SQL 基础
SQL 基础#
条件查询#
语法格式:#
select
字段1,字段2...
from
表名
where
条件;
执行顺序:#
先from,然后where,最后select.
<,>,<=,>=,<>,!=,and,between…and….,is null,is not null,or,in,not in,and和or联合使用(in等同于or)
模糊查询like
函数#
字符函数:#
length函数 select length('john');
concat函数拼接字符串
upper、lower函数改变大小写
substr、substring函数截取,索引从1开始
instr函数返回字符串第一次出现的索引,若找不到,则返回0
数学函数:#
round()函数四舍五入
ceil函数向上取整
floor函数向下取整
truncate函数截断
mod函数取余
日期函数:#
now函数
curdate函数返回当前日期,不包含时间
curtime函数返回当前时间,不包含日期
获取指定部分,年,月,日 select year(now()) as '年';
str_to_date函数
date_format函数
分组函数:#
count 计数
sum 求和
avg 平均值
max 最大值
min 最小值
分组函数自动忽略NULL。
count(*) filter (where ..)
排序:#
asc表示升序,desc表示降序。
完整的DQL语句:select … from … where … group by … having … order by … limit …
执行顺序 5 1 2 3 4 6 7
内连接#
内连接之等值连接:#
SQL92语法:
select
e.ename,d.dname
from
emp e, dept d
where
e.deptno = d.deptno;
SQL99语法:
select
e.ename,d.dname
from
emp e
join
dept d
on
e.deptno = d.deptno;
内连接之非等值连接:#
select
e.ename, e.sal, s.grade
from
emp e
join
salgrade s
on
e.sal between s.losal and s.hisal; // 条件不是一个等量关系,称为非等值连接。
内连接之自连接#
查询员工的上级领导,要求显示员工名和对应的领导名?技巧:一张表看成两张表。
select
a.ename as '员工名', b.ename as '领导名'
from
emp a
join
emp b
on
a.mgr = b.empno; //员工的领导编号 = 领导的员工编号
外连接#
外连接(右外连接):#
select
e.ename,d.dname
from
emp e
right join
dept d
on
e.deptno = d.deptno;
// outer是可以省略的,带着可读性强。
right代表什么:表示将join关键字右边的这张表看成主表,主要是为了将
这张表的数据全部查询出来,捎带着关联查询左边的表。
在外连接当中,两张表连接,产生了主次关系。
外连接(左外连接):#
select
e.ename,d.dname
from
dept d
left join
emp e
on
e.deptno = d.deptno;
// outer是可以省略的,带着可读性强。
带有right的是右外连接,又叫做右连接。
带有left的是左外连接,又叫做左连接。
任何一个右连接都有左连接的写法。
任何一个左连接都有右连接的写法。
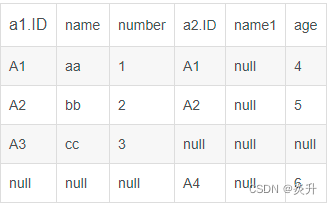
全连接 full join:#
FULL OUTER JOIN 关键字返回左表(left_table)和右表(right_table)中所有的行。
如果 "left_table" 表中的行在 "right_table" 中没有匹配或者 "right_table" 表中的行在
"left_table" 表中没有匹配,也会列出这些行。
a1
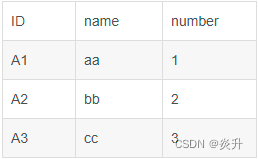
a2
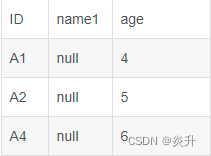
select a1.ID, name, number, a2.ID, name1, age from a1 full join a2 on a1.ID=a2.ID
结果
子查询:#
select
..(select).
from
..(select).
where
..(select).
union合并查询结果集#
select ename,job from emp where job = 'MANAGER'
union
select ename,job from emp where job = 'SALESMAN';
union的效率要高一些。对于表连接来说,每连接一次新表,
则匹配的次数满足笛卡尔积,成倍的翻。。。
但是union可以减少匹配的次数。在减少匹配次数的情况下,
还可以完成两个结果集的拼接。
limit(非常重要)#
完整用法:limit startIndex, length
startIndex是起始下标,length是长度。
起始下标从0开始。
缺省用法:limit 5; 这是取前5.
约束#
非空约束:not null
唯一性约束: unique
主键约束: primary key (简称PK)
外键约束:foreign key(简称FK)
检查约束:check(mysql不支持,oracle支持)
MySql/Oracle和SQL Server的分页查询
假设当前是第PageNo页,每页有PageSize条记录,现在分别用Mysql、Oracle和SQL Server分页查询student表。
1、Mysql的分页查询:#
SELECT
*
FROM
student
LIMIT (PageNo - 1) * PageSize,PageSize;
理解:(Limit n,m) =>从第n行开始取m条记录,n从0开始算。
2、Oracel的分页查询:#
SELECT
*
FROM
(
SELECT
S.*, ROWNUM rn
FROM
(SELECT * FROM Student) S
WHERE
Rownum <= pageNo * pageSize
)
WHERE
rn > (pageNo - 1) * pageSize或者
SELECT
*
FROM
(
SELECT
S.*, ROWNUM rn
FROM
(SELECT * FROM Student) S
)
WHERE
rn BETWEEN (pageNo - 1) * pageSize AND pageNo * pageSize
理解:假设pageNo = 1,pageSize = 10,先从student表取出行号小于等于10的记录,然后再从这些记录取出rn大于0的记录,从而达到分页目的。ROWNUM从1开始。
分析:对比这两种写法,绝大多数的情况下,第一个查询的效率比第二个高得多。
这是由于CBO 优化模式下,Oracle可以将外层的查询条件推到内层查询中,以提高内层查询的执行效率。对于第一个查询语句,第二层的查询条件WHERE ROWNUM <=
pageNo * pageSize就可以被Oracle推入到内层查询中,这样Oracle查询的结果一旦超过了ROWNUM限制条件,就终止查询将结果返回了。
而第二个查询语句,由于查询条件BETWEEN (pageNo - 1) * pageSize AND pageNo * pageSize是存在于查询的第三层,而Oracle无法将第三层的查询条件推到最内层(即使推到最内层也没有意义,因为最内层查询不知道RN代表什么)。因此,对于第二个查询语句,Oracle最内层返回给中间层的是所有满足条件的数据,而中间层返回给最外层的也是所有数据。数据的过滤在最外层完成,显然这个效率要比第一个查询低得多。
3、SQL Server分页查询:#
SELECT
TOP PageSize *
FROM
(
SELECT
ROW_NUMBER () OVER (ORDER BY id ASC) RowNumber ,*
FROM
student
) A
WHERE
A.RowNumber > (PageNo - 1) * PageSize
理解:假设pageNo = 1,pageSize = 10,先按照student表的id升序排序,rownumber作为行号,然后再取出从第1行开始的10条记录。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本