Redis哨兵内存碎片化故障处理
背景介绍
近期研发同学反馈业务响应波动厉害,怀疑是Redis操作key比较慢的缘故。由于该环境是我一手安装部署的,我将进行问题排查。
Redis环境以及业务环境都已经使用Prometheus进行了监控。
环境说明
我们有两套一样的环境来服务不同的客户,另外一套环境中业务一直平稳运行,Redis并没有任何问题。
由于部分信息涉及公司敏感数据,我将用A环境和B环境来代替问题环境和正常环境。
AB两个环境中都是部署的Redis哨兵模式,但研发同学由于业务需要,在插入Redis master后需要立即读取,所以他们并没有在代码中使用读写分离,担心主从延迟导致读取不到数据。
解决思路
1、对研发同学的判断持怀疑态度,首先确认是不是以为Redis操作key比较慢导致的业务波动
2、对比AB两环境机器本身的性能是不是差异很大
3、查看监控,对比AB两环境中Redis处理数据的差异
4、对比Redis的配置
5、对比Redis的info,查看是否有异常的地方
问题排查
理顺调用链路
由于研发同学是在监控面板看到Redis的业务波动,那我们也从监控面板来入手。调用线路如下:
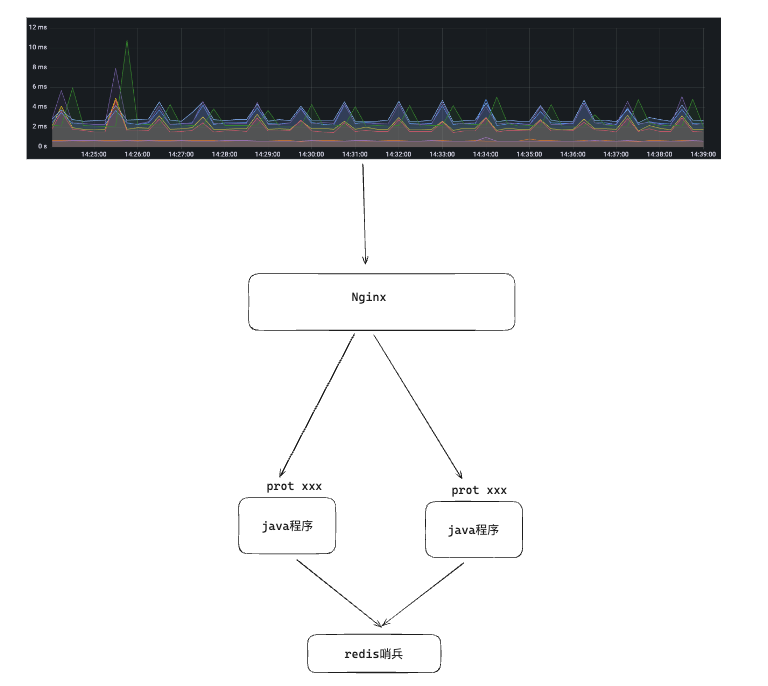
我根据AB两个环境进行了以下几个方面的对比:
机器本身的性能对比
A环境:21核心 负载 2.16 内存free 11G
B环境:8核心 负载:0.71 内存free 324M
A环境的机器资源远高于B环境的资源。Redis操作key慢不是因为机器性能原因或资源不够导致的
每秒网络流量对比
A环境Redis监控:流入2.76MiB/s 流出5.95MiB/s
B环境Redis监控:1.33MiB/s 流出2.67MiB/s
A环境的流入流量以及流出是要比B环境的流入流出高一些,需要再看下两个Redis的key数量的对比
命令执行平均耗时
A环境Redis监控:1.28ms
B环境Redis监控:140us
A环境的Redis操作key的速度确实要慢一些。
每秒命令花费的总时长
A环境Redis监控:20ms
B环境Redis监控:5ms
正如研发同学所说,A环境的Redis确实比较慢,接下来就是要查出Redis慢的具体原因了
保存策略
A环境
127.0.0.1:6379> config get save
1) "save"
2) "3600 1 300 100 60 10000"
B环境
127.0.0.1:6379> config get save
1) "save"
2) "3600 1 300 100 60 10000"
保存策略是一样的
配置文件
配置文件就不放出来给大家看了,涉及敏感信息太多。将对比之后的差异拿出来供大家参考
配置文件对比结果有差异的部分如下所示:
protected-mode yes
stream-node-max-bytes 4096
解释
protected-mode yes
是否开启保护模式,默认开启。要是配置里没有指定bind和密码。开启该参数后,redis只会
本地进行访问,拒绝外部访问。要是开启了密码 和bind,可以开启。否 则最好关闭,设置为no。
stream-node-max-bytes 4096
Stream是Redis 5.0版本新增的数据类型。stream-node-max-bytes:单位为Byte,默认值为4096,即每个宏节点占用的内存容量上限为4096 Bytes。取值范围:0~999,999,999,999,999。0表示无限制。
两个参数的差异和Redis操作比较慢并没有太大关系
进程对比
A环境Redis进程
# cat /proc/33126/status
......
VmRSS: 10069084 kB # 换算约等于10G
......
B环境Redis进程
# cat /proc/242235/status
......
VmRSS: 216592 kB # 换算约等于0.2G
......
解释:
VmRSS:程序现在使用的物理内存.
VmPeak:代表当前进程运行过程中占用内存的峰值.
