【Python】where cut query melt函数用法
一,where函数用法
where可以通过Pandas包调用也可以通过numpy来调用。但是日常我们使用numpy调用where的场景会更多。
一起来看一下两者的使用及区别吧。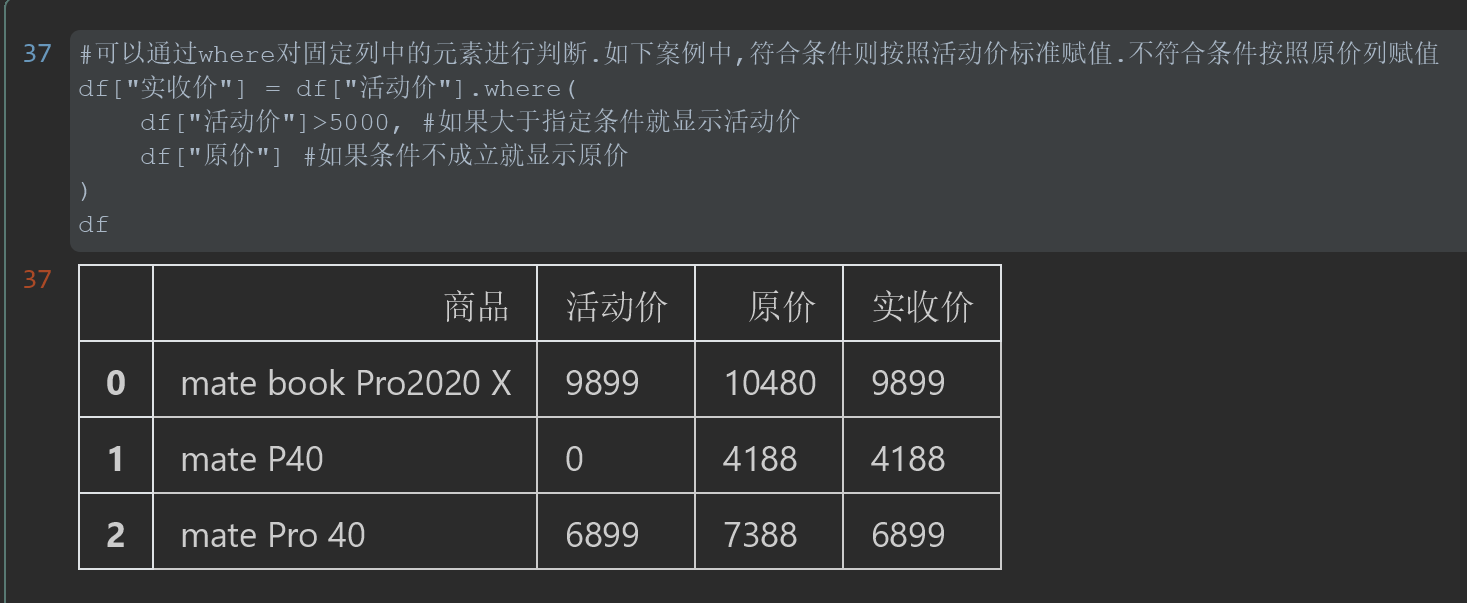
1. 使用Pandas中的where
数据源
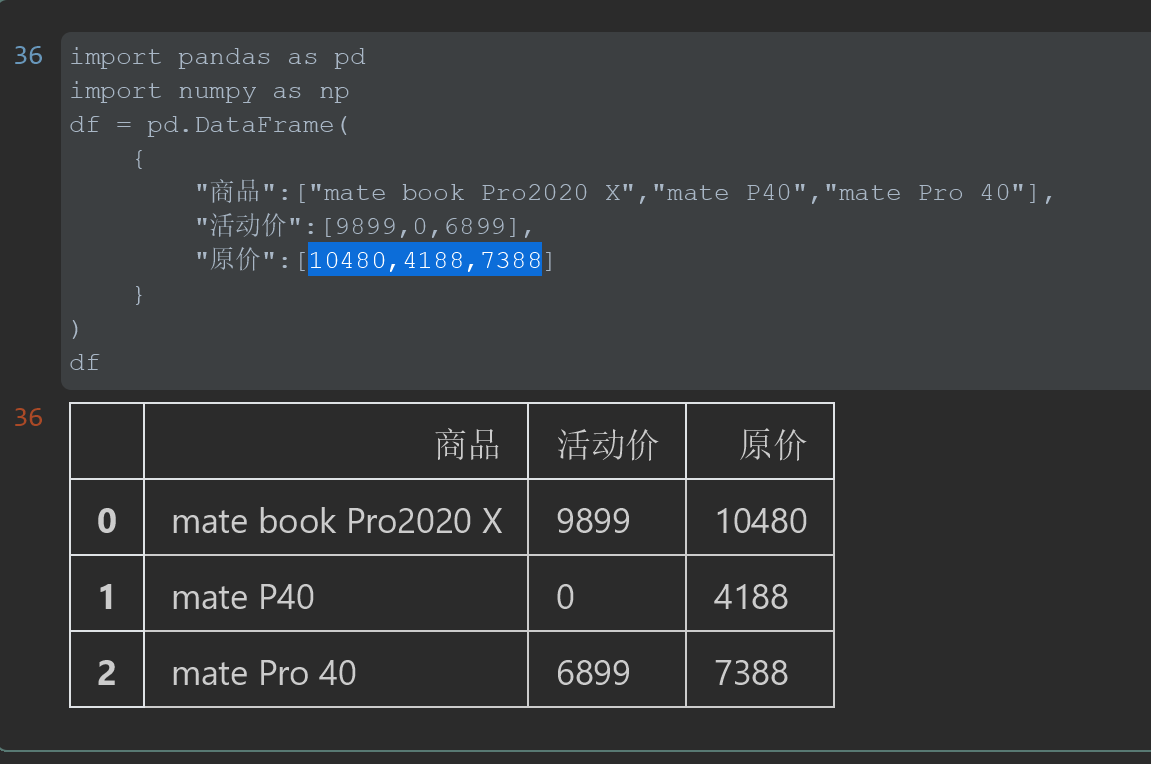
1 #%% 2 3 import pandas as pd 4 import numpy as np 5 df = pd.DataFrame( 6 { 7 "商品":["mate book Pro2020 X","mate P40","mate Pro 40"], 8 "活动价":[9899,0,6899], 9 "原价":[10480,4188,7388] 10 } 11 ) 12 df
结果
Pandas 使用where案例呈现
#%% #可以通过where对固定列中的元素进行判断.如下案例中,符合条件则按照活动价标准赋值.不符合条件按照原价列赋值 df["实收价"] = df["活动价"].where( df["活动价"]>5000, #如果大于指定条件就显示活动价 df["原价"] #如果条件不成立就显示原价 ) df
