数仓 hive
数据仓库
数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。
数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持(Decision Support)。
OLTP 与OLAP#
OLTP(On-Line Transaction Processing):联机事务处理,典型代表是关系型数据库(mysql),它的数据存储在服务器本地的文件里
OLAP(On-Line Analytical Processing):联机分析处理,OLAP型数据库的典型代表是分布式文件系统(hive),它的数据存储在HDFS集群里

数仓主要特征#
- 面向主题: 主题是一个抽象的概念,是较高层次上
数据综合、归类并进行分析利用的抽象 - 集成性: 主题相关的数据通常会分布在多个操作型 系统中,彼此分散、独立、异构。需要集 成到
数仓主题下 - 非易失性: 也叫非易变性。数据仓库是
分析数据的平台,而不是创造数据的平台。 - 时变性: 数据仓库的数据
需要随着时间更新,以适 应决策的需要
数仓分层

数据仓库五层架构规范#
1.1 数据仓库为什么要分层#
把复杂问题简单化,每一层只处理简单的任务,方便定位问题;
减少重复开发,规范数据分层,通过中间层数据能够减少重复计算,且增加计算结果的复用性;
隔离原始数据,不论是数据的异常还是数据的敏感性,使真实数据与统计数据解耦开。
1.2 DW五层架构的特点#
细化DW建模,对DW中各个主题业务建模进行了细分,每个层次具有不同的功能。保留了最细粒度数据,满足了不同维度、不同事实的信息;
满足数据重新生产,不同层次的数据支持数据重新生成,无需备份恢复,解决了由不同故障带来的数据质量问题,消除了重新初始化数据的烦恼;
减少应用对DW的压力,以业务应用驱动为向导建模,避免直接操作基础事实表,降低数据获取时间;
快速适应需求变更和维度变化,明细基础数据层稳定,适应前端应用层业务需求变更,所有前端应用层模型之间不存在依赖,需求变更对DW整个模型影响范围小,能适应短周期内上线下线需求。
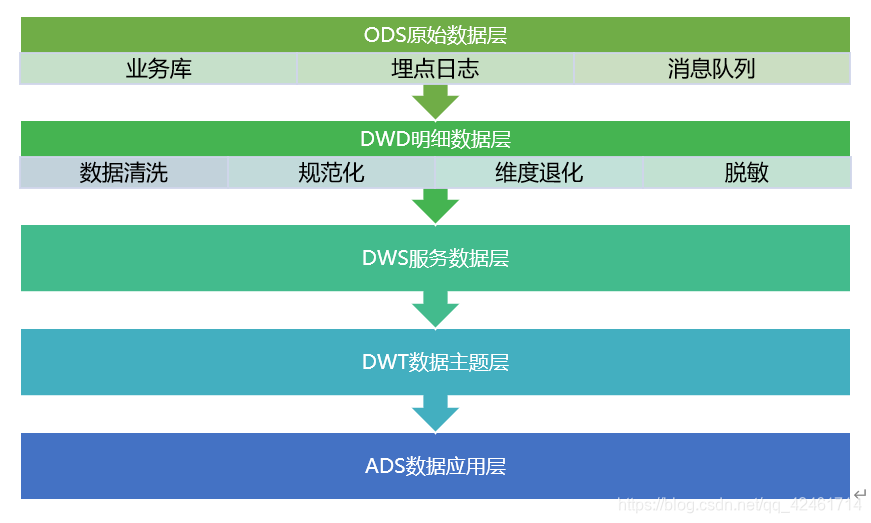
1.3 ODS(Operational Data Store)原始数据层#
数据准备区,也称为贴源层。数据仓库源头系统的数据表通常会原封不动的存储一份,以此减少对业务系统的影响,也是后续数据仓库加工数据的来源。业务DB基本上是直接同步过来,LOG主要做结构化。
1.3.1 ODS层数据的来源方式#
业务库
可使用Sqoop来抽取,例如每天定时抽取一次;
实时接入,考虑用canal监听MySQL的binlog;
Flume、Sqoop、Kettle等ETL工具导入到HDFS,并映射到HIVE的数据仓库表中。
埋点日志
日志一般以文件的形式保存,可以选择用Flume定时同步;
可以用Spark Streaming或者Flink来实时接入;
Kafka。
消息队列
来自ActiveMQ、Kafka的数据等。
1.3.2 建模方式及原则
从业务系统增量抽取;
保留时间由业务需求决定;
可分表进行周期存储;
数据不做清洗转换与业务系统数据模型保持一致;
按主题逻辑划分。
针对HDFS上的用户行为数据和业务数据,我们如何规划处理?
