
Centos7.0配置Hadoop2.7.0伪分布式
一、ssh免密登录
1.命令ssh-keygen、
overwrite输入y一路回车
2.将生成的密钥发送到本机
ssh-copy-id localhost中间会询问是否继续输入“yes”
3.测试免密登录是否成功
ssh localhost
二、Java配置
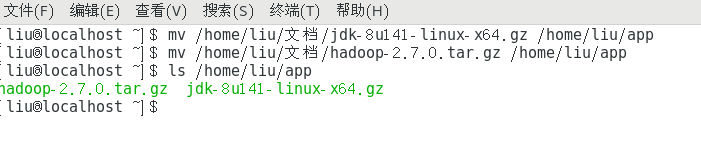
新建一个文件夹存放java和hadoop这里我在~目录下新建了一个app文件夹下面。

命令行移动文件到新建的app文件夹下。
解压jdk压缩包。

创建软连接或重命名已解压文件夹。

配置jdk环境变量。切换到root用户(输入su命令 切换root用户接着输入root用户密码),然后通过
vi /etc/profile
编辑、etc/profile文件配置环境变量。
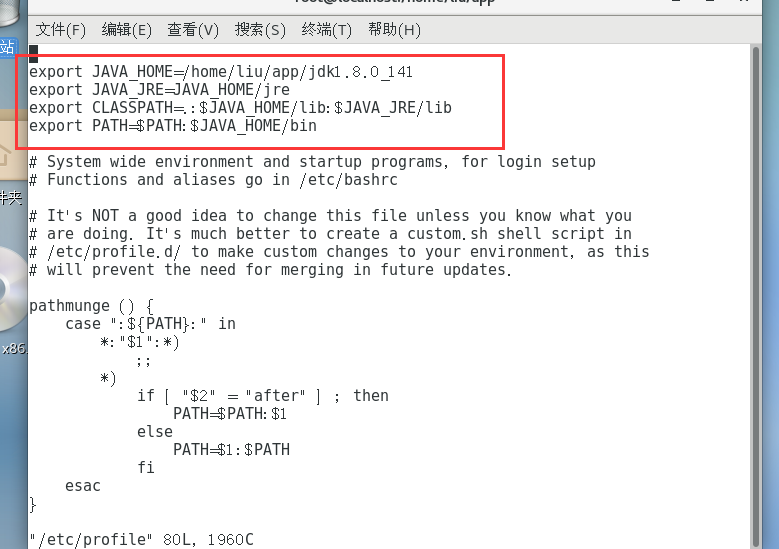
编辑好后Esc键接着“:”在输入wq保存并且退出编辑。
使/etc/profile生效,并检测是否配置成功。
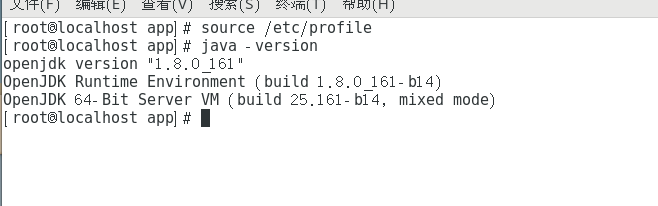
配置成功。
三、Hadoop配置
由root用户切换为普通用户,我这里用户名是liu所以使用命令 su liu。
解压Hadoop然后创建软连接或者重命名。

验证单击模式Hadoop是否安装成功,hadoop/bin/hadoop version
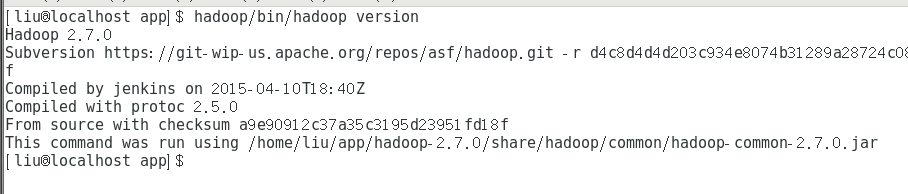
此时可以看到Hadoop版本2.7.0,安装成功。可以在hadoop目录下新建一个test.txt输入一下内容。
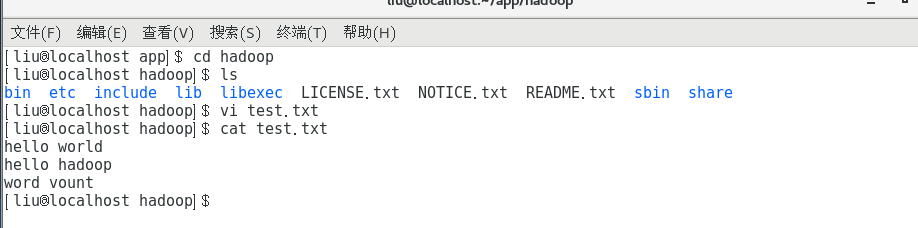
测试运行Hadoop自带的WordCount程序,统计单词个数。

查看结果文件夹output
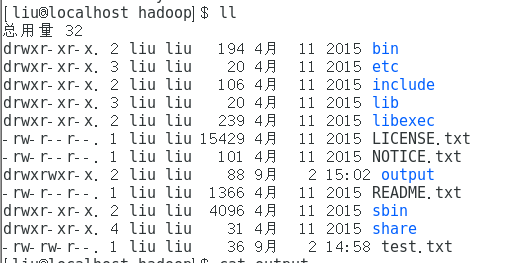
查看内容

四、Hadoop伪分布式配置
进入hadoop目录下的/etc/hadoop文件


<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/data/tmp</value> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> </configuration>
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/data/dfs/name</value> <final>true</final> </property> <property> <name>dfs.datanode.data.dir</name> <value>/data/dfs/data</value> <final>true</final> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
export JAVA_HOME=/home/liu/app/jdk1.8.0_141
<configuration> <property> <name>mapreduce.frameword.name</name> <value>yarn</value> </property> </configuration>
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-servies</name> <value>mapreduce_shuffle</value> </property> </configuration>
配置hadoop环境在 ~/.bashrc文件下

保存退出后记得source ~/.bashrc是修改生效。
然后在~下创建配置文件中的目录,
mkdir -p data/p
mkdir -p /data/dfs/name
mkdir -p /data/dfs/data
第一次需要格式化namenode,进入hadoop目录下。
cd /home/liu/app/hadoop
格式化。
bin/hdfs namenode -format
启动hadoop
sbin/start-all.sh
启动完毕后输入jps查看。
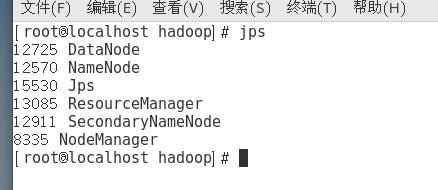
最重要的是NameNode和DataNode。这样就配置并且启动成功了。
需要注意的是如果jps后并没有则说明配置错误,请检查配置文件,若配置完环境变量后检测是否成功,提示失败并给出路径,很有可能是环境变量配置路径错误。
若第一次启动hadoop失败,后边重新启动的时候,请删除~下新建的data文件重新格式化NameNode。