结果

说明:上述是以活动价为判断条件,条件符合则按照条件执行,不符合则按照条件下方的原价执行。
2. 使用numpy中的where
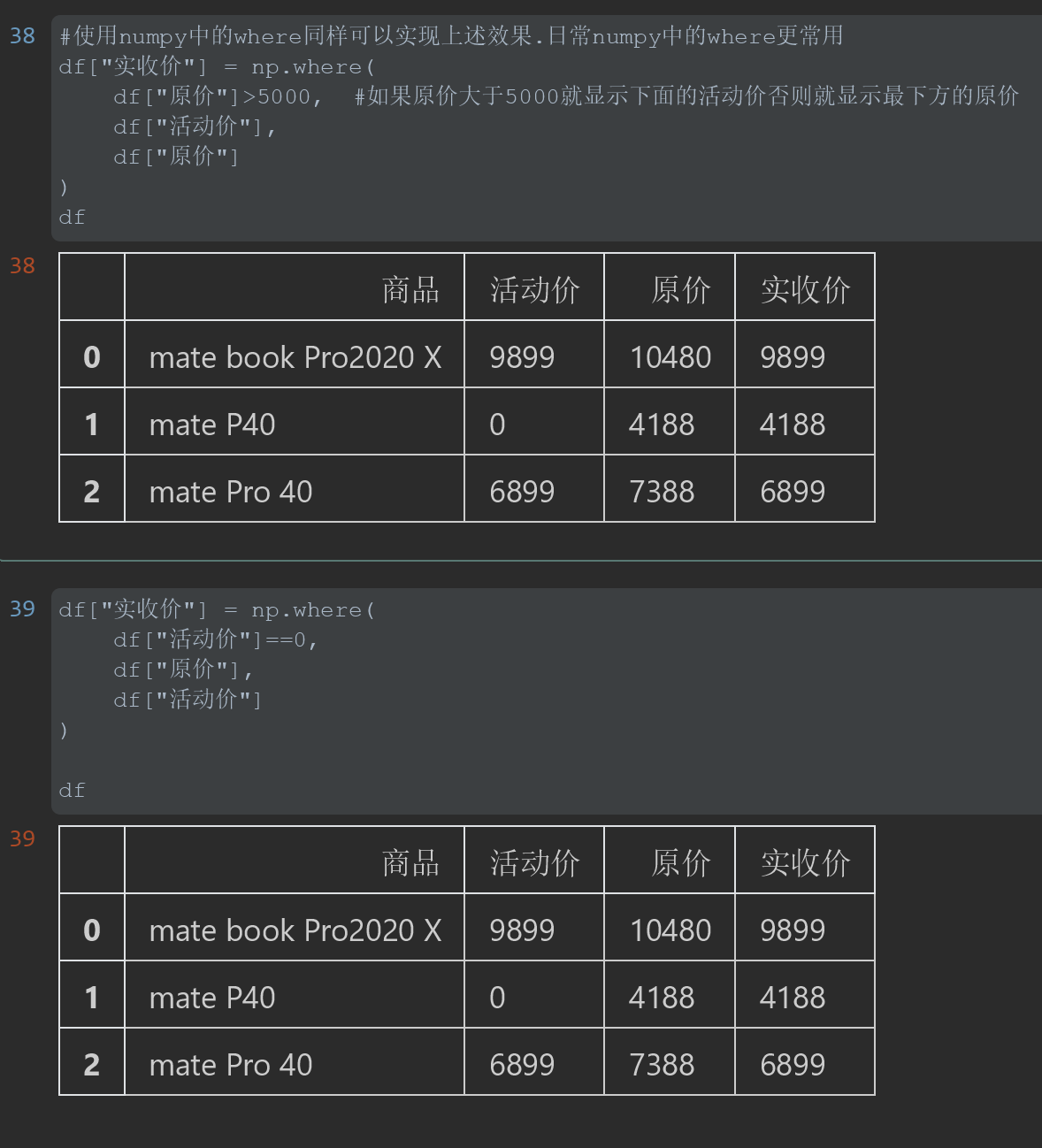
#使用numpy中的where同样可以实现上述效果.日常numpy中的where更常用 df["实收价"] = np.where( df["原价"]>5000, #如果原价大于5000就显示下面的活动价否则就显示最下方的原价 df["活动价"], df["原价"] ) df #%% df["实收价"] = np.where( df["活动价"]==0, df["原价"], df["活动价"] ) df
结果:
3. numpy中where的另一种使用场景
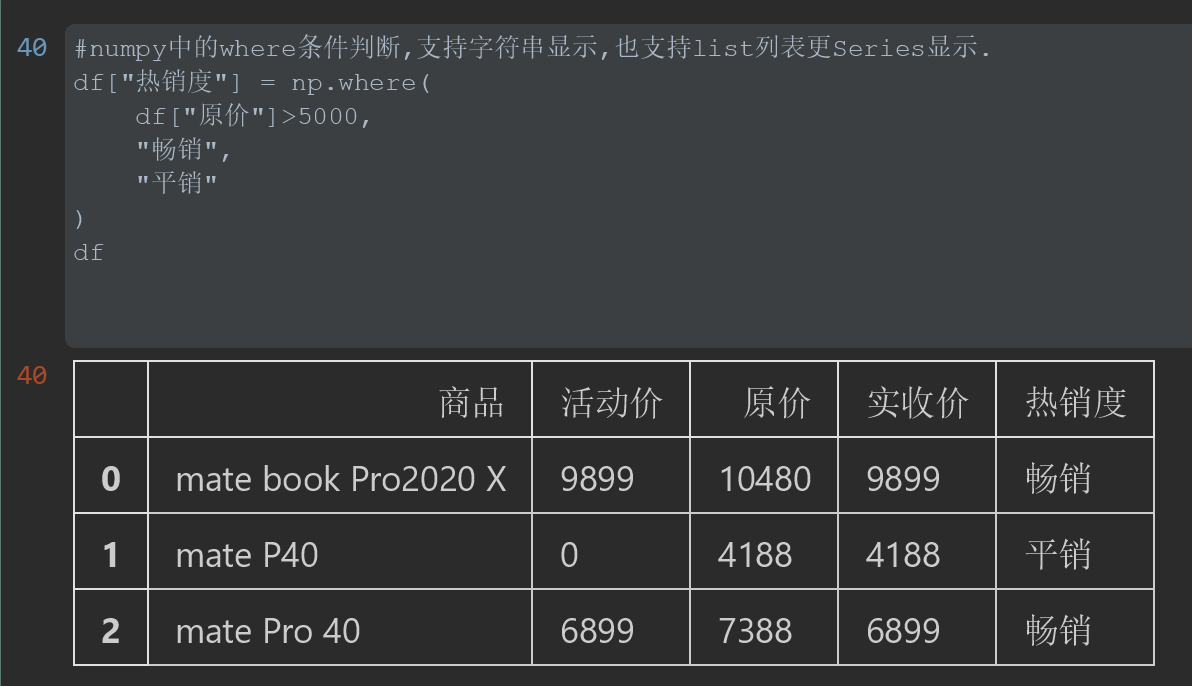
#numpy中的where条件判断,支持字符串显示,也支持list列表更Series显示. df["热销度"] = np.where( df["原价"]>5000, "畅销", "平销" ) df
