
hadoop的三大组件安装
安装过程分3步走: 1.安装namenode主机一台; 2.安装datanode主机三台; 3.启用集群的三大组件: HDFS,Mapreduce,Yarn.
重要的事情: 新建的虚拟机,预备安装hadoop的disk必须扩容到至少20G,否则后面集群起不来.如果遗漏,请重启主机和服务,扩容才会生效.
一, 安装namenode主机一台,命名主机名称为nn1
1. 配置主机名为nn01,ip为192.168.1.60,配置yum源
[root@nn1 ~]# vim /etc/yum.repos.d/local.repo
[local_repo]
name=CentOS
baseurl="ftp://192.168.1.254/centos-1804"
enabled=1
gpgcheck=1
2. 安装java环境
[root@nn1 ~]# yum -y install java-1.8.0-openjdk-devel
[root@nn1 ~]# java -version
openjdk version "1.8.0_161"
OpenJDK Runtime Environment (build 1.8.0_161-b14)
OpenJDK 64-Bit Server VM (build 25.161-b14, mixed mode)
[root@nn1 ~]# jps (java process show)
754 Jps
3. 安装hadoop
[root@room 04]#rsync -aHS hadoop root@192.168.1.60:/root/ #真机上传安装文件
[root@nn1 ~]# cd /hadoop
[root@nn1 hadoop]# ls
hadoop-2.7.7.tar.gz kafka_2.12-2.1.0.tgz zookeeper-3.4.13.tar.gz
[root@nn1 hadoop]# tar -xf hadoop-2.7.7.tar.gz
[root@nn1 hadoop]# mv hadoop-2.7.7 /usr/local/hadoop
[root@nn1 hadoop]# ls /usr/local/hadoop
LICENSE.txt NOTICE.txt README.txt bin etc include lib libexec sbin share
[root@nn1 hadoop]# cd /usr/local/hadoop
[root@nn1 hadoop]# ./bin/hadoop
Error: JAVA_HOME is not set and could not be found. #报错java程序没有找到
4. 解决java报错问题
[root@nn1 hadoop]# rpm -ql java-1.8.0-openjdk
[root@nn1 hadoop]# cd ./etc/hadoop
[root@nn1 hadoop]# vim hadoop-env.sh
export JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre/" #更改java程序调用路径
export HADOOP_CONF_DIR="/usr/local/hadoop/etc/hadoop" #hadoop调用路径
[root@nn1 hadoop]# cd /usr/local/hadoop
[root@nn1 hadoop]# ./bin/hadoop
5. 测试-词频
[root@nn1 hadoop]#mkdir /usr/local/hadoop/input
[root@nn1 hadoop]#cp *.txt /usr/local/hadoop/input
[root@nn1 hadoop]#./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount input output #wordcount统计input文件夹的词频,输出到文件夹output
[root@nn1 hadoop]#cat output/part-r-00000 #查看
二, 环境准备
1. 三台机器配置主机名为dn1,dn2,dn3,配置ip地址,yum源
2. 编辑/etc/hosts(四台主机同样操作,以nn1为例,修改后,任意主机之间可以ping通)
[root@nn1 hadoop]# vim /etc/hosts
# ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
192.168.1.60 nn1
192.168.1.61 dn1
192.168.1.62 dn2
192.168.1.63 dn3
3. 布置SSH信任关系
[root@nn1 ~]# ssh-keygen -f /root/.ssh/id_rsa -N ''
[root@nn1 ~]# for i in {60..63}
> do
> ssh-copy-id 192.168.1.$i
> done
4. 在dn1,dn2,dn3上面安装java环境
[root@dn1 ~]# yum -y install java-1.8.0-openjdk-devel
[root@dn2 ~]# yum -y install java-1.8.0-openjdk-devel
[root@dn3 ~]# yum -y install java-1.8.0-openjdk-devel
三, 部署hadoop
1. 修改slaves文件
[root@nn1 ~]# vim /usr/local/hadoop/etc/hadoop/slaves
dn1
dn2
dn3
2. hadoop的核心配置文件core-site
[root@nn1 ~]# cd /usr/local/hadoop/etc/hadoop/
[root@nn1 hadoop]# vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name> #name标记里面的参数来自https://hadoop.apache.org/docs/r3.2.0/,不可更改.
<value>hdfs://nn1:9000</value> #nn1为namenode主机名
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop</value> #hadoop数据根目录
</property>
</configuration>
[root@nn1 hadoop]# mkdir /var/hadoop #创建hadoop的数据根目录
3. 配置hdfs-site文件
[root@nn1 hadoop]# vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>nn1:50070</value> #namenode及端口
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>nn1:50090</value> #secondary namenode的端口50090
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
4. 同步namenode的/usr/local/hadoop/ 配置到dn1,dn2,dn3.
[root@nn1 hadoop]# for i in {61..63}
> do
> rsync -aSH --delete /usr/local/hadoop 192.168.1.$i:/usr/local/hadoop/ -e 'ssh' &
> done
[1] 23733
[2] 23734
[3] 23735
5. 格式化
[root@nn1 hadoop]# cd /usr/local/hadoop/
[root@nn1 hadoop]# ./bin/hdfs namenode -format
6. 启动集群,并查看状态
[root@nn1 hadoop]# ./sbin/start-dfs.sh
Starting namenodes on [nn1]
nn1: namenode running as process 23891. Stop it first.
dn1: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-dn1.out
dn3: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-dn3.out
dn2: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-dn2.out
Starting secondary namenodes [nn1]
nn1: secondarynamenode running as process 24074. Stop it first.
