

HashMap数组的长度为什么是16
HashMap中数组的初始长度为16,当出现hash冲突时HashMap利用链表来解决这个问题.当链表长度超过8时,并且桶容量大于等于64时链表转为红黑树,否则优先扩容.
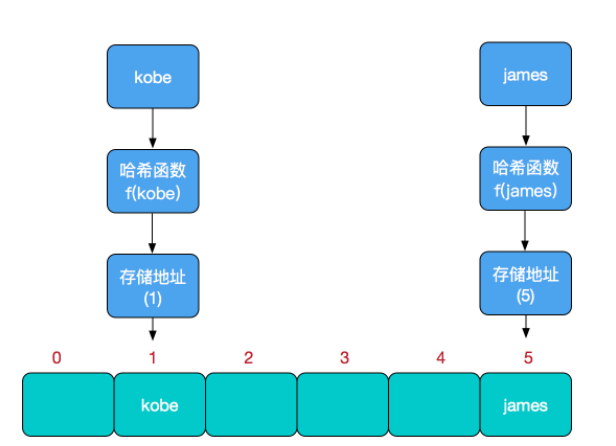
其中的哈希函数决定了整个HashMap的效率,
HashMap中的元素超过长度的百分之75时触发数组扩容.扩大为原来的两倍,扩容非常消耗性能.数组的初始化长度最好为2的幂.
回到标题,
假设张三手写了个HashMap,数组长度为10,前面提到哈希函数采用的是位运算的方式.hash算法的hash计算结果往往取决于HashCode值的最后几位
第一个数计算Hash值

第二个数计算Hash值

第三个数计算Hash值

虽然HashCode的倒数第二第三位从0变成了1,但是运算的结果都是1001。当HashMap长度为10的时候,有些index结果的出现几率会更大,而有些index结果永远不会出现(比如0111)
而长度为2的幂时,Length-1的值是所有二进制位全为1,这种情况下,index的结果完全取决于HashCode后几位的值。只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话