

elastic-job主要的设计理念是无中心化的分布式定时调度框架,思路来源于Quartz的基于数据库的高可用方案。但数据库没有分布式协调功能,所以在高可用方案的基础上增加了弹性扩容和数据分片的思路,以便于更大限度的利用分布式服务器的资源。
1. 主要功能
a) 分布式:重写Quartz基于数据库的分布式功能,改用Zookeeper实现注册中心。
b) 并行调度:采用任务分片方式实现。将一个任务拆分为n个独立的任务项,由分布式的服务器并行执行各自分配到的分片项。
c) 弹性扩容缩容:将任务拆分为n个任务项后,各个服务器分别执行各自分配到的任务项。一旦有新的服务器加入集群,或现有服务器下线,elastic-job将在保留本次任务执行不变的情况下,下次任务开始前触发任务重分片。
d) 集中管理:采用基于Zookeeper的注册中心,集中管理和协调分布式作业的状态,分配和监听。外部系统可直接根据Zookeeper的数据管理和监控elastic-job。
e) 定制化流程型任务:作业可分为简单和数据流处理两种模式,数据流又分为高吞吐处理模式和顺序性处理模式,其中高吞吐处理模式可以开启足够多的线程快速的处理数据,而顺序性处理模式将每个分片项分配到一个独立线程,用于保证同一分片的顺序性,这点类似于kafka的分区顺序性。
2. 其他功能
a) 失效转移:弹性扩容缩容在下次作业运行前重分片,但本次作业执行的过程中,下线的服务器所分配的作业将不会重新被分配。失效转移功能可以在本次作业运行中用空闲服务器抓取孤儿作业分片执行。同样失效转移功能也会牺牲部分性能。
b) Spring命名空间支持:elastic-job可以不依赖于spring直接运行,但是也提供了自定义的命名空间方便与spring集成。
c) 运维平台:提供web控制台用于管理作业。
3. 非功能需求
a) 稳定性:在服务器无波动的情况下,并不会重新分片;即使服务器有波动,下次分片的结果也会根据服务器IP和作业名称哈希值算出稳定的分片顺序,尽量不做大的变动。
b) 高性能:同一服务器的批量数据处理采用自动切割并多线程并行处理。
c) 灵活性:所有在功能和性能之间的权衡,都可通过配置开启/关闭。如:elastic-job会将作业运行状态的必要信息更新到注册中心。如果作业执行频度很高,会造成大量Zookeeper写操作,而分布式Zookeeper同步数据可能引起网络风暴。因此为了考虑性能问题,可以牺牲一些功能,而换取性能的提升。
d) 幂等性:elastic-job可牺牲部分性能用以保证同一分片项不会同时在两个服务器上运行。
e) 容错性:作业服务器和Zookeeper断开连接则立即停止作业运行,用于防止分片已经重新分配,而脑裂的服务器仍在继续执行,导致重复执行。
实现方案及开发理念
1. elastic-job的具体模块的底层及如何实现
elastic-job采用去中心化设计,主要分为注册中心,数据分片,分布式协调,定时任务处理和定制化流程型任务等模块。
a) 去中心化
去中心化指elastic-job并无调度中心这一概念,每个运行在集群中的作业服务器都是对等的,节点之间通过注册中心进行分布式协调。但elastic-job有主节点的概念,主节点用于处理一些集中式任务,如分片,清理运行时信息等,并无调度功能,定时调度都是由作业服务器自行触发。
b) 注册中心
注册中心模块目前直接使用zookeeper,用于记录作业的配置,服务器信息以及作业运行状态。Zookeeper虽然很成熟,但原理复杂,使用较难,在海量数据支持的情况下也会有性能和网络问题。目前elastic-job已经抽象出注册中心的接口,下一步将会考虑支持多注册中心,如etcd,或由用户自行实现注册中心。无临时节点和监听机制的注册中心需要自行实现定时心跳监测等功能。
c) 数据分片
数据分片是elastic-job中实现分布式的重要概念,将真实数据和逻辑分片对应,用于解耦作业框架和数据的关系。作业框架只负责将分片合理的分配给相关的作业服务器,而作业服务器需要根据所分配的分片匹配数据进行处理。服务器分片目前都存储在注册中心中,各个服务器根据自己的IP地址拉取分片。
d) 分布式协调
分布式协调模块用于处理作业服务器的动态扩容缩容。一旦集群中有服务器发生变化,分布式协调将自动监测并将变化结果通知仍存活的作业服务器。协调时将会涉及主节点选举,重分片等操作。目前使用的Zookeeper的临时节点和监听器实现主动检查和通知功能。
e) 定时任务处理
定时任务处理根据cron表达式定时触发任务,目前有防止任务同时触发,错过任务重出发等功能。主要还是使用Quartz本身的定时调度功能,为了便于控制,每个任务都使用独立的线程池。
f) 定制化流程型任务
定制化流程型任务将定时任务分为多种流程,有不经任何修饰的简单任务;有用于处理数据的fetchData/processData的数据流任务;以后还将增加消息流任务,文件任务,工作流任务等。用户能以插件的形式扩展并贡献代码。
官网地址:
源码解析-主要功能
1、原理
首先贴一张官网的架构设计图片
elastic-job有lite版和cloud版,最大的区别是有无调度中心,一般采用的是lite版本,无中心化。
功能列表有(官网):
- 分布式调度协调
- 弹性扩容缩容
- 失效转移
- 错过执行作业重触发
- 作业分片一致性,保证同一分片在分布式环境中仅一个执行实例
- 支持并行调度
- 支持作业声明周期操作
- 丰富的作业类型
- Spring整合以及命名空间提供
- 运维平台
个人使用和结合网上整理的:
定时任务: 基于成熟的定时任务作业框架Quartz cron表达式执行定时任务。
作业注册中心: 基于Zookeeper和其客户端Curator实现的全局作业注册控制中心。用于注册,控制和协调分布式作业执行。
作业分片: 将一个任务分片成为多个小任务项在多服务器上同时执行。
弹性扩容缩容: 运行中的作业服务器崩溃,或新增加n台作业服务器,作业框架将在下次作业执行前重新分片,不影响当前作业执行。
支持多种作业执行模式: 支持OneOff,Perpetual和SequencePerpetual三种作业模式。
失效转移: 运行中的作业服务器崩溃不会导致重新分片,只会在下次作业启动时分片。启用失效转移功能可以在本次作业执行过程中,监测其他作业服务器空闲,抓取未完成的孤儿分片项执行。
运行时状态收集: 监控作业运行时状态,统计最近一段时间处理的数据成功和失败数量,记录作业上次运行开始时间,结束时间和下次运行时间。
作业停止,恢复和禁用:用于操作作业启停,并可以禁止某作业运行(上线时常用)。
被错过执行的作业重触发:自动记录错过执行的作业,并在上次作业完成后自动触发。可参考Quartz的misfire。
多线程快速处理数据:使用多线程处理抓取到的数据,提升吞吐量。
幂等性:重复作业任务项判定,不重复执行已运行的作业任务项。由于开启幂等性需要监听作业运行状态,对瞬时反复运行的作业对性能有较大影响。
容错处理:作业服务器与Zookeeper服务器通信失败则立即停止作业运行,防止作业注册中心将失效的分片分项配给其他作业服务器,而当前作业服务器仍在执行任务,导致重复执行。
Spring支持:支持spring容器,自定义命名空间,支持占位符。
运维平台:提供运维界面,可以管理作业和注册中心。
结合使用过程中的理解和网上的结论:
a)第一台服务器上线触发主服务器选举。主服务器一旦下线,则重新触发选举,选举过程中阻塞,只有主服务器选举完成,才会执行其他任务。
b)某作业服务器上线时会自动将服务器信息注册到注册中心,下线时会自动更新服务器状态。
c)主节点选举,服务器上下线,分片总数变更均更新重新分片标记。
d)定时任务触发时,如需重新分片,则通过主服务器分片,分片过程中阻塞,分片结束后才可执行任务。如分片过程中主服务器下线,则先选举主服务器,再分片。
e)通过上一项说明可知,为了维持作业运行时的稳定性,运行过程中只会标记分片状态,不会重新分片。分片仅可能发生在下次任务触发前。
f)每次分片都会按服务器IP排序,保证分片结果不会产生较大波动。
g)实现失效转移功能,在某台服务器执行完毕后主动抓取未分配的分片,并且在某台服务器下线后主动寻找可用的服务器执行任务。
源码分析-主要类图
一、大概的类图

