 weight=10; } -
ip_hash(固定分发)
- 简介:根据请求按访问ip的hash结果分配,这样每个用户就可以固定访问一个后端服务器
- 场景:服务器业务分区、业务缓存、Session需要单点的情况
upstream lbs { ip_hash; server 192.168.159.133:8080; server 192.168.159.133:8081; }
节点参数配置:
| 参数 | 描述 |
|---|---|
| backup | 标记该服务器为备用服务器。当主服务器停止时,请求会被发送到它这里。 |
| down | 标记服务器永久停机了。表示当前的server暂时不参与负载 |
| max_fails | 允许请求失败的次数,默认为1。当超过最大次数时就不会请求。认为该服务器会已停机 |
| fail_timeout | 与 max_fails 结合使用,max_fails 次失败后,暂停请求的时间,默认 fail_timeout 为10s |
-
upstream还可以为每个节点设置状态值
- down:表示当前的server暂时不参与负载
- backup:其它所有非backup机器down时,会请求backup机器,这台机器压力会最轻,配置也会相对低
upstream lbs { server 192.168.159.133:8080; server 192.168.159.133:8081 down; } upstream 2bs { server 192.168.159.133:8080; server 192.168.159.133:8081 backup; } -
如果某个应用挂了,请求不应该继续分发过去
-
max_fails:允许请求失败的次数,默认为1.当超过最大次数时就不会请求
-
fail_timeout : max_fails次失败后,暂停的时间,默认:fail_timeout为10s
-
参数解释
- max_fails=N 设定Nginx与后端节点通信的尝试失败的次数。
- 在 fail_timeout 参数定义的时间内,如果失败的次数达到此值,Nginx就这个节点不可用。
- 在下一个fail_timeout时间段到来前,服务器不会再被尝试。
- 失败的尝试次数默认是1,如果设为0就会停止统计尝试次数,认为服务器是一直可用的。
-
具体什么是nginx认为的失败呢
- 可以通过指令 proxy_next_upstream来配置什么是失败的尝试。
- 注意默认配置时,http_404状态不被认为是失败的尝试。
upstream lbs { server 192.168.0.106:8080 max_fails=2 fail_timeout=60s ; server 192.168.0.106:8081 max_fails=2 fail_timeout=60s; } location /api/ { proxy_pass http://lbs; proxy_next_upstream error timeout http_500 http_503 http_404; }
-
案例实操
- 暂停一个后节点,然后访问接口大于10次,Nginx会把这个节点剔除
- 重启这个节点,在fail_timeout周期里面不会再获取流量
Nginx深入配置
Nginx全局异常处理
- Nginx自定义全局异常json数据
- 任何接口都是可能出错,4xx、5xx等错误,直接暴露给用户,无疑是看不懂
- 所以假如后端某个业务出错,nginx层也需要进行转换
- 让前端知道http响应是200,其实是将错误的状态码定向至200,返回了全局兜底数据
server{
listen 80; # 监听80端口
server_name localhost; # 对应的域名或者IP
location / {
proxy_pass http://192.168.0.106:8080;
proxy_redirect default;
# 开启错误拦截配置,一定要开启
proxy_intercept_errors on;
# 存放用户的真实ip,Nginx代理的服务想要拿到请求接口的真实ip需要如下配置
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# 那些是失败错误页面
proxy_next_upstream error timeout http_503 non_idempotent;
}
# 不加 =200,则返回的就是原本的http错误码;
# 配上后如果出现500等错误都返回给用户200状态,并跳转至/default_api
error_page 404 500 502 503 504 =200 /default_api;
location = /default_api {
default_type application/json;
return 200 '{"code":"-1","msg":"invoke fail, not found "}';
}
# 或者直接返回错误码json
error_page 403 /respon_403.json;
location = /respon_403.json {
default_type application/json;
return 403 '{"code":"403","status":"error","message":"Forbidden"}';
}
}
- Nginx自定义全局异常html页面返回
server{
listen 80; # 监听80端口
server_name localhost; # 对应的域名或者IP
proxy_intercept_errors on; # 开启错误拦截配置,一定要开启
location / {
root /usr/local/nginx/html;
index index.html; # 主页文件
}
# 如果出现404,则返回/404.html页面
error_page 404 /404.html;
location = /404.html {
root /usr/local/nginx/html;
}
# 如果出现50x,则返回/50x.html页面
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/local/nginx/html;
}
}
Nginx封禁恶意IP
简介:Nginx封禁恶意IP
-
网络攻击时有发生:1、TCP洪水攻击、注入攻击、DOS等。2、比较难防的有DDOS等
-
数据安全,防止对手爬虫恶意爬取,封禁IP
-
一般封禁ip方式:
- linux server的层面封IP:iptables、
- nginx的层面封IP ,方式多种 (但 req还是会打进来, 让nginx 返回 403, 占用资源)
- Nginx作为网关,可以有效的封禁ip
# 所有网站屏蔽IP的方法,把include xxx; 放到http {}语句块。 # 单独网站屏蔽IP的方法,把include xxx; 放到网址对应的在server{}语句块,虚拟主机 # 单独接口屏蔽IP的方法,把include xxx; 放到local{}语句块。 # nginx配置如下: http{ # .... # 引入黑名单配置文件 include blacklist.conf; server{ listen 80; # 监听80端口 server_name localhost; # 对应的域名或者IP location / { proxy_pass http://localhost:8080; proxy_redirect default; } } }# blacklist.conf文件内容 deny 192.168.159.2; deny 192.168.159.32;- ./nginx -s reload:# 重新加载配置,不中断服务
相关配置语句
# 1.屏蔽单个ip访问——格式: deny ip;
deny 123.68.23.5;
# 2.允许单个ip访问——格式: allow ip;
allow 123.68.25.6;
# 3.屏蔽所有ip访问——格式:deny all;
deny all;
# 4.允许所有ip访问——格式:allow all;
allow all;
# 5.屏蔽ip段访问——格式:deny ip/mask
# 屏蔽172.12.62.0到172.45.62.255访问的命令
deny 172.12.62.0/24;
# 6.允许ip段访问——格式:allow ip/mask
# 屏蔽172.102.0.0到172.102.255.255访问的命令
allow 172.102.0.0/16;
配置说明
-
可新建一个配置文件,如blockip.conf。在其中编写相关的ip限制语句,然后在nginx.conf中加入如下配置:
# 配置ip限制策略 include blockip.conf; -
nginx会根据配置文件中的语句,从上至下依次判断。因此,写在前面的语句可能会屏蔽后续的语句。
-
除部分ip白名单外,屏蔽所有ip的错误示例
deny all; # 该语句已经禁止所有ip的访问,后续的配置不会生效 allow 123.45.25.6; allow 123.68.52.125; allow 123.125.25.106; -
正确示例
# 允许部分ip访问 allow 123.45.25.6; allow 123.68.52.125; allow 123.125.25.106; # 禁止其余ip访问 deny all;
-
-
屏蔽策略文件可以放在http, server, location, limit_except语句块中,我们可以根据需要合理的配置。
放置位置 效果 备注 http nginx中所有服务起效 - server 指定的服务起效 - location 满足的location下起效 - limit_except 指定的http方法谓词起效 -
- 拓展-自动化封禁思路
- 编写shell脚本
- AWK统计access.log,记录每秒访问超过60次的ip,然后配合nginx或者iptables进行封禁
- crontab定时跑脚本
Nginx配置浏览器跨域
- 跨域:浏览器同源策略 1995年,同源政策由 Netscape 公司引入浏览器。目前,所有浏览器都实行这个政策。 最初,它的含义是指,A网页设置的 Cookie,B网页不能打开,除非这两个网页"同源"。所谓"同源"指的是"三个相同"
三个相同为(同源):
协议相同 http https
域名相同 www.xdclass.net
端口相同 80 81
一句话:浏览器从一个域名的网页去请求另一个域名的资源时,域名、端口、协议任一不同,都是跨域
浏览器控制台跨域提示:
No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'null' is therefore not allowed access.
-
解决方法
- JSONP
- Http响应头配置允许跨域
- nginx层配置
- 程序代码中处理通过拦截器配置
-
Nginx开启跨域配置
- location下配置
location / { # 如下为跨域配置 add_header 'Access-Control-Allow-Origin' $http_origin; add_header 'Access-Control-Allow-Credentials' 'true'; add_header ‘'Access-Control-Allow-Methods' 'GET,POST,OPTIONS'; add_header 'Access-Control-Allow-Headers' 'DNT,web-token,app-token,Authorization,Accept,Origin,Keep-Alive,User-Agent,X-Mx-ReqToken,X-Data-Type,X-Auth-Token,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range'; add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range'; # 如果预检请求则返回成功,不需要转发到后端 if ($request_method = 'OPTIONS') { add_header 'Access-Control-Max-Age' 1728000; add_header 'Content-Type' 'text/plain; charset=utf-8'; add_header 'Content-Length' 0; return 200; } }
下面简单讲解一下配置,以便大家配置成功!
1、Access-Control-Allow-Origin:允许跨域请求的域,$http_origin取得当前来源域,*代表所有
2、Access-Control-Allow-Credentials:为 true 的时候指请求时允许带上Cookie,自己按情况配置吧
3、Access-Control-Allow-Methods:OPTIONS一定要有的,另外一般也就GET和POST,*代表所有
4、Access-Control-Allow-Headers:允许请求的header。这个要注意,里面一定要包含自定义的http头字段(就是说前端请求接口时,如果在http头里加了自定义的字段,这里配置一定要写上相应的字段),从上面可看到我写的比较长,我在网上搜索一些常用的写进去了,里面有“web-token”和“app-token”,这个是我项目里前端请求时设置的,所以我在这里要写上;
5、Access-Control-Expose-Headers:可不设置,看网上大致意思是默认只能获返回头的6个基本字段,要获取其它额外的,先在这设置才能获取它;
6、语句“ if ($request_method = 'OPTIONS') { ”,因为浏览器判断是否允许跨域时会先往后端发一个 options 请求,然后根据返回的结果判断是否允许跨域请求,所以这里单独判断这个请求,然后直接返回;
下面发一个实际配置供参考,我做了少量更改,如下:
server {
listen 80;
server_name xxx.com;
location /xxx-web/papi {
# 配置跨域 start
add_header 'Access-Control-Allow-Origin' $http_origin;
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'DNT,web-token,app-token,Authorization,Accept,Origin,Keep-Alive,User-Agent,X-Mx-ReqToken,X-Data-Type,X-Auth-Token,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range';
add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range';
if ($request_method = 'OPTIONS') {
add_header 'Access-Control-Max-Age' 1728000;
add_header 'Content-Type' 'text/plain; charset=utf-8';
add_header 'Content-Length' 0;
return 204;
}
# 配置跨域 end
root html;
index index.html index.htm;
proxy_pass http://127.0.0.1:7071;
# 存放用户的真实ip,Nginx代理的服务想要拿到请求接口的真实ip需要如下配置
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_connect_timeout 5;
}
location /xxx-web {
add_header 'Access-Control-Allow-Origin' $http_origin;
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'DNT,web-token,app-token,Authorization,Accept,Origin,Keep-Alive,User-Agent,X-Mx-ReqToken,X-Data-Type,X-Auth-Token,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range';
add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range';
if ($request_method = 'OPTIONS') {
add_header 'Access-Control-Max-Age' 1728000;
add_header 'Content-Type' 'text/plain; charset=utf-8';
add_header 'Content-Length' 0;
return 204;
}
root html;
index index.html index.htm;
proxy_pass http://127.0.0.1:8080;
# 存放用户的真实ip,Nginx代理的服务想要拿到请求接口的真实ip需要如下配置
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_connect_timeout 5;
}
location / {
root /var/www/xxx/wechat/webroot;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
Nginx-locatioin规则
1、location语法
location [ = | 空格 | ~ | ~* | ^~ ] uri {
...
