sql
SQL 基础#
条件查询#
语法格式:#
select
字段1,字段2...
from
表名
where
条件;
执行顺序:#
先from,然后where,最后select.
<,>,<=,>=,<>,!=,and,between…and….,is null,is not null,or,in,not in,and和or联合使用(in等同于or)
模糊查询like
函数#
字符函数:#
length函数 select length('john');
concat函数拼接字符串
upper、lower函数改变大小写
substr、substring函数截取,索引从1开始
instr函数返回字符串第一次出现的索引,若找不到,则返回0
数学函数:#
round()函数四舍五入
ceil函数向上取整
floor函数向下取整
truncate函数截断
mod函数取余
日期函数:#
now函数
curdate函数返回当前日期,不包含时间
curtime函数返回当前时间,不包含日期
获取指定部分,年,月,日 select year(now()) as '年';
str_to_date函数
date_format函数
分组函数:#
count 计数
sum 求和
avg 平均值
max 最大值
min 最小值
分组函数自动忽略NULL。
count(*) filter (where ..)
排序:#
asc表示升序,desc表示降序。
完整的DQL语句:select … from … where … group by … having … order by … limit …
执行顺序 5 1 2 3 4 6 7
内连接#
内连接之等值连接:#
SQL92语法:
select
e.ename,d.dname
from
emp e, dept d
where
e.deptno = d.deptno;
SQL99语法:
select
e.ename,d.dname
from
emp e
join
dept d
on
e.deptno = d.deptno;
内连接之非等值连接:#
select
e.ename, e.sal, s.grade
from
emp e
join
salgrade s
on
e.sal between s.losal and s.hisal; // 条件不是一个等量关系,称为非等值连接。
内连接之自连接#
查询员工的上级领导,要求显示员工名和对应的领导名?技巧:一张表看成两张表。
select
a.ename as '员工名', b.ename as '领导名'
from
emp a
join
emp b
on
a.mgr = b.empno; //员工的领导编号 = 领导的员工编号
外连接#
外连接(右外连接):#
select
e.ename,d.dname
from
emp e
right join
dept d
on
e.deptno = d.deptno;
// outer是可以省略的,带着可读性强。
right代表什么:表示将join关键字右边的这张表看成主表,主要是为了将
这张表的数据全部查询出来,捎带着关联查询左边的表。
在外连接当中,两张表连接,产生了主次关系。
外连接(左外连接):#
select
e.ename,d.dname
from
dept d
left join
emp e
on
e.deptno = d.deptno;
// outer是可以省略的,带着可读性强。
带有right的是右外连接,又叫做右连接。
带有left的是左外连接,又叫做左连接。
任何一个右连接都有左连接的写法。
任何一个左连接都有右连接的写法。
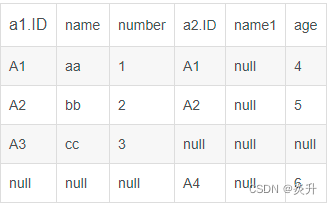
全连接 full join:#
FULL OUTER JOIN 关键字返回左表(left_table)和右表(right_table)中所有的行。
如果 "left_table" 表中的行在 "right_table" 中没有匹配或者 "right_table" 表中的行在
"left_table" 表中没有匹配,也会列出这些行。
a1
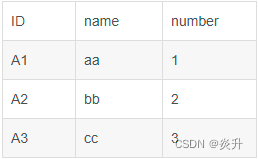
a2
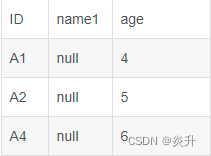
select a1.ID, name, number, a2.ID, name1, age from a1 full join a2 on a1.ID=a2.ID
结果
子查询:#
select
..(select).
from
..(select).
where
..(select).
union合并查询结果集#
select ename,job from emp where job = 'MANAGER'
union
select ename,job from emp where job = 'SALESMAN';
union的效率要高一些。对于表连接来说,每连接一次新表,
则匹配的次数满足笛卡尔积,成倍的翻。。。
但是union可以减少匹配的次数。在减少匹配次数的情况下,
还可以完成两个结果集的拼接。
limit(非常重要)#
完整用法:limit startIndex, length
startIndex是起始下标,length是长度。
起始下标从0开始。
缺省用法:limit 5; 这是取前5.
约束#
非空约束:not null
唯一性约束: unique
主键约束: primary key (简称PK)
外键约束:foreign key(简称FK)
检查约束:check(mysql不支持,oracle支持)
postgresql数据库#
数据库操作#
\q:退出当前选择的库
\l:查看当前有多少数据库
\c 数据库名:切换数据库
create database 数据库名
drop database 数据库名
psql -d 指定的数据库 快速打开指定的数据库
数据表操作#
\d:查看表信息
\d 表名: 查看表格信息
建表:
serial自增
create table student1(id serial primary key,name varchar(255),age int);
删表
DROP TABLE student;
数据
insert into student (name,age) values ('张三',20);
update student set name='李四' where id=1;
delete from student where id=1;
数据类型#
| 名字 | 存储长度 | 描述 | 范围 |
|---|---|---|---|
| smallint | 2 字节 | 小范围整数 | -32768 到 +32767 |
| integer | 4 字节 | 常用的整数 | -2147483648 到 +2147483647 |
| bigint | 8 字节 | 大范 围整数 | -9223372036854775808 到 +9223372036854775807 |
| decimal | 可变长 | 用户指定的精度,精确 | 小数点前 131072 位;小数点后 16383 位 |
| numeric | 可变长 | 用户指定的精度,精确 | 小数点前 131072 位;小数点后 16383 位 |
| real | 4 字节 | 可变精度,不精确 | 6 位十进制数字精度 |
| double precision | 8 字节 | 可变精度,不精确 | 15 位十进制数字精度 |
| smallserial | 2 字节 | 自增的小范围整数 | 1 到 32767 |
| serial | 4 字节 | 自增整数 | 1 到 2147483647 |
| bigserial | 8 字节 | 自增的大范围整数 | 1 到 9223372036854775807 |
字符串:
-
varchar(n),character varying(n), varchar(n) 变长,有长度限制
-
char(n) 定长,不足不空白
-
text:变长,character(n),无长度限制
日期:
-
timestramp:日期和时间
-
date:日期,无时间
-
time:时间
case when#
第一种 格式 : 简单Case函数 :
case 列名
when 条件值1 then 选择项1
when 条件值2 then 选项2.......
else 默认值 end
select
case job_level
when '1' then '1111'
when '2' then '1111'
when '3' then '1111'
else 'eee' end
from dbo.employee
第二种 格式 :Case搜索函数
case
when 列名= 条件值1 then 选择项1
when 列名=条件值2 then 选项2.......
else 默认值 end
eg:
update employee
set e_wage =
case
when job_level = '1' then e_wage*1.97
when job_level = '2' then e_wage*1.07
when job_level = '3' then e_wage*1.06
else e_wage*1.05
end
#### SQL中如何处理除数为0
情况一
例如
SELECT A/B FROM TAB
SELECT
CASE WHEN B=0 THEN 0 ELSE A/B END
FROM TAB
情况二
例如
SELECT SUM(A)/COUNT(B) FROM TAB
SELECT
ISNULL(SUM(A)/NULLIF(COUNT(B),0),0)
FROM TAB
其中这里使用了两个函数,NULLIF()和ISNULL() NULLIF函数有两个参数,定义如下:
NULLIF( expression1 , expression2 )
其作用就是:如果两个指定的表达式相等,就返回NULL值。
ISNULL函数也有两个参数,定义如下:
ISNULL( expression1 , expression2 )
其作用是:如果第一个参数的结果为NULL,就返回第二个参数的值。
当COUNT(B)的结果为0时,恰好与第二个给定的参数0相等,这个时候NULLIF函数就会返回NULL,而SUM(A)在除以NULL时结果为NULL,外层使用ISNULL函数再对NULL值进行判断,这样最终结果就是0了。
字符串函数#
拼接字符串#
select 'a' || 1;
select 2 || 'a' || 1;
select 2 || 44 || 'a' || 1; --Error
填充字符串#
lpad(string text, length int [, fill text])是在字符串左边填充字符,如果不指定要填充的字符,则默认填充空格
select LPAD((99 - 1)::text, 6); -- 98
select LPAD((99 - 1)::text, 6, '0'); --000098
select LPAD((99 + 1)::text, 6, 'ab'); --aba100
大小写转换#
upper和lower函数
select upper('test'); --TEST
select lower('TEST'); --test
获取字符串长度#
length、char_length和character_length函数
select length('test'); --4
select char_length('test'); --4
select character_length('test'); --4
截取字符串#
substring函数,支持下标范围截取或者正则表达式截取,
也可以用substr
select substring('PostgreSQL' from 2 for 4); --ostg
select substring('PostgreSQL' from '[a-z]+'); --ostgre
select substr('PostgreSQL', 2, 0); --空字符串
select substr('PostgreSQL', 2, 1); --o
select substr('PostgreSQL', 2, 4); --ostg
select substr('PostgreSQL', 2); --ostgreSQL
裁剪字符串#
trim函数,从字符串的开头/结尾/两边(leading/trailing/both)尽可能多地裁剪指定的字符,不指定则裁剪空白符
select trim(leading 'x' from 'xTestxx'); --Testxx
select trim(trailing 'x' from 'xTestxx'); --xTest
select trim(both 'x' from 'xTestxx'); --Test
select trim(both from ' Test '); --Test
select trim(' Test '); --Test
也可以用ltrim,rtrim或者btrim函数,效果同上:
select ltrim('xTestxxy', 'xy'); --Testxxy
select rtrim('xTestxxy', 'xy'); --xTest
select btrim('xTestxxy', 'xy'); --Test
nullif函数#
nullif(a, b)用来检测a参数是否与b参数相等,这里的a、b参数必须是同一种数据类型,否则会报错。当a参数与b参数相等时会返回null,否则返回a参数。
select nullif('test', 'unexpected'); --test
select nullif('unexpected', 'unexpected'); --null
select nullif(233, 111); --233
判断是否包含字符串#
position函数会返回字符串首次出现的位置,如果没有出现则返回0。因此可以通过返回值是否大于0来判断是否包含指定的字符串。strpos函数也是同样的效果:
select position('aa' in 'abcd'); --0
select position('bc' in 'abcd'); --2
select position('bc' in 'abcdabc'); --2
select strpos('abcd','aa'); --0
select strpos('abcd','bc'); --2
select strpos('abcdabc','bc'); --2
合并字符串#
string_agg函数可以将一个字符串列合并成一个字符串,该函数需要指定分隔符,还可以指定合并时的顺序,或者是对合并列进行去重:
select ref_no from cnt_item where updated_on between '2021-05-05' and '2021-05-30 16:13:25';
--结果如下:
--ITM2105-000001
--ITM2105-000002
--ITM2105-000003
--ITM2105-000003
select string_agg(ref_no, ',') from cnt_item where updated_on between '2021-05-05' and '2021-05-30 16:13:25';
--合并结果:ITM2105-000001,ITM2105-000002,ITM2105-000003,ITM2105-000003
将字符串合并成一个数组#
array_agg和string_agg函数类似,但会把一个字符串列合并成一个数组对象,同样支持指定合并顺序和去重操作;合并成数组后意味着你可以像数组那样去读取它,需要注意的是,数据库的数组下标是从1开始的,而不是从0开始:
select array_agg(distinct ref_no) from cnt_item where updated_on between '2021-05-05' and '2021-05-30 16:13:25';
--合并结果:{ITM2105-000001,ITM2105-000002,ITM2105-000003}
分割字符串#
string_to_array函数可以分割字符串,返回值是一个数组:
select string_to_array('ITM2105-000001&ITM2105-000002&ITM2105-000003', '&');
--结果:{ITM2105-000001,ITM2105-000002,ITM2105-000003}
字符串转换#
cast(i.monitoring_item_value as double precision)
cast(sum(no_month_flow)as decimal(18,2) )
extract(year from now())
like CONCAT('%', #{userId}, '%')
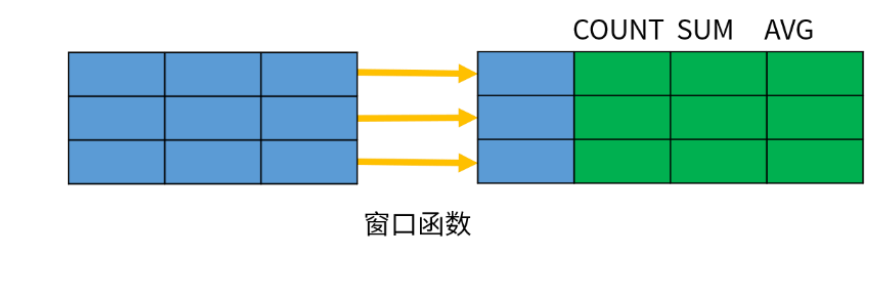
pg窗口函数介绍#
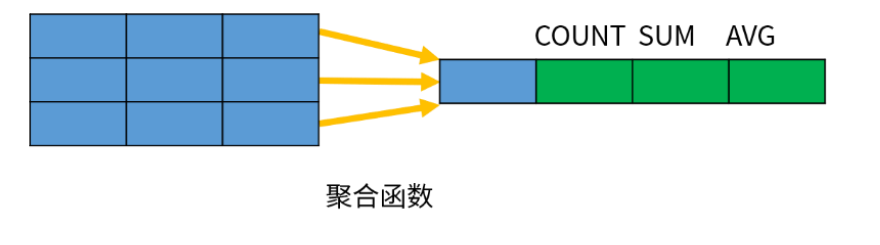
窗口函数是对数据进行分析处理的一种函数
-
常见的聚合函数,包括 AVG、COUNT、MAX、MIN、SUM。聚合函数的作用是针对一组数据行进行运算,并且返回一条汇总结果。
-
SQL 还定义了许多专门用于数据分析的窗口函数(Window Function)。 不过,窗口函数不是将一组数据汇总为单个结果,而是针对每一行数据,基于和它相关的一组数 据计算出一个结果。
建表语句
-- public.employees definition
-- Drop table
-- DROP TABLE employees;
CREATE TABLE employees (
employee_id int4 NOT NULL,
first_name varchar(20) NULL,
last_name varchar(25) NOT NULL,
email varchar(25) NOT NULL,
phone_number varchar(20) NULL,
hire_date date NOT NULL,
job_id varchar(10) NOT NULL,
salary numeric(8, 2) NULL,
commission_pct numeric(2, 2) NULL,
manager_id int4 NULL,
department_id int4 NULL,
CONSTRAINT emp_email_uk UNIQUE (email),
CONSTRAINT emp_emp_id_pk PRIMARY KEY (employee_id),
CONSTRAINT emp_salary_min CHECK ((salary > (0)::numeric))
);
-- public.employees foreign keys
ALTER TABLE public.employees ADD CONSTRAINT emp_dept_fk FOREIGN KEY (department_id) REFERENCES departments(department_id);
ALTER TABLE public.employees ADD CONSTRAINT emp_job_fk FOREIGN KEY (job_id) REFERENCES jobs(job_id);
ALTER TABLE public.employees ADD CONSTRAINT emp_manager_fk FOREIGN KEY (manager_id) REFERENCES employees(employee_id);
举例:使用差异
--(1) 使用差异
-- 平均月薪
SELECT avg(salary)
FROM employees;
-- 损失了员工信息,只返回了结果
-- 我想要输出员工的平均薪资并且返回员工信息
-- 聚合函数
SELECT employee_id,first_name,salary,avg(salary)
FROM employees;
-- 窗口函数
SELECT employee_id,first_name,salary,avg(salary) over()
FROM employees;
窗口函数定义:(OVER)
window_function (expression) OVER (
[ PARTITION BY part_list ]
[ ORDER BY order_list ]
[ { ROWS | RANGE } BETWEEN frame_start AND frame_end ] )
窗口函数出现在 SELECT 子句的表达式列表中,它最显著的特点就是 OVER 关键字。
PARTITION BY 表示将数据先按 part_list 进行分区。
ORDER BY 表示将各个分区内的数据按 order_list 进行排序(在区域内排序)。
最后一项表示 Frame 的定义,即:当前窗口包含哪些数据?
ROWS 选择前后几行
例如 ROWS BETWEEN 3 PRECEDING AND 3 FOLLOWING 表示往前3行到往后3行,一共7行数据(或小于7行,如果碰到了边界)
RANGE 选择数据范围
例如 RANGE BETWEEN 3 PRECEDING AND 3 FOLLOWING 表示所有值在[c−3,c+3]这个范围内的行,c为当前行的值。
当over后什么都不写,会返回所有数据的平均值
PARTITION BY#
PARTITION BY 选项用于定义分区,作用类似于 GROUP BY 的分组。如果指定了分区选项, 窗口函数将会分别针对每个分区单独进行分析;如果省略分区选项,所有的数据作为一个整体进 行分析
-- 按照部门分区,统计每个部门的平均值
SELECT employee_id,first_name,salary,department_id ,avg(salary) over(partition by department_id)
FROM employees;
ORDER BY#
ORDER BY 选项用于指定分区内的排序方式,通常用于数据的排名分析
-- 使用rank函数,查询每个部门收入从高到低排名(部门内排名)
SELECT employee_id,first_name,salary,department_id ,rank() over(partition by department_id order by salary desc)
FROM employees;
-- 如果把partition by去掉,返回整个员工的排名
SELECT employee_id,first_name,salary,department_id ,rank() over( order by salary desc)
FROM employees;
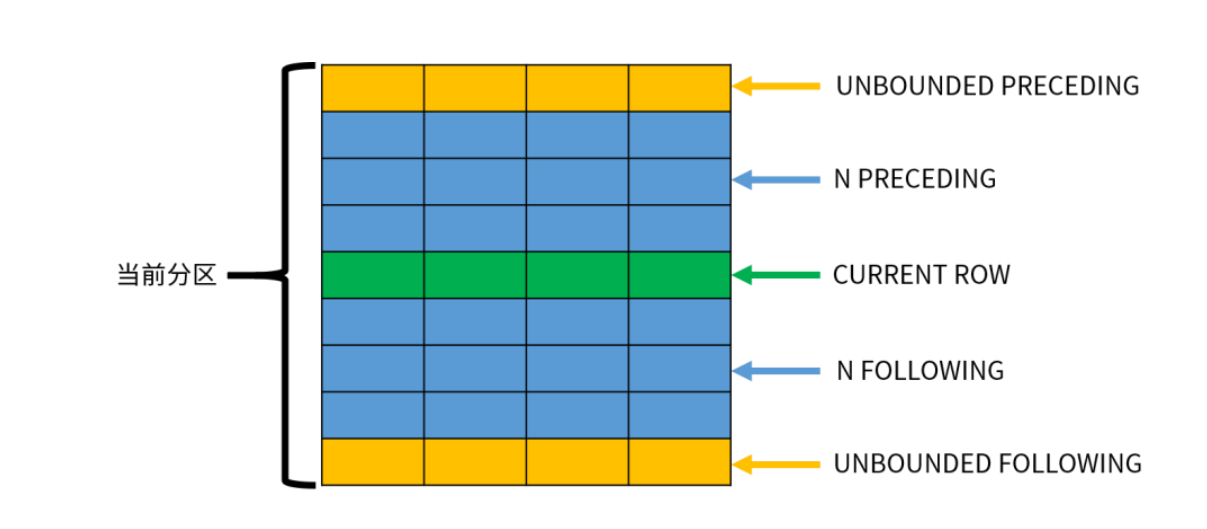
frame_clause#
frame_clause 选项用于在当前分区内指定一个计算窗口。指定了窗口之后,分析函数不再基 于分区进行计算,而是基于窗口内的数据进行计算。
实例sql
CREATE TABLE sales_monthly(product VARCHAR(20), ym VARCHAR(10), amount NUMERIC(10, 2));
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201801',10159.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201802',10211.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201803',10247.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201804',10376.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201805',10400.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201806',10565.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201807',10613.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201808',10696.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201809',10751.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201810',10842.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201811',10900.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201812',10972.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201901',11155.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201902',11202.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201903',11260.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201904',11341.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201905',11459.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201906',11560.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201801',10138.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201802',10194.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201803',10328.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201804',10322.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201805',10481.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201806',10502.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201807',10589.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201808',10681.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201809',10798.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201810',10829.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201811',10913.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201812',11056.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201901',11161.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201902',11173.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201903',11288.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201904',11408.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201905',11469.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201906',11528.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201801',10154.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201802',10183.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201803',10245.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201804',10325.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201805',10465.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201806',10505.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201807',10578.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201808',10680.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201809',10788.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201810',10838.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201811',10942.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201812',10988.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201901',11099.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201902',11181.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201903',11302.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201904',11327.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201905',11423.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201906',11524.00);
select * from sales_monthly
select * from sales_monthly
-- 按照不同的产品同步 从开始 累计到现在的累计销量
select product,ym,amount,
sum(amount) over(partition by product order by ym
rows between unbounded preceding and current row)
from sales_monthly;
select product,ym,amount,
sum(amount) over(partition by product order by ym
rows between unbounded preceding and current row)
from sales_monthly;
-- 窗口大小常用选项
{ ROWS | RANGE } frame_start
{ ROWS | RANGE } BETWEEN frame_start AND frame_end
-
UNBOUNDED PRECEDING,窗口从分区的第一行开始,默认值;
-
N PRECEDING,窗口从当前行之前的第 N 行或者数值开始;
-
CURRENT ROW,窗口从当前行开始。
frame_end 用于定义窗口的结束位置,可以指定以下内容之一:
-
CURRENT ROW,窗口到当前行结束,默认值;
-
N FOLLOWING,窗口到当前行之后的第 N 行或者数值结束;
-
UNBOUNDED FOLLOWING,窗口到分区的最后一行结束。
SELECT *,
avg(amount) over(partition by product order by ym),
sum(amount) over(partition by product order by ym),
count(*) over(partition by product order by ym),
min(amount) over(partition by product order by ym)
from sales_monthly
-- 移动窗口
-- 计算三行平均值 向上一行和向下一行
SELECT *,
avg(amount) over(partition by product order by ym rows between 1 preceding and 1 following),
sum(amount) over(partition by product order by ym),
count(*) over(partition by product order by ym),
min(amount) over(partition by product order by ym)
from sales_monthly
例: 移动平均值通常用于处理时间序列的数据。例如,厂房的温度检测器获取了每秒钟的温度, 我们可以使用以下窗口计算前五分钟内的平均温度:
avg(temperature) OVER (ORDER BY ts RANGE BETWEEN interval '5 minute' PRECEDING AND CURRENT ROW)
聚合函数#
常用的聚合函数后可以加窗口函数over ,完成统计
SELECT *,
avg(amount) over(partition by product order by ym ),
sum(amount) over(partition by product order by ym),
count(*) over(partition by product order by ym),
min(amount) over(partition by product order by ym)
from sales_monthly
排名函数#
(不支持移动窗口)
- ROW_NUMBER,为分区中的每行数据分配一个序列号,序列号从 1 开始分配。
- RANK,计算每行数据在其分区中的名次;如果存在名次相同的数据,后续的排名将会 产生跳跃。
- DENSE_RANK,计算每行数据在其分区中的名次;即使存在名次相同的数据,后续的 排名也是连续的值。
- PERCENT_RANK,以百分比的形式显示每行数据在其分区中的名次;如果存在名次相 同的数据,后续的排名将会产生跳跃。
-- 统计部门内的薪资的排名
select employee_id,first_name,department_id,salary,
row_number() over (partition by department_id order by salary) ,-- 行号
rank () over (partition by department_id order by salary), -- 排名
dense_rank () over (partition by department_id order by salary), -- 紧凑排名
percent_rank () over (partition by department_id order by salary) --百分比排名
FROM employees;
同比环比#
- FIRST_VALUE,返回窗口内第一行的数据。
- LAST_VALUE,返回窗口内最后一行的数据。
- NTH_VALUE,返回窗口内第 N 行的数据。
- LAG,返回分区中当前行之前的第 N 行的数据。
- LEAD,返回分区中当前行之后第 N 行的数据。
-- 部门内收入最高的员工
SELECT department_id, first_name, last_name, salary,
FIRST_VALUE(salary) OVER (PARTITION BY department_id ORDER BY salary desc),
LAST_VALUE(salary) OVER (PARTITION BY department_id ORDER BY salary desc),
NTH_VALUE(salary, 3) OVER (PARTITION BY department_id ORDER BY salary desc)
FROM employees
-- LAG,返回分区中当前行之前的第 N 行的数据。
-- LEAD,返回分区中当前行之后第 N 行的数据。
select *,
lag(amount,1) over (partition by product order by ym),
lead(amount,1) over (partition by product order by ym)
from sales_monthly
-- 环比增长率
select *,
100*(amount-lag(amount,1) over (partition by product order by ym))/lag(amount,1) over (partition by product order by ym)
from sales_monthly
-- 同比增长率
select *,
100*(amount-lag(amount,12) over (partition by product order by ym))/lag(amount,12) over (partition by product order by ym)
from sales_monthly
#
PG数据库与索引优化#
# 创建索引
CREATE INDEX idx_commodity //索引名
ON commodity //表名
**USING** **btree** //用B树实现
(commodity_id); //作用的具体列
#删除索引
DROP INDEX idx_commodity;
#查询索引
select * from pg_indexes where tablename =‘commodity';
#重命名索引
ALTER INEDX idx_commodity rename to idx_commodity2;
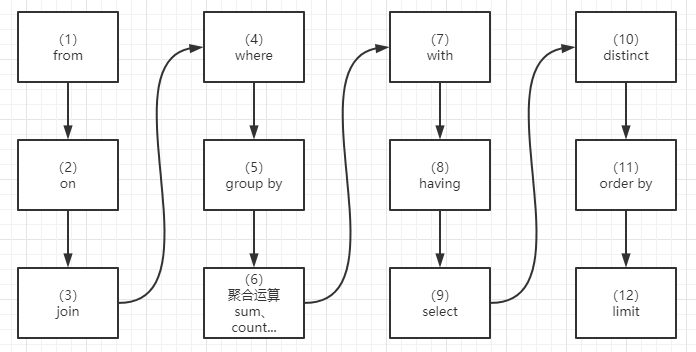
SQL语句执行顺序#
select 5 ..
from 1 ..
where 2 ..
group by 3 ..
having 4 ..
order by 6 ..
limit 7…
postgresql执行计划#

