

爬虫课程笔记01



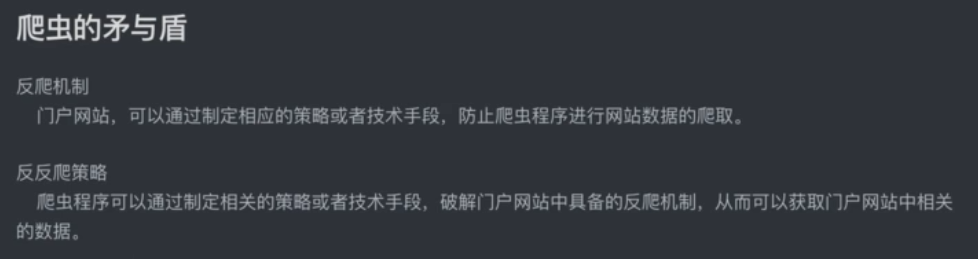
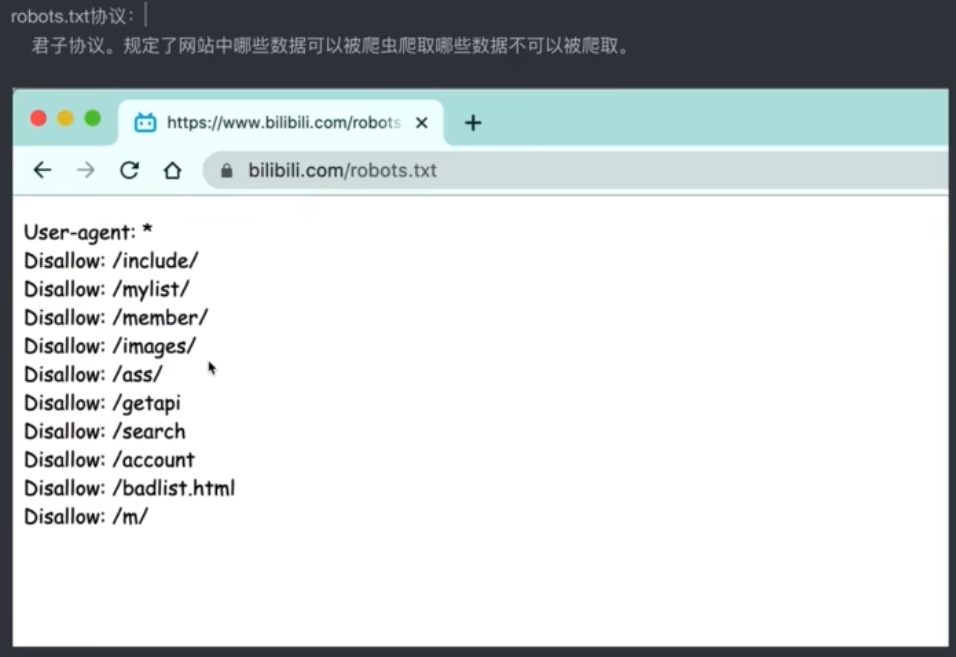
1、第一个爬虫程序