}
- 精准匹配: =
- 字符串匹配: 空格
- 优于正则匹配: ^~
- 正则匹配: ~ | ~* | !~ | !~*
- 通用匹配: /
其中:" ~ "表示:正则匹配且区分大小写;" ~ *"表示:正则匹配且不区分大小写;加" ! "代表:不匹配;^ 以什么开始,$ 以什么结束;
2、多个location的匹配顺序(优先级)
第一步:匹配带 " = " 的精准匹配,若匹配上,则直接返回;
第二步:匹配带 " 空格 " 的字符串匹配,若匹配上则先保存,不直接返回;
第三步:匹配带 " ^~ "的优于正则匹配,若匹配上了,则直接返回;
第四步:匹配带 " ~ | ~* | !~ | !~* "的正则匹配,若匹配,则直接返回;若没匹配,但第二步匹配上了,则直接返回第二步匹配上的;
第五步:匹配仅 " / " 的通用匹配,这个是任意访问路径都能匹配上的,直接返回。
注:
-
1、在同一级匹配规则下,按照在配置文件中的先后顺序匹配判断,匹配中了就立即返回(字符串匹配不直接返回);
-
2、对于字符串匹配,总是暂存匹配字符串最长的那一个记录。
-
优先级(不要写复杂,容易出问题和遗忘)
-
精准匹配 > 字符串匹配(若有多个匹配项匹配成功,那么选择匹配长的并记录) > 正则匹配
3、配置案例:
server {
listen 80;
server_name localhost;
# 避免中文乱码
charset utf-8,gbk,gb2312;
# 精准匹配
location = /public/index.html {
default_type text/html ;
return 601 '===============精准匹配601【location = /public/index.html】===============';
}
# 字符串匹配
location /public/index.html {
default_type text/html ;
return 611 '===============字符串匹配611【location /public/index.html】===============';
}
location /public/login.html {
default_type text/html ;
return 612 '===============字符串匹配612【location /public/login.html】===============';
}
location /public/ {
default_type text/html ;
return 613 '===============字符串匹配613【location /public/】===============';
}
location /public/second.html {
default_type text/html ;
return 614 '===============字符串匹配614【location /public/second.html】===============';
}
# 优于正则匹配
# 优于正则匹配中不能写与字符串匹配相同的访问路径,没有意义。
# location ^~ /public/index.html {
# default_type text/html ;
# return 621 '===============优于正则匹配621【location ^~ /public/index.html】===============';
# }
location ^~ /public/regist.html {
default_type text/html ;
return 623 '===============优于正则匹配623【location ^~ /public/regist.html】===============';
}
location ^~ /public/first.html {
default_type text/html ;
return 623 '===============优于正则匹配623_1【location ^~ /public/first.html】===============';
}
# 正则匹配
location ~ \/public\/index\.html$ {
default_type text/html ;
return 631 '===============正则匹配631【location ~ \/public\/index\.html】===============';
}
location ~ \/public\/first\.html$ {
default_type text/html ;
return 633 '===============正则匹配633_1【location ~ \/public\/first\.html】===============';
}
location ~ \/public\/second\.html$ {
default_type text/html ;
return 634 '===============正则匹配634【location ~ \/public\/second\.html】===============';
}
# 通用匹配
location / {
default_type text/html ;
return 640 '===============通用匹配640【location /】===============';
}
}
4、案例说明
# 1、【精准匹配】请求地址:
$ curl http://localhost/public/index.html
===============精准匹配601【location = /public/index.html】===============
# 2、【字符串匹配】请求地址:
$ curl http://localhost/public/login.html
===============字符串匹配612【location /public/login.html】===============
# 3、【优于正则匹配】请求地址:
$ curl http://localhost/public/regist.html
===============优于正则匹配623【location ^~ /public/regist.html】===============
# 3-1、【优于正则匹配】请求地址:
$ curl http://localhost/public/first.html
===============优于正则匹配623_1【location ^~ /public/first.html】===============
# 4、【正则匹配】请求地址:
$ curl http://localhost/public/second.html
===============正则匹配634【location ~ \/public\/second\.html】===============
注:实际上是经过"字符串匹配 [location /public/second.html] "将返回结果暂存,再经过"优于正则匹配",未发现匹配成功的,再经过"正则匹配"发现匹配成功的,最终返回"正则匹配"结果。
# 5、【通用匹配】请求地址:
$ curl http://localhost/static/common.html
===============通用匹配640【location /】===============
注:当经过所有的匹配规则之后,都没有匹配成功的,则进入"通用匹配",所有请求都能匹配成功。
^ 以什么开始,$ 以什么结束
^/api/user$
-
location 路径匹配:location [ = | 空格 | ~ | ~* | ^~ ] uri
-
location = /uri:"=" 表示精准匹配,只要完全匹配上才能生效
-
location /uri:不带任何修饰符(空格匹配),表示前缀匹配
-
location ^~ /uri/:匹配任何已 /uri/ 开头的任何查询并且停止搜索
-
location /:通用匹配,任何未匹配到其他location的请求都会匹配到
-
正则匹配:区分大小写匹配()、不区分大小写匹配(*)
-
优先级(不要写复杂,容易出问题和遗忘)
-
精准匹配 > 字符串匹配(若有多个匹配项匹配成功,那么选择匹配长的并记录) > 正则匹配
-
案例
server {
...
location ~^/api/pub$ {
...
}
}
^/api/pub$:这个正则表达式表示字符串必须以/开始,以b $结束,中间必须是/api/pub
http://xdclass.net/api/v1 匹配(完全匹配)
http://xdclass.net/API/PUB 不匹配,大小写敏感
http://xdclass.net/api/pub?key1=value1 匹配
http://xdclass.net/api/pub/ 不匹配
http://xdclass.net/api/public 不匹配,不能匹配正则表达式
- 测试
location = /img/test.png {
return 1;
}
location /img/test.png {
return 2;
}
location ^~/img/ {
return 3;
}
location = / {
return 4;
}
location / {
return 5;
}
Nginx-rewrite--重定向
1、rewrite 地址重定向,实现URL重定向的重要指令,他根据regex(正则表达式)来匹配内容跳转到
- 指令语法:
rewrite regex replacement [flag]; - 默认值:none
- 应用位置:server、location、if 中
简单案例:
# 这是一个正则表达式,匹配完整的域名和后面的路径地址
# replacement部分是 https://xdclass.net/$1,$1是取自regex部分()里的内容
rewrite ^/(.*) https://xdclass.net/$1 permanent
# 匹配成功后跳转到百度,执行永久301跳转
rewrite ^/(.*) http://www.baidu.com/ permanent;
- 常用正则表达式:
| 字符 | 描述 |
|---|---|
| \ | 将后面接着的字符标记为一个特殊字符或者一个原义字符或一个向后引用 |
| ^ | 匹配输入字符串的起始位置 |
| $ | 匹配输入字符串的结束位置 |
| * | 匹配前面的字符零次或者多次 |
| + | 匹配前面字符串一次或者多次 |
| ? | 匹配前面字符串的零次或者一次 |
| . | 匹配除“\n”之外的所有单个字符 |
| (pattern) | 匹配括号内的pattern |
- rewrite 最后一项 flag 参数:
| 标记符号 | 说明 |
|---|---|
| last | 本条规则匹配完成后继续向下匹配新的location URI规则 |
| break | 本条规则匹配完成后终止,不在匹配任何规则 |
| redirect | 返回302临时重定向 |
| permanent | 返回301永久重定向 |
-
应用场景
- 非法访问跳转,防盗链(图片)
- 网站更换新域名
- http跳转https
- 不同地址访问同一个虚拟主机的资源
- 根据特殊的变量、目录、客户端信息进行跳转
-
常用301跳转:
之前我们通过用起别名的方式做到了不同地址访问同一个虚拟主机的资源,现在我们可以用一个更好的方式做到这一点,那就是跳转的方法。
# 添加个server区块做跳转
server {
listen 80;
server_name 127.0.0.1;
rewrite ^/(.*) http://127.0.0.1:82/$1 permanent;
}
server {
listen 82;
server_name 127.0.0.1;
location / {
default_type text/html ;
return 200 'index';
}
location /public {
default_type text/html ;
return 200 'public';
}
location /1 {
default_type text/html ;
return 200 '1111';
}
}
然后访问:
127.0.0.1 (跳转到)=》127.0.0.1:82/ =》返回 index