结果:
二,Cut函数用法
Cut函数的使用,主要是将值做分类到间隔。简单来讲就是对指定的值划分层级,每个值隶属于那个层级就会划分到那里去。
一起来看一下以下的案例就清楚了。
数据源
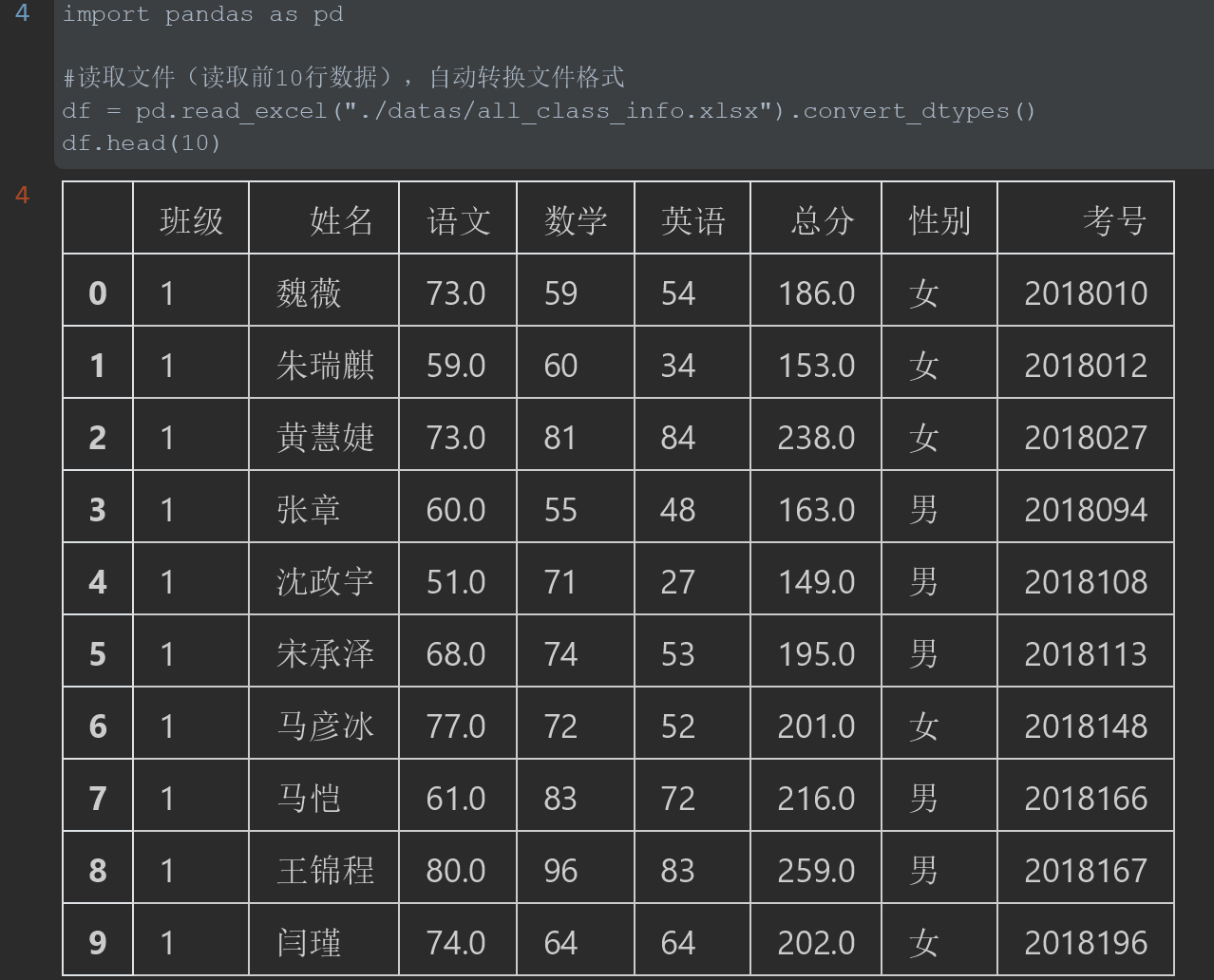
1 import pandas as pd 2 3 #读取文件(读取前10行数据),自动转换文件格式 4 df = pd.read_excel("./datas/all_class_info.xlsx").convert_dtypes() 5 df.head(10)
结果:
1. Cut函数等级划分(指定分数区间精确划分)
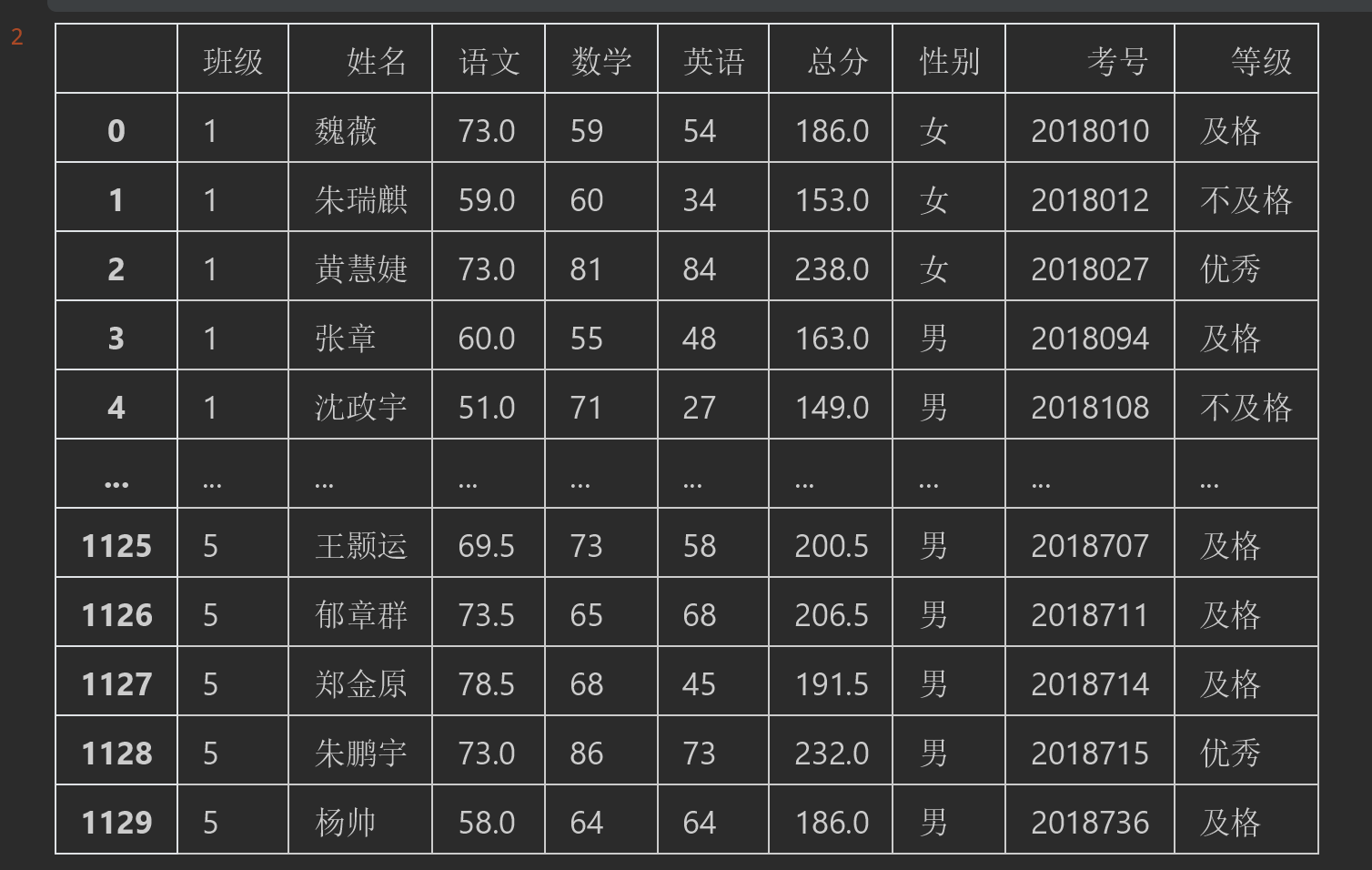
#%% #按照总分划分等级(精确划分) df["等级"] = pd.cut( df["总分"], # 把总分作为判断要素 bins=[0,160,210,300], #bins设置分段.0-160之间代表三门成绩不及格,以此类推 include_lowest=True, #如果为True,如果分数为0也会被包含到不及格.不然显示为None labels=["不及格","及格","优秀"] #对应上述bins设置等级 ) df
