redis(一)redis简介
nosql简介
nosql的出现
一、单机架构
一个网站访问量一般都不大,用单个数据库完全可以应付。静态页面比较多,动态交互类型的网站不多。

单机架构的瓶颈:
1、数据量的总大小 一个机器放不下时
2、数据的索引足够多 一个机器的内存放不下时
3、单台MySQL数据库 读写都负责 IO压力比较大
二、memcached缓存+MySQL
访问量比较大时,使用MySQL架构开始出现性能问题,web程序不能只注重功能,也要提高访问的速度。开始出现缓存机制,缓解MySQL的压力同时优化MySQL的结构和索引。开始比较流行的是通过文件缓存来缓解MySQL的压力,但是当访问量继续增大时,多台web机器通过文件缓存不能共享,大量的小文件缓存也带来了比较高的IO压力。
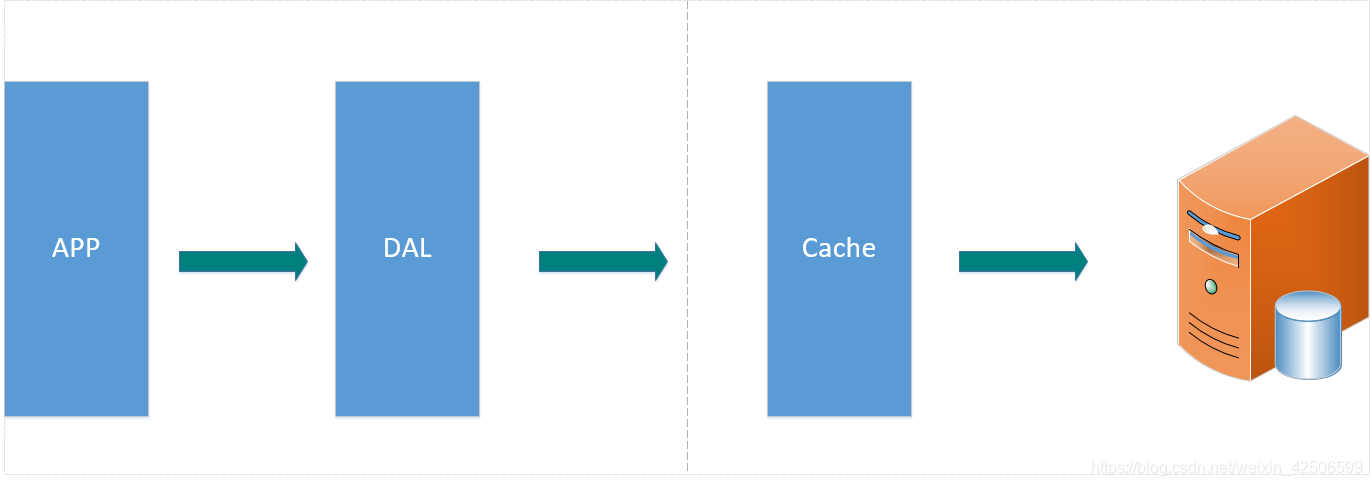
Memcached的出现缓解了这一性能问题。
Memcached作为一个独立的分布式缓存服务器,为多个web服务器提供了一个共享的高性能缓存服务。
并且Memcached可以搭建为多台组成集群。
缓存架构的瓶颈:
1、缓存机制只能对热数据进行缓存,是提高读的性能,但是当用户量再增长时,写入的数据量大,MySQL写入性能成为了新的瓶颈。
三、MySQL主从读写分离
由于MySQL的写入压力比较大,Memcached只能缓存MySQL的读取压力。读写集中在一个MySQL上让数据不堪重负,大部分网站开始使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展性。MySQL的master-slave模式成为这个网站的标配。
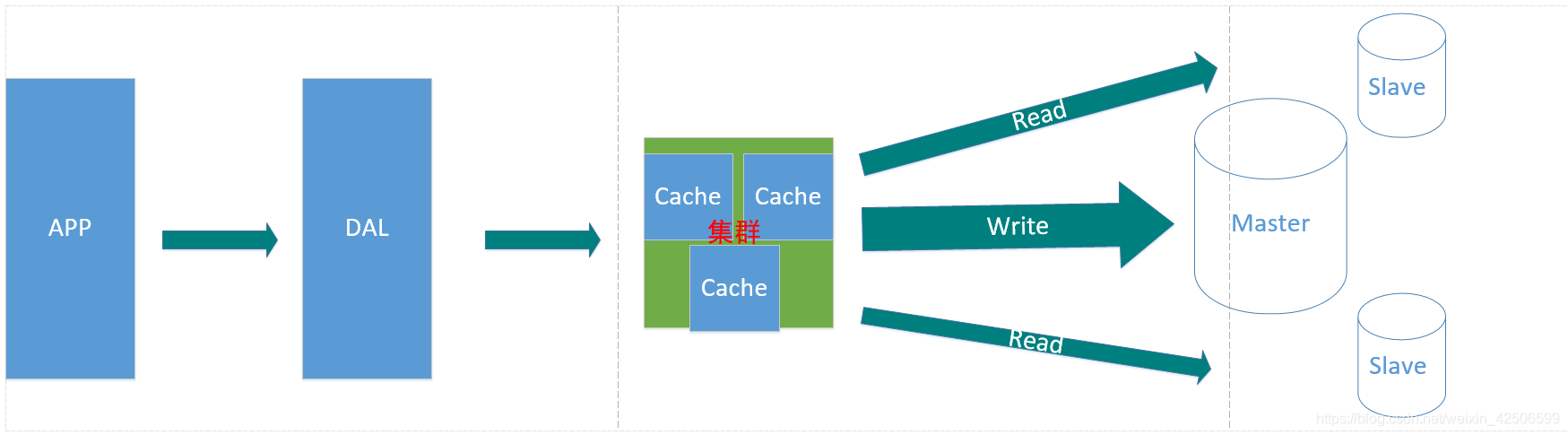