127.0.0.1/public (跳转到)=》127.0.0.1:82/public =》返回 public
127.0.0.1/1 (跳转到)=》127.0.0.1:82/1 =》返回 1111
-
域名跳转:
我们不仅可以做相同虚拟主机的资源域名跳转,也能做不同虚拟主机的域名跳转,我们下面就跳转下当访问brian.com域名的时候跳转到www.baidu.com的页面:
server {
listen 80;
server_name localhost;
if ( $http_host ~* "^(.*)") {
set $domain $1;
rewrite ^(.*) http://www.baidu.com break;
}
}
然访问:localhost (跳转到)=》http://www.baidu.com
Nginx-Websocket反向代理
- 配置
server {
listen 80;
server_name localhost;
location / {
# 添加wensocket代理,websocket服务器。不用管 ws://
proxy_pass http://xdclass.net;
# websocket空闲保持时长
proxy_read_timeout 300s;
# 存放用户的真实ip,Nginx代理的服务想要拿到请求接口的真实ip需要如下配置
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# WebSocket反向代理配置
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
}
}
- 核心是下面的配置 其他和普通反向代理没区别, 表示请求服务器升级协议为WebSocket
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
- 服务器处理完请求后,响应如下报文# 状态码为101
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: upgrade
Nginx服务端缓存配置
常见的开发人员控制的缓存分类
- 服务端缓存(数据库缓存、Redis缓存)
- Nginx缓存
- 客户端缓存(前端缓存)
Nginx-代理缓存流程:
-
第一步:客户端第一次向Nginx请求数据a;
-
第二步:当Nginx发现缓存中没有数据a时,会向服务端请求数据a;
-
第三步:服务端接收到Nginx发来的请求,则返回数据a到Nginx,并且缓存在Nginx;
-
第四步:Nginx返回数据a给客户端应用;
-
第五步:客户端第二次向Nginx请求数据a;
-
第六步:当Nginx发现缓存中存在数据a时,则不会请求服务端;
-
第七步:Nginx把缓存中的数据a返回给客户端应用。
-
/root/cache:
- 本地路径,用来设置Nginx缓存资源的存放地址
-
levels=1:2
- 默认所有缓存文件都放在上面指定的根路径中,可能影响缓存的性能,推荐指定为 2 级目录来存储缓存文件;1和2表示用1位和2位16进制来命名目录名称。第一级目录用1位16进制命名,如a;第二级目录用2位16进制命名,如3a。所以此例中一级目录有16个,二级目录有16*16=256个,总目录数为16 * 256=4096个。
- 当levels=1:1:1时,表示是三级目录,且每级目录数均为16个
-
key_zone
- 在共享内存中定义一块存储区域来存放缓存的 key 和 metadata
-
max_size
- 最大 缓存空间, 如果不指定会使用掉所有磁盘空间。当达到 disk 上限后,会删除最少使用的 cache
-
inactive
- 某个缓存在inactive指定的时间内如果不访问,将会从缓存中删除
-
proxy_cache_valid
- 配置nginx cache中的缓存文件的缓存时间,proxy_cache_valid 200 304 2m 对于状态为200和304的缓存文件的缓存时间是2分钟
-
use_temp_path
- 建议为 off,则 nginx 会将缓存文件直接写入指定的 cache 文件中
-
proxy_cache
- 启用proxy cache,并指定key_zone,如果proxy_cache off表示关闭掉缓存
-
add_header Nging-Cache "$upstream_cache_status"
- 用于前端判断是否是缓存,miss、hit、expired(缓存过期)、updating(更新,使用旧的应答)
proxy_cache_path /root/cache levels=1:2 keys_zone=xd_cache:10m max_size=1g inactive=60m use_temp_path=off;
server {
listen 80;
server_name localhost;
location / {
proxy_cache xd_cache;
proxy_cache_valid 200 304 10m;
proxy_cache_valid 404 1m;
proxy_cache_key $host$uri$is_args$args;
add_header Nginx-Cache "$upstream_cache_status";
}
}
还原nginx配置,只保留upstream模块
-
配置实操
- 请求后端json接口,通过控制台日志判断是否有到后端服务
-
注意:
- nginx缓存过期影响的优先级进行排序为:inactvie > 源服务器端Expires/max-age > proxy_cache_valid
- 如果出现 Permission denied 修改nginx.conf,将第一行修改为 user root
- 默认情况下GET请求及HEAD请求会被缓存,而POST请求不会被缓存,并非全部都要缓存,可以过滤部分路径不用缓存
-
缓存清空
- 直接rm删除
- ngx_cache_purge
-
缓存命中率统计
- 前端打点日志上报
- nginx日志模板增加信息
- $upstream_cache_status
Nginx静态资源压缩
通过Nginx访问的静态文件下载到浏览器客户端超过10秒,这时候要注意是否进行了gzip压缩,看响应头response header
- 压缩配置:对文本、js和css文件等进行压缩,一般是压缩后的大小是原始大小的25%
# 开启压缩(gzip),减少我们发送的数据量
gzip on;
# 是否压缩临界值,即文件大小大于 1k 才去压缩
# 该指令设置页面的字节数,当响应页面的大小大于该值时才启用Gzip功能。建议设置成 1024;
gzip_min_length 1k;
# 设置Gzip压缩文件使用缓存空间的大小,默认值是:gzip_buffers 32 4k|16 8k,4个单位为16k的内存作为压缩结果流缓存
gzip_buffers 4 16k;
# gzip压缩比,可在1~9中设置,1压缩比最小,速度最快,9压缩比最大,速度最慢,消耗CPU
gzip_comp_level 4;
# 设置哪种类型可以进行压缩,需要什么类型可以在参考nginx.conf同目录下的mime.types文件
gzip_types application/javascript text/plain text/css application/json application/xml text/javascript;
# 给代理服务器用的,有的浏览器支持压缩,有的不支持,所以避免浪费不支持的也压缩,所以根据客户端的HTTP头来判断,是否需要压缩
gzip_vary on;
# 禁用IE6以下的gzip压缩,IE某些版本对gzip的压缩支持很不好
gzip_disable "MSIE [1-6].";
# 设置http1.1协议才进行压缩 默认为1.1
gzip_http_version 1.1;
- 注意:gzip 可配置在http{ } 和 server{ }内。
- 压缩前后区别(上传js文件进行验证)
location /static {
alias /usr/local/software/static;
}
面试题:压缩是时间换空间,还是空间换时间?
- web层主要涉及浏览器和服务器的网络交互,而网络交互显然是耗费时间的
- 要尽量减少交互次数
- 降低每次请求或响应数据量。
- 开启压缩
- 在服务端是时间换空间的策略,服务端需要牺牲时间进行压缩以减小响应数据大小
- 压缩后的内容可以获得更快的网络传输速度,时间是得到了优化
- 所以是双向的
Nginx-Https配置
1.什么是https与https好处
- 什么是Https,和http的区别
- HTTPS (Secure Hypertext Transfer Protocol)安全超文本传输协议,是身披SSL外壳的HTTP
- HTTPS是一种通过计算机网络进行安全通信的传输协议,经由HTTP进行通信,利用SSL/TLS建立全信道,加密数据包。
- 为什么要用呢
- HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,要比 HTTP 协议安全,可防止数据在传输过程中被窃取、改变,确保数据的完整性
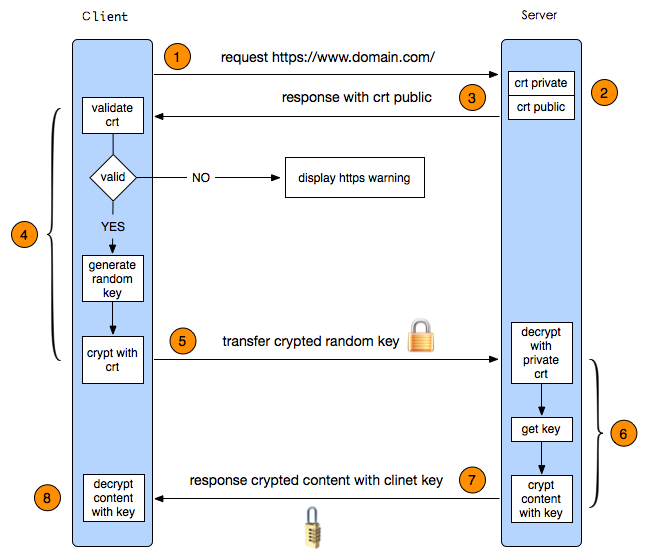
- 流程
- 秘钥交换使用非对称加密,内容传输使用对称加密的方式
2.阿里云Https证书申请
- 证书申请->审核等待->证书上传:https://common-buy.aliyun.com/?commodityCode=cas
3.Nginx配置Https证书
- 删除原先的nginx,新增ssl模块
./configure --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module
make
make install
#查看是否成功
/usr/local/nginx/sbin/nginx -V
- Nginx配置https证书
server {
listen 443 ssl;
server_name 16web.net;
ssl_certificate /usr/local/software/biz/key/4383407_16web.net.pem;
ssl_certificate_key /usr/local/software/biz/key/4383407_16web.net.key;
ssl_session_cache shared:SSL:1m;
ssl_session_timeout 5m;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_prefer_server_ciphers on;
location / {
root html;
index index.html index.htm;
}
}
-
https访问实操
- 杀掉原先进程
- 防火墙关闭或者开放443端口:service firewalld stop
service firewalld stop- 网络安全组开放端口
Nginx限流限速控并发
针对流控和并发 Nginx 可以对三个模块进行配置:
limit_conn_zone模块:限制同一 IP 地址并发连接数;即并发限制limit_req_zone模块: 限制同一 IP 某段时间的请求数或访问量;即速率限制core模块:提供 limit_rate 限制同一 IP 流量。
在 Nginx 中 以 LIMIT 开头的 配置项,都是做限制功能,以上三个功能都是 Nginx 编译后就有的功能,属于内置模块。
limit_conn_zone 模块
使用 ngx_http_limit_conn_module 模块可以 限制用户的连接数的,即限制同一用户 IP 地址的并发连接数,该模块为内置模块。
这个模块用来限制单个IP的请求数。并非所有的连接都被计数。只有在服务器处理了请求并且已经读取了整个请求头时,连接才被计数。
指令
limit_conn_zone 指令
语法:limit_conn_zone key zone=name:size;
默认:无
区域:http
示例:(该指令定义 某个 zone,该 zone 存储会话的状态)
http {
# 如下配置定义了两个 zone
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn_zone $server_name zone=perserver:10m; # 设置虚拟主机同时的链接总数限制。
server {
....