通过在SQL语句前面加 explain操作,就可以获取到该SQL的执行计划.该SQL并没有实际执行。输出的执行计划有如下特点:
1.查询规划:以规划为节点的树形结构。树的最底节点是扫描节点:他返回表中的原数据行。
2.不同的表有不同的扫描节点类型:顺序扫描.索引扫描和位图索引扫描。
3.也有非表列源,如ALUES子句并设置FROM返回.他们有白己的扫描类型。
4.如果查询需要关联,聚合,排序观其他操作,会在扫描节点之上增加节点执行这些操作。
5.explain的输出是每个树节点显示一行,内客是基本节点类型和执行节点的消耗评估。可能会出现同级别的节点,从汇总行节点缩进显示节点的其他属性,第一行(最上节点的汇总行)是评估执行计划的总消耗,这个值越小好。
explain (analyze true|false,verbose true|false,costs true|false,buffers true|false,format text|xml|json|yaml)
- analyze:真实执行sql获取执行计划,dml语句不想改变数据库数据可放入事务,执行完后回滚,该选项默认值为false。
- verbose:用于显示计划的附加信息,附加信息有计划树中每个节点输出的各个列,如果触发器被触发,还会输出触发器的名称,该选项默认值为false。
- costs:显示每个计划节点的启动成本和总成本,以及估计行数和每行宽度,该选项默认值为true。
- buffers:显示关于缓冲器使用的信息,只能与analyze参数一起使用,显示的缓冲区信息包括共享块、本地块、临时块的读写块数,表、索引、临时表、临时索引及排序和物化计划中使用的磁盘块,上层节点使用的块数包含所有节点使用的块数。该选项默认值为false。
- format:指定数据格式,可以是text、xml、json、yaml,默认值为text。
执行计划路径方式
全表扫描(顺序扫描):seq scan,所有数据块,从头扫到尾。
索引扫描:index scan,在索引中找到数据行的位置,然后到表的数据块中把对应的数据读出。
位图索引扫描:bitmap index scan,把满足条件的行或块在内存中建一个位图,扫描完索引后,再根据位图把表的数据文件中相应的数据读取出来。
条件过滤:filter
嵌套循环连接:nestloop join,外表(驱动表)小,内表(被驱动表)大
散列连接:hash join,用较小的表在内存中建立散列表,再去扫描较大的表,连接的表均为小表。
合并连接:merge join,通常散列连接比合并连接性能好,当有索引或结果已经被排序时,合并连接性能好。
表的统计信息
select
-- 当前表所占用的数据页数量
relpages,
-- 当前表一共有多少行组(记录)
reltuples
from pg_class
where relname = #tableName#
单列统计信息
-- 查询某个表的某一列的统计信息
select
-- Null值率
null_frac,
-- 去重后的值个数/其与总元组比值的负数
n_distinct,
-- 高频值个数,简称MCV,由default_statistics_target(默认100)决定记录多少个
most_common_vals,
-- 高频值占比(与MCV一一对应)
most_common_freqs,
-- 等频直方图,剔除MCV后,每个区间范围中的元素在总元组中的占比一样
histogram_bounds,
-- 物理行序与索引行序的相关性
correlation,
-- 平均行宽度,单位Byte
avg_width
from pg_stats
where tablename = #tableName#
and attname = #columnName#
示例
--估算
chis=> explain select * from patient;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on patient (cost=0.00..106205.66 rows=2406066 width=655)
(1 row)
--实际运行
chis=> explain analyze select * from patient;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------
Seq Scan on patient (cost=0.00..106205.66 rows=2406066 width=655) (actual time=0.016..13198.645 rows=2406066 loops=1)
Planning Time: 0.158 ms
Execution Time: 13293.205 ms
(3 rows)
--查询页面读取数和扫描行数
chis=> SELECT relpages, reltuples FROM pg_class WHERE relname = 'patient';
relpages | reltuples
----------+--------------
82145 | 2.406066e+06
--成本代价
cost = relpages(页面读取数)*seq_page_cost(1.0) + reltuples(扫描的行数)*cpu_tuple_cost(0.01) + reltuples(扫描的行数)*cpu_operator_cost(0.0025)
postgresql 索引
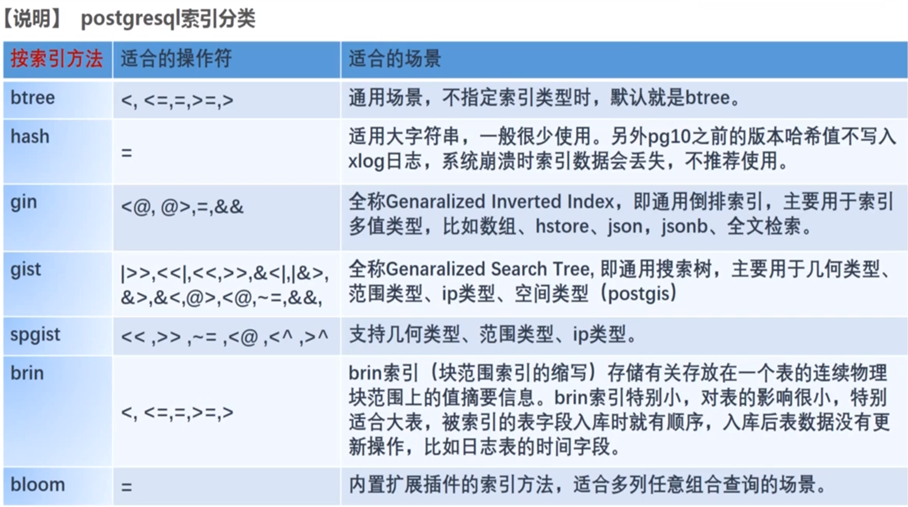
PostgreSQL提供了多种索引类型,主要的四种:B-Tree、Hash、GiST和GIN
每种索引使用了不同的算法,都有其适合的查询类型
缺省时,CREATE INDEX命令将创建B-Tree索引
1.b-tree 索引
是标准的索引类型,B代表平衡,主要用于等于和范围查询,
具体使用场景:
◆当索引列包含操作符"<、<=、=、>=和>"作为查询条件时
◆在使用BETWEEN、IN、IS NULL和IS NOT NULL的查询中
◆基于模式匹配操作符的查询,仅当模式存在一个常量,且该常量位于模式字符串的开头时 如col LIKE'foo%'索引才会生效,否则将会执行全表扫描,如:col LIKE'%bar
create index 索引名称 on 表名(字段名)
2.hash 索引
散列(Hash)索引只能处理简单的等于比较
当索引列使用等于操作符进行比较时,查询规划器会考虑使用散列索引
3.GIST
GiST(通用搜索树提供了一种用于存储数据的方式来构建平衡的树结构
二维几何操作:点位面计算