保持数据原貌不做任何修改,起到备份数据的作用;
数据采用压缩,减少磁盘存储空间;
创建分区表,防止后续的全表扫描。
1.4 DWD(Data Warehouse Detail)明细数据层#
DWD是业务层与数据仓库的隔离层,主要对ODS数据层做一些数据清洗(去除空值、脏数据、超过极限范围的数据)、规范化、维度退化、脱敏等操作。
1.4.1 建模方式及原则
需要构建维度模型,一般采用星型模型,呈现的状态一般为星座模型(由多个事实表组合,维表是公共的,可被多个事实表共享);
为支持数据重跑可额外增加数据业务日期字段,可按年月日进行分表,用增量ODS层数据和前一天DWD相关表进行merge处理;
粒度是一行信息代表一次行为,例如一次下单。
1.4.2 维度建模步骤
选择业务过程:在业务系统中,挑选感兴趣的业务线,比如下单业务,支付业务,退款业务,物流业务,一条业务线对应一张事实表。如果是中小公司,尽量把所有业务过程都选择。如果是大公司(1000多张表),选择和需求相关的业务线。
声明粒度:数据粒度指数据仓库的数据中保存数据的细化程度或综合程度的级别。声明粒度意味着精确定义事实表中的一行数据表示什么,应该尽可能选择最小粒度,以此来应各种各样的需求。典型的粒度声明如下:订单当中的每个商品项作为下单事实表中的一行,粒度为每次。每周的订单次数作为一行,粒度为每周。每月的订单次数作为一行,粒度为每月。如果在DWD层粒度就是每周或者每月,那么后续就没有办法统计细粒度的指标了。所以建议采用最小粒度。
确定维度:维度的主要作用是描述业务是事实,主要表示的是“谁,何处,何时”等信息。确定维度的原则是:后续需求中是否要分析相关维度的指标。例如,需要统计,什么时间下的订单多,哪个地区下的订单多,哪个用户下的订单多。需要确定的维度就包括:时间维度、地区维度、用户维度。维度表:需要根据维度建模中的星型模型原则进行维度退化。
确定事实:此处的“事实”一词,指的是业务中的度量值(次数、个数、件数、金额,可以进行累加),例如订单金额、下单次数等。在DWD层,以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表。事实表可做适当的宽表化处理。
注意:DWD层是以业务过程为驱动。DWS层、DWT层和ADS层都是以需求为驱动,和维度建模已经没有关系了。DWS和DWT都是建宽表,按照主题去建表。主题相当于观察问题的角度。对应着维度表。
1.5 DWS(Data Warehouse Service)服务数据层#
DWB:data warehouse base 数据基础层,存储的是客观数据,一般用作中间层,可以认为是大量指标的数据层。
以DWD为基础,按天进行轻度汇总。粒度是一行信息代表一天的行为,例如一天下单次数。
1.5.1 功能
DWB是根据DWD明细数据经行清晰转换,如维度转代理键、身份证清洗、会员注册来源清晰、字段合并、空值处理、脏数据处理、IP清晰转换、账号余额清洗、资金来源清洗等;
DWS是根据DWB层数据按各个维度ID进行粗粒度汇总聚合,如按交易来源,交易类型进行汇合。
1.5.2 建模方式及原则
聚合、汇总增加派生事实;
关联其它主题的事实表,DW层可能会跨主题域;
DWB保持低粒度汇总加工数据,DWS保持高粒度汇总数据;
数据模型可能采用反范式设计,合并信息等。
1.6 DWT(Data Warehouse Topic)数据主题层#
以DWS为基础,按主题进行汇总。粒度是一行信息代表累积的行为,例如用户从注册那天开始至今一共下了多少次单。
1.6.1 功能
可以是一些宽表,是根据DW层数据按照各种维度或多种维度组合把需要查询的一些事实字段进行汇总统计并作为单独的列进行存储;
满足一些特定查询、数据挖掘应用。
1.6.2 建模方式及原则
尽量减少数据访问时计算,优化检索;
维度建模,星型模型;
事实拉宽,度量预先计算;
分表存储。
1.7 ADS(Application Data Store)数据应用层#
面向实际的数据需求,同步到关系型数据库服务RDS。该层主要是提供数据产品和数据分析使用的数据,一般会存储在ES、mysql等系统中供线上系统使用。我们通过说的报表数据,或者说那种大宽表,一般就放在这里。为应用层,这层数据是完全为了满足具体的分析需求而构建的数据,也是星形结构的数据。应用层为前端应用的展现提现数据,可以为关系型数据库组成。
1.7.1 功能
ST层面向用户应用和分析需求,包括前端报表、分析图表、KPI、仪表盘、OLAP、专题等分析,面向最终结果用户;
适合作OLAP、报表模型,如ROLAP、MOLAP;
根据DW层经过聚合汇总统计后的粗粒度事实表。
1.7.2 建模方式及原则
保持数据量小;
维度建模,星形模型;
各位维度代理键+度量;
增加数据业务日期字段,支持数据重跑;
不分表存储。
1.8 其他层
数据缓存层:用于存放接口方提供的原始数据的数据库层,此层的表结构与源数据保持基本一致,数据存放时间根据数据量大小和项目情况而定,如果数据量较大,可以只存近期数据,将历史数据进行备份。此层的目的在于数据的中转和备份。
临时数据表层:存放临时测试数据表(Temp表),或者中间结果集的表。
