
爬虫课程笔记02

1、re正则解析:开源中国的正则测试学习链接:https://tool.oschina.net/regex#
菜鸟课程的正则:https://www.runoob.com/regexp/regexp-syntax.html

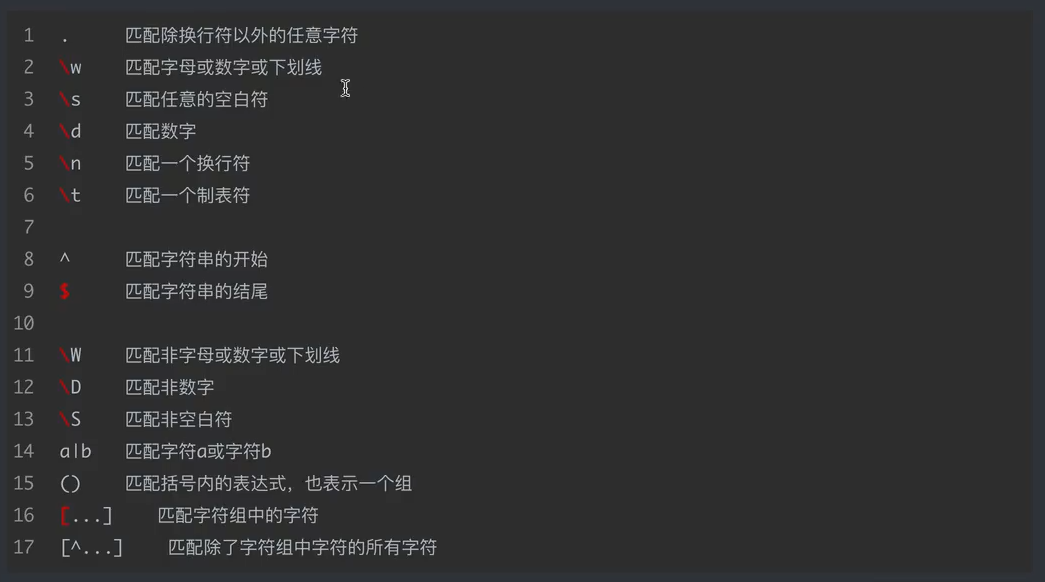

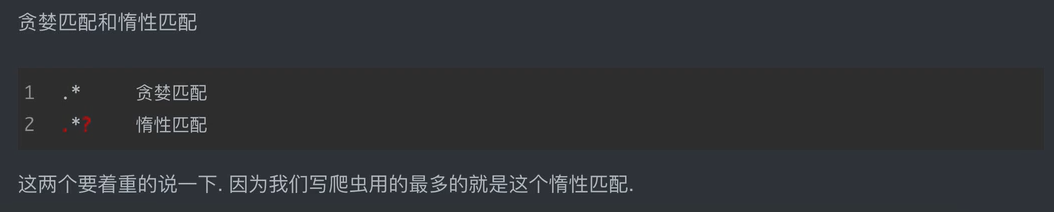
1、re模块在python中的使用
# 导入正则模块
import re
1)findall()查找所有,返回list
# findall:匹配字符串中所有的符合正则的内容 lst = re.findall(r'\d+','我的电话是:10086,我女朋友的电话是:10010') print(lst) # -->['10086', '10010']
2)search()会进行匹配,但是如果匹配到了第一个结果,就会返回这个结果,如果匹配不上search返回的则是None
# search:找到一个结果就返回,返回的结果是match对象,拿数据需要.group() s = re.search(r'\d+','我的电话是:10086,我女朋友的电话是:10010') print(s) # --> <re.Match object; span=(6, 11), match='10086'> print(s.group()) # -->10086
3)match()只能从字符串的开头进行匹配
# match从头开始匹配,与search的不同是search从全文中匹配 # m = re.match(r'\d+','我的电话是:10087,我女朋友的电话是:10010') m = re.match(r'\d+','10087,我女朋友的电话是:10010') print(m.group()) # AttributeError: 'NoneType' object has no attribute 'group'
4)finditer(),和findall差不多,只不过这时候返回的是迭代器(重点)
# finditer:匹配字符串中所有的内容,返回的是迭代器,从迭代器中拿到内容需要使用.group() it = re.finditer(r'\d+','我的电话是:10086,我女朋友的电话是:10010') # print(it) # --><callable_iterator object at 0x000001C7FB2D2E50> for i in it: # print(i) # --><re.Match object; span=(6, 11), match='10086'> <re.Match object; span=(21, 26), match='10010'> print(i.group()) # --> 10086 10010
5)compile()可以将一个长长的正则进行预加载,方便后面的使用
# 预加载正则表达:compile()可以将一个长长的正则进行预加载,方便后面的使用 obj = re.compile(r"\d+") ret = obj.finditer("我的电话是:10086,我女朋友的电话是:10010") print(ret) # --><callable_iterator object at 0x00000138F5DE2DC0> for it in ret: print(it.group()) # -->10086 10010
6)正则中的内容如何单独提取?单独获取到正则中的具体内容可以给分组起名字

