
1.大数据概述
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。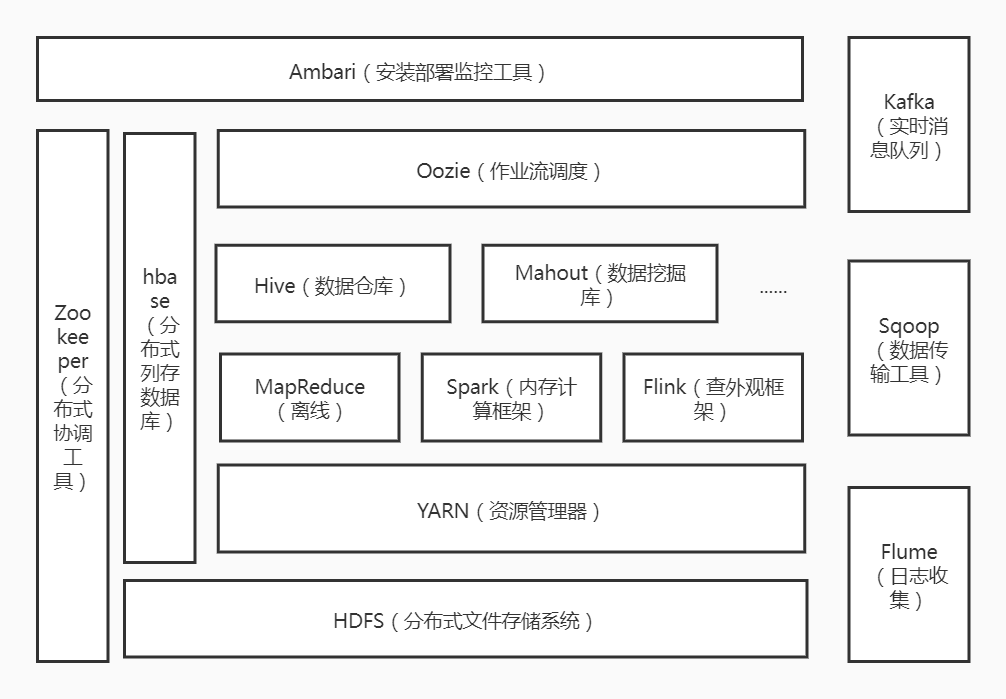
生态系统是一个由许多组件组成的生态链,只有持续开发,Hadoop生态系统才能不断成熟,现在有多个子项目,核心HDFS和MapReduce,以及Hadoop生态系统、zoopker、hbae、hive、pig、mahout、sqoop等等,包括flame和ambari等功能组件。这些组件涵盖了当前行业中已处理的所有场景。
2.对比Hadoop与Spark的优缺点。
答:hadoop:两步计算,磁盘存储
spark:多步计算,内存存储
Spark是MapReduce的替代品,HDFS和Hive兼容性可以整合到Hadoop生态系统来弥补MapReduce的缺点。
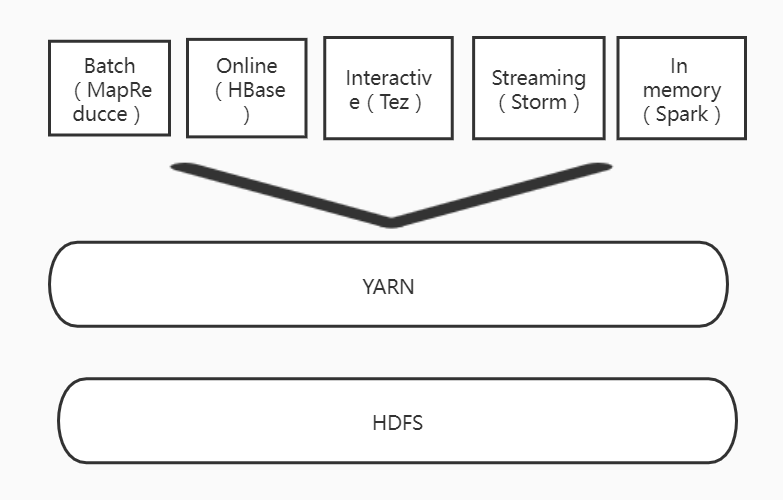
3.如何实现Hadoop与Spark的统一部署?
Hadoop、MapReduce、HBase、Storm和Spark都可以通过资源管理框架线进行运行。因此,它们可以均匀地在线上展开。
他们在YARN上带来的好处:
按需计算资源;
无负荷应用程序映射,高集群利用;
为了避免整个集群的数据转移,共享基础存储。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号