
用C语言实现了对英文文章中单词频率的统计,得到出现最多的前十个!
这是一道我们软件工程的个人作业,得到了这个题目,我第一个念头就是用C语言来编写,毕竟别的语言不太精通只能选择C语言!
程序说明:对于这个问题我的理解就是要通过结构体来实现对单词和出现次数的统计,先将文章读入,然后通过每次读入一个字符来判断它是否是字母,如果不是字母,那么就说明一个单词已经结束了,通过这样来确定单词的结束!通过将单词存入一个缓冲的数组,然后再和结构体的数组进行对比,如果单词有重复,那就将该单词出现的次数加一,如果没有出现,那就继续运行!最后通过一个冒泡排序算法,将A[i].num从大到小排序,最后输出出现字数最多的前十个!
程序代码:
#include "stdafx.h"
#include "stdio.h"
#include "string.h"
struct word
{
char str[30]; //单词
int num; //单词出现的次数
}A[1000];
int sum; //单词的总个数
void chuli(char s[])
{
int i,j;
int flag=0; //flag为零时没有重复的
for(i=0;i<=sum;i++)
{
if(strcmp(A[i].str,s)==0)
{
A[i].num++;
flag=1;
sum++;
}
}
if(flag==0)
{
for(j=0;j<30;j++)
A[sum].str[j]=s[j];
A[sum].num++;
sum++;
}
}
void paixu()
{
int i,j;
struct word a;
for(i=0;i<sum;i++)
{
for(j=i+1;j<sum;j++)
if(A[i].num<A[j].num)
{
a=A[j];
A[j]=A[i];
A[i]=a;
}
}
}
int main()
{
char ch,s[30];
int i,flag=0;
FILE *fp;
fp=fopen("d:\\a.txt","r");
if(fp==NULL)
{
printf("此文件不存在!\n");
}
sum=0;
ch=NULL;
for(i=0;i<1000;i++)
A[i].num=0;
while(ch!=-1)
{
for(i=0;i<30;i++)
s[i]='\0';
ch=fgetc(fp);
if((65<=ch&&ch<=90)||(ch>=97&&ch<=122))
{
for(i=0;;i++)
{
s[i]=ch;
ch=fgetc(fp);
if((65<=ch&&ch<=90)||(ch>=97&&ch<=122))continue;
else break;
}
chuli(s);
}
}
paixu();
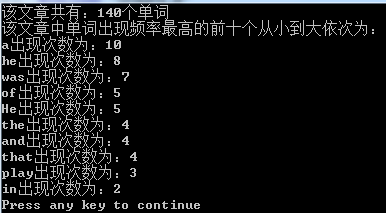
printf("该文章共有:%d个单词\n",sum);
printf("该文章中单词出现频率最高的前十个从小到大依次为:\n");
for(i=0;i<10;i++)
printf("%s出现次数为:%d\n",A[i].str,A[i].num);
return 0;
}
程序不足:区分了单词的大小写,因为有些单词的首字母是否大写表示的单词意思不同,我就将这中情况看做不同的单词!
程序截图:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号