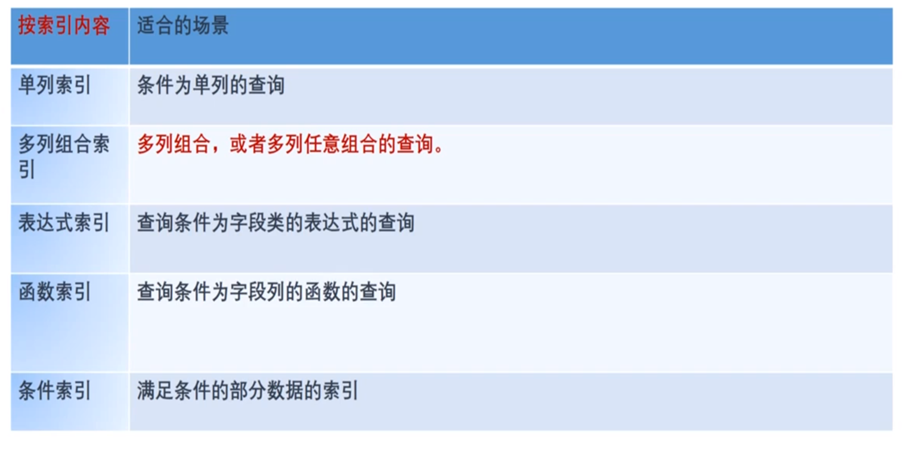
4.多列索引
PostgreSQL中的索引可以定义在数据表的多个字段上
CREATE TABLE test2(major int,minor int,name varchar)
CREATE INDEX test2_mm_idx ON test2(major,minor);
·在大多数情况下,单一字段上的索引就己经足够了,并且还节约时间和空间
5.唯一索引
只有B-Tree索引可以被声明为唯一索引
如果索引声明为唯一索引,就不允许出现多个索引值相同的行(NULL值相互间不相等)
6.表达式索引
主要用于在查询条件中存在基于某个字段的函数或表达式的结果与其他值进行比较时
CREATE INDEX test1_lower_.col1_idx ON test1(lower(col1)
-- 1. BTREE索引:
create table t1 (id int, info text);
insert into t1 values(generate_series(1,100000), md5(random()::text));
analyze t1;
--不建立索引 顺序扫描
explain select * from t1 where t1.id = 10007;
--建立索引
create index on t1(id);
explain select * from t1 where t1.id =10007;
explain select * from t1 where t1.id <200;
--模糊查询使用索引
explain select * from t1 where t1.info like '0123%';
--2. Hash索引(简单的等值比较 )当索引列涉及到等于操作比较时,优化器会考虑使用Hash索引。Hash索引是通过比较hash值来查找定位,如果hash索引列的数据重复度比较高,容易产生严重的hash冲突,从而降低查询效率,因此这种情况下,不适合hash索引。
create table t2 (id int, info text);
insert into t2 values(generate_series(1,100000), md5(random()::text));
create index on t2 using hash(id);
explain select * from t2 where id = 10008;
--非等于操作不会用到hash索引
explain select * from t2 where id < 10008;
--3. GiST索引 GiST可以用来做位置搜索,如包含、相交、左边、右边等。和Btree索引相比,GiST多字段索引在查询条件中包含索引字段的任何子集都会使用索引扫描,而Btree索引只有查询条件包含第一个索引字段才会使用索引扫描。GiST索引特定操作符类型高度依赖于索引策略(操作符类)。GiST跟Btree索引相比,索引创建耗时较长,占用空间也比较大。
create table t3(a bigint, b timestamp without time zone,c varchar(64));
insert into t3 values(generate_series(1,100000), now()::timestamp, md5(random()::text));
--建立了BTREE组合索引(a, b),如果SQL where条件中有a或者a,b都可以使用该组合索引,但是如果where条件中只有b,则无法使用索引。
create index on t3(a, b);
explain select * from t3 where b = '2022-11-18 17:50:29.245683';
explain select * from t3 where a = 10000;
--GiST可以解决这种情况。
create extension btree_gist;create index idx_t3_gist on t3 using gist(a,b);
analyze t3;
explain select * from t3 where a = '10000' or b = '2022-11-18 17:50:29.245683';
explain select * from t3 where a = '10000' and b = '2022-11-18 17:50:29.245683';
--4. SP-GiST索引与GIST类似
--5. GIN索引
create table t4(id int, info text);
insert into t4 values(generate_series(1,10000), md5(random()::text));
create index idx_t4_gin on t4 using gin(to_tsvector('english',info));
analyze t4;
explain select * from t4 where to_tsvector('english', info) @@ plainto_tsquery( 'hello');
--6. BRIN索引 比较BTREE索引 占用空间小,单查询性能不如BTREE索引,BRIN索引适用于存储流式数据日志。
create table t5(id int, name text);
insert into t5 values(generate_series(1,100000), md5(random()::text));
create index idx_t5_brin on t5 using brin(id);
analyze t5;
explain select * from t5 where id > 98765;
--7.唯一索引
create table t6(id int, name text);
create unique index idx_t6_id on t6 (id);
--8. 多列索引(复合索引) 最左匹配原则
create table t7(c1 int ,c2 int,c3 int);
create index idx_t7 on t7 using btree(c1,c2,c3);
insert into t7 select random()*100,random()*100,random()*100 from generate_series(1,1000000);
explain analyze select * from t7 where c1=10 and c2=40 and c3 =80;
explain analyze select * from t7 where c1=10 and c2=40;
explain analyze select * from t7 where c1=10 and c3 =80;
explain analyze select * from t7 where c2=40 and c3 =80;
explain analyze select * from t7 where c2 =80;
explain analyze select * from t7 where c3 =80;
--9.表达式索引
create table t8(c1 int ,c2 varchar,c3 int);
create index idx_t8_c1 on t8((c2*10));
--10. .函数索引
create index idx_t8_c1 on t8(max(c3));
索引优化#
1. 尽量避免在字段开头模糊查询,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE username LIKE '%陈%'
优化方式:尽量在字段后面使用模糊查询。如下:
SELECT * FROM t WHERE username LIKE '陈%'
2. 尽量避免使用in 和not in,会导致引擎走全表扫描。如下:
SELECT * FROM t WHERE id IN (2,3)
优化方式:如果是连续数值,可以用between代替。如下:
SELECT * FROM t WHERE id BETWEEN 2 AND 3
如果是子查询,可以用exists代替。如下:
-- 不走索引
select * from A where A.id in (select id from B);
-- 走索引
select * from A where exists (select * from B where B.id = A.id);
3. 尽量避免使用 or,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE id = 1 OR id = 3
优化方式:可以用union代替or。如下:
SELECT * FROM t WHERE id = 1
UNION
SELECT * FROM t WHERE id = 3
4. 尽量避免进行null值的判断,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE score IS NULL
优化方式:可以给字段添加默认值0,对0值进行判断。如下:
SELECT * FROM t WHERE score = 0
5.尽量避免在where条件中等号的左侧进行表达式、函数操作,会导致数据库引擎放弃索引进行全表扫描。
可以将表达式、函数操作移动到等号右侧。如下:
-- 全表扫描
SELECT * FROM T WHERE score/10 = 9
-- 走索引
SELECT * FROM T WHERE score = 10*9
6. 当数据量大时,避免使用where 1=1的条件。通常为了方便拼装查询条件,我们会默认使用该条件,数据库引擎会放弃索引进行全表扫描。如下:
SELECT username, age, sex FROM T WHERE 1=1
优化方式:用代码拼装sql时进行判断,没 where 条件就去掉 where,有where条件就加 and。
7. 查询条件不能用 <> 或者 !=
使用索引列作为条件进行查询时,需要避免使用<>或者!=等判断条件。如确实业务需要,使用到不等于符号,需要在重新评估索引建立,避免在此字段上建立索引,改由查询条件中其他索引字段代替。
8. where条件仅包含复合索引非前置列
如下:复合(联合)索引包含key_part1,key_part2,key_part3三列,但SQL语句没有包含索引前置列"key_part1",按照MySQL联合索引的最左匹配原则,不会走联合索引。
select col1 from table where key_part2=1 and key_part3=2
9. 隐式类型转换造成不使用索引
如下SQL语句由于索引对列类型为varchar,但给定的值为数值,涉及隐式类型转换,造成不能正确走索引。
select col1 from table where col_varchar=123;
10. order by 条件要与where中条件一致,否则order by不会利用索引进行排序
-- 不走age索引
SELECT * FROM t order by age;
-- 走age索引
SELECT * FROM t where age > 0 order by age;
对于上面的语句,数据库的处理顺序是:
· 第一步:根据where条件和统计信息生成执行计划,得到数据。
· 第二步:将得到的数据排序。当执行处理数据(order by)时,数据库会先查看第一步的执行计划,看order by 的字段是否在执行计划中利用了索引。如果是,则可以利用索引顺序而直接取得已经排好序的数据。如果不是,则重新进行排序操作。
· 第三步:返回排序后的数据。
当order by 中的字段出现在where条件中时,才会利用索引而不再二次排序,更准确的说,order by 中的字段在执行计划中利用了索引时,不用排序操作。
这个结论不仅对order by有效,对其他需要排序的操作也有效。比如group by 、union 、distinct等。
11. 只需要一条数据的时候,使用limit 1
SELECT * FROM students FORCE INDEX (idx_class_id) WHERE class_id = 1 ORDER BY id DESC;
SELECT语句优化#
1. 避免出现select *
首先,select * 操作在任何类型数据库中都不是一个好的SQL编写习惯。
使用select * 取出全部列,会让优化器无法完成索引覆盖扫描这类优化,会影响优化器对执行计划的选择,也会增加网络带宽消耗,更会带来额外的I/O,内存和CPU消耗。
建议提出业务实际需要的列数,将指定列名以取代select *。
2. 避免出现不确定结果的函数
特定针对主从复制这类业务场景。由于原理上从库复制的是主库执行的语句,使用如now()、rand()、sysdate()、current_user()等不确定结果的函数很容易导致主库与从库相应的数据不一致。另外不确定值的函数,产生的SQL语句无法利用query cache。
3.多表关联查询时,小表在前,大表在后。
执行 from 后的表关联查询是从左往右执行的(Oracle相反),第一张表会涉及到全表扫描,所以将小表放在前面,先扫小表,扫描快效率较高,在扫描后面的大表,或许只扫描大表的前100行就符合返回条件并return了。
例如:表1有50条数据,表2有30亿条数据;如果全表扫描表2,你品,那就先去吃个饭再说吧是吧。
4. 使用表的别名
当在SQL语句中连接多个表时,请使用表的别名并把别名前缀于每个列名上。这样就可以减少解析的时间并减少哪些友列名歧义引起的语法错误。
5. 用where字句替换HAVING字句
避免使用HAVING字句,因为HAVING只会在检索出所有记录之后才对结果集进行过滤,而where则是在聚合前刷选记录,如果能通过where字句限制记录的数目,那就能减少这方面的开销。HAVING中的条件一般用于聚合函数的过滤,除此之外,应该将条件写在where字句中。
where和having的区别:where后面不能使用组函数
6.调整Where字句中的连接顺序
SQL执行采用从左往右,自上而下的顺序解析where子句。根据这个原理,应将过滤数据多的条件往前放,最快速度缩小结果集。
7.当只需要一条数据的时候,使用limit 1
查询条件优化#
1. 对于复杂的查询,可以使用中间临时表 暂存数据
2. 优化join语句
MySQL中可以通过子查询来使用 SELECT 语句来创建一个单列的查询结果,然后把这个结果作为过滤条件用在另一个查询中。使用子查询可以一次性的完成很多逻辑上需要多个步骤才能完成的 SQL 操作,同时也可以避免事务或者表锁死,并且写起来也很容易。但是,有些情况下,子查询可以被更有效率的连接(JOIN)..替代。
例子:假设要将所有没有订单记录的用户取出来,可以用下面这个查询完成:
SELECT col1 FROM customerinfo WHERE CustomerID NOT in (SELECT CustomerID FROM salesinfo )
如果使用连接(JOIN).. 来完成这个查询工作,速度将会有所提升。尤其是当 salesinfo表中对 CustomerID 建有索引的话,性能将会更好,查询如下:
SELECT col1 FROM customerinfo
LEFT JOIN salesinfoON customerinfo.CustomerID=salesinfo.CustomerID
WHERE salesinfo.CustomerID IS NULL
连接(JOIN).. 之所以更有效率一些,是因为 MySQL 不需要在内存中创建临时表来完成这个逻辑上的需要两个步骤的查询工作。
3. 优化union查询
MySQL通过创建并填充临时表的方式来执行union查询。除非确实要消除重复的行,否则建议使用union all。原因在于如果没有all这个关键词,MySQL会给临时表加上distinct选项,这会导致对整个临时表的数据做唯一性校验,这样做的消耗相当高。
高效:
SELECT COL1, COL2, COL3 FROM TABLE WHERE COL1 = 10
UNION ALL
SELECT COL1, COL2, COL3 FROM TABLE WHERE COL3= 'TEST';
低效:
SELECT COL1, COL2, COL3 FROM TABLE WHERE COL1 = 10
UNION
SELECT COL1, COL2, COL3 FROM TABLE WHERE COL3= 'TEST';
4.拆分复杂SQL为多个小SQL,避免大事务
· 简单的SQL容易使用到MySQL的QUERY CACHE;
· 减少锁表时间特别是使用MyISAM存储引擎的表;
· 可以使用多核CPU。
5. 使用truncate代替delete
当删除全表中记录时,使用delete语句的操作会被记录到undo块中,删除记录也记录binlog,当确认需要删除全表时,会产生很大量的binlog并占用大量的undo数据块,此时既没有很好的效率也占用了大量的资源。
使用truncate替代,不会记录可恢复的信息,数据不能被恢复。也因此使用truncate操作有其极少的资源占用与极快的时间。另外,使用truncate可以回收表的水位,使自增字段值归零。
6. 使用合理的分页方式以提高分页效率
使用合理的分页方式以提高分页效率 针对展现等分页需求,合适的分页方式能够提高分页的效率。
案例1:
select * from t where thread_id = 10000 and deleted = 0
order by gmt_create asc limit 0, 15;
上述例子通过一次性根据过滤条件取出所有字段进行排序返回。数据访问开销=索引IO+索引全部记录结果对应的表数据IO。因此,该种写法越翻到后面执行效率越差,时间越长,尤其表数据量很大的时候。
适用场景:当中间结果集很小(10000行以下)或者查询条件复杂(指涉及多个不同查询字段或者多表连接)时适用。
案例2:
select t.* from (select id from t where thread_id = 10000 and deleted = 0
order by gmt_create asc limit 0, 15) a, t
where a.id = t.id;
上述例子必须满足t表主键是id列,且有覆盖索引secondary key:(thread_id, deleted, gmt_create)。通过先根据过滤条件利用覆盖索引取出主键id进行排序,再进行join操作取出其他字段。数据访问开销=索引IO+索引分页后结果(例子中是15行)对应的表数据IO。因此,该写法每次翻页消耗的资源和时间都基本相同,就像翻第一页一样。
适用场景:当查询和排序字段(即where子句和order by子句涉及的字段)有对应覆盖索引时,且中间结果集很大的情况时适用。
建表优化#
1. 在表中建立索引,优先考虑where、order by使用到的字段。
2. 尽量使用数字型字段(如性别,男:1 女:2),若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
这是因为引擎在处理查询和连接时会 逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
3. 查询数据量大的表 会造成查询缓慢。主要的原因是扫描行数过多。这个时候可以通过程序,分段分页进行查询,循环遍历,将结果合并处理进行展示。要查询100000到100050的数据,如下:
SELECT * FROM (SELECT ROW_NUMBER() OVER(ORDER BY ID ASC) AS rowid,*
FROM infoTab)t WHERE t.rowid > 100000 AND t.rowid <= 100050
4. 用varchar/nvarchar 代替 char/nchar
尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
不要以为 NULL 不需要空间,比如:char(100) 型,在字段建立时,空间就固定了, 不管是否插入值(NULL也包含在内),都是占用 100个字符的空间的,如果是varchar这样的变长字段, null 不占用空间。
常用技巧#
generate_series#
一、简介
PostgreSQL中有一个很有用的内置函数generate_series,可以按不同的规则产生一系列的填充数据。
二、语法
| 函数 | 参数类型 | 返回类型 | 描述 |
|---|---|---|---|
| generate_series(start, stop) | int 或 bigint | setof int 或 setof bigint(与参数类型相同) | 生成一个数值序列,从start 到 stop,步进为一 |
| generate_series(start, stop, step) | int 或 bigint | setof int 或 setof bigint(与参数类型相同) | 生成一个数值序列,从start 到 stop,步进为step |
| generate_series(start, stop, step_interval) | timestamp or timestamp with time zone | timestamp 或 timestamp with time zone(same as argument type) | 生成一个数值序列,从start 到 stop,步进为step |
select to_char(b, 'YYYYMM') as t_date_complete
from generate_series(
to_timestamp(to_char(now()::timestamp + '-1 year', 'YYYYMM'), 'YYYYMM'),
to_timestamp('202212', 'YYYYMM'), '1 month') as b
select *,
lag(t1.amount,1) over (partition by t1.product order by t1.ym),
lead(t1.amount,1) over (partition by t1.product order by t1.ym)
from sales_monthly t1
left join
(select to_char(b, 'YYYYMM') as t_date_complete
from generate_series(
to_timestamp(to_char(now()::timestamp + '-5 year', 'YYYYMM'), 'YYYYMM'),
to_timestamp('202212', 'YYYYMM'), '1 month') as b) t2 on t1.ym =t2. t_date_complete
查询统计数据,补全没有数据的日期和值#
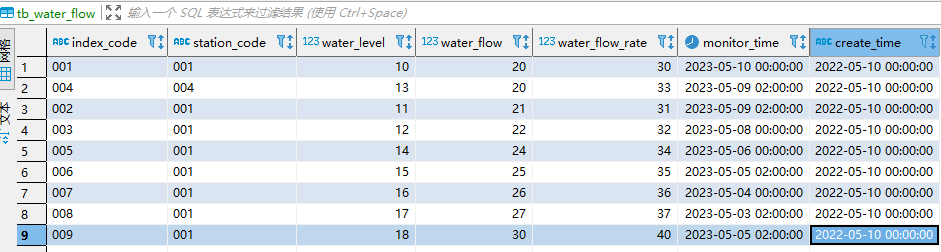
-- public.tb_water_flow definition
-- Drop table
-- DROP TABLE tb_water_flow;
CREATE TABLE tb_water_flow (
index_code varchar NULL,
station_code varchar NULL, -- 河道站点编码
water_level float8 NULL, -- 水位(单位:米)
water_flow float8 NULL, -- 水流量(单位:立方米每秒)
water_flow_rate float8 NULL, -- 水流速(单位:米每秒)
monitor_time timestamp NULL, -- 监测时间
create_time varchar NULL -- 创建时间
);
-- Column comments
COMMENT ON COLUMN public.tb_water_flow.station_code IS '河道站点编码';
COMMENT ON COLUMN public.tb_water_flow.water_level IS '水位(单位:米)';
COMMENT ON COLUMN public.tb_water_flow.water_flow IS '水流量(单位:立方米每秒)';
COMMENT ON COLUMN public.tb_water_flow.water_flow_rate IS '水流速(单位:米每秒)';
COMMENT ON COLUMN public.tb_water_flow.monitor_time IS '监测时间';
COMMENT ON COLUMN public.tb_water_flow.create_time IS '创建时间';
查询sql语句
with t1 as (
select to_char(b, 'yyyy-MM-dd') as t_date_complete
from generate_series(
to_timestamp(to_char(current_date - interval '6 day','yyyy-MM-dd'), 'yyyy-MM-dd'),
to_timestamp(to_char(current_date,'yyyy-MM-dd'), 'yyyy-MM-dd'), '1 day') as b
),t2 as (
SELECT station_code,
to_char(monitor_time,'yyyy-MM-dd') as monitor_time,
avg( water_flow) as water_flow_avg,
avg( water_flow_rate) as water_flow_rate_avg
FROM public.tb_water_flow
where to_char(monitor_time,'yyyy-MM-dd') between to_char(current_date - interval'6 day','yyyy-MM-dd') and to_char(current_date,'yyyy-MM-dd')
and station_code = '001'
group by station_code,to_char(monitor_time,'yyyy-MM-dd')
)
select
t1.t_date_complete,
coalesce( water_flow_avg, -1) as water_flow_avg,
coalesce( water_flow_rate_avg, -1) as water_flow_rate_avg
from t1 full join t2 on t1.t_date_complete=t2.monitor_time
order by t1.t_date_complete;
PG生成uuid#
create extension "uuid-ossp" ;
select replace(cast(uuid_generate_v4() as VARCHAR), '-', '');
PG 根据字段中字符,将数据拆封为多行#
unnest(string_to_array(字段名,指定字符))
select unnest(string_to_array('1-3,5-6',','))
PG 创建自增序列#
create sequence if not EXISTS seq_name
increment by 1 --步长
minvalue 1 --最小值