Memcache缓存+MySQL主从复制架构的瓶颈:
1、此架构基本上已经满足大部分中小企业,但是对于大型项目而言,考虑到以后的大数据量,虽然已经将读写已经分离,但是此时的主库(也就是写入库)的压力也是此架构的一个瓶颈问题。
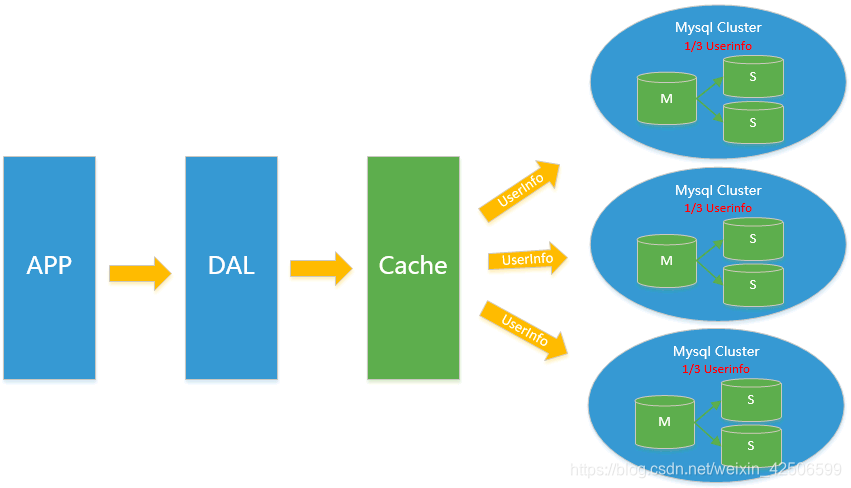
四、Memcache集群+MySQL集群分库分表
在Memcached的高速缓存,MySQL的主从复制,读写分离的基础之上,这时MySQL主库的写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM使用表锁,在高并发下会出现严重的锁问题,大量的高并发MySQL应用开始使用InnoDB引擎代替MyISAM。
同时,开始流行使用分表分库来缓解写压力和数据增长的扩展问题。这个时候,分表分库成了一个热门技术,是面试的热门问题也是业界讨论的热门技术问题。也就在这个时候,MySQL推出了还不太稳定的表分区,这也给技术实力一般的公司带来了希望。虽然MySQL推出了MySQL Cluster集群,但性能也不能很好满足互联网的要求,只是在高可靠性上提供了非常大的保证。
五、MySQL不适用的场景
虽然以上四种架构可以缓解MySQL的压力 但是有些场景MySQL不适用。
比如:
用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL数据库的发展也却能很好的处理这些大的数据。
nosql简介
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”
泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题,包括超大规模数据的存储。
