

【Python】Merge函数的用法
Merge函数的用法
简单来说Merge函数相当于Excel中的vlookup函数。当我们对2个表进行数据合并的时候需要通过指定两个表中相同的列作为key,然后通过key匹配到其中要合并在一起的values值。
然后对于merge函数在Pandas中分为1vs1, 多(m)vs1,以及多(m)vs多(m)这三种场景。但是平时用的最多的往往是多vs1的这种场景。也就是说2个表中其中一个表作为key的值会出现重复,而另外一个表作为key的值则是唯一。
这种场景也很好理解。例如:我们在生产环境中对服务器进行管理,一台服务器上可能装了各种各样的软件。那么如果是Excel表格来管理的话一个软件就占用一行信息。而服务器名是相同的。所以一个相同的服务器名就会出现多个。
这台服务器上安装了多少个软件,服务器名就会重复几次,也就是最终有几行。那么另外一个表要想读取这台服务器上安装的所有软件,那么服务器名就要作为key,各个软件的信息则是value值。最终被读取写入的那张表的key只能唯一。
我们看下面这个案例,是真实多v1的案例。为了数据安全我只能把截图分享给大家,并把服务器名遮掩希望大家谅解。
数据表1:作为查询的总表,其中服务器名这列就是B列中的信息会出现重复
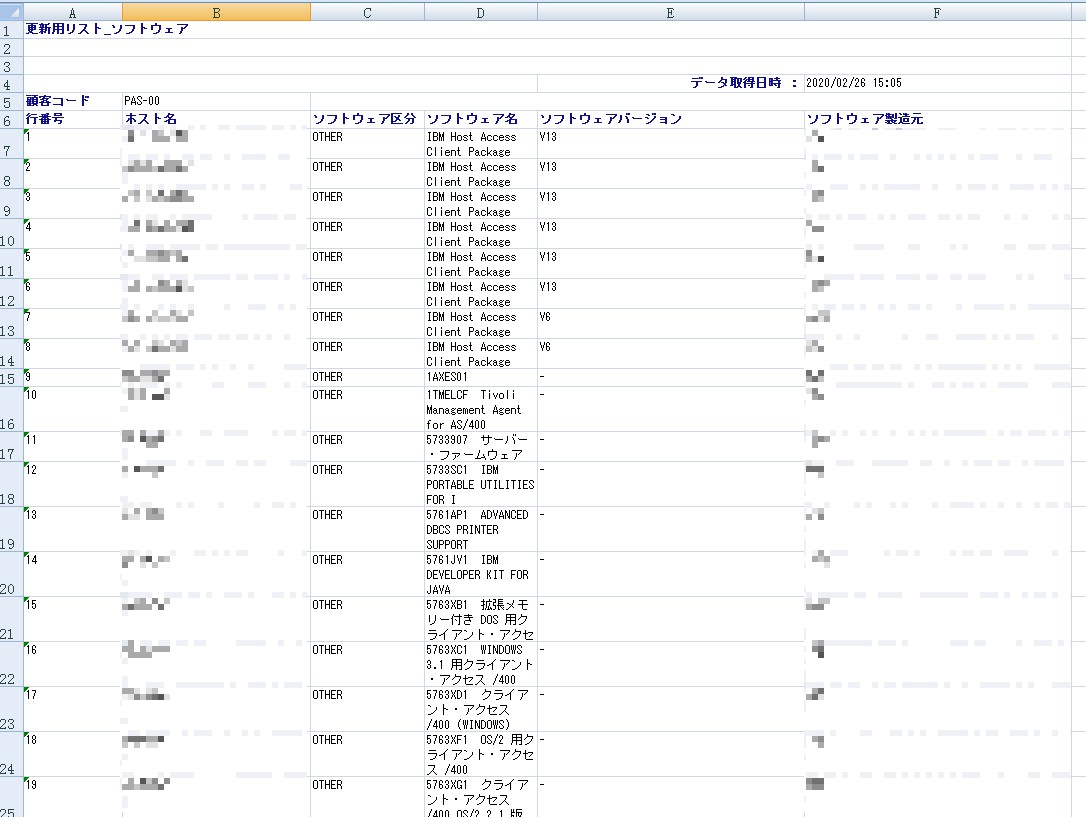
数据表2:下表为按照表1的key就是hostname来匹配,匹配到后按照表2的列名来读取信息写入到表2.这里同上因为服务器名敏感,所以也用马赛克挡住了,忘谅解。
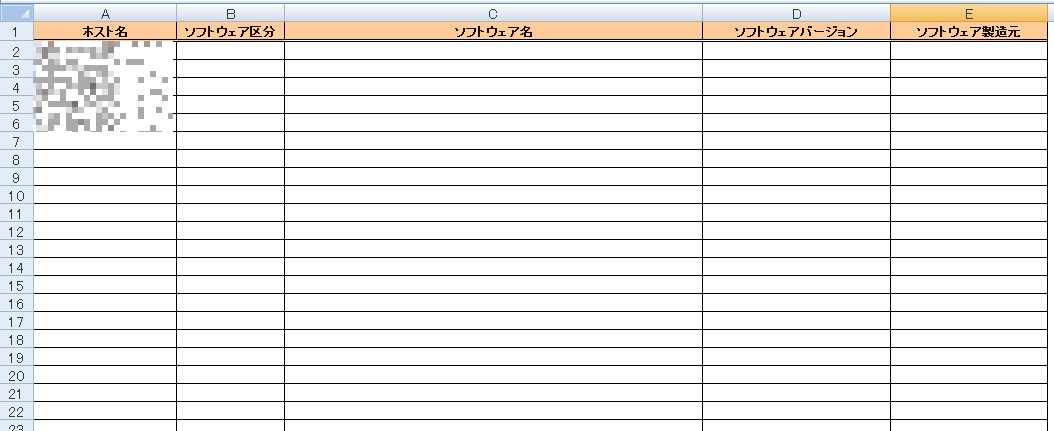
代码演示:
1. 读取表1,表2中的内容,作为DataFrame赋值给变量
#%% import pandas as pd #读取表1 df01 = pd.read_excel("./datas/new_all_datas.xlsx", header=5) df01.head() #%% #读取表2 df02 = pd.read_excel("./datas/new_software_InputSheet.xlsx") df02 #%%
2. 通过merge函数合并两个DataFrame。on代表指明拿什么作为key来进行匹配。how这里分为left,right,inner,outer等方式。这里left代表按照表1为主表进行合并。