no maxvalue --最大值
start 1
select nextval( seq_name::regclass)
Postgresql 实现数据不存在插入,存在更新#
-- 语法形式
INSERT INTO 表名 VALUES ('值1', '值2', ...)
ON CONFLICT(唯一或排除约束字段名)
DO UPDATE SET 列1='值', 列2='值', ...;
举例
CREATE TABLE test_update_insert (
id varchar NOT NULL,
"name" varchar NULL,
age varchar NULL,
CONSTRAINT test_update_insert_pk PRIMARY KEY (id)
);
insert into test_update_insert VALUES ('1','zhangsan','age')
ON CONFLICT (id)
DO UPDATE set id='1',"name"='zhangsan2', age='18'
使用postgresql开放局域网访问的方法#
-
修改pg_hba.conf的配置文件
找到postgresql当时的安装目录PostgreSQL/14/data/pg_hba.conf文件,用记事本或者notepad++等软件打开pg_hba.conf,在大约86行那里有:
’ # IPv4 local connections:
host all all 127.0.0.1/32 scram-sha-256’
在这个下一行添加一个新行:
host all all 0.0.0.0/0 scram-sha-256
然后,保存,重启postgresql服务2.修改防火墙的配置 -
右键此电脑,属性,隐私和安全,windows安全中心,防火墙和网络保护,高级设置,入站规则,新建规则,在跳出的向导中点击端口,下一步,特定本地端口填写5432,之后一直下一步,最后命名点击完成即可;
-
获取数据库电脑的ip地址
win+r然后cmd 输入ipconfig获取本机的ip地址 -
外网访问
在另外一台电脑上,ip地址输入3中获取的,端口5432,用户名和密码用安装设置的,即可访问1中的postgresql数据库。
用row_number()实现数据去重#
select * from (
select a.*,row_number() over(partition by 分组字段 order by 排序字段) rn from 表名 a
) b where b.rn = 1
PostgreSQL中的递归#
PostgreSQL中的递归常用于解决树形结构的模型,常用的需求有:查询根节点、层级、路径、是否叶子节点、是否死循环等,下面通过实例讲解如何解决这些问题。
- 实例数据准备
test=> CREATE TABLE sys_cbp_test (id INT,parent_id INT);
CREATE TABLE
test=> INSERT INTO sys_cbp_test
test-> VALUES
test-> (1, NULL),
test-> (2, 1),
test-> (3, 2),
test-> (4, 3),
test-> (5, 1),
test-> (6, 5),
test-> (7, 2),
test-> (8, 6),
test-> (5, 8), --此次存在死循环
test-> (20, NULL),
test-> (21, 20),
test-> (22, 21);
INSERT 0 12
test=> SELECT * FROM sys_cbp_test;
id | parent_id
----+-----------
1 |
2 | 1
3 | 2
4 | 3
5 | 1
6 | 5
7 | 2
8 | 6
5 | 8
20 |
21 | 20
22 | 21
(12 rows)
- 查询节点层级、起始节点、节点路径、是否存在死循环、是否叶子节点等
test=> WITH RECURSIVE x(id, --节点ID
test(> parent_id, --父节点ID
test(> level, --节点层级
test(> path, --节点路径
test(> root, --起始节点
test(> cycle --节点是否循环
test(> ) AS
test-> (--起始节点查询语句
test(> SELECT id,
test(> parent_id,
test(> 1,
test(> ARRAY[id],
test(> id AS root,
test(> FALSE
test(> FROM sys_cbp_test
test(> WHERE parent_id IS NULL --查询的起始节点
test(> UNION ALL
test(> --递归循环语句
test(> SELECT b.id,
test(> b.parent_id,
test(> level + 1, --递归一层节点层级加1
test(> x.path || b.id, --把节点按照递归的次序依次存入数组
test(> x.root, --记录起始节点
test(> b.id = ANY(path) --判断当前节点是否已存在路径数组中,如果存在说明存在循环
test(> FROM x,
test(> sys_cbp_test b
test(> WHERE x.id = b.parent_id --从起始节点往下递归
test(> AND NOT cycle --终止循环节点
test(> )
test-> SELECT id,
test-> x.parent_id,
test-> level,
test-> array_to_string(path, '->') AS path,
test-> root,
test-> path,
test-> cycle,
test-> CASE
test-> WHEN t.parent_id IS NULL THEN
test-> TRUE
test-> ELSE
test-> FALSE
test-> END AS isleaf --是否叶子节点
test-> FROM x
test-> LEFT JOIN (SELECT parent_id
test(> FROM sys_cbp_test
test(> GROUP BY parent_id) t
test-> ON x.id = t.parent_id
test->--WHERE NOT cycle --去掉循环重复的节点,反过来也可以查找哪个节点存在死循环
test-> ORDER BY id;
id | parent_id | level | path | root | path | cycle | isleaf
----+-----------+-------+---------------+------+-------------+-------+--------
1 | | 1 | 1 | 1 | {1} | f | f
2 | 1 | 2 | 1->2 | 1 | {1,2} | f | f
3 | 2 | 3 | 1->2->3 | 1 | {1,2,3} | f | f
4 | 3 | 4 | 1->2->3->4 | 1 | {1,2,3,4} | f | t
5 | 8 | 5 | 1->5->6->8->5 | 1 | {1,5,6,8,5} | t | f --此行一般需要过滤掉(NOT cycle)
5 | 1 | 2 | 1->5 | 1 | {1,5} | f | f
6 | 5 | 3 | 1->5->6 | 1 | {1,5,6} | f | f
7 | 2 | 3 | 1->2->7 | 1 | {1,2,7} | f | t
8 | 6 | 4 | 1->5->6->8 | 1 | {1,5,6,8} | f | f
20 | | 1 | 20 | 20 | {20} | f | f
21 | 20 | 2 | 20->21 | 20 | {20,21} | f | f
22 | 21 | 3 | 20->21->22 | 20 | {20,21,22} | f | t
(12 rows)
查询正在执行的所有sql#
SELECT
pid,
datname,
usename,
client_addr,
application_name,
STATE,
backend_start,
xact_start,
xact_stay,
query_start,
query_stay,
REPLACE ( query, chr( 10 ), ' ' ) AS query
FROM
(
SELECT
pgsa.pid AS pid,
pgsa.datname AS datname,
pgsa.usename AS usename,
pgsa.client_addr client_addr,
pgsa.application_name AS application_name,
pgsa.STATE AS STATE,
pgsa.backend_start AS backend_start,
pgsa.xact_start AS xact_start,
EXTRACT ( epoch FROM ( now( ) - pgsa.xact_start ) ) AS xact_stay,
pgsa.query_start AS query_start,
EXTRACT ( epoch FROM ( now( ) - pgsa.query_start ) ) AS query_stay,
pgsa.query AS query
FROM
pg_stat_activity AS pgsa
WHERE
pgsa.STATE != 'idle'
AND pgsa.STATE != 'idle in transaction'
AND pgsa.STATE != 'idle in transaction (aborted)'
) idleconnections
ORDER BY
query_stay DESC
如果要释放掉慢查询资源
SELECT pg_terminate_backend(PID);
MySql/Oracle和SQL Server的分页查询#
假设当前是第PageNo页,每页有PageSize条记录,现在分别用Mysql、Oracle和SQL Server分页查询student表。
1、Mysql的分页查询:#
1 SELECT
2 *
3 FROM
4 student
5 LIMIT (PageNo - 1) * PageSize,PageSize;
理解:(Limit n,m) =>从第n行开始取m条记录,n从0开始算。
2、Oracel的分页查询:#
1 SELECT
2 *
3 FROM
4 (
5 SELECT
6 S.*, ROWNUM rn
7 FROM
8 (SELECT * FROM Student) S
9 WHERE
10 Rownum <= pageNo * pageSize
11 )
12 WHERE
13 rn > (pageNo - 1) * pageSize或者
1 SELECT
2 *
3 FROM
4 (
5 SELECT
6 S.*, ROWNUM rn
7 FROM
8 (SELECT * FROM Student) S
11 )
12 WHERE
13 rn BETWEEN (pageNo - 1) * pageSize AND pageNo * pageSize
理解:假设pageNo = 1,pageSize = 10,先从student表取出行号小于等于10的记录,然后再从这些记录取出rn大于0的记录,从而达到分页目的。ROWNUM从1开始。
分析:对比这两种写法,绝大多数的情况下,第一个查询的效率比第二个高得多。
这是由于CBO 优化模式下,Oracle可以将外层的查询条件推到内层查询中,以提高内层查询的执行效率。对于第一个查询语句,第二层的查询条件WHERE ROWNUM <=
pageNo * pageSize就可以被Oracle推入到内层查询中,这样Oracle查询的结果一旦超过了ROWNUM限制条件,就终止查询将结果返回了。
而第二个查询语句,由于查询条件BETWEEN (pageNo - 1) * pageSize AND pageNo * pageSize是存在于查询的第三层,而Oracle无法将第三层的查询条件推到最内层(即使推到最内层也没有意义,因为最内层查询不知道RN代表什么)。因此,对于第二个查询语句,Oracle最内层返回给中间层的是所有满足条件的数据,而中间层返回给最外层的也是所有数据。数据的过滤在最外层完成,显然这个效率要比第一个查询低得多。
3、SQL Server分页查询:#
1 SELECT
2 TOP PageSize *
3 FROM
4 (
5 SELECT
6 ROW_NUMBER () OVER (ORDER BY id ASC) RowNumber ,*
7 FROM
8 student
9 ) A
10 WHERE
11 A.RowNumber > (PageNo - 1) * PageSize
理解:假设pageNo = 1,pageSize = 10,先按照student表的id升序排序,rownumber作为行号,然后再取出从第1行开始的10条记录。
sql server 字符编码#
先说下结论:
- 如果你想在数据库中存储emoji表情等特殊字符,就需要将varchar改为nvarchar并且在编写sql语句时使用大N(N'小明...')。
- 默认的sqlserver中字符串的排序比较已忽略掉了全角/半角、大/小写的差别,所以不用担心因为大小写和全半角搜索不到数据的问题。
一、说说字符集、字符集编码和排序规则
字符集:罗列所有图形字符的一张大表。
比如:
GBK字符集(中国制造): 罗列了所有的中文简体、繁体字的一张大表。
Unicode字符集(全世界通用):罗列了世界上所有图形字符的一张大表。
字符集编码:将字符集上罗列的图形字符存储到计算机中的一种编码规则。
比如:
GBK字符编码(中国制造):GBK本身既是字符集,也是编码规则;
UTF-16:存储Unicode字符集的一种编码规则,使用2个(中文)、4个(emoji表情)字节存储。
UTF-8:也是存储Unicode字符集的一种编码规则,使用1个、2个、3个、4个字节存储。
排序规则:定义各个图形字符之间的大小比较规则,比如:是否区分大小写,区分全角和半角等。
在软件使用中,一般我们只指定字符编码即可,因为确定了字符编码字符集自然就确定了。
但是在数据库类软件中,我们除了要指定编码规则,还需要指定排序规则,因为,数据库是要提供模糊匹配、排序显示功能的。
二、sqlserver中字符集编码和排序规则
上面虽然把字符集、字符集编码、排序规则的概念分的很清,但sqlserver中的配置并没有分的太清。
在sqlserver中没有单独设置字符集编码的地方,仅能设置排序规则。
至于最终使用什么字符集编码,则会受排序规则、数据类型(varchar、nvarchar)的影响。
一般我们在window或window server上安装sqlserver 2014,安装后默认排序规则是:Chinese_PRC_CI_AS。
Chinese_PRC:针对大陆简体字UNICODE的排序规则。
CI:CaseSensitivity,指定不区分大小写。
AS:AccentSensitivity,指定区分重音。
sqlserver设置排序规则有四个级别:服务器(示例级别)、数据库、 列级别、表达式级别:
SELECT name FROM customer ORDER BY name COLLATE Latin1_General_CS_AI;
注意:
Chinese_PRC_CI_AS不是存储为UTF8,事实上,直到SqlServer2019才引入UTF-8的支持(Chinese_PRC_CI_AS_UTF8)。
参照:
《Introducing UTF-8 support for SQL Server》
《排序规则和 Unicode 支持》
附:查询排序规则元数据
-- 查询数据库的排序规则
select serverproperty(N'Collation');
--查询所有受支持的排序规则
select * from fn_helpcollations()
-- 查询列的排序规则
select name,collation_name from sys.columns where collation_name is not null
三、排序规则对sql语句的一影响
观察排序规则对sql语句影响的时候,我主要从以下两个方面考虑:
全角/半角
大写/小写
至于其他的重音、假名则是很难用到,直接用默认的即可。
分析其他数据库的排序规则时,也可以从这两个方面考虑,经过综合对比,sqlserver中的排序规则还是很贴近实际情况的,其他的数据库或多或少都有问题。
全角/半角对查询的影响:
我们期望的效果:当使用like查询或=比较符时,数据库能忽略掉全角“a”和 半角"a",将它们判定相等。
sqlserver不负众望,默认情况下的比较是忽略全角/半角的,所以,sqlserver能做到判定它们相等。
看如下实验:
create table test(
id int identity(1,1),
name varchar(50)
);
insert into test values
('角a啊'),--全角a
('角a啊');--半角a
--测试like中的全角半角处理
select * from test where name like '%a%';--半角a
select * from test where name like '%a%';--全角a
--测试=中的全角半角处理
select * from test where name = '角a啊';--半角a
select * from test where name = '角a啊';--全角a
上面的查询结果均显示:
大小写对查询的影响:
我们期望的效果:当使用like查询或=比较符时,数据库能忽略掉大写和小写的区别,将它们判定相等。
sqlserver不负众望,默认情况下的比较是忽略大小写的,所以,sqlserver能做到判定它们相等。
看如下实验:
create table test(
id int identity(1,1),
name varchar(50)
)
insert into test values
('A'),('a');
select * from test where name like 'A';
select * from test where name like 'a';
select * from test where name = 'A';
select * from test where name = 'a';
上面的查询结果均显示:
四、sqlserver究竟会以何种编码存储字符
上面只说了sqlserver中的默认排序规则:Chinese_PRC_CI_AS,但是sqlserver中究竟是以哪种编码规则存储的呢?
具体用什么编码规则存储不仅受排序规则的影响,还受数据类型的影响(nvarchar、varchar)。
以Chinese_PRC_CI_AS排序规则为例:
当我们使用varchar类型时,存储到表里面的数据其实就是GBK编码,因为:Chinese_PRC对应的是区域编码(ANSI,活动代码页:936)是GBK。可以通过sql查询得知:
SELECT COLLATIONPROPERTY('Chinese_PRC_CI_AS', 'CodePage')
当我们使用nvarchar类型时,存储到表里面的是UTF-16的编码。
验证不同数据类型对应的编码规则:
首先,我们数据库的排序规则是:Chinese_PRC_CI_AS,已知 汉字“王”的各种格式编码如下:
参考:《细说ASCII、GB2312/GBK/GB18030、Unicode、UTF-8/UTF-16/UTF-32编码》
准备数据:
create table test(
name varchar(50),
nname nvarchar(50)
)
insert into test values('王','王')
select
name,nname,
convert (varbinary (20) , name) as name_binary,
convert (varbinary (20) , nname) as nname_binary
from test
由此,可以看出,数据表中存储使用的字符编码和排序规则和数据类型都有关系。
具体可以参考:《nchar 和 nvarchar (Transact-SQL)》
五、sqlserver中数据类型varchar和nvarchar的区别、N’'的作用
其实从上面的实验中可以看得出来,对于Chinese_PRC_CI_AS排序规则来说:
varchar类型的列使用ANSI编码,也即GBK存储数据(不能存储emoji表情);
而nvarchar类型的列使用UTF-16编码存储数据(能存储所有Unicode字符,包含emoji表情)。
我们知道,UTF-16编码规则最少使用2个字节存储字符,即使对于英文字母“W”也要使用两个字节,而GBK编码则可以使用1个字节存储英文字母“W”,所有当只有英文字母时,varchar显然要节省空间。
下面是存储英文字母“W”的示例:
create table test(
name varchar(50),
nname nvarchar(50)
)
insert into test values('W','W')
select
name,nname,
convert (varbinary (20) , name) as name_binary,
convert (varbinary (20) , nname) as nname_binary
from test
nvarchar(8000)和varchar(8000) 中的8000指的是字节数,而不是字符数,GBK中一个字符可以是1个字节或两个字节,UTF-16中一个字符则是2个或4个字节,所以在计算最多存储多少文字时不要搞错了。
N’小明’ 的作用:
这个大N表示单引号中的字符串使用的是Unicode编码,当我们sqlserver引擎会用Unicode的方式去解析"小明",而不是用GBK编码的方式。
一般来说,我们感觉不到加不加大N的区别,那是因为我们存储的数据都在Unicode的常见字符区域内,如果我们存储一个emoji表情,那么加不加大N的就立马看得出来了,看如下的实验:
create table test(
name varchar(50),
nname nvarchar(50)
)
insert into test values('王','王')
insert into test values(N'王',N'王')
insert into test values('W','W')
insert into test values(N'W',N'W')
insert into test values('😀','😀')
insert into test values(N'😀',N'😀')
select
name,nname,
convert (varbinary (20) , name) as name_binary,
convert (varbinary (20) , nname) as nname_binary
from test
到底该如何选用nvarchar和varchar?用不用以N’'形式编写sql?
如果你的数据中不需要保存中英文以外的字符(如:emoji表情字符),那么你可以忽略nvarchar和N’’,如果你的数据库中需要保存其他特殊字符(如:emoji表情字符),那么你就必须使用nvarchar数据类型,并且以N’'形式编写sql语句。
六、关于nvarchar(10)个varchar(10)的最多能存多少个字符
首先,要明白字符和字节不是一个概念。英文字母“a”、汉字“啊”、emoji表情“😀”都称之为一个字符,但使用不同的字符集编码的时候他们可能占用不同的字节。
英文字母“a”在GBK下占1个字节、在UTF-16下占2个字节、在UTF-8下占用1个字节;
汉字“啊”在GBK下和UTF-16下都占2个字节、在UTF-8下占三个字节;
emoji表情“😀”在UTF-16和UTF-8下都占4个字节,在GBK下无对应编码;
在sqlserver2012以上的Chinese_PRC_CI_AS排序规则下,nvarchar使用UTF-16编码,varchar使用ANSI编码(如果电脑的区域设置为中文的话,就是GBK编码,在中国可认为就是GBK编码)。
对于nvarchar(10)来说,这一列将最多使用10*2个字节来存储数据。又因为使用UTF-16来编码数据,所以最多存储10个英文字母或汉字,这看起来capcity就像是字符数量一样(但实际不是)。如果你存储的只有英文字符和汉字的话,这么认为也没有错,但如果你要存储emoji表情的话(UTF-16下占4个字节),那么capcity可就不能这么认为了。一会看下面的实验;
对于varchar(10)来说。这一列将最多使用10个字节来存储数据。又因为使用GBK(在中国这么认为)编码,所以最多存储10个英文字母或10/2个汉字。注意:emoji表情存不进去哦(GBK中没有emoji,存进去就是乱码)。
另外,应该微软有意限制varchar或nvarchar占用的字节数,所以规定nvarchar(capcity)的capcity最大值为4000,varchar(capcity)的capcity的最大值为8000。当然,如果你用nvarchar(max)或varchar(max)就基本上可以忽略大小限制了,因为它们最大可占用2G。
关于nvarchar和varchar的容量实验:
-- sqlserver2014
-- 排序规则: Chinese_PRC_CI_AS
--drop table t
create table t(
name nvarchar(10),
name2 varchar(10)
)
-- name: 最多存储10*2=20个字节,对于英文字母和汉字(utf16编码下都是两个字节)来说就是10个字符
-- name2 最多存储10个字节,用GBK编码,英文字母一个字节,汉字两个字节,最多存储10个英文字母和5个汉字
insert into t(name) values('1234567890') --正常
insert into t(name) values('一二三四五六七八九十') --正常
insert into t(name) values('123456789😀') -- 截断
insert into t(name2) values('一二三四五') --正常
insert into t(name2) values('1234567890') --正常
insert into t(name2) values('一二三四五1') --截断
数据库三大范式#
什么是范式?#
范式是数据库设计时遵循的一种规范,不同的规范要求遵循不同的范式。
最常用的三大范式#
第一范式(1NF):属性不可分割,即每个属性都是不可分割的原子项。(实体的属性即表中的列)
第二范式(2NF):满足第一范式;且不存在部分依赖,即非主属性必须完全依赖于主属性。(主属性即主键;完全依赖是针对于联合主键的情况,非主键列不能只依赖于主键的一部分)
第三范式(3NF):满足第二范式;且不存在传递依赖,即非主属性不能与非主属性之间有依赖关系,非主属性必须直接依赖于主属性,不能间接依赖主属性。(A -> B, B ->C, A -> C)
举例说明3NF#
第一范式1NF#
属性不可再分,即表中的每个列都不可以再进行拆分。
如下学生信息表(student):
id、name(姓名)、sex_code(性别代号)、sex_desc(性别描述)、contact(联系方式)
primary key(id)