}
}
第一个参数:$binary_remote_addr 是获取客户端ip地址的变量,长度为 4 字节,会话信息的长度为 32 字节。也可以使用如$server_name作为KEY来限制域名级别的最大连接数;
第二个参数:zone=perip:10m 表示生成一个大小为10M,名字为perip的内存区域,10m会话状态储存的空间
说明:区域名称为perip,大小为10m,键值是客户端IP。 如果限制域的存储空间耗尽,对于后续所有请求,服务器都会返回 503 错误。
备注:
在这里,客户端IP地址作为关键。请注意,不是 $remote_addr,而是使用 $binary_remote_addr变量。 $remote_addr变量的大小可以从7到15个字节不等。存储的状态在32位平台上占用32或64字节的内存,在64位平台上总是占用64字节。对于IPv4地址,$binary_remote_addr`变量的大小始终为4个字节,对于IPv6地址则为16个字节。存储状态在32位平台上始终占用32或64个字节,在64位平台上占用64个字节。一个兆字节的区域可以保持大约32000个32字节的状态或大约16000个64字节的状态。如果区域存储耗尽,服务器会将错误返回给所有其他请求。
limit_conn 指令
语法:limit_conn zone number;
默认:无
区域:http、server、location
功能:该指令用于为一个会话设定最大并发连接数。如果并发请求超过这个限制,那么将返回预定错误(limit_conn_status )
示例一:
http {
limit_conn_zone $binary_remote_addr zone=perip:10m;
server {
location /download/ {
limit_conn perip 1; # 一次每个IP地址只允许一个连接。
}
}
}
示例二:
http {
limit_conn_zone $binary_remote_addr zone=perip:10m; # 设置同一客户端ip地址访问限制
limit_conn_zone $server_name zone=perserver:10m; # 设置虚拟主机同时的链接总数限制(同一server最大并发数)
server {
limit_conn perip 10; # 表示限制每个客户端IP的最大并发连接数10
limit_conn perserver 100; # 表示该服务提供的总连接数不得超过100,
}
}
limit_conn_status 指令
语法:limit_conn_status code;
默认:limit_conn_status 503;
区域:http、server、location
功能:设置要返回的状态码以响应被拒绝的请求。
limit_conn_log_level 指令
语法:limit_conn_log_level info | notice | warn | error
默认值:limit_conn_log_level error;
区域:http、server、location
功能:该指令用于设置日志的错误级别,当达到连接限制时,将会产生错误日志。
limit_conn_zone 测试
对 limit_conn_zone 模块的功能进行测试。
(1)测试1:对页面访问的并发限制
首先,来尝试用户对页面访问的并发限制,配置如下:
limit_conn_zone $binary_remote_addr zone=perip:10m;
server {
listen 80;
server_name localhost;
location / {
limit_conn perip 1;
root /usr/share/nginx/www;
index index.html index.htm;
}
}
通过配置,设定 location /download 这个区域,每个IP,同一时刻只存在一个连接。注意:并发的概念并不是说 每秒多少连接。
生成一个较大的 index.html 页面:
[root@localhost ~]# cd /data/nginx/www/
[root@localhost www]# for i in {1..10000}; do echo "hello, $i" >> index.html ; done
[root@localhost www]# ll -sh index.html
120K -rw-r--r-- 1 root root 117K Oct 11 02:09 index.html
客户端主机: 通过 ab 命令模拟并发访问:
# -n:总请求数:10、-c:单个时刻并发 10
[root@localhost ~]# ab -n 10 -c 10 http://localhost/
....
Server Software: nginx/1.18.0
Server Hostname: localhost
Server Port: 80
Document Path: /
Document Length: 118894 bytes
# 主要参考如下显示
Concurrency Level: 10
Time taken for tests: 0.002 seconds
Complete requests: 10
Failed requests: 0
Write errors: 0
....
通过上面的测试,只有 0 个连接错误。经过多次测试,这个问题依然存在,也查阅过一些资料,有人表示这是个 BUG 的。目前还是表示疑惑的,希望有人能够帮忙解惑。
(2)测试2:对文件下载进行测试,或者是访问较大的文件
生成一个 100M 的文件,因为局域网 千兆网络,所以生成的比较大。
[root@localhost www]# dd if=/dev/zero of=/data/nginx/www/testfile bs=1M count=100
100+0 records in
100+0 records out
104857600 bytes (105 MB) copied, 0.0382712 s, 2.7 GB/s
[root@localhost www]# ll -sh testfile
100M -rw-r--r-- 1 root root 100M Oct 11 02:19 testfile
然后在用 ab 进行测试:
[root@localhost www]# ab -n10 -c10 http://localhost/testfile
.....
Server Software: nginx/1.18.0
Server Hostname: localhost
Server Port: 80
Document Path: /testfile
Document Length: 153 bytes
# 主要参考如下显示
Concurrency Level: 10
Time taken for tests: 0.045 seconds
Complete requests: 10
Failed requests: 1
(Connect: 0, Receive: 0, Length: 1, Exceptions: 0)
Write errors: 0
Non-2xx responses: 9 # 返回9个非200的请求
.....
经过这次的测试,完成了 10 个并发连接,其中 9 个返回的是 非200 的状态。继续查看 Nginx 日志:
[root@localhost www]# tailf /data/nginx/logs/access.log
172.17.0.1 - - [10/Oct/2020:18:21:32 +0000] "GET /testfile HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:18:21:32 +0000] "GET /testfile HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:18:21:32 +0000] "GET /testfile HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:18:21:32 +0000] "GET /testfile HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:18:21:32 +0000] "GET /testfile HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:18:21:32 +0000] "GET /testfile HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:18:21:32 +0000] "GET /testfile HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:18:21:32 +0000] "GET /testfile HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:18:21:32 +0000] "GET /testfile HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:18:21:32 +0000] "GET /testfile HTTP/1.0" 200 104857600 "-" "ApacheBench/2.3" "-"
10 个并发连接,其中只有 1 个返回 200 状态,其余 9 个都是 404(503) 状态,这样的测试结果和设定的配置相符。
limit_req_zone 模块
使用 ngx_http_limit_req_module 模块可以 限制某一 IP 在一段时间内对服务器发起请求的连接数,该模块为内置模块。
指令
limit_req_zone 指令
语法:limit_req_zone key zone=name:size rate= number r/s;
默认值:无
区域:http
示例:limit_req_zone $binary_remote_addr zone=addr:10m rate=1r/s;
http {
limit_req_zone $binary_remote_addr zone=addr:10m rate=1r/s;
server {
....
}
}
- 第一个参数:$binary_remote_addr 表示通过remote_addr这个标识来做限制,“binary_”的目的是缩写内存占用量,是限制同一客户端ip地址。
- 第二个参数:zone=addr:10m表示生成一个大小为10M,名字为addr的内存区域,用来存储访问的频次信息。
- 第三个参数:rate=1r/s 表示允许相同标识的客户端的访问频次,这里限制的是每秒1次,即限制每 1秒 访问一次,即每 1秒 才处理一个请求,还可以有比如 30r/m 的。
参数详解:
语法:
limit_req_zone [key] zone = [name]:[size] rate=[rate]
# 这个变量只能在HTTP中使用,limit_req_zone用来限制请求的频率。
limit_req_zone
# 每个IP的请求频率每秒不能超过1次且最大容量为10M
limit_req_zone $binary_remote_addr zone=perip:10m rate=1r/s;
# 每个虚拟服务的请求频率每秒不能超过10次且最大容量为10M
limit_req_zone $server_name zone=perserver:10m rate=10r/s;
# 参数:
key 表示限制的关键词,可以是 IP 或 虚拟服务
zone的名称可以自定义,但不能重复,它代表一个存储 session 状态的容器,size 表示 容器的大小。以范例中的 perip 限制区域为例,大小为10M,按照 64-byte / session,约能存储 1.6W 个 session。
rate 表示请求的频率(规定时间内连接请求的数量),r/s:表示每秒请求频率限制, r/m:表示每分钟的请求频率限制。单位(request/second)
limit_req 指令
语法:limit_req zone=name [burst=number] [nodelay | delay=number];
默认:无
区域:http、server、location
示例:limit_req zone=zone burst=5 nodelay;
http {
limit_req_zone $binary_remote_addr zone=addr:10m rate=1r/s;
server {
location /search/ {
limit_req zone=addr burst=5 nodelay;
}
}
}
- 第一个参数:zone=addr:设置使用哪个配置名来做限制,与上面 limit_req_zone 里的 name 对应
- 第二个参数:burst=5 :这个配置的意思是设置一个大小为5的缓冲区,当有大量请求过来时,超过访问频次限制 (rate=1r/s) 的请求可以先放到这个缓冲区内等待,但是这个缓冲区只有5个位置,超过这个缓冲区的请求直接报503并返回。
- 第三个参数:nodelay:如果设置,会在瞬间提供处理(rate+burst)个请求的能力,请求超时(rate+burst)的时候直接返回503,永远不存在请求需要等待的情况。如果没有设置,则所有请求会依次等待排队;(如果请求不需要被延迟,添加nodelay参数,服务器会立刻返回503状态码。如果没有该字段会造成大量的tcp连接请求等待。)
参数详解:
limit_req zone=[name] burst=[count] nodelay
limit_req 这个变量可放 server 或 location 中,放在 server 中时表示对整个服务做限流,放在 location 中表示对特定请求做限流。
参数说明:
zone 选择的限流容器 name 限流容器名称
burst 缓存的数量 count 最大请求缓存数
nodelay 表示不延迟,即如果请求缓存超过 count 的值时马上返回 503 错误。
limit_req_status 指令
语法:limit_req_status code;
默认:limit_req_status 503;
区域:http、server、location
功能:设置要返回的状态码以响应被拒绝的请求。
limit_req_log_level 指令
(该指令出现在版本0.8.18中)
语法:limit_req_log_level info | notice | warn | error;
默认:limit_req_log_level error;
区域:http、server、location
功能:该指令用于设置日志的错误级别,当达到连接限制时,将会产生错误日志。
limit_req_zone 测试
本模块测试分为三种不同的方式进行测试验证:
- 1、不加 burst 和 不加 nodelay
- 2、加 burst 和 不加 nodelay
- 3、加burtst 和 加 nodelay
测试1 :不加 burst 和 不加 nodelay
配置如下:
limit_req_zone $binary_remote_addr zone=addr:10m rate=1r/s;
server {
listen 80;
server_name localhost;
location / {
limit_req zone=addr;
root /usr/share/nginx/www;
index index.html index.htm;
}
}
客户端主机:通过 ab 命令模拟并发访问:
[root@localhost ~]# ab -n 10 -c 10 http://localhost/index.html
...
Concurrency Level: 10
Time taken for tests: 0.002 seconds
Complete requests: 10
Failed requests: 9
(Connect: 0, Receive: 0, Length: 9, Exceptions: 0)
Write errors: 0
Non-2xx responses: 9 # 返回9个非200的请求
Total transferred: 121859 bytes
HTML transferred: 120271 bytes
Requests per second: 5246.59 [#/sec] (mean)
...
通过 ab 测试后的结果,10 个并发连接,只有 1 个成功,剩余 9 个都返回 非200 状态,查看 Nginx 日志:
[root@localhost www]# tailf /data/nginx/logs/access.log
172.17.0.1 - - [10/Oct/2020:22:03:20 +0000] "GET /index.html HTTP/1.0" 200 118894 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:03:20 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:03:20 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:03:20 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:03:20 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:03:20 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:03:20 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:03:20 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:03:20 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:03:20 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
1秒钟的10次并发请求,只有 1 个返回 200 ,剩余全是 404(503) 请求被拒绝。
不加 burst 和 不加 nodelay 的情况下,rate=1r/s 1 秒钟只能处理 1 个请求,剩余的所有请求都会直接返回 503
测试2 :加 burst 和 不加 nodelay
配置如下:
limit_req_zone $binary_remote_addr zone=addr:10m rate=1r/s;
server {
listen 80;
server_name localhost;
location / {
limit_req zone=addr burst=5;
root /usr/share/nginx/www;
index index.html index.htm;
}
}
客户端主机:通过 ab 命令模拟并发访问:
[root@localhost ~]# ab -n 10 -c 10 http://localhost/index.html
...