#%% #ホスト名作为key来匹配两个表,相当于vlookup函数 #how=left代表以left左表为主,这里则代表表二为左表 df03 = pd.merge(df02,df01,on="ホスト名",how="left") df03
结果:合并结果如下。但是因为表1,表2中出现重复元素的列名,因此合并后Pandas会按照后缀,把相同列名按照_x,_y的方式生成多列。
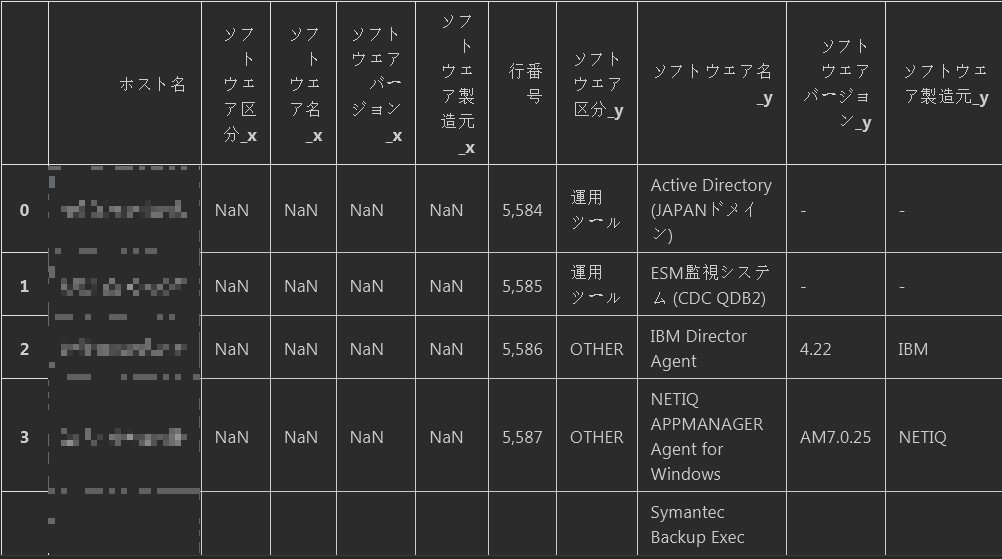
3. 去除没用的列并按照条件查询想要的数据. 下列需求是按照服务器名,找出对应的 "ソフトウェア名"也就是software名为Trend Micro的软件以及"ソフトウェア製造元"software制造商为Symantec的所有行。
#%% #因为表中有相同的列名因此自动后缀被加上了_y #下面代表筛选查询范围,以及指定查询值 df03 = df03.loc[:,["ホスト名","行番号","ソフトウェア区分_y","ソフトウェア名_y","ソフトウェアバージョン_y","ソフトウェア製造元_y"]] df04 = df03[(df03["ソフトウェア名_y"]=="Trend Micro") | (df03["ソフトウェア製造元_y"]=="Symantec")] #重新把列名设定换一下然后输出 df04.columns = ["ホスト名","行番号","ソフトウェア区分","ソフトウェア名","ソフトウェアバージョン","ソフトウェア製造元"] df04
结果:

4. 将数据导出到Excel文件
#%% with pd.ExcelWriter("./datas/output_mergedatas.xlsx") as writer: df04.to_excel(writer,index=False) print("Done!!")
结果:当然也可以直接导入到数据表2中去。我这里为了不破坏原表,因此作为新的Excel表导出了。

大家在日常业务中,如果遇到类似场景可以尝试通过merge函数来合并您的数据。还可以结合loc切片以及写下来要发表的pivot,pivot_table透视表来更加丰富的对数据进行清洗。
总体而言用惯了Pandas后会感觉相比Excel中的函数及宏。Pandas会更加的灵活也更加的强大。