如果在查询学生表时经常用到学生的电话号,则应该将联系方式(contact)这一列分为电话号(phone)和地址(address)两列,这样才符合第一范式。
修改使表满足1NF后:

判断表是否符合第一范式,列是否可以再分,得看需求,如果将电话号和地址分开才能满足查询等需求时,那之前的表设计就是不满足1NF的,如果电话号和地址拼接作为一个字段也可以满足查询、存储等需求时,那它就满足1NF。
第二范式 2NF#
在满足1NF的前提下,表中不存在部分依赖,非主键列要完全依赖于主键。(主要是说在联合主键的情况下,非主键列不能只依赖于主键的一部分)
如下学生成绩表(score):
stu_id(学生id)、kc_id(课程id)、score(分数)、kc_name(课程名)
primary key(stu_id, kc_id)

表中主键为stu_id和kc_id组成的联合主键。满足1NF;非主键列score完全依赖于主键,stu_id和kc_id两个值才能决定score的值;而kc_name只依赖于kc_id,与stu_id没有依赖关系,它不完全依赖于主键,只依赖于主键的一部分,不符合2NF。
修改使表满足2NF后:
成绩表(score) primary key(stu_id)

课程表(kc) primary key(kc_id)

将原来的成绩表(score)拆分为成绩表(score)和课程表(kc),而且两个表都符合2NF。
第三范式 3NF:#
在满足2NF的前提下,不存在传递依赖。(A -> B, B -> C, A->C)
如下学生信息表(student):
primary key(id)

表中sex_desc依赖于sex_code,而sex_code依赖于id(主键),从而推出sex_desc依赖于id(主键);sex_desc不直接依赖于主键,而是通过依赖于非主键列而依赖于主键,属于传递依赖,不符合3NF。
修改表使满足3NF后:
学生表(student) primary key(id)

性别代码表(sexcode) primary key(sex_code)