# 爬虫:通过编写程序来获取到互联网上的资源 # 百度 # 需求:用程序模拟浏览器.输入一个网址,从该网址中获取到资源或者内容 # python搞定以上需求 from urllib.request import urlopen # url = 'http://www.baidu.com' url = 'https://www.cnblogs.com/liunaixu/' resp = urlopen(url) with open("files/bokeyuan.html",mode='w',encoding='utf-8') as f: f.write(resp.read().decode()) print('over!')
乱码的解决:decode('utf-8')会造成乱码,所以加入encoding='utf-8'才能解决。
2、web请求过程
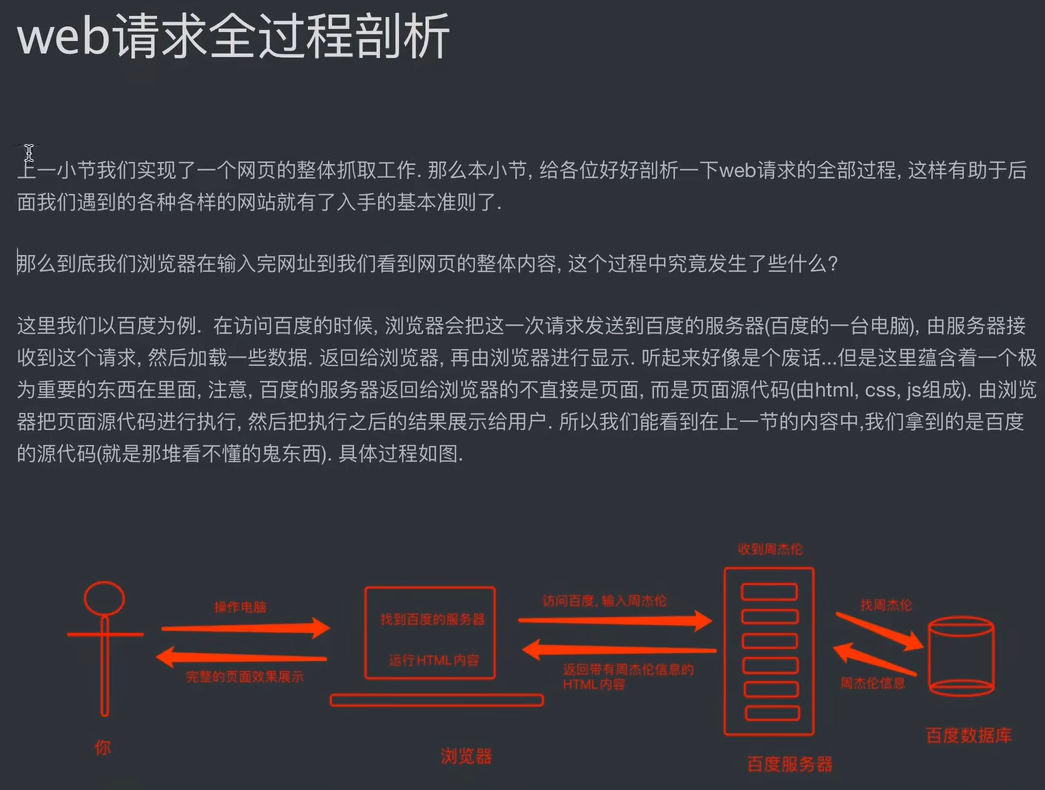
1)服务器渲染:在服务器那边直接把数据和html整合在一起,统一返回给浏览器。 特点:在页面源代码中能看到数据

2)客户端渲染:第一次请求只要一个html骨架,第二次请求拿到数据.进行数据展示。 特点:在页面源代码中,看不到数据。
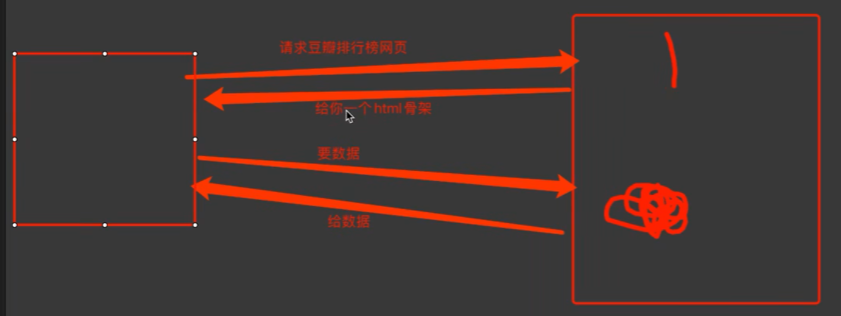
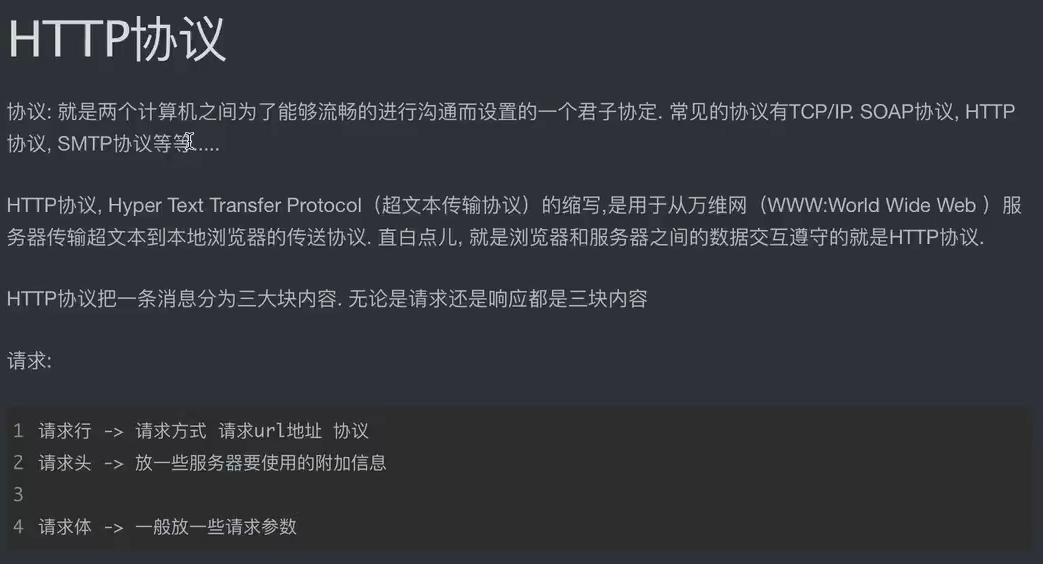
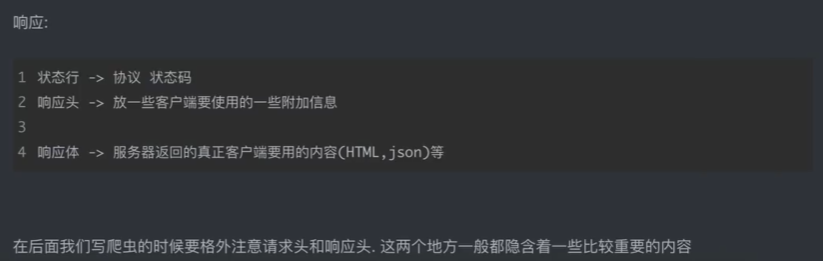
3、http协议