Concurrency Level: 10
Time taken for tests: 5.002 seconds
Complete requests: 10 # 处理10个请求
Failed requests: 4 # 失败4个请求
(Connect: 0, Receive: 0, Length: 4, Exceptions: 0)
Write errors: 0
Non-2xx responses: 4 # 返回4个非200的请求
Total transferred: 716004 bytes
HTML transferred: 713976 bytes
Requests per second: 2.00 [#/sec] (mean)
Time per request: 5002.447 [ms] (mean)
Time per request: 500.245 [ms] (mean, across all concurrent requests)
Transfer rate: 139.78 [Kbytes/sec] received
...
处理了10个连接请求,其中失败了 4 个,成功了 6个。
在本次测试中,使用 burst = 5 建立了一个可以存放 5 个并发连接的缓冲区。根据上面的 漏斗算法 来进行分析:
第一秒:10个连接并发请求,1个处理 5个等待,4个丢弃;
第二秒:1个处理 4 个等待;
第三秒:1个处理 3 个等待;
第四秒:1个处理 2 个等待;
第五秒:1个处理 1 个等待;
第六秒:1个处理 完毕。
通过上面的推算,一共需要 6 秒才能处理完所有的请求,查看 Nginx 日志,验证推算是不是正确:
[root@localhost www]# tailf /data/nginx/logs/access.log
172.17.0.1 - - [10/Oct/2020:22:31:45 +0000] "GET /index.html HTTP/1.0" 200 118894 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:31:45 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:31:45 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:31:45 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:31:45 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:31:46 +0000] "GET /index.html HTTP/1.0" 200 118894 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:31:47 +0000] "GET /index.html HTTP/1.0" 200 118894 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:31:48 +0000] "GET /index.html HTTP/1.0" 200 118894 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:31:49 +0000] "GET /index.html HTTP/1.0" 200 118894 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:31:50 +0000] "GET /index.html HTTP/1.0" 200 118894 "-" "ApacheBench/2.3" "-"
通过日志,可以看出,第一秒处理了 1 个请求,拒绝了 4 个连接,剩下的请求分别是每秒 1个连接请求的处理。
规则:rate=1r/s 、burst=5
一次来了 10 个连接并发请求,处理 1 个,缓存 5 个后续 1 秒一个的处理,其他的全部丢弃。
加 burst 和 不加 nodelay 的情况下,rate=1r/s burst=5 处理 1 个,缓存 5 个后续 1 秒一个的处理,其他的全部丢弃。
测试3 :加 burst 和 加 nodelay
配置如下:
limit_req_zone $binary_remote_addr zone=addr:10m rate=1r/s;
server {
listen 80;
server_name localhost;
location / {
limit_req zone=addr burst=5 nodelay;
root /usr/share/nginx/www;
index index.html index.htm;
}
}
客户端主机:通过 ab 命令模拟并发访问:
[root@localhost ~]# ab -n 10 -c 10 http://localhost/index.html
...
Concurrency Level: 10
Time taken for tests: 0.003 seconds
Complete requests: 10
Failed requests: 4
(Connect: 0, Receive: 0, Length: 4, Exceptions: 0)
Write errors: 0
Non-2xx responses: 4
Total transferred: 716004 bytes
HTML transferred: 713976 bytes
Requests per second: 3797.95 [#/sec] (mean)
Time per request: 2.633 [ms] (mean)
Time per request: 0.263 [ms] (mean, across all concurrent requests)
Transfer rate: 265561.21 [Kbytes/sec] received
...
10 个并发连接请求,很快就直接返回了,其中 4 个非200错误, 6 个成功。查看 Nginx 日志:
[root@localhost www]# tailf /data/nginx/logs/access.log
172.17.0.1 - - [10/Oct/2020:22:37:44 +0000] "GET /index.html HTTP/1.0" 200 118894 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:37:44 +0000] "GET /index.html HTTP/1.0" 200 118894 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:37:44 +0000] "GET /index.html HTTP/1.0" 200 118894 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:37:44 +0000] "GET /index.html HTTP/1.0" 200 118894 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:37:44 +0000] "GET /index.html HTTP/1.0" 200 118894 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:37:44 +0000] "GET /index.html HTTP/1.0" 200 118894 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:37:44 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:37:44 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:37:44 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
172.17.0.1 - - [10/Oct/2020:22:37:44 +0000] "GET /index.html HTTP/1.0" 404 153 "-" "ApacheBench/2.3" "-"
这次的测试结果,同一秒钟,处理了 rate+burst 个请求,其他的全部返回连接请求拒绝。
3.4 总结
通过测试的三种情况,返回了不同的结果,因此有必要详细说明:
- 1、不加 burst 和 不加 nodelay 的情况:按照 rate 设定的规则,严格执行。例如:rate=1r/s ,则1秒只处理1个请求,其他的全部返回连接503
- 2、加 burst 和 不加 nodelay 的情况:首先按照 rate 规则处理,并且缓存 burst 个连接,剩余的全部返回503,后续缓存的 burst 按照 rate 规则进行处理
- 3、加 burst 和 nodelay 的情况:第一次处理 rate+burst 个连接请求,剩余的请求全部返回 503
limit_rate 根据IP限流量
对于提供下载的网站,肯定是要进行流量控制的。Nginx 通过 core模块的 limit_rate 等指令可以做到限流的目的。
指令名称:limit_rate
语法:limit_rate speed;
默认值:无
区域:http、server、location
示例: limit_rate 512k;
功能:该指令用于指定向客户端传输数据的速度,速度的单位是每秒传输的字节数。注意:该限制只是针对一个连接的设定,也就是说,如果同时有2个连接,那么它的速度将会是该指令设置的两倍。
指令名称:limit_rate_after
语法:limit_rate_after size;
默认值:limit_rate_after 1m;
区域:http、server、location
示例:limit_rate_after 3m;
功能:以最大的速度下载 size大小后,在进行 limit_rate speed 限速,例如:limit_rate_after 3m 解释为:以最大的速度下载3m后,再进行限速。
测试:
测试前疑问:对于这个模块是通过什么来进行限速的呢? 上面的两个模块都有声明 $binary_remote_addr 远端ip地址进行操作的,而 limit_rate 什么都没规定。针对这个问题,做以下测试:
server {
listen 80;
server_name localhost;
# 限速 512k 的速度下载。
location /download1 {
limit_rate 512k;
}
# 正常速度下载 10m 数据后,限速 512k 的速度下载。
location /download2 {
limit_rate_after 10m;
limit_rate 512k;
}
}
正常速度下载 3m数据后,限速 512k 的速度下载。
1、生成一个较大的下载文件:
[root@localhost www]# dd if=/dev/zero of=/data/nginx/www/testfile bs=1M count=50
50+0 records in
50+0 records out
52428800 bytes (52 MB) copied, 0.0225122 s, 2.3 GB/s
2、这次通过,curl 来下载文件:
[root@localhost ~]# curl localhost/testfile -O testfile
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
39 50.0M 39 19.5M 0 0 1049k 0 0:00:48 0:00:19 0:00:29 511k
这里使用的是千兆网络,超过10m,速度被限制在512K 以下。这是一个连接下载,如果同时开启多个终端,都进行下载呢?
终端连接-1
[root@localhost ~]# curl localhost/testfile -O testfile
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 50.0M 100 50.0M 0 0 647k 0 0:01:19 0:01:19 --:--:-- 635k
终端连接-2
[root@localhost tmp]# curl localhost/testfile -O testfile
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
32 50.0M 32 16.0M 0 0 1363k 0 0:00:37 0:00:12 0:00:25 511k
因为 limit_rate 并没有声明以什么条件作为限制,所以同一个ip无论发起多少个请求,每个请求都会是 512k 下载。在迅雷等多种下载软件中,使用多线程的方式下载同一个文件,这个速度就翻倍了。 那这个限速就形同虚设。
因此,如果要进行限速,可以和 limit_conn_zone 模块配合进行使用。配置如下:
limit_conn_zone $binary_remote_addr zone=perip:10m;
server {
listen 80;
server_name localhost;
location / {
limit_conn perip 1; # 一次每个IP地址只允许一个连接。
limit_rate_after 10m; # 正常速度下载 10m 数据后开始限速
limit_rate 512k; # 限速 512k 的速度下载
root /usr/share/nginx/www;
index index.html index.htm;
}
}
同一时刻,只有一个连接请求。
再进行同主机多线程下载:
终端连接-1
[root@localhost ~]# curl http://localhost/testfile -O testfile
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
29 50.0M 29 14.5M 0 0 1647k 0 0:00:31 0:00:09 0:00:22 511k
终端连接-2
[root@localhost tmp]# curl http://localhost/testfile -O testfile
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 197 100 197 0 0 39741 0 --:--:-- --:--:-- --:--:-- 49250
curl: (6) Could not resolve host: testfile; Name or service not known
[root@localhost tmp]# curl -I http://localhost/testfile
HTTP/1.1 503 Service Temporarily Unavailable
Server: nginx/1.18.0
Date: Sat, 10 Oct 2020 23:22:14 GMT
Content-Type: text/html
Content-Length: 197
Connection: keep-alive
总结
当需要进行限速操作时,需要 limit_rate 和 limit_conn 模块联合起来使用才能达到限速的效果。
Nginx高可用-LVS+KeepAlived
Nginx单点问题剖析
全链路高可用之Nginx反向代理单点故障分析
- DNS 轮训多个ip,假如某个nginx挂了,怎么办?
--------》后端服务1...
|
用户--》 nginx|--------》后端服务2...
|
--------》后端服务3...
- Nginx集群架构(vip-虚拟ip)
|----》后端服务1...
Nginx----------|
⬆ |-----》后端服务2...
|
用户--》 LVS+Keepalived(VIP)
|
⬇ |-----》后端服务1...
Nginx----------|
|-----》后端服务2...