VmSize:代表进程现在正在占用的内存
VmLck:VmLck代表进程已经锁住的物理内存的大小.锁住的物理内存不能交换到硬盘.
VmData:表示进程数据段的大小.
VmStk:表示进程堆栈段的大小.
VmExe:表示进程代码的大小.
VmLib:表示进程所使用LIB库的大小.
VmPTE:占用的页表的大小.
发现A环境中的Redis使用的物理内存远高于正常环境B中Redis,那会不会是因为A环境中数量量较大的缘故?继续调查
A环境Redis进程
# ps axo pid,comm,pcpu|grep 33126
33126 redis-server 4.5
B环境Redis进程
# ps axo pid,comm,pcpu|grep 242235
242235 redis-server 10.8
Redis info对比
A环境Redis详情:
127.0.0.1:6379> info
# Server
redis_version:6.2.12
# Memory
used_memory_rss_human:9.60G Redis进程占用的物理内存总量
used_memory_peak_human:9.35G 以可读格式返回内存使用的最大值
mem_fragmentation_ratio:227.45 碎片率过大,导致内存资源浪费;,如果值越大,说明碎片越严重。
mem_allocator:libc # 内存分配器。默认是jemalloc
# Stats
total_connections_received:1085788
total_commands_processed:23625699956 服务器处理的命令总数
instantaneous_ops_per_sec:16904 每秒处理的命令数
# Keyspace
db0:keys=91039,expires=76193,avg_ttl=197651010
db10:keys=1124,expires=0,avg_ttl=0
B环境Redis详情
127.0.0.1:6379> info
# Server
redis_version:6.2.7
# Memory
used_memory_rss_human:210.41M
used_memory_peak_human:10.21G
mem_fragmentation_ratio:1.69
mem_allocator:jemalloc-5.1.0
# Stats
total_connections_received:1214805
total_commands_processed:84962263325
instantaneous_ops_per_sec:5752
# Keyspace
db0:keys=249802,expires=22780,avg_ttl=259788874
db10:keys=68340,expires=1,avg_ttl=29650800
db11:keys=3,expires=0,avg_ttl=0
通过查看info,我们可以看到A环境的key数量比B环境是要少的,既然少还执行这么慢,应该是其他地方出现了问题。
A机器的mem_fragmentation_ratio远大于正常值,并且mem_allocator是libc(默认是jemalloc,并且默认的jemalloc对于内存碎片管理是支持手动回收的。 )
A环境的Redis中key的数量还没有B环境多,却用了将近10G的内存,有很大问题。
mem_fragmentation_ratio的值代表含义如下:
- mem_fragmentation_ratio < 1 表示Redis内存分配超出了物理内存,操作系统正在进行内存交换,内存交换会引起非常明显的响应延迟;
- mem_fragmentation_ratio > 1 是合理的;
- mem_fragmentation_ratio > 1.5 说明Redis消耗了实际需要物理内存的150%以上,其中50%是内存碎片率,可能是操作系统或Redis实例中内存管理变差的表现
确定问题
经过以上排查,大概是因为Redis内存碎片化的缘故导致A环境的Redis操作较慢。
什么是Redis内存碎片化?
Redis分配内存时,会根据需要申请一段连续的内存空间。但当Redis删除或修改数据时,释放的内存空间并不一定能被立即重新利用,尤其是当这些空闲内存空间大小不一致时,就可能导致内存碎片的出现。
为了提高内存使用的效率,Redis内部使用内存分配器来对内存的申请和释放进行管理。Redis使用的内存分配器默认是「jemalloc」。
我翻看当时安装A环境的Redis时使用整理的安装文档,如下:
# 消除警告
sysctl vm.overcommit_memory=1
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo "511" > /proc/sys/net/core/somaxconn
sysctl net.core.somaxconn=4096
# 开始安装
apt install make gcc
wget https://download.redis.io/releases/redis-6.2.12.tar.gz
mv redis-6.2.12.tar.gz /etc/
cd /etc/
tar xf redis-6.2.12.tar.gz
mv redis-6.2.12 redis
rm -rf redis-6.2.12.tar.gz
cd redis/
make && make install
echo $?
mkdir /etc/redis/conf
cp redis.conf ./conf
rm -f /etc/redis/redis.conf
#sed -i 's#daemonize no#daemonize yes#g' /etc/redis/conf/redis.conf
groupadd redis
useradd redis -g redis -M -s /sbin/nologin
chown -R redis:redis /etc/redis
vim /etc/redis/conf/redis.conf
requirepass 2023@666.168
slaveof 10.0.0.10 6379
masterauth 2023@666.168
cat >/usr/lib/systemd/system/redis.service<<EOF
[Unit]
Description=Redis persistent key-value database
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
LimitNOFILE=65536
ExecStart=/usr/local/bin/redis-server /etc/redis/conf/redis.conf --supervised systemd
ExecStop=/usr/local/bin/redis-cli -a 2023@666.168 shutdown
User=root
Group=root
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl start redis
ps -ef |grep redis
默认安装的Redis就是使用jemalloc才对,不应该是libc,很奇怪这一点,为何会装成了libc呢?
解决方案
经过和研发同学沟通今晚将重新安装A环境的Redis哨兵,使redis使用jemalloc,可以定期回收内存。
重新编译安装后业务没有再波动,内存使用量
注释:
测试sentinel auth-pass mymaster xxxx参数设置与不设置时 故障是否会自动转移 ?
答案: 需要设置并且在哨兵中的主从都需要设置masterauth xxx

