
自己之前写的匹配查找算法,综合评估都很不错(带注解)
不同于目前最流行的,有碰撞的,空间占用很高的HASH算法。对于普通程序而言,自然希望使用的空间能小点。当然,自己的这个算法自然要比市面上那些KMP,BM,SUNDAY等搜索匹配算法的综合效率要高些,在短串与其他长串的性能会有所提高,但也有它的限制与缺陷。在此,也希望各位能够把它进一步改进与优化,好根据项目的需求来找到或创造更好,更合适的算法。
/*
lpdStr 、即被搜索的文本
dnSize 、即被搜索本文的大小
lpsStr 、指定搜索的内容
snSize 、指定搜索内容的大小
返回:指定搜索内容的具体位置,否则返回(-1)
*/
#define MAX_BMAP_SIZE (256U)
#define MAX_BINDEX_SIZE (MAX_BMAP_SIZE + 1U)
static unsigned char g_strChar[MAX_BMAP_SIZE][MAX_BINDEX_SIZE] = { {0U} };
//典型的空间换时间,不要嘲笑我,我只是抓住了这条法则,去实现它
static int _cdecl al_bm_search(const unsigned char * lpdStr, int dnSize, const unsigned char * lpsStr, int snSize)
{
register int i = 0;
register unsigned char n; //利用类型范围,可以让我们减少溢出判断
/*
对指定查找的内容进行定位整合,
我们需要定位单个或是重复字节
的具体位置,方便我们更能有效
的进行模糊匹配,减少多余的比
较。
*/
do {
n = (*g_strChar[lpsStr[i]] + 1); //这里方便的指向了重复内容下一次的索引
g_strChar[lpsStr[i]][n] = i;
*g_strChar[lpsStr[i++]] = n;
} while (i < snSize);
/*
这里我们对整合好的内容进行更有效的匹配查找,
一定要搞清楚什么时候该用while,什么时候该用for,
哪怕有一点点性能的提升,你都是最棒的!
*/
for (i = (snSize - 1); i < dnSize; i += snSize)
{
if (*g_strChar[lpdStr[i]] > 0U) //哦,发现有我们想要的线索
{
register int nOffset;
for (n = *g_strChar[lpdStr[i]];;)
{
nOffset = i - g_strChar[lpdStr[i]][n]; //获得匹配内容开头字节的偏移
if (lpdStr[nOffset] == *lpsStr)
{
register int nIndex = 1;
while (nIndex < snSize)
{
if (lpdStr[++nOffset] != lpsStr[nIndex]) {
goto GOTONEXT;
} ++nIndex;
}
//清理BMAP空间,以便下次复用
i = 0; do {
*g_strChar[lpsStr[i++]] = 0U;
} while (i < snSize);
return (nOffset - (nIndex - 1)); //得到我们想要内容的起始位置
}
GOTONEXT:
if (!(--n)) {
//if (nOffset > i) {
// i = (nOffset - 1);
//}
break;
}
}
}
}
/*
最后我们需要清理我们的BMAP空间,
尽量减少写内容,因为那样很耗时。
*/
i = 0; do {
*g_strChar[lpsStr[i++]] = 0U;
} while (i < snSize);
return (-1); //很遗憾,我们没有发现你想要的内容
}
我们需要来看看测试结果:第一轮是短字符测试,文档很长很大,反复N次查找,接下来我们查询“998”这个短串。

首先,是我的算法测试结果:
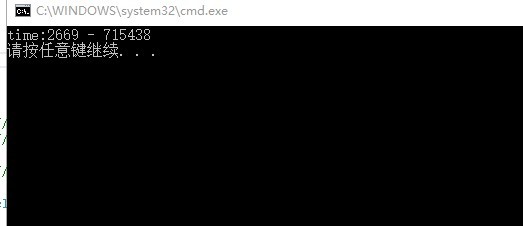
这里我们用最快的sunday算法查找的结果:

最后,我们测试一个长串,我们查询“_gaq.push(['_setAccount', 'UA-53560¥-6']);_gaq.push(['_addOrganic', 'wap.baidu', 'word']);”整条字串。

首先,是我的结果:
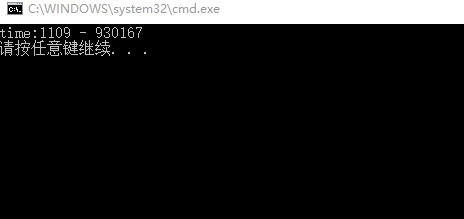
然后是sunday算法的结果:
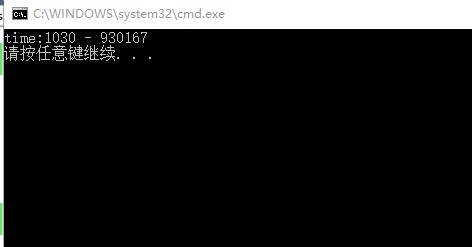
我测试过很多不同的字串与文本,不同的文本用我的算法与sunday算法各有所异,有些文本sunday要比我快很多,然而,有的文本我却要比sunday快不少。