-
Nginx 高可用解决方案—基础
国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系。 从低到高分别是:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层 四层工作在OSI第四层,也就是传输层 七层工作在最高层,也就是应用层- F5、LVS(四层负载 TCP):用虚拟ip+port接收请求,再转发到对应的真实机器
- HAproxy、Nginx(七层负载):用虚拟的url或主机名接收请求,再转向相应的处理服务器
Linux虚拟服务器 LVS
- 官网:www.linuxvirtualserver.org
- 什么是LVS:
LVS是Linux Virtual Server,Linux虚拟服务器,是一个虚拟的服务器集群系统
项目是由章文嵩博士成立,是中国国内最早出现的自由软件项目之一
Linux2.4 内核以后,LVS 已经是 Linux 标准内核的一部分
软件负载解决的两个核心问题是:选谁、转发
- 图解:
|-----》后端服务1
---->Nginx1:realServer1——
| |-----》后端服务2
master LVS+Keppalived----|
⬆ | |-----》后端服务1
| ---->Nginx2:realServer2——
| |-----》后端服务2
客户端---VIP---》
| |-----》后端服务1
| ---->Nginx3:realServer3——
⬇ | |-----》后端服务2
backup LVS+Keppalived----|
| |-----》后端服务1
---->Nginx4:realServer4——
|-----》后端服务2
- 提供了10多种调度算法: 轮询、加权轮询、最小连接、目标地址散列、源地址散列等
- 三种负载均衡转发技术:
- NAT:数据进出都通过 LVS, 前端的Master既要处理客户端发起的请求,又要处理后台RealServer的响应信息,将RealServer响应的信息再转发给客户端, 容易成为整个集群系统性能的瓶颈; (支持任意系统且可以实现端口映射)
- DR:移花接木,最高效的负载均衡规则,前端的Master只处理客户端的请求,将请求转发给RealServer,由后台的RealServer直接响应客户端,不再经过Master, 性能要优于LVS-NAT; 需要LVS和RS集群绑定同一个VIP(支持多数系统,不可以实现端口映射)
- TUNL:隧道技术,前端的Master只处理客户端的请求,将请求转发给RealServer,然后由后台的RealServer直接响应客户端,不再经过Master;(支持少数系统,不可以实现端口映射))
keepalived 介绍与安装
keepalived 是什么:
- 核心:监控并管理 LVS 集群系统中各个服务节点的状态
keepalived是一个类似于交换机制的软件,核心作用是检测服务器的状态,如果有一台web服务器工作出现故障,Keepalived将检测到并将有故障的服务器从系统中剔除,使用其他服务器代替该服务器的工作,当服务器工作正常后Keepalived自动将服务器加入到服务器群中,这些工作全部自动完成。
后来加入了vrrp(虚拟路由器冗余协议),除了为lvs提供高可用还可以为其他服务器比如Mysql、Haproxy等软件提供高可用方案
- 安装、启动和查看命令
yum install -y keepalived # 安装keepalived
cd /etc/keepalived # 安装之后路径
cat /etc/keepalived/keepalived.conf # 配置文件路径
=====================================================
systemctl start keepalived.service # 启动
systemctl stop keepalived.service # 停止
systemctl status keepalived.service # 查看状态
systemctl restart keepalived.service # 重启
systemctl stop firewalld.service # 停止防火墙
=====================================================
service keepalived start # 启动
service keepalived stop # 停止
service keepalived status # 查看状态
service keepalived restart # 重启
systemctl stop firewalld.service # 停止防火墙
- 注意: 如果有缺少依赖可以执行下面的命令
yum install -y gcc
yum install -y openssl-devel
yum install -y libnl libnl-devel
yum install -y libnfnetlink-devel
yum install -y net-tools
yum install -y vim wget
====================================
yum install -y gcc openssl-devel libnl libnl-devel libnfnetlink-devel
Keepalived 核心配置讲解
- 配置文件地址:
/etc/keepalived/keepalived.conf - 完整版本
# 全局配置
global_defs {
# 邮件通知信息
notification_email {
# 定义收件人
acassen@firewall.loc
}
# 定义发件人
notification_email_from Alexandre.Cassen@firewall.loc
# SMTP服务器地址
smtp_server 192.168.200.1
smtp_connect_timeout 30
# 路由器标识,一般不用改,也可以写成每个主机自己的主机名
router_id LVS_DEVEL
# VRRP的ipv4和ipv6的广播地址,配置了VIP的网卡向这个地址广播来宣告自己的配置信息,下面是默认值
vrrp_mcast_group4 224.0.0.18
vrrp_mcast_group6 ff02::12
}
# 定义用于实例执行的脚本内容,比如可以在线降低优先级,用于强制切换
vrrp_script SCRIPT_NAME {
}
# 一个vrrp_instance就是定义一个虚拟路由器的,实例名称
vrrp_instance VI_1 {
# 定义初始状态,可以是MASTER或者BACKUP
state MASTER
# 工作接口,通告选举使用哪个接口进行
interface ens33
# 虚拟路由ID,如果是一组虚拟路由就定义一个ID,如果是多组就要定义多个,而且这个虚拟
# ID还是虚拟MAC最后一段地址的信息,取值范围0-255
virtual_router_id 51
# 使用哪个虚拟MAC地址
use_vmac XX:XX:XX:XX:XX
# 监控本机上的哪个网卡,网卡一旦故障则需要把VIP转移出去
track_interface {
eth0
ens33
}
# 如果你上面定义了MASTER,这里的优先级就需要定义的比其他的高
priority 100
# 通告频率,单位为秒
advert_int 1
# 通信认证机制,这里是明文认证还有一种是加密认证
authentication {
auth_type PASS
auth_pass 1111
}
# 设置虚拟VIP地址,一般就设置一个,在LVS中这个就是为LVS主机设置VIP的,这样你就不用自己手动设置了
virtual_ipaddress {
# IP/掩码 dev 配置在哪个网卡
192.168.200.16/24 dev eth1
# IP/掩码 dev 配置在哪个网卡的哪个别名上
192.168.200.17/24 dev label eth1:1
}
# 虚拟路由,在需要的情况下可以设置lvs主机 数据包在哪个网卡进来从哪个网卡出去
virtual_routes {
192.168.110.0/24 dev eth2
}
# 工作模式,nopreempt表示工作在非抢占模式,默认是抢占模式 preempt
nopreempt|preempt
# 如果是抢占默认则可以设置等多久再抢占,默认5分钟
preempt delay 300
# 追踪脚本,通常用于去执行上面的vrrp_script定义的脚本内容
track_script {
}
# 三个指令,如果主机状态变成Master|Backup|Fault之后会去执行的通知脚本,脚本要自己写
notify_master ""
notify_backup ""
notify_fault ""
}
# 定义LVS集群服务,可以是IP+PORT;也可以是fwmark 数字,也就是防火墙规则
# 所以通过这里就可以看出来keepalive天生就是为ipvs而设计的
virtual_server 10.10.10.2 1358 {
delay_loop 6
# 算法
lb_algo rr|wrr|lc|wlc|lblc|sh|dh
# LVS的模式
lb_kind NAT|DR|TUN
# 子网掩码,这个掩码是VIP的掩码
nat_mask 255.255.255.0
# 持久连接超时时间
persistence_timeout 50
# 定义协议
protocol TCP
# 如果后端应用服务器都不可用,就会定向到那个服务器上
sorry_server 192.168.200.200 1358
# 后端应用服务器 IP PORT
real_server 192.168.200.2 1358 {
# 权重
weight 1
# MSIC_CHECK|SMTP_CHEKC|TCP_CHECK|SSL_GET|HTTP_GET这些都是
# 针对应用服务器做健康检查的方法
MISC_CHECK {}
# 用于检查SMTP服务器的
SMTP_CHEKC {}
# 如果应用服务器不是WEB服务器,就用TCP_CHECK检查
TCP_CHECK {
# 向哪一个端口检查,如果不指定默认使用上面定义的端口
connect_port <PORT>
# 向哪一个IP检测,如果不指定默认使用上面定义的IP地址
bindto <IP>
# 连接超时时间
connect_timeout 3
}
# 如果对方是HTTPS服务器就用SSL_GET方法去检查,里面配置的内容和HTTP_GET一样
SSL_GET {}
# 应用服务器UP或者DOWN,就执行那个脚本
notify_up "这里写的是路径,如果脚本后有参数,整体路径+参数引起来"
notify_down "/PATH/SCRIPTS.sh 参数"
# 使用HTTP_GET方法去检查
HTTP_GET {
# 检测URL
url {
# 具体检测哪一个URL
path /testurl/test.jsp
# 检测内容的哈希值
digest 640205b7b0fc66c1ea91c463fac6334d
# 除了检测哈希值还可以检测状态码,比如HTTP的200 表示正常,两种方法二选一即可
status_code 200
}
url {
path /testurl2/test.jsp
digest 640205b7b0fc66c1ea91c463fac6334d
}
url {
path /testurl3/test.jsp
digest 640205b7b0fc66c1ea91c463fac6334d
}
# 向哪一个端口检查,如果不指定默认使用上面定义的端口
connect_port <PORT>
# 向哪一个IP检测,如果不指定默认使用上面定义的IP地址
bindto <IP>
# 连接超时时间
connect_timeout 3
# 尝试次数
nb_get_retry 3
# 每次尝试之间间隔几秒
delay_before_retry 3
}
}
real_server 192.168.200.3 1358 {
weight 1
HTTP_GET {
url {
path /testurl/test.jsp
digest 640205b7b0fc66c1ea91c463fac6334c
}
url {
path /testurl2/test.jsp
digest 640205b7b0fc66c1ea91c463fac6334c
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
- 简约版
! Configuration File for keepalived
global_defs {
# 设置lvs的id,在一个网络内应该是唯一的
router_id LVS_DEVEL
# 允许执行外部脚本
enable_script_security
# 指定运行脚本的用户名和组
# 默认使用用户的默认组。如未指定,默认为 keepalived_script 用户,如无此用户,则使用root
# script_user keepalived_script
}
# 配置vrrp_script,主要用于健康检查及检查失败后执行的动作。
vrrp_script chk_real_server {
# 健康检查脚本,当脚本返回值不为0时认为失败
script "/usr/local/shell/chk_server.sh"
# 检查频率,以下配置每2秒检查1次
interval 2
# 当检查失败后,将vrrp_instance中priority减5
weight -5
# 连续监测失败3次,才认为真的健康检查失败。并调整优先级
fall 3
# 连续监测2次成功,就认为成功。但不调整优先级
rise 2
# 执行脚本的用户或组
user root
}
# 配置对外提供服务的VIP vrrp_instance配置
vrrp_instance VI_1 {
# 指定vrrp_instance的状态,是MASTER还是BACKUP主要还是看优先级
state MASTER
# 指定vrrp_instance绑定的网卡,最终通过指定的网卡绑定VIP
interface eth0
# 相当于VRID,用于在一个网内区分组播,需要组播域内内唯一
virtual_router_id 51
# 本机的优先级,VRID相同的机器中,优先级最高的会被选举为MASTER
priority 100
# 心跳间隔检查,默认为1s,MASTER会每隔1秒发送一个报文告知组内其他机器自己还活着。
advert_int 1
# 设置主备节点间的通信验证类型及密码,同一个VRRP实例中需一致
authentication {
auth_type PASS
auth_pass 1111
}
# 定义虚拟IP(VIP)可多设,每行一个,之后访问的就是该IP
virtual_ipaddress {
172.17.0.20
}
# 本vrrp_instance所引用的脚本配置,名称就是vrrp_script 定义的容器名
track_script {
chk_real_server
}
}
# 定义对外提供服务的LVS的VIP以及port
virtual_server 172.17.0.20 80 {
# 设置健康检查时间,单位秒
delay_loop 6
# 设置负载调度的算法为rr
lb_algo rr
# 设置LVS实现负载的机制,有NAT、TUN、DR三个模式
lb_kind NAT
# 会话保持时间,单位秒
persistence_timeout 50
# 指定转发协议类型(TCP、UDP)
protocol TCP
# 指定realserver1的IP地址,该IP为后端服务的ip
real_server 172.17.0.14 80 {
# 配置节点权值,数字越大权重越高
weight 1
# 健康检查方式
TCP_CHECK {
# 连接超时,单位秒
connect_timeout 10
# 重试次数
retry 3
# 重试间隔
delay_before_retry 3
# 检查时连接的端口
connect_port 80
}
}
# 指定realserver2的IP地址,该IP为后端服务的ip
real_server 172.17.0.14 81 {
# 配置节点权值,数字越大权重越高
weight 1
# 健康检查方式
TCP_CHECK {
# 连接超时,单位秒
connect_timeout 10
# 重试次数
retry 3
# 重试间隔
delay_before_retry 3
# 检查时连接的端口
connect_port 80
}
}
}
- 配置注意:(一定要注意router_id、state、interface的值,我就在这里踩坑了)
- router_id:后面跟的自定义的ID在同一个网络下是一致的
- state:后跟的MASTER和BACKUP必须是大写;否则会造成配置无法生效的问题
- interface:网卡ID;要根据自己的实际情况来看,可以使用以下方式查询
ip a或ip addr查询 - authentication主备之间的认证方式,一般使用PASS即可;主备的配置必须一致,不能超过8位
- 在 BACKUP 节点上,其 keepalived.conf 与 Master 上基本一致,修改 state 为 BACKUP ,priority 值改小即可
- 如果其中keepalived挂了,那就会vip就会分发到另外一个keepalived节点,响应正常
- 如果某个realServer挂了,比如是Nginx挂了,那对应keepalived节点存活依旧可以转发过去,但是响应失败
- 为了解决问题2,所以需要配置监听脚本
- 脚本监听 模块
# 配置 vrrp_script,主要用于健康检查及检查失败后执行的动作。
vrrp_script chk_real_server {
script "/usr/local/shell/chk_server.sh" # 健康检查脚本,当脚本返回值不为0时认为失败
interval 2 # 检查频率,以下配置每2秒检查1次
weight -5 # 当检查失败后,将vrrp_instance中priority减5
fall 3 # 连续监测失败3次,才认为真的健康检查失败。并调整优先级
rise 2 # 连续监测2次成功,就认为成功。但不调整优先级
user root # 执行脚本的用户或组
}
chk_server.sh脚本内容(需要 chmod +x chk_server.sh)
#!/bin/bash
# 检查nginx进程是否存在
counter=$(ps -C nginx --no-heading|wc -l)
if [ "${counter}" -eq "0" ]; then
service keepalived stop
echo 'nginx server is died.......'