结果:
说明:
上述案例主要是通过bins参数指定数值范围,例如0-160对应的是labels中的不及格.160-210对应的是及格,最后210-300对应的是优秀。include_lowest如果为True代表0也会包含到0-160这个区间范围内。如果为False的话则不被包含在内。
2. Cut函数等级划分(模糊划分)
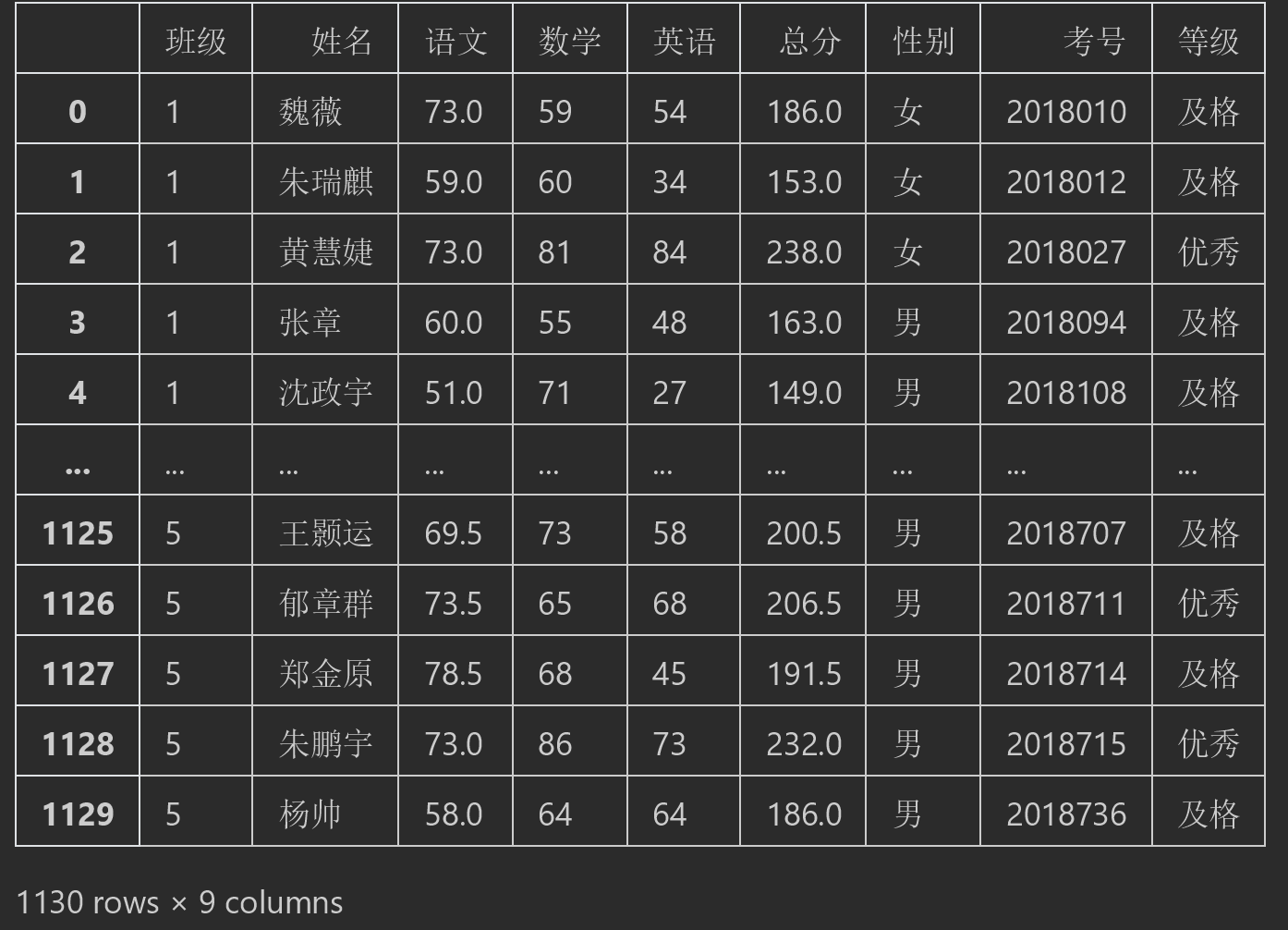
#按照总分划分等级(模糊划分) df["等级"] = pd.cut( df["总分"], # 把总分作为判断要素 bins= 3, #也可以直接给一个int类型.会根据最小到最大值/3来自动分为3个段.这样做算的是均值没有bins指定来的精确 labels=["不及格","及格","优秀"] #对应上述bins设置等级 ) df
结果:
说明:
主要是通过bins这个参数来指定要划分多少个区间。3为总分的平均值。是按照总分的最小值到最大值的1/3来划分的。这样做就没有上述指定每段区间值的范围来的更加精确。