import re s = """ <div class='jay'><span id='1'>宋江</span></div> <div class='jj'><span id='2'>卢俊义</span></div> <div class='jolin'><span id='3'>吴用</span></div> <div class='sylar'><span id='4'>公孙胜</span></div> <div class='tory'><span id='5'>关胜</span></div> """ # 需求单独提取出宋江、卢俊义、吴用等人名 # 使用(?P<分组名字>正则)可以单独从正则匹配的内容中进一步提取内容 obj = re.compile(r"<div class='.*?'><span id='(?P<id>\d)+'>(?P<name>.*?)</span></div>",re.S) # 让.匹配换行符 result = obj.finditer(s) for it in result: print(it.group("name")) print(it.group("id"))
2、BS4:使用bs4爬取数据
1)案例一
# 安装bs4 # pip install bs4 -i 清华源 from bs4 import BeautifulSoup # 1、拿到页面源代码 # 2、使用bs4进行解析,拿到数据 import requests url = 'http://www.xinfadi.com.cn/priceDetail.html' resp = requests.get(url) # print(resp.text) # 解析数据 # 1、把页面源代码交给beautifulSoup进行处理,生成bs4对象,指定:html.parser解析 page = BeautifulSoup(resp.text,"html.parser") # 2、从bs对象中查找数据:find(标签,属性=值) find_all(标签,属性=值) # a = page.find("a",class_="navactive scroll header-avtive") # class是python的关键字,所以要用class_区分 # 上面一行可以演化,可以避免class的出现 a = page.find("a",attrs={"class":"navactive scroll header-avtive"}) print(a) # 拿到所有的行 trs = a.find_all("tr")[1:] for tr in trs: # 每一行 tds = tr.find_all('td') # 拿到每行中所有的td name = tds[0].text # .text表示拿到被标签标记的内容 low = tds[1].text # .text表示拿到被标签标记的内容 avg = tds[2].text # .text表示拿到被标签标记的内容 high = tds[3].text # .text表示拿到被标签标记的内容 gui = tds[4].text # .text表示拿到被标签标记的内容
2)案例二