将原来的student表进行拆分后,两个表都满足3NF。
什么样的表越容易符合3NF?#
非主键列越少的表。(1NF强调列不可再分;2NF和3NF强调非主属性列和主属性列之间的关系)
如代码表(sexcode),非主键列只有一个sex_desc;
或者将学生表的主键设计为primary key(id,name,sex_code,phone),这样非主键列只有address,更容易符合3NF。
什么是索引覆盖?什么是索引下推?#
一. 什么是索引覆盖?#
在执行某个查询语句时,在一颗索引数上就能够获取sql所需要的所有列的数据,无需回表。这就是索引覆盖。
当发起一个索引覆盖的查询时,在explain的extra列会显示Using index
如何实现索引覆盖呢?
常见方法:将被查询的字段建立到联合索引里去。
举个例子,先建立一张表,表结构如下:
create table user(
id int primary key,
name varchar(20),
sex varchar(5),
index(name)
)engine=innodb;
1234567891011
然后执行sql语句:
select id, name, sex from user where name='zhangsan'
1
显而易见,这个sql是可以命中name索引的,但是这个sql 不符合索引覆盖,原因就是name索引的叶子节点只存储了id和name字段,没有存储sex,sex字段必须回表查询才能获取到,需要拿到id值到主键索引获取sex字段
这时如果把(name)单列索引换成联合索引(name, sex),那就不同了,索引的叶子节点存储了主键id、name、sex那么上面的sql 语句就可以命中索引覆盖无需回表,查询效率更高。
二. 什么是索引下推?#
索引条件下推 也被称为 索引下推(Index Condition Pushdown)ICP,MySQL5.6新添加的特性,用于优化数据查询的。
5.6之前通过非主键索引查询时,存储引擎通过索引查询数据,然后将结果返回给MySQL server层,在server层判断是否符合条件,在以后的版本可以使用索引下推,当存在索引列作为判断条件时,Mysql server 将这一部分判断条件传递给存储引擎,然后存储引擎会筛选出符合传递传递条件的索引项,即在存储引擎层根据索引条件过滤掉不符合条件的索引项,然后回表查询得到结果,将结果再返回给Mysql server,有了索引下推的优化,在满足一定条件下,存储 引擎层会在回表查询之前对数据进行过滤,可以减少存储引擎回表查询的次数。
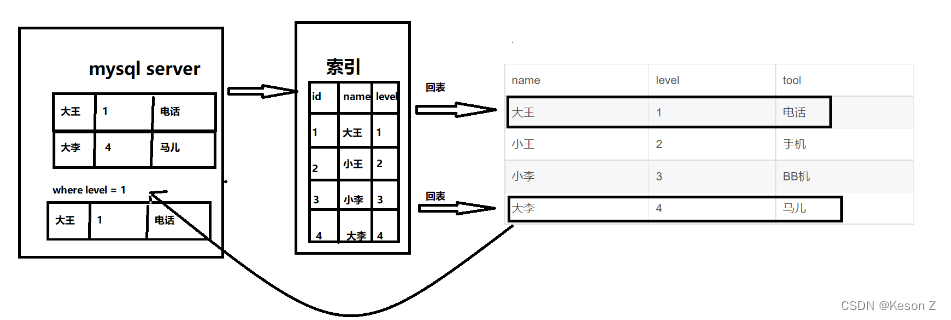
假如有一张表user
表有四个字段 id,name,level,tool
| id | name | level | tool |
|---|---|---|---|
| id | name | level | tool |
| 1 | 大王 | 1 | 电话 |
| 2 | 小王 | 2 | 手机 |
| 3 | 小李 | 3 | BB机 |
| 4 | 大李 | 4 | 马儿 |
建立联合索引(name,level)
匹配姓名第一个字为“大”,并且level为1的用户,sql语句为:
select * from user where name like "大%" and level = 1;
1
在5.6之前,执行流程是如下图:
5.6及之后,执行流程图如下:
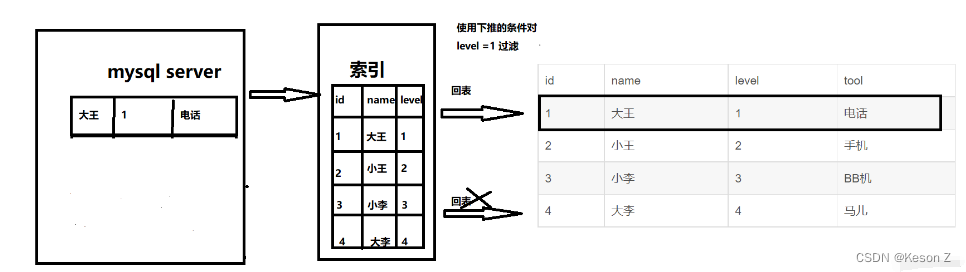
使用索引下推后由两次回表变为一次,提高了查询效率。
为什么 B+ 树比 B 树更适合应用于数据库索引?#
1.由一个例子总结索引的特点#
加索引是数据库加速查询的一种方式,那么为什么用索引可以加快查询呢?
讲到索引,其实我们经常会听到一个图书馆的例子,图书馆里的书目繁杂,我们如何从若干本书里面找到一本我们想要的书呢?
我们根据图书馆系统检索,可以找到某本书对应的图书编号。在基于书籍按照一定规则排列的前提下,我们可以根据图书编号找到这本书。
例如,假设图书编号根据:
第几个书架 - 书架上第几个格子 - 从左到右数第几个位置这样的规则编排,我们就可以轻松的获取到我们想要的书籍。
你也许发现了,这个例子中,藏着两个信息:
- 按照一定的规则排列
- 有序
按照一定的规则,建立一定的映射关系,这让你联想到了什么?
没错,就是哈希表。
2.基于哈希表实现的哈希索引#
在 Mysql 的 InnoDB 引擎中,自适应哈希索引就是用哈希表实现的。
哈希索引是数据库自身创建并使用的,DBA 本身不能对其进行干预,但是可以通过参数来禁止或者启用此特性。
显然用哈希表实现索引的好处是非常明显的,查找单个指定数据只需要 O(1)O(1) 的时间复杂度。
例如下面的 sql 语句:
select id from tablename where id == 1;
1
但是对于这种查找指定范围的 sql 语句,哈希索引就无能为力了。
select id from tablename where id BETWEEN 20 AND 23;
1
说明:因为哈希表本身是无序的,所以不利于范围查询
再次思考
到这里我们遇到了一个问题,就是哈希表虽然从查找效率上满足了我们查找单个数据的要求,但是显然,当遇到范围查询时,由于哈希表本身的无序性,不利于指定范围查找。
也就是说,我们的需求增加了,我们希望数据的组织方式,既要有一定规则,又要有序。
在引出这种数据结构之前,我们首先来看一种查找方式:二分查找。
3.高效的查找方式:二分查找#
二分查找的核心思想是给定一个 有序 的数组,在查找过程中采用跳跃式的方式查找,即先以有序数列的中点位置为比较对象,如果要查找的元素小于中点元素,则将待查序列缩小为左半部分,否则为右半部分。通过每次比较,将查找区间减少一半,直到找到所需元素。
比如要从以下序列中查找到数字 4
[1,3,4,5,6,7,8]
需要经过下面的查找步骤:
- 取中心位置对应元素,显然 5 大于 4,在左边区间 [1,3,4] 进行查找
- 继续取中心位置对应元素 3,显然 3 大于 4,在右边区间 [4] 进行查找
- 4 等于 4,所以我们查找成功。
可以看到二分查找的效率是 O(log n)。
由于有序数组自身的有序性,所以范围查询依然可以通过二分查找的方式查找区间的边界来实现。
这样看来,如果单从查询效率上来说,有序的数组是一种很好的选择。
但是显然有序数组对于插入和删除并不友好,假设我们要插入元素或者删除元素,都需要把部分元素全部向后或者向前移动,最糟糕的时间复杂度是 O(n)O(n)。
有没有这样一种数据结构,既有一定顺序,又方便插入和删除呢?事实上,基于二分查找的思想,诞生了这样一种数据结构:二分查找树。
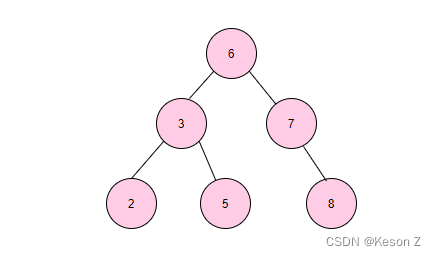
4.基于二分查找思想的二叉查找树#
二叉查找树(Binary Search Tree)即BST树是这样的一种数据结构,如下图:
在二叉搜索树中:
1). 若任意结点的左子树不空,则左子树上所有结点的值均不大于它的根结点的值。
2). 若任意结点的右子树不空,则右子树上所有结点的值均不小于它的根结点的值。
3). 任意结点的左、右子树也分别为二叉搜索树。
这样的结构非常适合用二分查找的思维查找元素。
比如我们需要查找键值为8的记录:
- 先从根找起,找到 6; 显然 8>6,
- 所以接着找到 6 的右子树,找到 7;
- 显然 8>7, 所以找 7 的右子树,找到了8,查找结束。
这样一棵子树高度差不大于 1 的二叉查找树的查找效率接近与 O(log n)O(logn);
但是当二叉树的构造变成这样时,
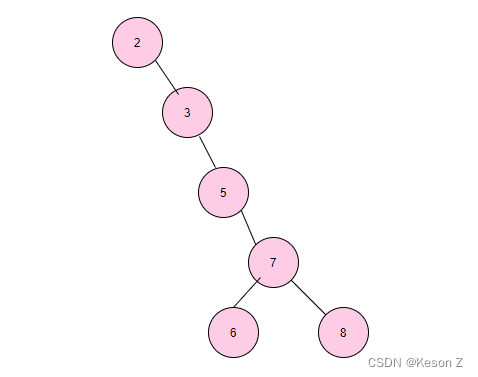
此时我们再查找 8 时,查找效率就沦为接近顺序遍历查找的效率。
5.升级版的BST树:AVL 树#
我们对二叉查找树做个限制,限制必须满足任何节点的两个子树的最大差为 1,也是AVL 树的定义,这样我们的查找效率就有了一定的保障。AVL 树 是一种自平衡二叉查找树(self-balancing binary search tree)。
当然,维护AVL 树也是需要一定开销的,即当树插入/更新/删除新的数据时假设破坏了树的平衡性,那么需要通过左旋和右旋来维护树的平衡。当数据量很多时,同样也会出现二叉树过高的情况。我们知道AVL 树的查找效率为 O(log n),也就是说,当树过高时,查找效率会下降。
另外由于我们的索引文件并不小,所以是存储在磁盘上的。文件系统需要从磁盘读取数据时,一般以页为单位进行读取,假设一个页内的数据过少,那么操作系统就需要读取更多的页,涉及磁盘随机 I/O 访问的次数就更多。
将数据从磁盘读入内存涉及随机 I/O 的访问,是数据库里面成本最高的操作之一。
因而这种树高会随数据量增多急剧增加,每次更新数据又需要通过左旋和右旋维护平衡的二叉树,不太适合用于存储在磁盘上的索引文件。
6.更加符合磁盘特征的B树#
前面我们看到,虽然AVL树既有链表的快速插入与删除操作的特点,又有数组快速查找的优势,但是这并不是最符合磁盘读写特征的数据结构。
也就是说,我们要找到这样一种数据结构,能够有效的控制树高,那么我们把二叉树变成m叉树,也就是下图的这种数据结构:B 树。
B树是一种这样的数据结构:
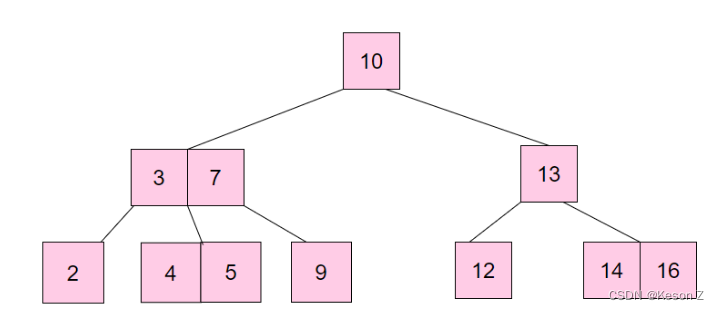
- 根结点至少有两个子结点;
- 每个中间节点都包含 k-1 个元素和k个子结点,其中 m/2 <= k <= m;
- 每一个叶子结点都包含 k-1个元素,其中 m/2 <= k <= m;
- 所有的叶子结点都位于同一层;
- 每个结点中关键字从小到大排列,并且当该结点的孩子是非叶子结点时,该 k-1 个元素正好是 k 个子结点包含的元素的值域的分划。
可以看到,B树在保留二叉树预划分范围从而提升查询效率的思想的前提下,做了以下优化:
二叉树变成 m 叉树,这个 m 的大小可以根据单个页的大小做对应调整,从而使得一个页可以存储更多的数据,从磁盘中读取一个页可以读到的数据就更多,随机 IO 次数变少,大大提升效率。
但是我们看到,我们只能通过中序遍历查询全表,当进行范围查询时,可能会需要中序回溯。
7.不断优化的B树:B+ 树#
基于以上的缺陷,又诞生了一种新的优化B树的树: B+ 树
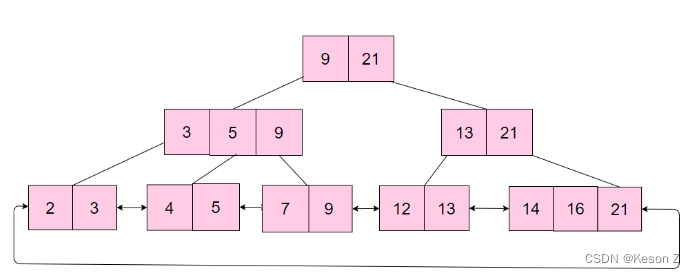
B+树在B树的基础上加了以下优化:
1.叶子结点增加了指针进行连接,即叶子结点间形成了链表;
2.非叶子结点只存关键字 key,不再存储数据,只在叶子结点存储数据;
说明:叶子之间用双向链表连接比单向链表连接多出的好处是通过链表中任一结点都可以通过往前或者往后遍历找到链表中指定的其他结点。
这样做的好处是:
- 范围查询时可以通过访问叶子节点的链表进行有序遍历,而不再需要中序回溯访问结点。
- 非叶子结点只存储关键字key,一方面这种结构相当于划分出了更多的范围,加快了查询速度,另一方面相当于单个索引值大小变小,同一个页可以存储更多的关键字,读取单个页就可以得到更多的关键字,可检索的范围变大了,相对 IO 读写次数就降低了。
8.一些总结#
B+ 树和 B 树的区别?#
B 树非叶子结点和叶子结点都存储数据,因此查询数据时,时间复杂度最好为 O(1),最坏为 O(log n)。B+ 树只在叶子结点存储数据,非叶子结点存储关键字,且不同非叶子结点的关键字可能重复,因此查询数据时,时间复杂度固定为 O(log n)。- B+ 树叶子结点之间用
链表相互连接,因而只需扫描叶子结点的链表就可以完成一次遍历操作,B树只能通过中序遍历。
为什么 B+ 树比 B 树更适合应用于数据库索引?#
- B+ 树更加适应磁盘的特性,相比 B 树
减少了 I/O 读写的次数。由于索引文件很大因此索引文件存储在磁盘上,B+ 树的非叶子结点只存关键字不存数据,因而单个页可以存储更多的关键字,即一次性读入内存的需要查找的关键字也就越多,磁盘的随机 I/O 读取次数相对就减少了。 - B+ 树的
查询效率相比B树更加稳定,由于数据只存在在叶子结点上,所以查找效率固定为 O(log n)。 - B+ 树叶
子结点之间用链表有序连接,所以扫描全部数据只需扫描一遍叶子结点,利于扫库和范围查询;B 树由于非叶子结点也存数据,所以只能通过中序遍历按序来扫。也就是说,对于范围查询和有序遍历而言,B+ 树的效率更高。
数据库事务与锁详解#
1. 什么是事务(Transaction)?#
是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。 事务处理可以确保除非事务性单元内的所有操作都成功完成,否则不会永久更新面向数据的资源。通过将一组相关操作组合为一个要么全部成功要么全部失败的单元,可以简化错误恢复并使应用程序更加可靠。一个逻辑工作单元要成为事务,必须满足所谓的ACID(原子性、一致性、隔离性和持久性)属性。事务是数据库运行中的一个逻辑工作单位,由DBMS中的事务管理子系统负责事务的处理。
举个例子加深一下理解:
同一个银行转账,A转1000块钱给B,这里存在两个操作,一个是A账户扣款1000元,两一个操作是B账户增加1000元,两者就构成了转账这个事务。
两个操作都成功,A账户扣款1000元,B账户增加1000元,事务成功
两个操作都失败,A账户和B账户金额都没变,事务失败