补充点#
2.1 事实表#
是数据仓库结构中的中央表,它包含联系事实与维度表的数字度量值和键。事实数据表包含描述业务(例如产品销售)内特定事件的数据。
1)、事实表就是你要关注的内容;
2)、维度表就是你观察该事务的角度,是从哪个角度去观察这个内容的。
例如,某地区商品的销量,是从地区这个角度观察商品销量的。事实表就是销量表,维度表就是地区表。
2.2 维度表#
是维度属性的集合。是分析问题的一个窗口。是人们观察数据的特定角度,是考虑问题时的一类属性,属性的集合构成一个维。数据库结构中的星型结构,该结构在位于结构中心的单个事实数据表中维护数据,其它维度数据存储在维度表中。每个维度表与事实数据表直接相关,且通常通过一个键联接到事实数据表中。星型架构是数据仓库比较流向的一种架构。
星型模式的基本思想就是保持立方体的多维功能,同时也增加了小规模数据存储的灵活性。
2.3 主题表#
主题(Subject)是在较高层次上将企业信息系统中的数据进行综合、归类和分析利用的一个抽象概念,每一个主题基本对应一个宏观的分析领域。在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象。例如“销售分析”就是一个分析领域,因此这个数据仓库应用的主题就是“销售分析”。
面向主题的数据组织方式,就是在较高层次上对分析对象数据的一个完整并且一致的描述,能刻画各个分析对象所涉及的企业各项数据,以及数据之间的联系。所谓较高层次是相对面向应用的数据组织方式而言的,是指按照主题进行数据组织的方式具有更高的数据抽象级别。与传统数据库面向应用进行数据组织的特点相对应,数据仓库中的数据是面向主题进行组织的。例如,一个生产企业的数据仓库所组织的主题可能有产品订货分析和货物发运分析等。而按应用来组织则可能为财务子系统、销售子系统、供应子系统、人力资源子系统和生产调度子系统。
2.4 宽表#
含义:指字段比较多的数据库表。通常是指业务主体相关的指标、纬度、属性关联在一起的一张数据库表。
特点:宽表由于把不同的内容都放在同一张表,宽表已经不符合三范式的模型设计规范:
坏处:数据有大量冗余
好处:查询性能的提高和便捷
宽表的设计广泛应用于数据挖掘模型训练前的数据准备,通过把相关字段放在同一张表中,可以大大提供数据挖掘模型训练过程中迭代计算的消息问题。
2.5 数据库设计三范式#
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式时符合某一种设计要求的总结。
第一范式:确保每列保持原子性,即要求数据库表中的所有字段值都是不可分解的原子值。
第二范式:确保表中的每列都和主键相关。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
作用:减少了数据库的冗余
第三范式:确保每列都和主键列直接相关,而不是间接相关。
2.6 数仓命名规范#
表命名
ODS层命名为ods_表名
DWD层命名为dwd_dim/fact_表名
DWS层命名为dws_表名
DWT层命名为dwt_表名
ADS层命名为ads_表名
临时表命名为xxx_tmp
用户行为表,以log为后缀
数据源_to_目标_db/log.sh
用户行为脚本以log为后缀
业务数据脚本以db为后缀
数量类型为bigint
金额类型为decimal(16,2),表示:16位有效数字,其中小数部分2位
字符串(名字,描述信息等)类型为string
主键外键类型为string
时间戳类型为bigint
脚本命名
数据源_to_目标_db/log.sh
用户行为脚本以log为后缀;业务数据脚本以db为后缀
表字段类型
数量类型为bigint
金额类型为decimal(16, 2),表示:16位有效数字,其中小数部分2位
字符串(名字,描述信息等)类型为string
主键外键类型为string
时间戳类型为bigint
Hive
Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化 数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和 分析存储在Hadoop文件中的大型数据集。Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行。 Hive由Facebook实现并开源。
Hive利用HDFS存储数据,利用MapReduce查询分析数据。
hive组件#
- 元数据存储: 通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是 否为外部表等),表的数据所在目录等
- Driver驱动程序,包括语法解析器、计划编译器、优化器、执行器 : 完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在 随后有执行引擎调用执行。
- 执行引擎 : Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark3种执行引擎