二、程序的入口
elastic-job-example\elastic-job-example-lite-java\src\main\java\com\dangdang\ddframe\job\example\JavaMain.java

我们看到这里启动了三种Job,分别是SimpleJob、DataflowJob、ScriptJob,这三种job本质上是不同的,其内部实现采用了3中不同的执行器(稍后说)。
我们先看下setUpSimpleJob

最重要的jobschedule的主要方法如下图:

服务创建好了,就需要启动它,就是JobScheduler.init 方法了

job启动和执行过程
作业启动流程
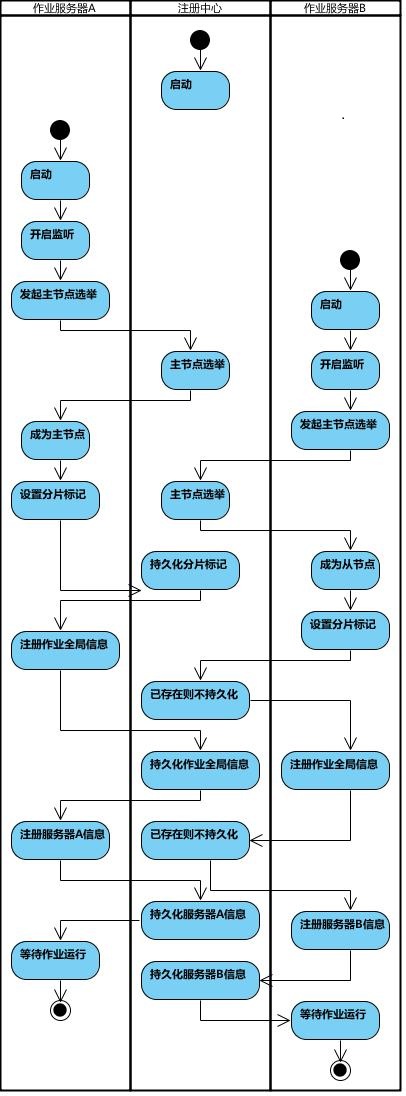
作业执行流程

elastic-job应用实例
一、引入依赖
elastic-job需要一个注册中心

二、配置文件
properties文件

job定义的xml文件:

三、实例代码
simplejob:

dataflowjob:

elastic-job问题答疑
elastic-job页面监控
前面说了那么多,需要一个web工程来直观的展示各个job,elastic-job-console应运而生
一、功能简介
1、添加注册中心

这个web工程是支持多注册中心的,可以对注册中心进行添加、删除操作。
二、任务查看

点击详情,可以看到这个服务器上对应的任务列表等信息

三、切换注册中心
多个注册中心,需要切换的时候

代码如下,console依赖common所以代码有两部分
1、common:elastic-job-common.rar
2、console:elastic-job-lite.rar