fi
常见问题:
- vip 能 ping通,vip监听的端口不通:第一个原因:nginx1和nginx2两台服务器的服务没有正常启动
- vip ping不通,核对是否出现裂脑,常见原因为防火墙配置所致导致多播心跳失败,核对keepalived的配置是否正确
特别注意: selinux的影响:keepalived配置了vrrp_script脚本总是无效,需要关闭selinux,不然sh脚本可能不生效,
- 查看状态:getenforce
- 临时关闭:setenforce 0
- 永久关闭:修改/etc/sysconfig/selinux文件把里面的一行修改为SELINUX=disabled,保存重启就可以了。
生产环境问题
- VIP : 阿里云(LBS)、华为云、腾讯云、AWS
Keepalived+Nginx 主从模式
|---->Nginx1 192.168.1.33
Keppalived(主)192.168.1.31 --->|
⬆ |---->Nginx2 192.168.1.34
|
客户端--VIP-192.168.3.110-》
|
⬇ |---->Nginx1 192.168.1.33
Keppalived(备)192.168.1.32 --->|
|---->Nginx2 192.168.1.34
1)实验环境准备(此处都是使用的centos7系统)
$ cat /etc/redhat-release
CentOS Linux release 7.4.1708 (Core)
在所有节点上面进行配置
$ systemctl stop firewalld //关闭防火墙
// 如下两种选择其一就可以了
$ setenforce 0 //关闭selinux,临时生效
$ sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/sysconfig/selinux //关闭selinux,重启生效
$ ntpdate 0.centos.pool.ntp.org //时间同步
$ yum install nginx -y //安装nginx
2)配置后端web服务器(两台一样)
// 准备测试文件,此处是将主机名和ip写到index.html页面中
$ echo "`hostname` `ifconfig ens33 |sed -n 's#.*inet \(.*\)netmask.*#\1#p'`" > /usr/share/nginx/html/index.html
# 配置文件时默认的,无修改
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}
$ systemctl start nginx // 启动nginx
$ systemctl enable nginx // 加入开机启动
3)开始搭建keepalived,在两台 lb 节点上面安装keepalived
[root@LB-01 ~]# yum install keepalived -y // 安装keepalived
[root@LB-01 ~]# systemctl start keepalived // 启动keepalived
[root@LB-01 ~]# systemctl enable keepalived // 加入开机自启动
配置 LB-01节点
[root@LB-01 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
8629303@qq.com
}
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.110/24 dev ens33 label ens33:1
}
}
重启后生效配置文件
[root@LB-01 ~]# systemctl restart keepalived
[root@LB-01 ~]# ip a //查看IP,会发现多出了VIP 192.168.1.110
......
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:94:17:44 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.31/24 brd 192.168.1.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.1.110/24 scope global secondary ens33:1
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe94:1744/64 scope link
valid_lft forever preferred_lft forever
......
配置 LB-02节点
[root@LB-02 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
8629303@qq.com
}
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.110/24 dev ens33 label ens33:1
}
}
[root@LB-02 ~]# systemctl start keepalived //启动keepalived
[root@LB-02 ~]# systemctl enable keepalived //加入开机自启动
[root@LB-02 ~]# ifconfig // 查看IP,此时备节点不会有VIP(只有当主挂了的时候,VIP才会飘到备节点)
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.32 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::20c:29ff:feab:6532 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:ab:65:32 txqueuelen 1000 (Ethernet)
RX packets 43752 bytes 17739987 (16.9 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 4177 bytes 415805 (406.0 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
......
Keepalived+Nginx 双从模式
将keepalived做成双主模式,其实很简单,就是再配置一段新的vrrp_instance(实例)规则,主上面加配置一个从的实例规则,从上面加配置一个主的实例规则。
说明:还是按照上面的环境继续做实验,只是修改LB节点上面的keepalived服务的配置文件即可。此时LB-01节点即为Keepalived的主节点也为备节点,LB-02节点同样即为Keepalived的主节点也为备节点。LB-01节点默认的主节点VIP(192.168.1.110),LB-02节点默认的主节点VIP(192.168.1.210)
|---->Nginx1 192.168.1.33
Keppalived(主)192.168.1.31 --->|
⬆ ⬆ |---->Nginx2 192.168.1.34
| |
客户端--192.168.3.110 192.168.3.210
| |
⬇ ⬇ |---->Nginx1 192.168.1.33
Keppalived(备)192.168.1.32 --->|
|---->Nginx2 192.168.1.34
1)配置 LB-01 节点
[root@LB-01 ~]# vim /etc/keepalived/keepalived.conf // 编辑配置文件,增加一段新的vrrp_instance规则
! Configuration File for keepalived
global_defs {
notification_email {
8629303@qq.com
}
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.110/24 dev ens33 label ens33:1
}
}
vrrp_instance VI_2 {
state BACKUP
interface ens33
virtual_router_id 52
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 2222
}
virtual_ipaddress {
192.168.1.210/24 dev ens33 label ens33:2
}
}
[root@LB-01 ~]# systemctl restart keepalived //重新启动keepalived
[root@LB-01 ~]# ip addr // 查看LB-01 节点的IP地址,发现VIP(192.168.1.110)同样还是默认在该节点
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:94:17:44 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.31/24 brd 192.168.1.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.1.110/24 scope global secondary ens33:1
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe94:1744/64 scope link
valid_lft forever preferred_lft forever
2)配置 LB-02 节点
[root@LB-02 ~]# vim /etc/keepalived/keepalived.conf //编辑配置文件,增加一段新的vrrp_instance规则
! Configuration File for keepalived
global_defs {
notification_email {
8629303@qq.com
}
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.110/24 dev ens33 label ens33:1
}
}
vrrp_instance VI_2 {
state MASTER
interface ens33
virtual_router_id 52
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 2222
}
virtual_ipaddress {
192.168.1.210/24 dev ens33 label ens33:2
}
}
[root@LB-02 ~]# systemctl restart keepalived //重新启动keepalived
[root@LB-02 ~]# ip addr // 查看LB-02节点IP,会发现也多了一个VIP(192.168.1.210),此时该节点也就是一个主了。
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:ab:65:32 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.32/24 brd 192.168.1.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.1.210/24 scope global secondary ens33:2
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:feab:6532/64 scope link
valid_lft forever preferred_lft forever
3)测试
[root@node01 ~]# curl 192.168.1.110
web01 192.168.1.33
[root@node01 ~]# curl 192.168.1.110
web02 192.168.1.34
[root@node01 ~]# curl 192.168.1.210
web01 192.168.1.33
[root@node01 ~]# curl 192.168.1.210
web02 192.168.1.34
// 停止LB-01节点的keepalived再次测试
[root@LB-01 ~]# systemctl stop keepalived
[root@node01 ~]# curl 192.168.1.110
web01 192.168.1.33
[root@node01 ~]# curl 192.168.1.110
web02 192.168.1.34
[root@node01 ~]# curl 192.168.1.210
web01 192.168.1.33
[root@node01 ~]# curl 192.168.1.210
web02 192.168.1.34
测试可以发现我们访问keepalived中配置的两个VIP都可以正常调度等,当我们停止任意一台keepalived节点,同样还是正常访问;到此,keepalived+nginx高可用集群(双主模式)就搭建完成了。
Nginx—OpenResty
OpenResty+Lua 介绍
- 什么是OpenResty, 为什么要用OpenResty?