4、requests模块
安装:requests模块
pip install requests
国内网速快的情况下:使用清华源 https://mirrors.tuna.tsinghua.edu.cn/help/pypi/
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
5、get请求
# 使用搜狗浏览器搜索明星的get请求 import requests query = input('请输入一个你喜欢的明星:') url = f'https://www.sogou.com/web?query={query}' # url = 'https://www.sogou.com/web?query=%E5%8D%95%E7%94%B0%E8%8A%B3' dic = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'} resp = requests.get(url,headers=dic) # 处理一个反爬 # resp = requests.get(url) # 处理一个反爬 print(resp) print(resp.text) # 拿到页面源码
执行结果:
请输入一个你喜欢的明星:周杰伦 <Response [200]> ...var oldQuery="周杰伦", ... <a href="http://map.sogou.com/#lq=周杰伦"
... name="query" value="周杰伦"> <input type="hidden"
... 7zOM=_-63072914&htdbg=on">乐坛谁比周杰伦地位高</a>
... 3072914&htdbg=on">周杰伦最好听的10首歌</a> ...
6、post请求
# 使用百度翻译的post请求 import requests url = 'https://fanyi.baidu.com/sug' s = input('请输入你要翻译的英文单词:') dic = {'kw':s} # 发送post请求,发送的数据必须放在字典中,通过data参数进行传递 resp = requests.post(url,data=dic) # print(resp.text) # 会出现乱码 # 将服务器返回的内容直接处理成json的dict格式 print(resp.json())
请输入你要翻译的英文单词:dog
{'errno': 0, 'data': [{'k': 'dog', 'v': 'n. 狗; 蹩脚货; 丑女人; 卑鄙小人 v. 困扰; 跟踪'}, {'k': 'DOG', 'v': 'abbr. Data Output Gate 数据输出门'}, {'k': 'doge', 'v': 'n. 共和国总督'}, {'k': 'dogm', 'v': 'abbr. dogmatic 教条的; 独断的; dogmatism 教条主义; dogmatist'}, {'k': 'Dogo', 'v': '[地名] [马里、尼日尔、乍得] 多戈; [地名] [韩国] 道高'}]}
7、爬虫的步骤
import requests
from time import sleep # 爬虫:豆瓣网》排行榜》喜剧 # 步骤分解 # 1、地址。 url = 'https://movie.douban.com/j/chart/top_list' # 2、参数。当url后面跟着的参数很多时,重新封装参数 param = { 'type': '24', 'interval_id': '100:90', 'action': '', 'start': 0, 'limit': 20 } # 6、修改headers headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36' } # 3、发送请求。7、添加headers resp = requests.get(url=url,params=param,headers=headers) # 输出请求的连接地址,与F12的标头》请求网址一样 # print(resp.request.url) # 4、爬取结果。如果没有打印出任何结果,情况可能是被反爬了.8、爬取结果 # print(resp.text) # 5、分析。尝试查看headers,user-agent的结果是'python-requests/2.24.0' # print(resp.request.headers) # {'User-Agent': 'python-requests/2.24.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'} # 9、json处理 print(resp.json())
# 10、等待5秒后关闭爬取请求
sleep(5)
resp.close()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!