
今日内容:爬虫
网络爬虫是通过网页的链接地址来寻找网页的,从网页的主页开始,读取网页的内容,找到在主页中的其他链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网上的蜘蛛就可以通过这个原理把互联网上所有的页面都抓取下来。
爬虫原理:
1.什么是互联网
指的是由一堆网络设备,把一台台计算机互联网到一起称之为互联网
2。建立互联网的目的
为了数据的传递以及数据的共享
3.上网的全过程
普通用户:打开浏览器-->发送请求-->获取响应-->渲染到浏览器
爬虫程序:模拟浏览器-->发送请求-->获取响应-->提取有价值的数据-->持久到数据中
4.浏览器发送的请求
http协议的请求。
客户端:浏览器是一个软件-->客户端的IP和端口
服务端:http://www.jd.com/
www.jd.com(京东域名)-->DNS解析-->京东服务端的IP和端口
客户端的IP和端口------>服务端的IP和端口 发送请求可以建立链接获取相应的数据
5.爬虫的全过程
(1)发送请求 (需要请求库:request请求库,selenium请求库)
(2)获取响应数据
(3)解析并提取数据 (需要解析库: re,beautifulsoup4,Xpath。。。)
(4)保存到本地 (文件处理,数据库)
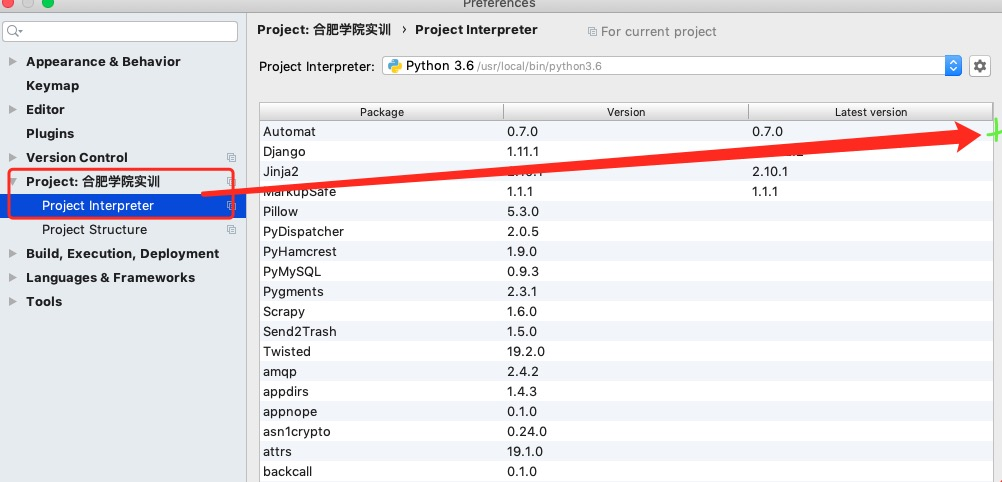
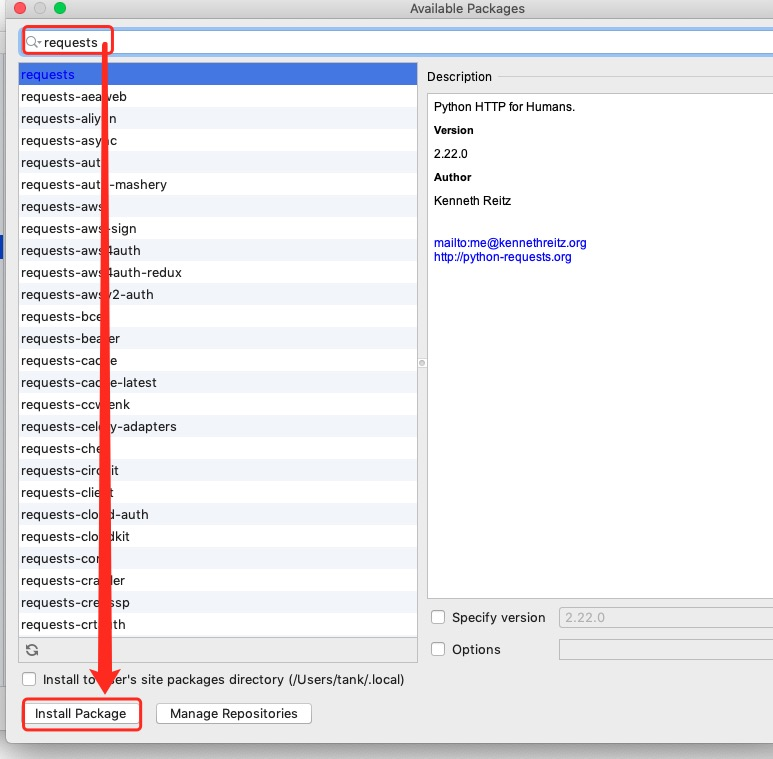
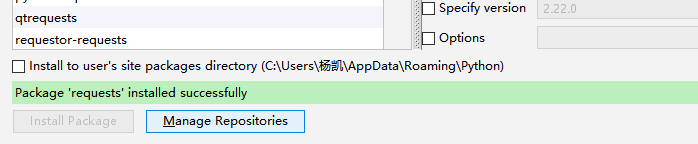
request请求库安装:
打开cmd,输入:pip3 install requests

import requests import re response = requests.get('https://www.pearvideo.com/') print(response.text) res_list = re.findall('<a href="video_(.*?)"',response.text,re.S) print(res_list) for v_id in res_list: detail_url = '[图片]https://www.pearvideo.com/video_' + v_id print(detail_url)
import requests import re # 爬虫三部曲 # 1、发送请求 def get_page(base_url): response = requests.get(base_url) return response # 2、解析文本 def parse_index(text): res = re.findall('<div class="item">.*?<em class="">(.*?)</em>.*?<a href="(.*?)">.*?<span class="title">(.*?)</span>.*?导演:(.*?)</p>.*?<span class="rating_num" .*?>(.*?)</span>.*?<span>(.*?)人评价</span>.*?<span class="inq">(.*?)</span>',text,re.S) # print(res) return res # 3、保存数据 def save_data(data): with open('douban.txt', 'a', encoding='utf-8') as f: f.write(data) # main +回车键 if __name__== '__main__': # num = 10 # base_url = f'[图片]https://movie.douban.com/top250?start={}&filter='.format(num) num = 0 for line in range(10): base_url = f'[图片]https://movie.douban.com/top250?start={num}&filter=' num += 25 print(base_url) # 1、发送请求,调用函数 response = get_page(base_url) # 2、解析文本 movie_list = parse_index(response.text) # 3、保存数据 # 数据的格式化 for movie in movie_list: print(movie) # 解压赋值 # 电影排名、电影url、电影名称、导演-主演-类型、电影评分、评价人数、电影简介 v_top, v_url, v_name, v_director, v_point, v_num, v_desc = movie # v_top = movie(0) # v_url = movie(1) movie_content = f''' 电影排名:{v_top} 电影url:{v_url} 电影名称:{v_name} 导演主演:{v_director} 电影评分:{v_point} 评价人数:{v_num} 电影简介:{v_desc} \n ''' print(movie_content) # 保存数据 save_data(movie_content)