最后思考一下,怎么样会出现A账户扣款1000元,B账户金额不变?如果你是把两个操作放在一个事务里面,并且是数据库提供的内在事务支持,那就不会有问题,但是开发人员把两个操作放在两个事务里面,而第二个事务失败就会出现中间状态。现实中自己实现的分布式事务处理不当也会出现中间状态,这并不是事务的错,事务本身就是规定不会出现中间状态,是事务实现者做出来的方案有问题。
2. 事务的4个特性#
- 原子性(Atomic):事务必须是原子工作单元;对于其数据修改,要么
全都执行,要么全都不执行。通常,与某个事务关联的操作具有共同的目标,并且是相互依赖的。如果系统只执行这些操作的一个子集,则可能会破坏事务的总体目标。原子性消除了系统处理操作子集的可能性。 - 一致性(Consistency):事务的一致性指的是在
一个事务执行之前和执行之后数据库都必须处于一致性状态。这种特性称为事务的一致性。假如数据库的状态满足所有的完整性约束,就说该数据库是一致的。 - 隔离性(Isolation):
由并发事务所作的修改必须与任何其它并发事务所作的修改隔离。事务查看数据时数据所处的状态,到底是另一个事务执行之前的状态还是中间某个状态,相互之间存在什么影响,是可以通过隔离级别的设置来控制的。 - 持久性(Durability):事务结束后,事务处理的结果必须能够得到固化,即
写入数据库文件中即使机器宕机数据也不会丢失,它对于系统的影响是永久性的。
3. 事务并发控制#
我们从另外一个方向来说说,如果不对事务进行并发控制,我们看看数据库并发操作是会有那些异常情形,有些使我们可以接受的,有些是不能接受的,注意这里的异常就是特定语境下的,并不一定就是错误什么的。假设有一个order表,有个字段叫count,作为计数用,当前值为100
- 第一类丢失更新(Update Lost):此种
更新丢失是因为回滚的原因,所以也叫回滚丢失。此时两个事务同时更新count,两个事务都读取到100,事务一更新成功并提交,count=100+1=101,事务二出于某种原因更新失败了,然后回滚,事务二就把count还原为它一开始读到的100,此时事务一的更新就这样丢失了。 - 脏读(Dirty Read):此种异常时
因为一个事务读取了另一个事务修改了但是未提交的数据。举个例子,事务一更新了count=101,但是没有提交,事务二此时读取count,值为101而不是100,然后事务一出于某种原因回滚了,然后第二个事务读取的这个值就是噩梦的开始。 - 不可重复读(Not Repeatable Read):此种异常是
一个事务对同一行数据执行了两次或更多次查询,但是却得到了不同的结果,也就是在一个事务里面你不能重复(即多次)读取一行数据,如果你这么做了,不能保证每次读取的结果是一样的,有可能一样有可能不一样。造成这个结果是在两次查询之间有别的事务对该行数据做了更新操作。举个例子,事务一先查询了count,值为100,此时事务二更新了count=101,事务一再次读取count,值就会变成101,两次读取结果不一样。 - 第二类丢失更新(Second Update Lost):此种
更新丢失是因为更新被其他事务给覆盖了,也可以叫覆盖丢失。举个例子,两个事务同时更新count,都读取100这个初始值,事务一先更新成功并提交,count=100+1=101,事务二后更新成功并提交,count=100+1=101,由于事务二count还是从100开始增加,事务一的更新就这样丢失了。 - 幻读(Phantom Read):幻读和不可重复读有点像,只是
针对的不是数据的值而是数据的数量。此种异常是一个事务在两次查询的过程中数据的数量不同,让人以为发生幻觉,幻读大概就是这么得来的吧。举个例子,事务一查询order表有多少条记录,事务二新增了一条记录,然后事务一查了一下order表有多少记录,发现和第一次不一样,这就是幻读。
4. 数据库事务隔离级别#
看到上面提到的几种问题,你可能会想,我擦,这么多坑怎么办啊。其实上面几种情况并不是一定都要避免的,具体看你的业务要求,包括你数据库的负载都会影响你的决定。不知道大家发现没有,上面各种异常情况都是多个事务之间相互影响造成的,这说明两个事务之间需要某种方式将他们从某种程度上分开,降低直至避免相互影响。这时候数据库事务隔离级别就粉墨登场了,而数据库的隔离级别实现一般是通过数据库锁实现的。
- 读未提交(Read Uncommitted):该隔离级别指
即使一个事务的更新语句没有提交,但是别的事务可以读到这个改变,几种异常情况都可能出现。极易出错,没有安全性可言,基本不会使用。 - 读已提交(Read Committed):该隔离级别
指一个事务只能看到其他事务的已经提交的更新,看不到未提交的更新,消除了脏读和第一类丢失更新,这是大多数数据库的默认隔离级别,如Oracle,Sqlserver。 - 可重复读(Repeatable Read):该隔离级别指
一个事务中进行两次或多次同样的对于数据内容的查询,得到的结果是一样的,但不保证对于数据条数的查询是一样的,只要存在读改行数据就禁止写,消除了不可重复读和第二类更新丢失,这是Mysql数据库的默认隔离级别。 - 串行化(Serializable):意思是说
这个事务执行的时候不允许别的事务并发执行,完全串行化的读,只要存在读就禁止写,但可以同时读,消除了幻读。这是事务隔离的最高级别,虽然最安全最省心,但是效率太低,一般不会用。
下面是各种隔离级别对各异常的控制能力:
| 级别\异常 | 第一类更新丢失 | 脏读 | 不可重复读 | 第二类丢失更新 | 幻读 |
|---|---|---|---|---|---|
| 读未提交 | Y | Y | Y | Y | Y |
| 读已提交 | N | N | Y | Y | Y |
| 可重复读 | N | N | N | N | Y |
| 串行化 | N | N | N | N | N |
5. 数据库锁分类#
一般可以分为两类,一个是悲观锁,一个是乐观锁,悲观锁一般就是我们通常说的数据库锁机制,乐观锁一般是指用户自己实现的一种锁机制,比如hibernate实现的乐观锁甚至编程语言也有乐观锁的思想的应用。
5.1 悲观锁#
悲观锁:顾名思义,就是很悲观,它对于数据被外界修改持保守态度,认为数据随时会修改,所以整个数据处理中需要将数据加锁。悲观锁一般都是依靠关系数据库提供的锁机制,事实上关系数据库中的行锁,表锁不论是读写锁都是悲观锁。
悲观锁按照使用性质划分:
- 共享锁(Share locks简记为S锁):也称
读锁,事务A对对象T加s锁,其他事务也只能对T加S,多个事务可以同时读,但不能有写操作,直到A释放S锁。 - 排它锁(Exclusivelocks简记为X锁):也称
写锁,事务A对对象T加X锁以后,其他事务不能对T加任何锁,只有事务A可以读写对象T直到A释放X锁。 - 更新锁(简记为U锁):用来预定要对此对象施加X锁,
它允许其他事务读,但不允许再施加U锁或X锁;当被读取的对象将要被更新时,则升级为X锁,主要是用来防止死锁的。因为使用共享锁时,修改数据的操作分为两步,首先获得一个共享锁,读取数据,然后将共享锁升级为排它锁,然后再执行修改操作。这样如果同时有两个或多个事务同时对一个对象申请了共享锁,在修改数据的时候,这些事务都要将共享锁升级为排它锁。这些事务都不会释放共享锁而是一直等待对方释放,这样就造成了死锁。如果一个数据在修改前直接申请更新锁,在数据修改的时候再升级为排它锁,就可以避免死锁。
悲观锁按照作用范围划分:
- 行锁:锁的
作用范围是行级别,数据库能够确定那些行需要锁的情况下使用行锁,如果不知道会影响哪些行的时候就会使用表锁。举个例子,一个用户表user,有主键id和用户生日birthday当你使用update … where id=?这样的语句数据库明确知道会影响哪一行,它就会使用行锁,当你使用update … where birthday=?这样的的语句的时候因为事先不知道会影响哪些行就可能会使用表锁。 - 表锁:锁的
作用范围是整张表。
5.2 乐观锁#
顾名思义,就是很乐观,每次自己操作数据的时候认为没有人回来修改它,所以不去加锁,但是在更新的时候会去判断在此期间数据有没有被修改,需要用户自己去实现。既然都有数据库提供的悲观锁可以方便使用为什么要使用乐观锁呢?对于读操作远多于写操作的时候,大多数都是读取,这时候一个更新操作加锁会阻塞所有读取,降低了吞吐量。最后还要释放锁,锁是需要一些开销的,我们只要想办法解决极少量的更新操作的同步问题。换句话说,如果是读写比例差距不是非常大或者你的系统没有响应不及时,吞吐量瓶颈问题,那就不要去使用乐观锁,它增加了复杂度,也带来了额外的风险。
乐观锁实现方式:
- 版本号(记为version):就是
给数据增加一个版本标识,在数据库上就是表中增加一个version字段,每次更新把这个字段加1,读取数据的时候把version读出来,更新的时候比较version,如果还是开始读取的version就可以更新了,如果现在的version比老的version大,说明有其他事务更新了该数据,并增加了版本号,这时候得到一个无法更新的通知,用户自行根据这个通知来决定怎么处理,比如重新开始一遍。这里的关键是判断version和更新两个动作需要作为一个原子单元执行,否则在你判断可以更新以后正式更新之前有别的事务修改了version,这个时候你再去更新就可能会覆盖前一个事务做的更新,造成第二类丢失更新,所以你可以使用update … where … and version="old version"这样的语句,根据返回结果是0还是非0来得到通知,如果是0说明更新没有成功,因为version被改了,如果返回非0说明更新成功。 - 时间戳(timestamp):和版本号基本一样,只是
通过时间戳来判断而已,注意时间戳要使用数据库服务器的时间戳不能是业务系统的时间。 - 待更新字段:和版本号方式相似,只是
不增加额外字段,直接使用有效数据字段做版本控制信息,因为有时候我们可能无法改变旧系统的数据库表结构。假设有个待更新字段叫count,先去读取这个count,更新的时候去比较数据库中count的值是不是我期望的值(即开始读的值),如果是就把我修改的count的值更新到该字段,否则更新失败。java的基本类型的原子类型对象如AtomicInteger就是这种思想。 - 所有字段:和待更新字段类似,只是
使用所有字段做版本控制信息,只有所有字段都没变化才会执行更新。
乐观锁几种方式的区别:
新系统设计可以使用version方式和timestamp方式,需要增加字段,应用范围是整条数据,不论那个字段修改都会更新version,也就是说两个事务更新同一条记录的两个不相关字段也是互斥的,不能同步进行。旧系统不能修改数据库表结构的时候使用数据字段作为版本控制信息,不需要新增字段,待更新字段方式只要其他事务修改的字段和当前事务修改的字段没有重叠就可以同步进行,并发性更高。
MySQL优化—Explain#
一. 查看SQL执行频率#
MySQL 客户端连接成功后,通过 show [session|global] status 命令可以提供服务器状态信息。它可以根据需要加上参数“session”或者“global”来显示 session 级(当前连接)的统计结果和global 级(自数据库上次启动至今)的统计结果。如果不写,默认使用参数是“session”。
下面的命令显示了当前 session 中所有统计参数的值:
show status like 'Com_______';
1
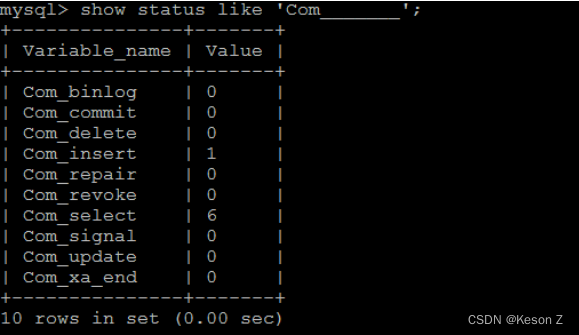
show status like 'Innodb_rows_%';
1
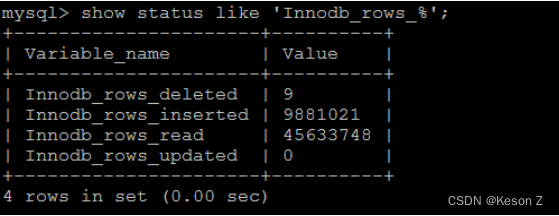
Com_xxx 表示每个 xxx 语句执行的次数,我们通常比较关心的是以下几个统计参数。
| 参数 | 含义 |
|---|---|
| Com_select | 执行 select 操作的次数,一次查询只累加 1。 |
| Com_insert | 执行 INSERT 操作的次数,对于批量插入的 INSERT 操作,只累加一次。 |
| Com_update | 执行 UPDATE 操作的次数。 |
| Com_delete | 执行 DELETE 操作的次数。 |
| Innodb_rows_read select | 查询返回的行数。 |
| Innodb_rows_inserted | 执行 INSERT 操作插入的行数。 |
| Innodb_rows_updated | 执行 UPDATE 操作更新的行数。 |
| Innodb_rows_deleted | 执行 DELETE 操作删除的行数。 |
| Connections 试图连接 | MySQL 服务器的次数。 |
| Uptime | 服务器工作时间。 |
| Slow_queries | 慢查询的次数。 |
Com_*** : 这些参数对于所有存储引擎的表操作都会进行累计。
Innodb_*** : 这几个参数只是针对InnoDB 存储引擎的,累加的算法也略有不同。
二. 定位低效率执行SQL#
可以通过以下两种方式定位执行效率较低的 SQL 语句。
慢查询日志: 通过慢查询日志定位那些执行效率较低的 SQL语句,用–log-slow-queries[=file_name]选项启动时,mysqld 写一个包含所有执行时间超过long_query_time 秒的 SQL 语句的日志文件。show processlist:慢查询日志在查询结束以后才纪录,所以在应用反映执行效率出现问题的时候查询慢查询日志并不能定位问题,可以使用show processlist命令查看当前MySQL在进行的线程,包括线程的状态、是否锁表等,可以实时地查看 SQL的执行情况,同时对一些锁表操作进行优化。