[root@nn1 hadoop]# jps
23891 NameNode
24074 SecondaryNameNode
24543 Jps
[root@nn1 hadoop]# ./bin/hdfs dfsadmin -report
Live datanodes (3): #出现3个节点,就意味着dfs集群启用成功
四, 配置mapred-site
[root@nn1 hadoop]# cd /usr/local/hadoop/etc/hadoop/
[root@nn1 hadoop]# mv mapred-site.xml.template mapred-site.xml
[root@nn1 hadoop]# vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
五, 配置yarn-site
[root@nn1 hadoop]# vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>nn1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
六, 同步mapred-site和yarn-site的配置内容到dn1,dn2,dn3
[root@nn1 hadoop]# for i in {61..63}
> do
> rsync -aSH --delete /usr/local/hadoop/ 192.168.1.$i:/usr/local/hadoop/ -e 'ssh' &
> done
[1] 1202
[2] 1203
[3] 1204
七, 验证配置
[root@nn1 hadoop]# cd /usr/local/hadoop
[root@nn1 hadoop]# ./sbin/start-dfs.sh
[root@nn1 hadoop]# ./sbin/start-yarn.sh
[root@nn1 hadoop]# jps #nn1查看有ResourceManager
994 SecondaryNameNode
805 NameNode
1532 ResourceManager
1791 Jps
[root@dn1 ~]# jps #dn1查看有NodeManager
932 Jps
830 NodeManager
687 DataNode
[root@dn2 ~]# jps #dn2查看有NodeManager
833 NodeManager
690 DataNode
935 Jps
[root@dn3 ~]# jps #dn3查看有NodeManager
931 Jps
828 NodeManager
686 DataNode
[root@nn1 hadoop]# ./bin/yarn node -list #验证服务
19/07/20 11:52:14 INFO client.RMProxy: Connecting to ResourceManager at nn1/192.168.1.60:8032
Total Nodes:3
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
dn2:43088 RUNNING dn2:8042 0
dn3:32790 RUNNING dn3:8042 0
dn1:33836 RUNNING dn1:8042 0
八, 从浏览器访问hadoop
namenode nn1的web页面: http://192.168.1.60:50070/
secondory namenode nn1的web页面: http://192.168.1.60:50090/
datanode dn1的web页面: http://192.168.1.61:50075/
datanode dn2的web页面: http://192.168.1.62:50075/
datanode dn3的web页面: http://192.168.1.62:50075/
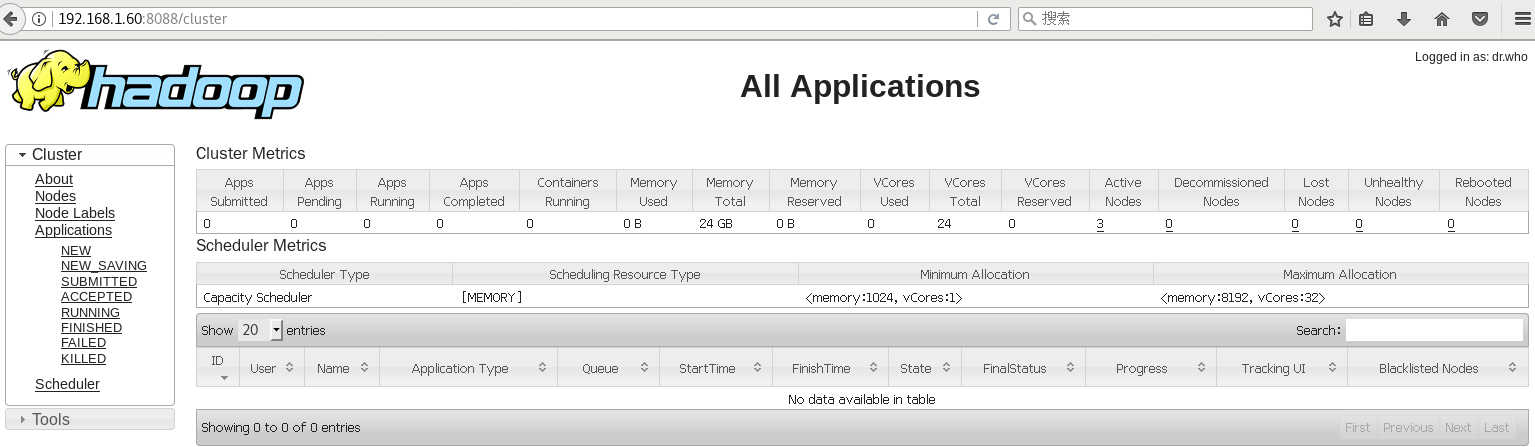
resourcemanager nn1的web页面: http://192.168.1.60:8088/
nodemanager dn1的web页面: http://192.168.1.61:8042/
nodemanager dn2的web页面: http://192.168.1.62:8042/
nodemanager dn3的web页面: http://192.168.1.63:8042/
结束.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号