非关系型数据库没有这么多的表结构,不必将不同作用的数据分开存放。
这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
传统的RDBMS vs NoSql
RDBMS
高度组织化结构化数据
结构化查询语言
数据和关系都存储在单独的表中
数据操作语言,数据定义语言
严格的一致性
基础事务
NoSql
代表的不仅仅是Sql
没有声明性查询语言
没有预定义的模式
键值对存储,列存储,文档存储,图形数据库
最终一致性,而非ACID属性
非结构化和不可预知的数据
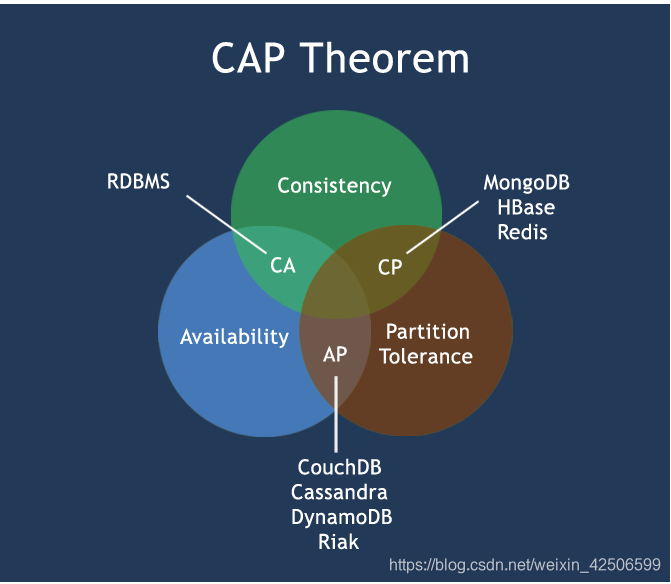
CAP定理
高性能,高可用和可伸缩性
nosql的优势
1、易扩展
nosql数据库种类繁多,但是他们有一个共同的特点:就是去除关系型数据库的“关系型”特点。数据之间无关系,这样就变的非常容易扩展,而相对应来看:关系型数据库修改表结构非常困难。
这就为项目架构设计体提供了很大的扩展空间。
2、大数据量高性能
nosql数据库都具有非常高的读写能力,尤其是在大数据量的情况下,表现同样优秀。这得益于nosql数据库中的数据没有关系,数据库结构简单。
从缓存角度来看,MySQL的缓存是粗粒度缓存,假设存储了100条数据,其中有一条数据修改了,整个缓存就失效了。nosql的数据库缓存时记录级的细粒度缓存,任何一条记录的修改都不会影响其他记录,效率非常高。
3、多样灵活的数据模型
nosql数据库无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系性数据库中,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增减修改字段简直就是一个噩梦。