元数据#
元数据(Metadata),又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属 性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能 。
Hive Metadata 即Hive的元数据 , 包含用Hive创建的database、table、表的位置、类型、属性,字段顺序类型等元信息, 元数据存储在关系型数据库中。如hive内置的Derby、或者第三方如MySQL等。
- Metastore即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通 过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。
- 有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码 ,只需要连接metastore 服务即可。某种程度上也保证了hive元数据的安全。
- metastore服务配置有3种模式:内嵌模式、本地模式、远程模式。
Hive客户端
Hive的ddl操作
1 Hive的数据库DDL操作#
#创建数据库
hive> show databases;
#显示数据库
hive> show databases like 'db_hive*';
#查看数据库详情
hive> desc database db_hive;
#显示数据库详细信息
hive> desc database extended db_hive;
#切换当前数据库
hive > use db_hive;
#删除数据库
hive> drop database if exists db_hive;
#如果数据库中有表存在,那么要加cascade强制删除
hive> drop database if exists db_hive cascade;
2 Hive的表DDL操作(重要)#
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] 分区
[CLUSTERED BY (col_name, col_name, ...) 分桶
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format] row format delimited fields terminated by “分隔符”
[collection items terminated by ':'] (指定struct数据类型内的分隔符)
[map keys terminated by ':'] (指定map键值对的分隔符)
[STORED AS file_format]
[LOCATION hdfs_path]
有三种常用建表方法
#直接建表
create table if not exists student(
id int,
name string
)
row format delimited fields terminated by '\t' (如果不指定,整行数据会被当做一个字段)
stored as textfile;(不指定就默认是文本文件)
#通过AS语句,将查询的子结果存在新表里
create table if not exists student1 as select id, name from student;
#Like建表法
create table if not exists student2 like student;
查询表类型
hive > desc formatted student;
3 创建外部表#
create external table if not exists default.emp(
id int,
name string,
age int
)
row format delimited fields terminated by '\t'
location '/hive/bigdata' (这个目录可以现实不存在,建表时创建)
- 创建外部表的时候需要加上external 关键字
- location字段可以指定,也可以不指定
- 指定就是数据存放的具体目录
- 不指定就是使用默认目录 /user/hive/warehouse
在建表的数据库位置执行 load data local inpath '/home/hadoop/data/student.txt' into table student; 需要注意的是,这里就算直接把txt文件的数据存放到hdfs上表对应的存储目录,那么在select * FROM时也能查出后来添加的数据,因为建表定义存放位置时,实际是指向具体的文件,将文件映射成表结构展示出来。
内部表与外部表的区别
- 1.创建表时:创建内部表时,会将数据移动到数据仓库指向的路径;创建外部表时需要加上external关键字,它仅记录数据所在的路径,不对数据的位置做任何改变