1)id列,用户登录mysql时,系统分配的"connection_id",可以使用函数connection_id()查看
2)user列,显示当前用户。如果不是root,这个命令就只显示用户权限范围的sql语句
3)host列,显示这个语句是从哪个ip的哪个端口上发的,可以用来跟踪出现问题语句的用户
4)db列,显示这个进程目前连接的是哪个数据库
5)command列,显示当前连接的执行的命令,一般取值为休眠(sleep),查询(query),连接 (connect)等
\6) time列,显示这个状态持续的时间,单位是秒
\7) state列,显示使用当前连接的sql语句的状态,很重要的列。state描述的是语句执行中的某一个状态。一个sql语句,以查询为例,可能需要经过copying to tmp table、sorting result、sending data等状态
才可以完成
8)info列,显示这个sql语句,是判断问题语句的一个重要依据
三. explain分析执行计划#
通过以上步骤查询到效率低的 SQL 语句后,可以通过 EXPLAIN命令获取 MySQL如何执行 SELECT 语句的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序。
查询SQL语句的执行计划 :
explain select * from tb_item where id = 1;
1

explain select * from tb_item where title = '阿尔卡特 (OT-979) 冰川白 联通3G手机3';
1

| 字段 | 含义 |
|---|---|
| id | select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。 |
| select_type | 表示 SELECT 的类型,常见的取值有 SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION 中的第二个或者后面的查询语句)、SUBQUERY(子查询中的第一个 SELECT)等 |
| table | 输出结果集的表 |
| type | 表示表的连接类型,性能由好到差的连接类型为( system —> const -----> eq_ref ------> ref-------> ref_or_null----> index_merge —> index_subquery -----> range -----> index ------>all ) |
| possible_keys | 表示查询时,可能使用的索引 |
| key | 表示实际使用的索引 |
| key_len | 索引字段的长度 |
| rows | 扫描行的数量 |
| extra | 执行情况的说明和描述 |
3.1 id#
id 字段是 select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。id 情况有三种:
a) id 相同表示加载表的顺序是从上到下。
explain select * from t_role r, t_user u, user_role ur where r.id = ur.role_id and
u.id = ur.user_id ;
12

b) id 不同id值越大,优先级越高,越先被执行。
EXPLAIN SELECT * FROM t_role WHERE id = (SELECT role_id FROM user_role WHERE user_id
= (SELECT id FROM t_user WHERE username = 'stu1'))
12

c) id 有相同,也有不同,同时存在。id相同的可以认为是一组,从上往下顺序执行;在所有的组中,id的值越大,优先级越高,越先执行。
EXPLAIN SELECT * FROM t_role r , (SELECT * FROM user_role ur WHERE ur.`user_id` =
'2') a WHERE r.id = a.role_id ;
12

3.2 select_type#
表示 SELECT 的类型,常见的取值,如下表所示:
| select_type | 含义 |
|---|---|
| SIMPLE | 简单的select查询,查询中不包含子查询或者UNION |
| PRIMARY | 查询中若包含任何复杂的子查询,最外层查询标记为该标识 |
| SUBQUERY | 在SELECT 或 WHERE 列表中包含了子查询 |
| DERIVED | 在FROM 列表中包含的子查询,被标记为 DERIVED(衍生) MYSQL会递归执行这些子查询,把结果放在临时表中 |
| UNION | 若第二个SELECT出现在UNION之后,则标记为UNION ; 若UNION包含在FROM子句的子查询中,外层SELECT将被标记为 : DERIVED |
| UNION RESULT | 从UNION表获取结果的SELECT |
3.3 table#
展示这一行的数据是关于哪一张表的
3.4 type#
type 显示的是访问类型,是较为重要的一个指标,可取值为:
| type | 含义 |
|---|---|
| null | MySQL不访问任何表,索引,直接返回结果 |
| system | 表只有一行记录(等于系统表),这是const类型的特例,一般不会出现 |
| const | 表示通过索引一次就找到了,const 用于比较primary key 或者 unique 索引。因为只匹配一行数据,所以很快。如将主键置于where列表中,MySQL 就能将该查询转换为一个常量。const于将"主键" 或 “唯一” 索引的所有部分与常量值进行比较 |
| eq_ref | 类似ref,区别在于使用的是唯一索引,使用主键的关联查询,关联查询出的记录只有一条。常见于主键或唯一索引扫描 |
| ref | 非唯一性索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,返回所有匹配某个单独值的所有行(多个) |
| range | 只检索给定返回的行,使用一个索引来选择行。 where 之后出现 between , < , > , in 等操作。 |
| index | index 与 ALL的区别为 index 类型只是遍历了索引树, 通常比ALL 快, ALL 是遍历数据文件。 |
| all | 将遍历全表以找到匹配的行 |
结果值从最好到最坏依次是null> system > const > eq_ref > ref > range > index > all
一般来说, 我们需要保证查询至少达到 range 级别, 最好达到ref 。
3.5 key#
| key | 含义 |
|---|---|
| possible_keys | 显示可能应用在这张表的索引, 一个或多个 |
| key | 实际使用的索引, 如果为NULL,则没有使用索引 |
| key_len | 表示索引中使用的字节数, 该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前 提下,长度越短越好 |
3.6 rows#
扫描行的数量。
3.7 extra#
其他的额外的执行计划信息,在该列展示 。
| extra | 含义 |
|---|---|
| using filesort | 说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取, 称为“文件排序”, 效率低。 |
| using temporary | 使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于 order by 和group by; 效率低 |
| using index | 表示相应的select操作使用了覆盖索引, 避免访问表的数据行, 效率不错。 |
四. show profile分析SQL#
Mysql从5.0.37版本开始增加了对 show profiles 和 show profile 语句的支持。show profiles 能够在做SQL优化时帮助我们了解时间都耗费到哪里去了。
通过 have_profiling 参数,能够看到当前MySQL是否支持profile:

默认profiling是关闭的,可以通过set语句在Session级别开启profiling:

set profiling=1; //开启profiling 开关;
1
通过profile,我们能够更清楚地了解SQL执行的过程。
首先,我们可以执行一系列的操作,如下图所示:
show databases;
use db01;
show tables;
select * from tb_item where id < 5;
select count(*) from tb_item;
12345
执行完上述命令之后,再执行show profiles 指令, 来查看SQL语句执行的耗时:
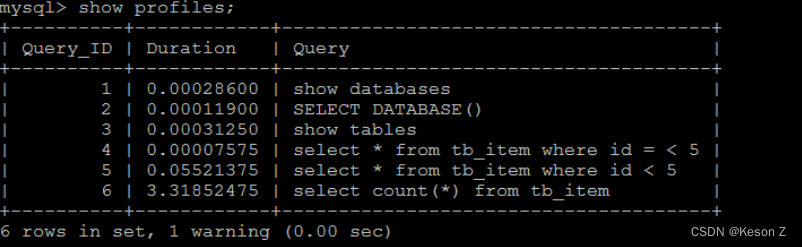
通过show profile for query query_id 语句可以查看到该SQL执行过程中每个线程的状态和消耗的时间:
show profile for query query 6
1
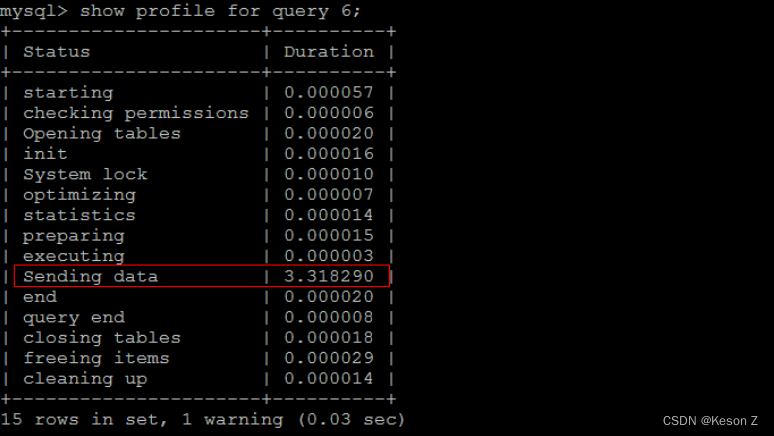
Sending data 状态表示MySQL线程开始访问数据行并把结果返回给客户端,而不仅仅是返回个客户端。由于在Sending data状态下,MySQL线程往往需要做大量的磁盘读取操作,所以经常是整各查询中耗时最长的状态。
在获取到最消耗时间的线程状态后,MySQL支持进一步选择all、cpu、block io 、context switch、page faults等明细类型类查看MySQL在使用什么资源上耗费了过高的时间。例如,选择查看CPU的耗费时间:
show profile cpu for query query 6
1
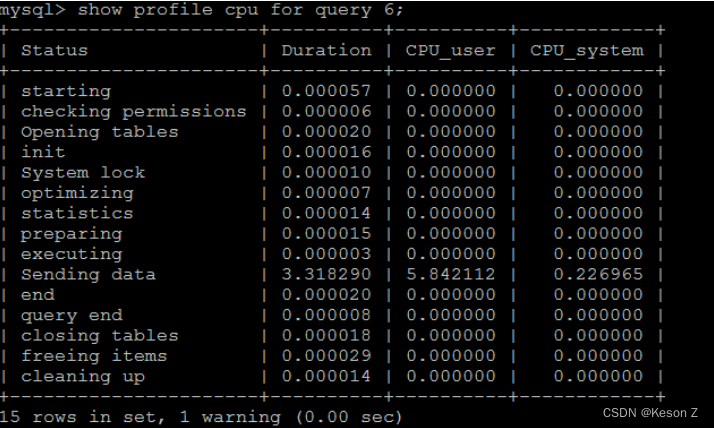
| 字段 | 含义 |
|---|---|
| Status | sql语句执行的状态 |
| Duration | 执行过程中每一个步骤的耗时 |
| CPU_user | 当前用户占有的cpu |
| CPU_system | 系统占有的cpu |




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具