由章亦春发起,是基于Ngnix和Lua的高性能web平台,内部集成精良的LUa库、第三方模块、依赖, 开发者可以方便搭建能够处理高并发、扩展性极高的动态web应用、web服务、动态网关。
OpenResty将Nginx核心、LuaJIT、许多有用的Lua库和Nginx第三方模块打包在一起
Nginx是C语言开发,如果要二次扩展是很麻烦的,而基于OpenResty,开发人员可以使用 Lua 编程语言对 Nginx 核心模块进行二次开发拓展
性能强大,OpenResty可以快速构造出1万以上并发连接响应的超高性能Web应用系统
- 官网:http://openresty.org
- 阿里、腾讯、新浪、酷狗音乐等都是 OpenResty 的深度用户
拓展
让Web 服务直接跑在 Nginx 服务内部,充分利用 Nginx 的非阻塞 I/O 模型,不仅仅对 HTTP 客户端请求,甚至于对远程后端诸如 MySQL, Memcaches 以及 Redis 等都进行一致的高性能响应。所以对于一些高性能的服务来说,可以直接使用 OpenResty 访问 Mysql或Redis等,而不需要通过第三方语言(PHP、Python、Ruby)等来访问数据库再返回,这大大提高了应用的性能
Lua脚本介绍
Lua 由标准 C 编写而成,没有提供强大的库,但可以很容易的被 C/C++ 代码调用,也可以反过来调用 C/C++ 的函数。
在应用程序中可以被广泛应用,不过Lua是一种脚本/动态语言,不适合业务逻辑比较重的场景,适合小巧的应用场景,代码行数保持在几十行到几千行。
LuaJIT 是采用 C 和汇编语言编写的 Lua 解释器与即时编译器
- 什么是ngx_lua
ngx_lua是Nginx的一个模块,将Lua嵌入到Nginx中,从而可以使用Lua来编写脚本,部署到Nginx中运行,
即Nginx变成了一个Web容器;开发人员就可以使用Lua语言开发高性能Web应用了。
-
OpenResty提供了常用的ngx_lua开发模块
- lua-resty-memcached
- lua-resty-mysql
- lua-resty-redis
- lua-resty-dns
- lua-resty-limit-traffic
通过上述的模块,可以用来操作 mysql数据库、redis、memcached等,也可以自定义模块满足其他业务需求, 很多经典的应用,比如开发缓存前置、数据过滤、API请求聚合、AB测试、灰度发布、降级、监控、限流、防火墙、黑白名单等
OpenResty+Lua 安装
OpenResty 安装 下载:http://openresty.org/en/linux-packages.html#centos
- yum安装(不推荐)
# add the yum repo:
# yum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo
wget -P /opt/ https://openresty.org/package/centos/openresty.repo
sudo mv /opt/openresty.repo /etc/yum.repos.d/
# update the yum index:
sudo yum check-update
# 安装openresty
sudo yum install openresty
# 安装命令行工具
sudo yum install openresty-resty
# 列出所有 openresty 仓库里的软件包
sudo yum --disablerepo="*" --enablerepo="openresty" list available
# 查看版本
resty -V
- 源码安装(推荐)
# 下载源码安装包
wget -P /opt/ https://openresty.org/download/openresty-1.17.8.2.tar.gz
# 解压
tar -zxvf openresty-1.17.8.2.tar.gz
# 选择需要的插件启用, --with-Components 激活组件,–without 则是禁止组件
./configure --without-http_redis2_module --with-http_iconv_module
# 编译加安装
make && make install
# 加入path路径
vi /etc/profile
# 加入的内容
export PATH=$PATH:/usr/local/openresty/nginx/sbin/
# 使配置生效
source /etc/profile
Nginx+OpenResty 案例
- Nginx+OpenRestry 开发
vim /usr/local/openresty/nginx/conf/nginx.conf
http{
# 虚拟机主机块
server{
# 监听端口
listen 80;
# 配置请求的路由
location /{
default_type text/html;
content_by_lua_block{
ngx.say("hello world; xdclass.net 小滴课堂");
}
}
}
}
# 使用其他方式
http{
# 虚拟机主机块,还需要配置lua文件扫描路径
lua_package_path "$prefix/lualib/?.lua;;";
lua_package_cpath "$prefix/lualib/?.so;;";
server{
# 监听端口
listen 80;
# 配置请求的路由
location /{
default_type text/html;
content_by_lua_file lua/xdclass.lua;
}
}
}
- 启动Nginx(直接用openresty里面的nginx即可,默认安装了多个模块)
访问 curl 127.0.0.1
如果浏览器访问会出现文件下载,因为没有Html头信息
注意:如果需要指定配置文件 nginx -c 配置文件路径
比如
./nginx -c /usr/local/nginx/conf/nginx.conf
Nginx内置变量+OpenResty请求阶段
Nginx内置变量
- 提供丰富的内置变量, openresty里面使用参考下面的文档:https://github.com/openresty/lua-nginx-module#ngxvarvariable
- 部分变量是可以被修改的,部分是不给修改
| 名称 | 说明 |
|---|---|
| $arg_name | 请求中的name参数 |
| $args | 请求中的参数 |
| $content_length | HTTP请求信息里的"Content-Length" |
| $content_type | 请求信息里的"Content-Type" |
| $host | 请求信息中的"Host",如果请求中没有Host行,则等于设置的服务器名 |
| $hostname | 机器名使用 gethostname系统调用的值 |
| $http_cookie | cookie 信息 |
| $http_referer | 引用地址 |
| $http_user_agent | 客户端代理信息 |
| $http_via | 最后一个访问服务器的Ip地址。 |
| $http_x_forwarded_for | 相当于网络访问路径 |
| $is_args | 如果请求行带有参数,返回“?”,否则返回空字符串 |
| $limit_rate | 对连接速率的限制 |
| $nginx_version | 当前运行的nginx版本号 |
| $pid | worker进程的PID |
| $query_string | 与$args相同 |
| $remote_addr | 客户端IP地址 |
| $remote_port | 客户端端口号 |
| $request | 用户请求 |
| $request_method | 请求的方法,比如"GET"、"POST"等 |
| $request_uri | 请求的URI,带参数 |
| $scheme | 所用的协议,比如http或者是https |
| $server_name | 请求到达的服务器名 |
| $server_port | 请求到达的服务器端口号 |
| $server_protocol | 请求的协议版本,"HTTP/1.0"或"HTTP/1.1" |
| $uri | 请求的URI,可能和最初的值有不同,比如经过重定向之类的 |
Nginx 处理请求的过程一共划分为 11 个阶段,按照执行顺序依次是 :
post-read、server-rewrite、find-config、rewrite、post-rewrite、preaccess、access、post-access、try-files、content 以及 log。
nginx对于请求的处理分多个阶段,Nginx , 从而让第三方模块通过挂载行为在不同的阶段来控制, 大致如下:

- 初始化阶段(Initialization Phase)
- init_by_lua_file
- init_worker_by_lua_file
- 重写与访问阶段(Rewrite / Access Phase)
- rewrite_by_lua_file
- access_by_lua_file
- 内容生成阶段(Content Phase)
- content_by_lua_file
- 日志记录阶段(Log Phase)
内网访问限制
Nginx+OpenResty +Lua内网访问限制
- 生产环境-管理后台一般需要指定的网络才可以访问,网段/ip等
- Nginx+OpenRestry+Lua开发
http{
# 这里设置为 off,是为了避免每次修改之后都要重新 reload 的麻烦。
# 在生产环境上需要 lua_code_cache 设置成 on。
lua_code_cache off;
# lua_package_path可以配置openresty的文件寻址路径,$PREFIX 为openresty安装路径
# 文件名使用“?”作为通配符,多个路径使用“;”分隔,默认的查找路径用“;;”
# 设置纯 Lua 扩展库的搜寻路径
lua_package_path "$prefix/lualib/?.lua;;";
# 设置 C 编写的 Lua 扩展模块的搜寻路径(也可以用 ';;')
lua_package_cpath "$prefix/lualib/?.so;;";
server {
location / {
access_by_lua_file lua/white_ip_list.lua;
proxy_pass http://lbs;
}
}
}
lua/white_ip_list.lua
local black_ips = {["127.0.0.1"]=true}
local ip = ngx.var.remote_addr
if true == black_ips[ip] then
ngx.exit(ngx.HTTP_FORBIDDEN)
return;
end
- 拓展
- 如何做一个动态黑名单控制?
- 里面 /usr/local/openresty/lualib/resty 很多第三方模块
资源下载限速
Nginx+OpenResty实现资源下载限速
- 限速限流应用场景
- 下载限速:保护带宽及服务器的IO资源
- 请求限流:防止恶意攻击,保护服务器及资源安全
- 限制某个用户在一个给定时间段内能够产生的HTTP请求数
- 限流用在保护上游应用服务器不被在同一时刻的大量用户访问
- openResty下载限速案例实操
- Nginx 有一个
$limit_rate,这个反映的是当前请求每秒能响应的字节数, 该字节数默认为配置文件中limit_rate指令的设值
- Nginx 有一个
# 当前请求的响应上限是 每秒 300K 字节
location /download {
access_by_lua_block {
ngx.var.limit_rate = "300K"
}
alias /usr/local/software/app;
autoindex on; # 开启目录文件列表
}
下载限速实现原理
下载限速实现原理
- 目的:限制下载速度
- 常用的是漏桶原理和令牌桶原理
什么是漏桶算法
- 备注:如果是请求限流,请求先进入到漏桶里,漏桶以固定的速度出水,也就是处理请求,当水加的过快也就是请求过多,桶就会直接溢出,也就是请求被丢弃拒绝了,所以漏桶算法能强行限制数据的传输速率或请求数
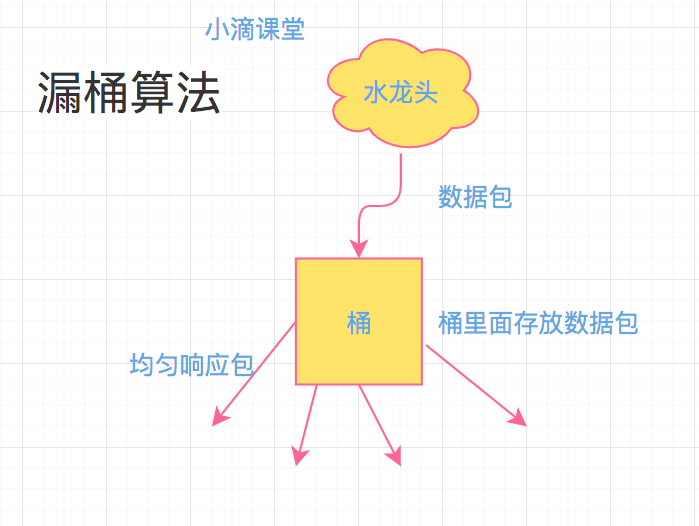
什么是令牌桶算法
-
备注:只要突发并发量不高于桶里面存储的令牌数据,就可以充分利用好机器网络资源。
如果桶内令牌数量小于被消耗的量,则产生的令牌的速度就是均匀处理请求的速度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号