# 1、拿到主页面的源代码,然后提取到子页面的链接地址,href # 2、通过href拿到子页面的内容,从子页面中找到图片的下载地址:img-->src # 3、下载图片 import requests,time from bs4 import BeautifulSoup url = 'https://www.umei.cc/bizhitupian/diannaobizhi' resp = requests.get(url) resp.encoding = 'utf-8' # 处理乱码 # print(resp.text) # 把源代码交给bs main_page = BeautifulSoup(resp.text,'html.parser') alist = main_page.find('div', class_='swiper-wrapper after').find_all('a') # 把范围第一次缩小 # print(alist) for a in alist: # print(url.replace(url,'https://www.umei.cc/') + a.get('href')) # 直接通过get就可以拿到属性值 href = url.replace(url,'https://www.umei.cc/') + a.get('href') # 拿到子页面的源代码 child_page_resp = requests.get(href) child_page_resp.encoding = 'utf-8' child_page_text = child_page_resp.text # 从子页面中拿到图片的下载路径 child_page = BeautifulSoup(child_page_text,'html.parser') child_div = child_page.find('div', class_='con-hot') img = child_div.find('img') # print(img.get('data-src')) data_src = img.get('data-src') # 下载图片 img_resp = requests.get(data_src) # img_resp.content # 这里拿到的是字节 img_name = data_src.split('/')[-1] # 拿到url中的最后一个/以后的内容 with open('img/'+img_name, mode='wb') as f: f.write(img_resp.content) # 图片内容写入文件 print("over!!",img_name) time.sleep(1) print("all over!!!")
3、使用xpath爬取数据
1)先了解如下图片内容
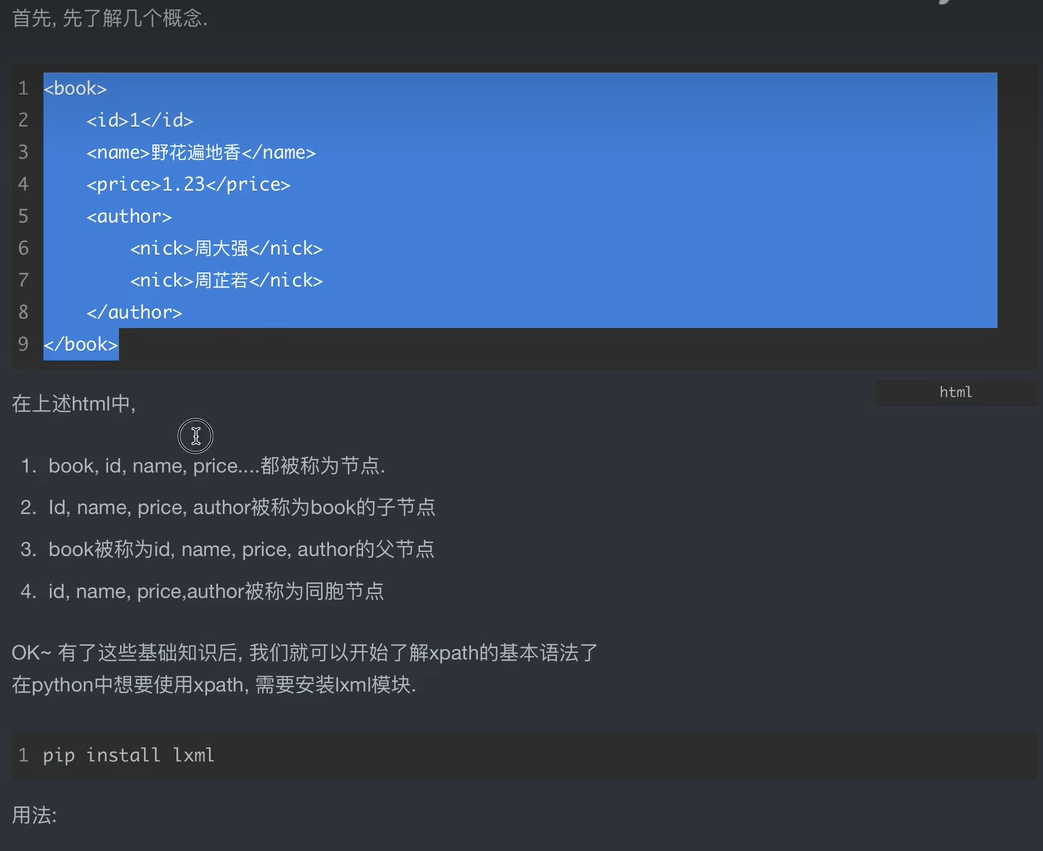
自定义的xml文件
<book> <id>1</id> <name>你好世界</name> <price>1.23</price> <nick>豆腐脑</nick> <author> <nick id=“10086”>周大强</nick> <nick id=“10010”>周芷若</nick> <nick class=“joy”>周杰伦</nick> <nick class=“zhoujie”>周杰</nick> <div> <nick>周通</nick> </div> </author> <partner> <nick id=“songjiang”>宋江</nick> <nick id=“lujunyi”>卢俊义</nick> </partner> </book>


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程
2020-06-29 python中的日志级别