- 2.删除表时:删除表后,内部表的元数据和真实数据会被一起删除,而外部表仅删除元数据,不删除真实数据,这样外部表相对来说更加安全些,数据组织也比较灵活,方便共享原始数据。(直接重建原来的表后,数据就自动导入到原来的表去了,location直接指向原来存储的位置.)
- 外部表保障底层数据的安全性,内部表适用于管理中间表和结果表。
4.hive的分区表的概念#
把表的数据分目录存储,存储在不同的文件夹下,后期按照不同的目录查询数据,不需要进行全量扫描,提升查询效率。 分区没有上限,但一般是3个以内。
- 创建一个分区字段的分区表,一级分区
create table student_partition1(
id int,
name string,
age int
)
partitioned by (dt string)
row format delimited fields terminated by '\t';
- 创建二级分区
create table student_partition2(
id int,
name string,
age int
)
partitioned by (month string,day string)
row format delimited fields terminated by '\t';
5.hive修改表#
#修改表名称
alter table student_partition1 rename to student_P1;
#查看表的信息
desc student_p1;
desc formatted student_p1;
#增加列
alter table student add columns(address string);
#修改列
alter table student change columns address address_id int;
#替换列
alter table student replace columns(deptno string,dname string,loc string); --替换表中所有的字段。
- 修改分区(注意这里partition不加ed)
#添加单个分区
alter table student add partition(dt='20200402');
#添加多个分区
alter table student add partition(dt='20200401',dt='20200402');
或者
alter table student add partition(dt='20200401') partition(dt='20200402');
#删除分区
alter table student drop partition(dt=‘20200401’);
alter table student drop partition(‘20200401’),partition(dt=‘20200402’);
#查看分区
show partitions student;
6.hive的分桶表#
分桶是将整个数据内容按照某列属性值去hash值进行区分,对取得的hash再做模运算(columnValue.hashCode % 桶数),具有相同结果的数据进入同一个文件中。(本质上来说可以看成是对一个大文件进行拆分成小文件) 比如将name列分为4个桶,则name属性的值取hash值后对4求模运算,取模结果0,1,2,3的分开存放到不同文件中。
7.hive的SerDe#
SerDe是Serializer/Deserializer(序列化和反序列化)的简写,hive使用Serde进行 行对象的序列和反序列化,最后实现把文件内容映射到hive表中。
HDFS file -> InputFileFormat -> key,value -> Deserializer(反序列化) -> Row object
REATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [col_name... ]...)] [COMMENT table_comment]
[PARTITIONED BY (col_name data_type)]
[CLUSTERED BY (col_name data_type)]
[SORTED BY (col_name [ASC|DESC]...)] INTO num_buckers BUCKETS
[ROW FORMAT row_format] (可以指定SerDe的类型)
[STORED AS file_format]
[LOCATION hdfs_path]
创建表时可以使用用户自定义的SerDe或者native SerDe,如果ROW FORMAT没有指定,或者指定了ROW FORMAT DELIMITED就会使用native SerDe类型
Hive SerDe:Avro ORC RegEx Thrift Parquet CSV MultiDelimitSerDe




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具