例如:朱瑞麒的成绩加起来平均值明显每门成绩低于60但是依然定义为及格。是因为总分的最大值到最小值进行了1/3平均所导致的。因此如果要精确划分的话建议使用案例1的做法。
如果只是算平均划分的话可以使用案例2。
三,Query函数用法
Query也是对数据进行筛选。之前的章节中提到过掩码的用法。可以通过返回True,False的方式对指定行列进行条件判断,符合条件的则被过滤筛选出来。
Query也可以实现相同的效果。一起来看一下下列的案例演示。
数据源
#%% import pandas as pd df = pd.read_excel("./datas/all_class_info.xlsx").convert_dtypes() df
结果:
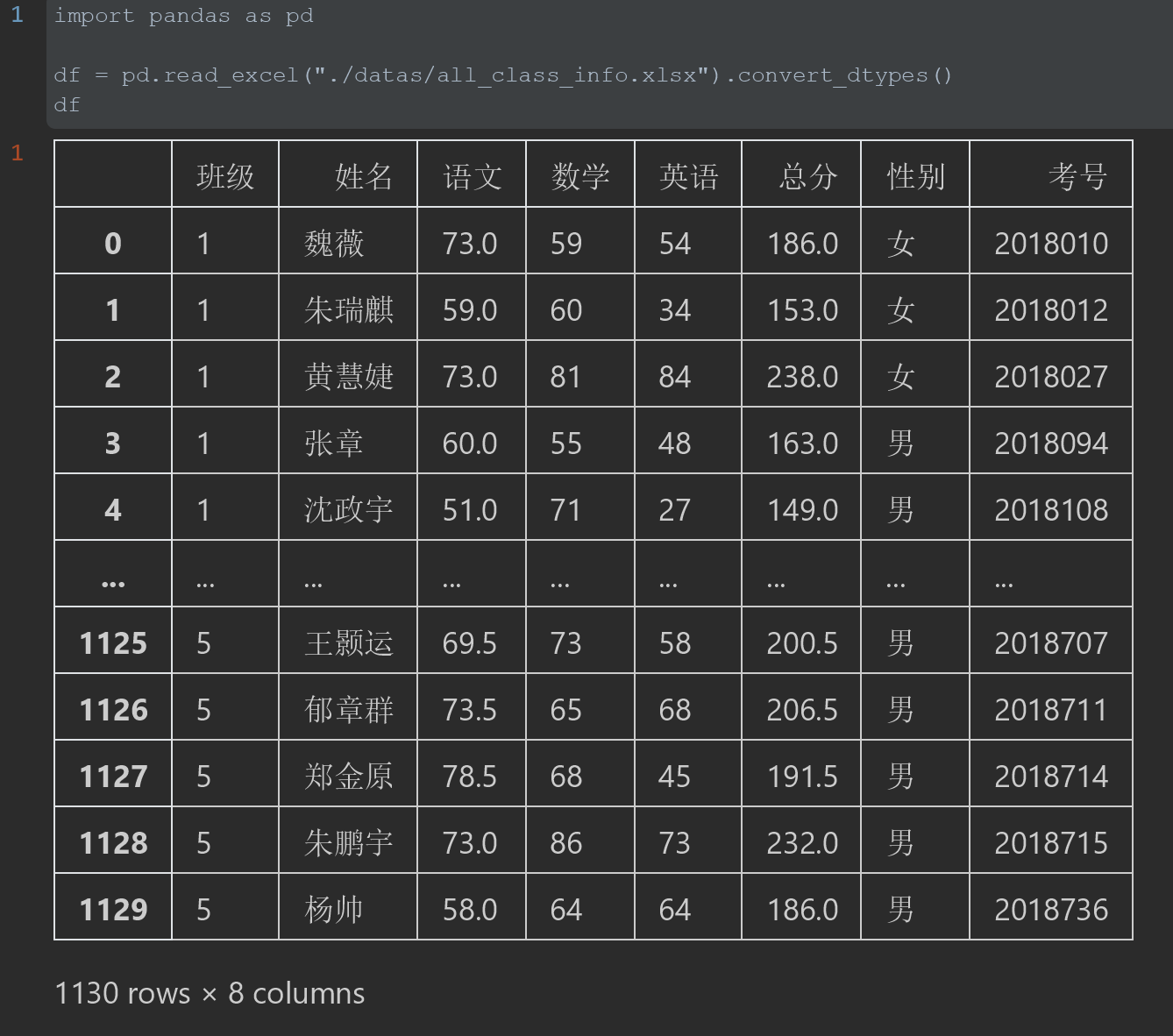
1. 通过掩码的方式,筛选出数学,语文,英语都及格的男生学生信息。
#需求1 #通过掩码提取数学,英语,语文都大于60分的男同学信息 df[(df["数学"]>60)&(df["语文"]>60)&(df["英语"]>60)&(df["性别"]=="男")]
结果:
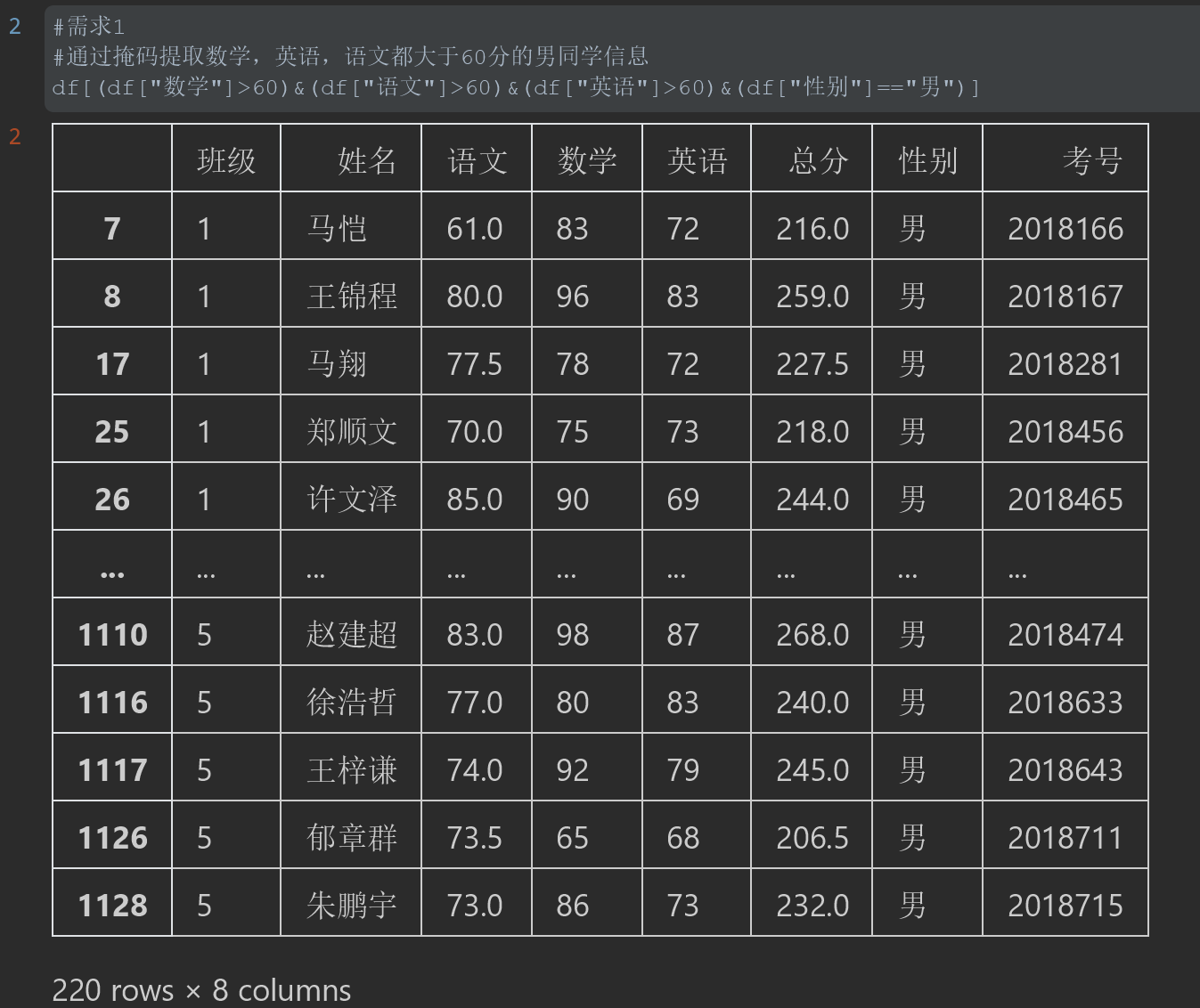