CAP原则
传统的ACID
A: 原子性
C: 一致性
I: 独立性
D: 持久性
CAP
C :强一致性(在分布式系统中的所有数据备份,在同一时刻是否同样的值。)
A :可用性(保证每个请求不管成功或者失败都有响应。)
P :分区容错性(系统中任意信息的丢失或失败不会影响系统的继续运作。)
CAP理论就是说在分布式存储系统中,最多只能实现上面的两点。而由于当前的网络硬件肯定会出现延迟丢包等问题,所以
分区容错性是必须要实现的。
所以我们要在一致性和可用性之间进行权衡,没有nosql系统可以同时保证这三点。
CA 传统Oracle数据库
AP 大多数网站架构的选择
CP redis Mongodb
注意: 分布式架构的时候必须要做出取舍。
一致性和可用性之间取一个平衡。大多数的网站应用,其实不需要强一致性。所以大多数网站使用AP (可用性、分区容错性)
CAP原则总结
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,
最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
CP - 满足一致性,分区容忍必的系统,通常性能不是特别高。
AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
redis简介
redis是完全开源免费的,用C语言编写,遵守BSD协议,是一个高性能的key-value分布式内存数据库,基于内存运行,并支持持久化的nosql数据库,是当前最热门的nosql数据库之一,也被称为数据结构服务器。
redis的特点
1、redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。并且在保存在磁盘时是使用异步存储的过程不影响服务的正常运行。