2. 通过Query函数,筛选出数学,语文,英语都及格的男生学生信息。
注意:这里使用了变量赋值的方法。在调用变量时,Query要求在变量前加@符号不然无法识别变量
#%% #需求2 #通过query提取变量的方式,找出数学,语文,英语都大于60的男同学 x=60 #定义变量 y="男" #通过query提取变量做条件判断,提取数据。但是提取变量前必须加@符号。缺点:代码可读性差。优点:结构清晰联动方便 df.query("数学>@x").query("语文>@x").query("英语>@x").query("性别==@y") #df.query("语文>60").query("数学>60").query("英语>60")
结果:
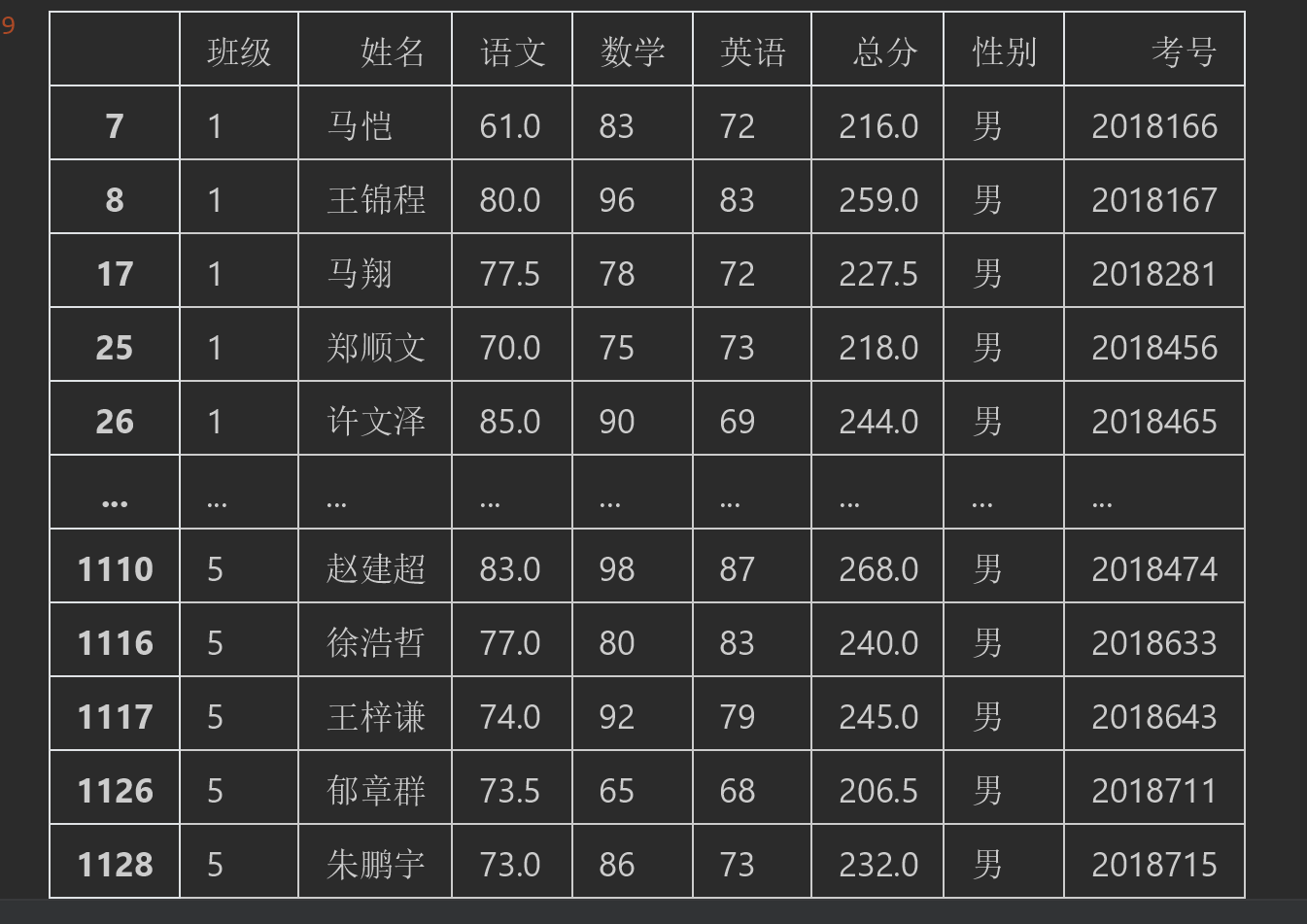
当然也可以变量和条件联合使用例如:
#%% #上述的例子也可以直接通过传入数字和变量的方式联合使用。注意不能直接==字符串.必须先声明才能做判断 y="女" #定义变量 df.query("语文>60").query("数学>60").query("英语>60").query("性别==@y")
结果:

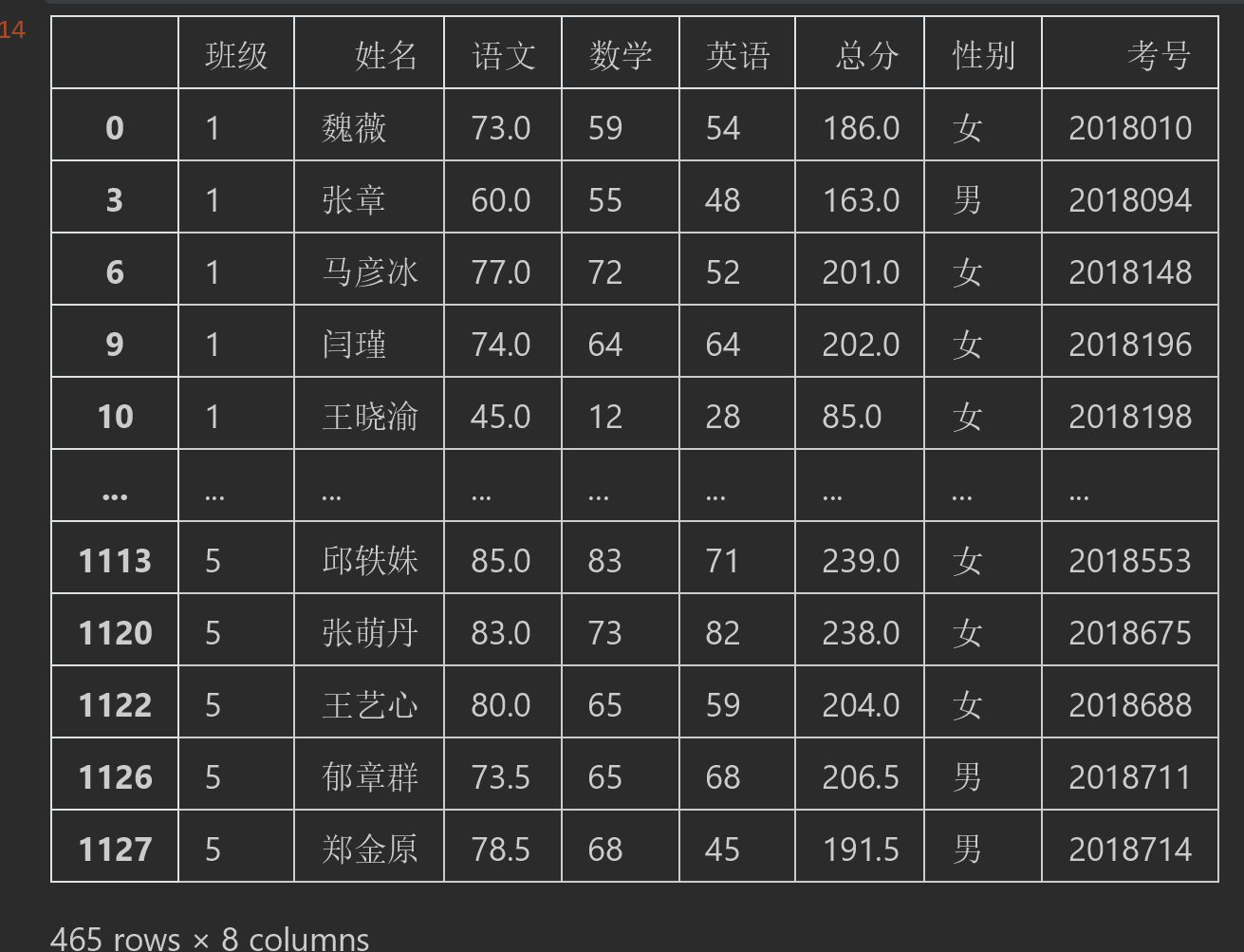
还可以对两列进行直接的对比运算例如
#需求3 #筛选出语文大于英语,同时语文也大于数学成绩的所有行 df.query("语文>英语").query("语文>数学")
结果:
还可以对指定行列进行数值的加减乘除等运算。例如
#%% #总分基础上成10这个通过query做会报错 df["总分"]*10
结果:
四,melt逆透视函数用法
melt逆透视主要是把行数据转换成2列的纵向数据。例如对比下列源数据,使用melt不加任何参数的情况下的数据对比。
源数据
import pandas as pd df = pd.read_excel("./datas/all_class_info.xlsx").convert_dtypes() df.head(3)
结果:
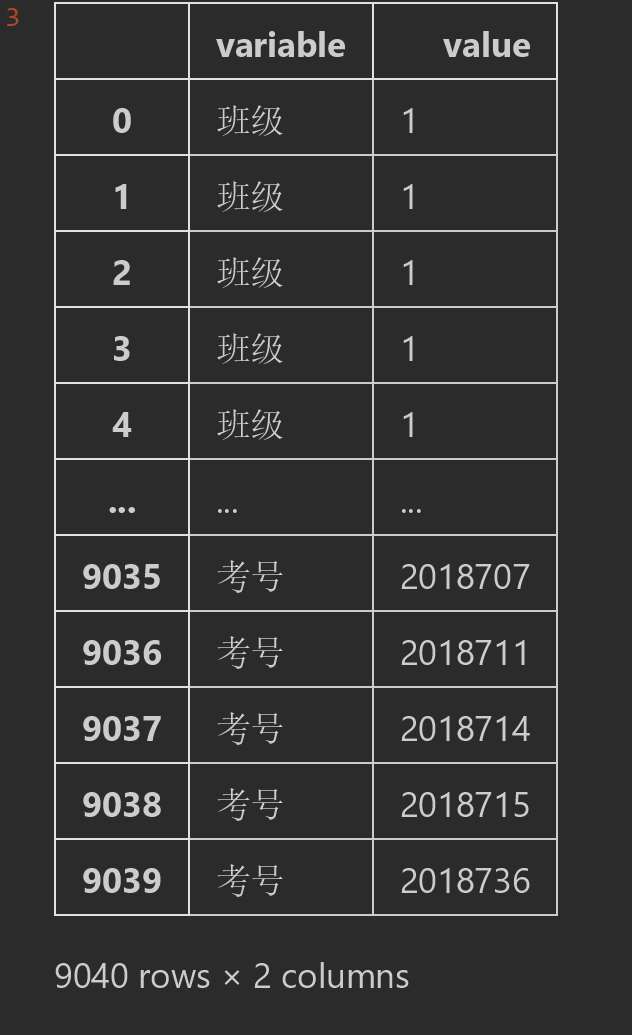
使用melt函数后的数据呈现。它是把横向坐标的列数据转成了纵向坐标的行数据。variable代表之前的列名,value很好理解就是之前的行数据值。
#%% #melt方法如果不加参数直接使用是把行模式的数据转化成列模式的透视格式 df.melt()