2、redis不仅仅支持简单的key-value类型的数据,同时还提供list、set、zset、hash等数据结构的存储。
3、redis支持数据的备份,主从、集群等方式。
redis的运行机制
5.0
redis5.x 以及之前的版本中 都是单work线程处理所有步骤
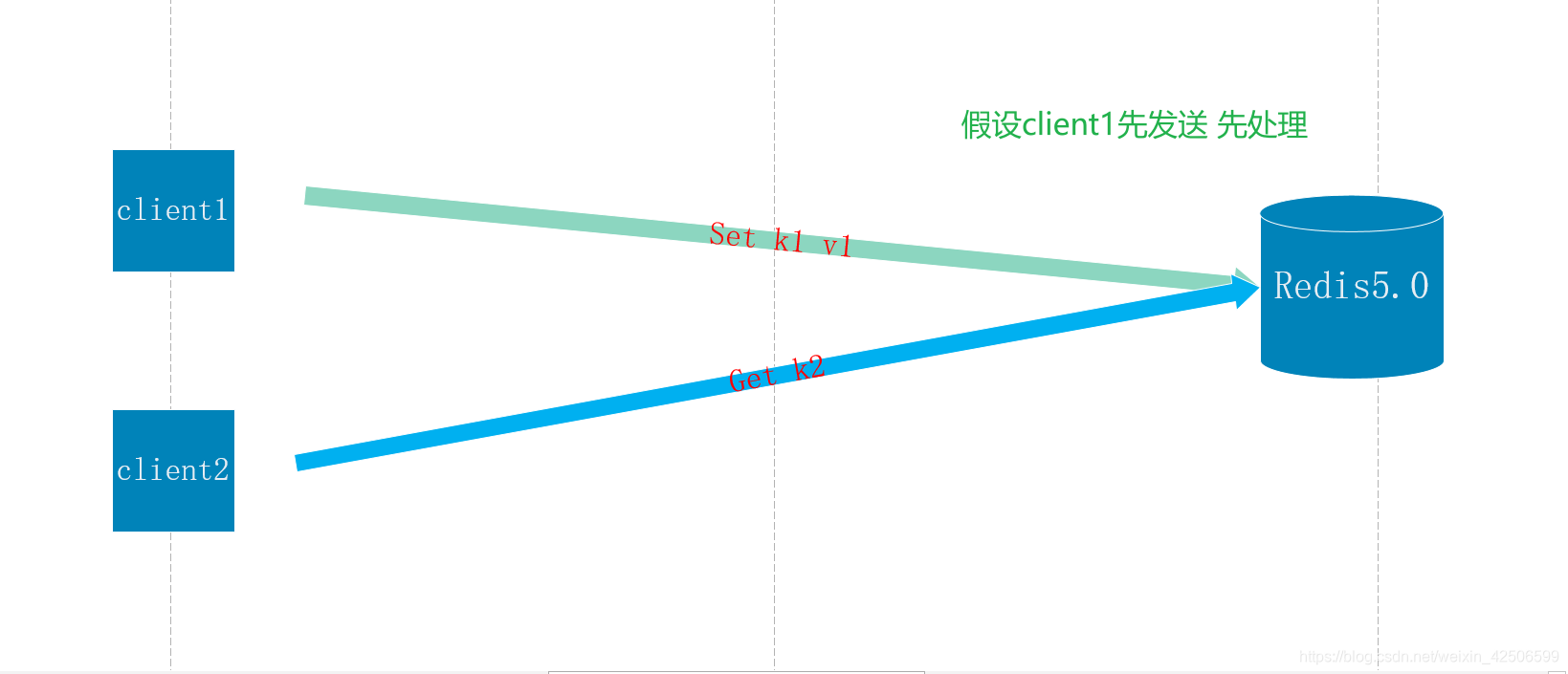
处理步骤:
1、work单线程先进行接受并读取IO流 简称 read io
2、work单线程对读取到的IO进行计算,插入到内存中
3、将插入结果返回给客户端 简称 write io
6.0
redis6.0后都是单work进程处理计算部分,子进程处理read io 和write io
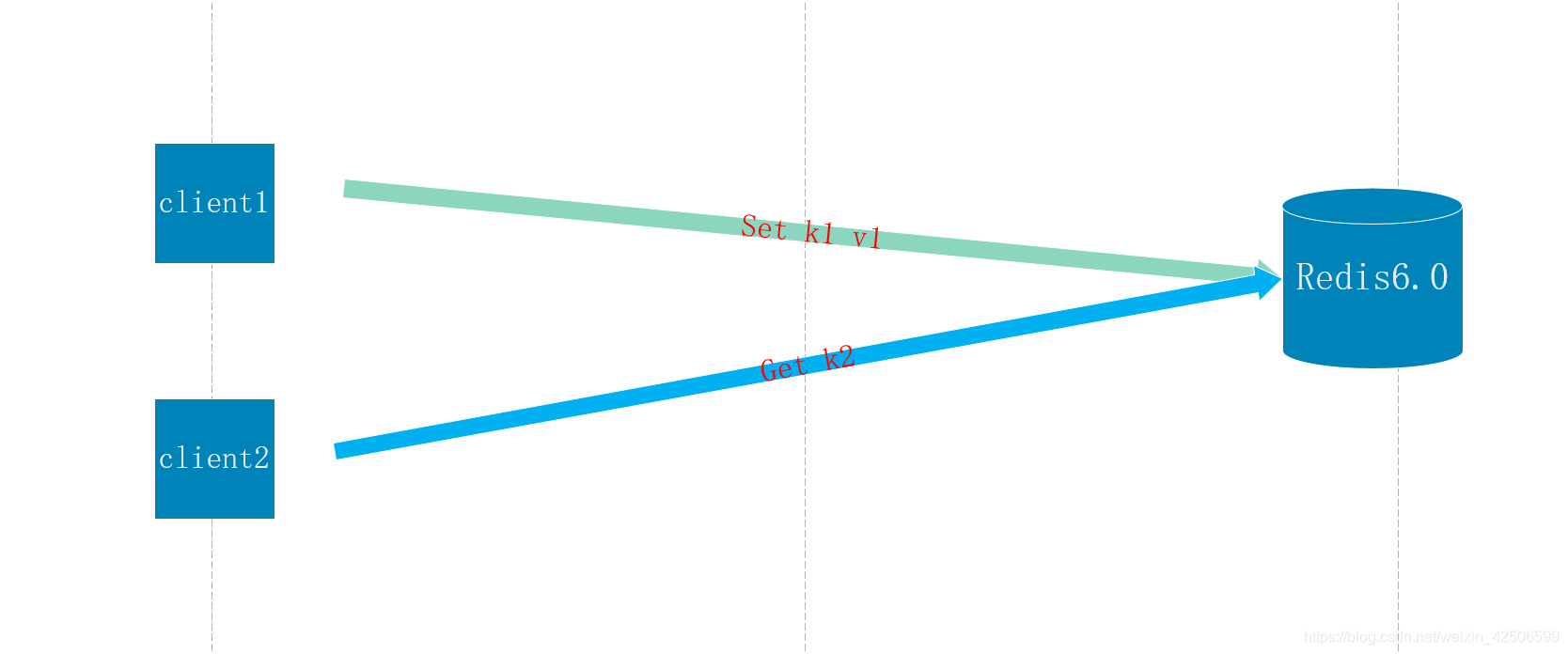
处理步骤:
1、work单线程先进行接受 并创建子进程进行读取IO流 简称 read io
2、work单线程对读取到的IO进行计算,插入到内存中
3、子进程将插入结果返回给客户端 简称 write io


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· C++代码改造为UTF-8编码问题的总结
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 实操Deepseek接入个人知识库
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· 【.NET】调用本地 Deepseek 模型
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库