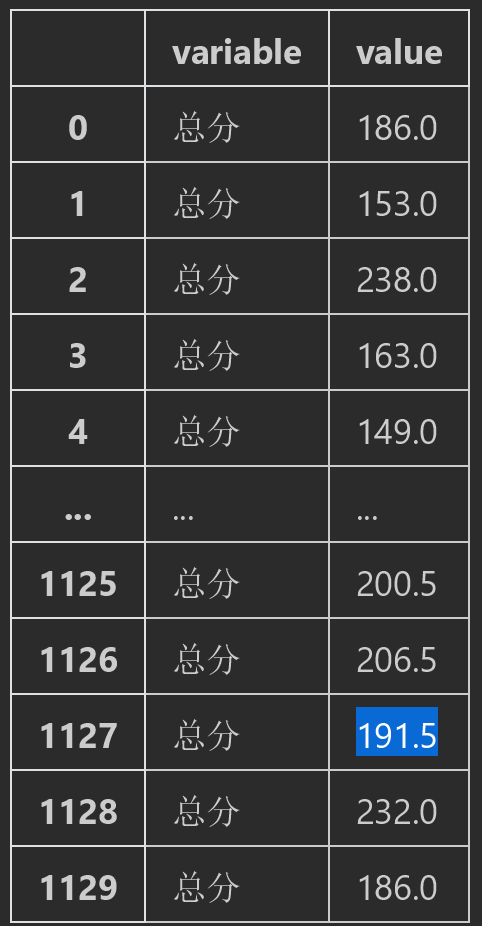
如果想要找出一列。就是筛选出之前的一列数据的话。可以指定value_vars参数指定列名
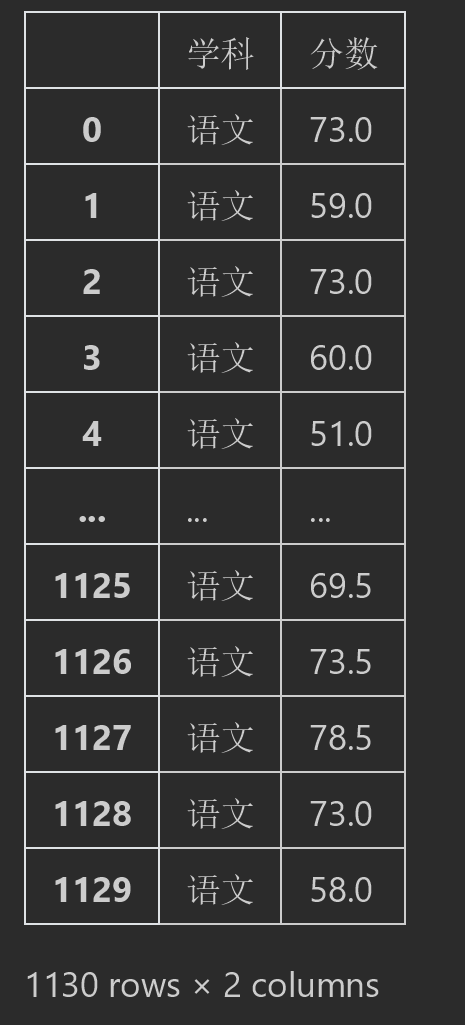
#可以通过指定参数显示value数据 df.melt(ignore_index=False,value_vars="总分")
结果:
melt方法中还有其他的参数。id_vars代表指定某一列为id。value_vars填入指定的数据,可以是字符串也可以是列表。var_name是给默认的variable改名,value_name也一样。代表给value改列名
#%% #同时也支持list多values的传入 df.melt(id_vars="班级", #把班级作为id value_vars=["语文","数学","英语"], var_name="学科", #改列名 value_name="分数") #同样也是改列名
结果:
下面是值定位单个字符串的案例
#单独提取语文成绩的分数 df.melt( value_vars="语文", var_name="学科", value_name="分数" )
结果: