
Python的装饰器
装饰器
1、装饰器的知识点储备

"""
1、*args,**kwargs:形参中的作用汇总:*args是元组形式,**kwargs字典形式
2、*args,**kwargs:实参中的作用展开:
"""
# 一、储备知识
# 1、假设一个应用场景:在调用的时候只能调用wrapper,而wrapper内调的是另外一个函数
# 需求:我们要把传给wrapper的参数原封不动的传给index函数,解决方案如下:
def wrapper(*args,**kwargs): # (1)把*args和**kwargs传给wrapper(*args,**kwargs)
index(*args,**kwargs) # (2)把*args和**kwargs传给index(*args,**kwargs)
wrapper()
举例:
def index(x,y): # (9)考虑传参问题,此时的wrapper传给的(1,2,3,4,5,a=1,b=2)会报错,本身就有2个位置参数,你却给了5个。TypeError: index() takes 2 positional arguments but 5 were given
print(x,y)
def wrapper(*args,**kwargs): # (1)*args和**kwargs是变量名,用来接收值的,(4)汇总 *args(1,2,3,4,5)**kwargs{"a":1,"b":2}
index(*args,**kwargs) # (2)*args和**kwargs,把上面的变量名,传给此处对应的值,(5)打散:*args成为位置实参,**kwargs成为关键字实参。
# (6)此处为实参打散:index(*args(1,2,3,4,5),**kwargs{"a":1,"b":2})
# (7)打散后index(1,2,3,4,5,a=1,b=2)
# (8)总结一下我们可以看到,给wrapper传参最后都传给了index
# wrapper(1,2,3,4,5,a=1,b=2) # (3)传参时候语法不错就行。但要考虑index处的参数,此处会报错:本身就有2个位置参数,你却给了5个。TypeError: index() takes 2 positional arguments but 5 were given
# (10)修改此处的参数,先注销,修改方式一如下
# wrapper(1,2) # (10)修改此处的参数(位置参数),方式一,运行结果:1 2
# wrapper(1,y=2) # (10)修改此处的参数(位置参数和关键字参数,关键字参数一定在位置参数后面),方式二,运行结果: 1 2
wrapper(y=2,x=1) # (10)修改此处的参数(关键字参数),方式三,运行结果: 1 2
# 2、名称空间与作用域:名称空间的“嵌套”关系实在函数定义阶段,即检测语法的时候确定的。
# 名称空间的特点:不同的名称空间内可以存放相同的名称。
# 因为内置命名空间有input这个函数,而函数又是变量
# input = 1 # (3)把input注释
def func():
input = 2
print(input) # (1)验证局部命名空间的值 结果是input=2
func()
print(input) # (2)验证全局命名空间的input值 结果input=1。(4)验证内置命名空间的input值input结果input=<built-in function input>
# 3、函数对象:
# (1)可以把函数当作另一个函数的参数传入。
# (2)可以把函数当作返回值返回。
# 举例:
def index(): # (2)定义第二个函数
return 123
def foo(func): # (1)定义第一个函数
return func # (4)把函数当作返回值返回
foo(index) # (3)把函数当成另一个函数的参数传入,注意index和index()的区别:index是函数的地址值,index()是该函数的运行结果。
res = foo(index)()
print(res) # 123 验证(4)把函数当作返回值返回
# 可以验证index两处的内存地址是否一样?
print(id(index)) # 1942095631840
print(id(foo(index))) # 1942095631840
# 4、函数的嵌套定义:在一个函数内我可以在包一个函数
def outter(func): # (1)定义外层函数 (4)传进一个函数func
def wrapper(): # (2)在外层函数内包一个函数
pass
return wrapper # (3)我们要使用函数对象,这里返回内层函数的内存地址,也就是返回函数。
# 5、闭包函数:闭合在一个函数内
# def wrapper(): # 闭函数:闭合在一个函数内,也就把该块代码缩进到一个函数内。
# pass
# 包函数:在闭函数的基础上,内部函数要访问一个外部的变量,整体把该块代码包裹起来,我们叫闭包函数。
def outter(): # (4)定义外部函数。
x = 1 # (3)定义外部变量。
def wrapper(): # (1)wrapper要访问一个变量。
x # (2)此处的变量是外部给传递的。
return wrapper # (5)在没有被包裹起来之前wrapper属于全局名称空间,包起来后成了局部名称空间的了,\
# 我要还想把wrapper返回到全局名称空间,就要使用return wrapper,把wrapper返回到全局
f = outter() # (6)此处虽然调用的是outter(),但是实质得到的是wrapper 的内存地址。如下图所示:
# 注意:此时的wrapper是不是原来的wrapper呢?
# 此时的f是全局名称空间,f访问outter()函数,而此时得到的wrapper的内存地址。也就是说此时的wrapper已经不是原来的wrapper了
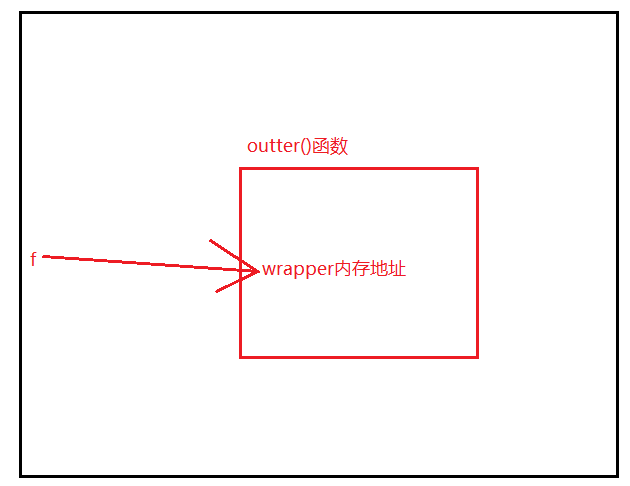
# 思考:当f=outter()后,outter()函数内的x是否被回收了?
# 答:因为wrapper内依然引用x,所以此时f=outter()虽然调用完毕了,但是不能被回收。
# 实例1:
# def f1():
# x=1
# y=2
# z=3
#
# f1() # 当f1()调用完毕后,f1函数内的的x,y,z因为没有被外界引用到,所以x,y,z被python解释器的回收机制回收了
# 实例2:
def f1():
x=1
y=2
z=3
def f2():
print(x)
print(y)
print(z)
f2()
f1() # 此时f1()虽然运行完了,但是f1()里的x,y,z,依然被f2()引用,所以此时x,y,不能被回收。
# 总结:两种传参的方式
# 方式一:通过参数的形式为函数体传值。
# 方式二:通过闭包的方式为函数体传值。
# 方式一:通过参数的形式为函数体传值,实例:
# def wrapper(x): # 此时的x为形参
# print(x)
#
# wrapper(1) # 通过实参的形式为函数体传值。
# wrapper(2)
# wrapper(3)
# 方式二:通过闭包的方式为函数体传值。实例:如果不能使用参数传值,那么我们就要考虑使用闭包函数。
def outter(x): # (4)闭包wrapper函数 (6)为避免把参数写死,把x传给outter(x)
# x = 1 # (1)定义一个参数 (5)为避免把参数写死,注释该处代码
def wrapper(): # (2)定义一个函数wrapper
print(x)
# print(id(wrapper)) # (13)验证id地址结果与print(id(outter(1)))相同
return wrapper # (3)返回该wrapper的内存地址,也就是说是return outter内的wrapper那个函数的内存地址。
# outter(1)# (7)我们要把1这个值传给wrapper函数的函数体。
"""
此时运行了三行代码如下:
x=1 # (1)变量x赋值1
def wrapper(): (2)定义一个函数
print(x)
return wrapper (3)返回wrapper,也就是outter的返回值
"""
# f1 = outter(1) # (8)我把1这个值传给wrapper函数的函数体,返回的wrapper的内存地址传给f1。
# f2 = outter(2)
# f3 = outter(3)
# (9)思考此时的f1可以是任意名称,(名称空间的特点是:不同的名称空间可以有相同的名称),我们可以用wrapper命名
wrapper = outter(1) # (10)此时wrapper是全局名称空间的名字,而outter(1)返回的是局部名称空间的名字也就是wrapper的内存地址
# 也就是说此时的wrapper被偷梁换柱了,表面看到的是调用wrapper闭包前的wrapper,其实是名称相同而已。
# 我们可以通过id()函数验证
# print(id(wrapper)) # (11)验证id地址结果:属于全局名称空间的地址
# print(id(outter(1))) # (12)验证id地址结果与(13)闭包内的print(id(wrapper))相同
wrapper() # (14)得到运行结果 1
方式二实例,如下图所示:

2、装饰器介绍
为何要用装饰器?
软件的设计应该遵循开放封闭原则,即对扩展是开放的,而对修改是封闭的。对扩展开放,意味着有新的需求或变化时,可以对现有代码进行扩展,以适应新的情况。对修改封闭,意味着对象一旦设计完成,就可以独立完成其工作,而不要对其进行修改。
软件包含的所有功能的源代码以及调用方式,都应该避免修改,否则一旦改错,则极有可能产生连锁反应,最终导致程序崩溃,而对于上线后的软件,新需求或者变化又层出不穷,我们必须为程序提供扩展的可能性,这就用到了装饰器。
什么是装饰器?
’装饰’代指为被装饰对象添加新的功能,’器’代指器具/工具,装饰器与被装饰的对象均可以是任意可调用对象。概括地讲,装饰器的作用就是在不修改被装饰对象源代码和调用方式的前提下为被装饰对象添加额外的功能。装饰器经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等应用场景,装饰器是解决这类问题的绝佳设计,有了装饰器,就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。
提示:可调用对象有函数,方法或者类,此处我们单以本章主题函数为例,来介绍函数装饰器,并且被装饰的对象也是函数。
提炼重点:
器:指的是工具,可以定义成函数。
装饰:指的是为其他事务添加额外的东西点缀。
装饰器:
装饰器:可以定义一个函数,但是该函数是用来为其他函数增加额外的功能。
开放封闭原则
开放:指的是对拓展功能是开放的。(在源代码不动的基础上增加功能)
封闭:指的是对修改原代码是封闭的。(思考场景:当用户正用我的软件时候我要拓展功能,不能终止用户的运行)
装饰器的总结:在原代码不动的情况下为其添加新功能。
也就是在不修改被装饰器对象的源代码和不修改调用方式的前提下,为被装饰对象添加新功能
三层结构
应用程序
linux
硬件
所以线上运行的软件不能随意修改,
3、 装饰器的实现:
装饰器=函数嵌套+闭包+函数对象
# 介绍时间模块 import time()
# 打印时间:自1970年1月1日00时00分00秒计算,单位是秒(unix系统元年1970年,我们用的所有系统都是基于unix系统的)
# print(time.time()) # 1585814242.7567132 - 1585814141.1479957
# 装饰器的实现
# def index(x,y):
# print("index %s %s" %(x,y))
#
# index(111,222) # 位置传参 index 111 222
# index(111,y=222) # 位置传参和关键字传参,注意关键字参数要在后面 index 111 222
# index(y=222,x=111) # 关键字传参 index 111 222
# 源代码
import time # 导入时间模块
def index(x,y):
time.sleep(2) # 拖延时间
print("index %s %s" %(x,y))
index(111,222)
# 需求:在不修改index函数的源代码以及调用方式的前提下,为index函数添加一个新的功能,就是统计index函数的运行时间。
# 解决方案一:失败
# 失败原因:没有修改被装饰对象的调用方式,但是修改了源代码。而我们的原则是开放封闭原则。
# import time # 导入时间
# def index(x,y):
# start = time.time() # 开始时间
# time.sleep(3)
# print("index %s %s"%(x,y))
# stop = time.time() # 结束时间
# print(stop - start) # 时间差
# index(1,2) # 运行结果: index 1 2 3.000020980834961 这里没有修改调用方式
# 解决方案二:失败
# 失败原因:虽然没有修改源代码和调用方式,但是代码冗余
# import time
# def index(x,y):
# time.sleep(3)
# print("index %s %s"%(x,y))
#
# start = time.time()
# index(1,2)
# stop = time.time()
# print(stop - start)
# 运行结果: index 1 2 3.000020980834961
# 上述方法看似合理,没有修改源代码,加上了新功能,但是,如果有一百万个地方都要用到这个功能呢?都加上,就造成了代码冗余。如下所示:
import time
def index(x,y):
time.sleep(3)
print("index %s %s"%(x,y))
# 冗余一:没有修改源代,也没有修改代码的调用方式
start = time.time()
index(1,2)
stop = time.time()
print(stop - start)
# 冗余二
start = time.time()
index(3,4)
stop = time.time()
print(stop - start)
# 冗余三
start = time.time()
index(5,6)
stop = time.time()
print(stop - start)
....
# 冗余一百万,这是个什么玩意儿啊。。。。
# 要解决代码冗余问题。
# 解决方案三:失败
# 失败原因:虽然解决了二的代码冗余问题。但是带来一个新的问题
# 优点:源代码没有修改,
# 缺点:1、调用方式改变了。2、参数写死了。
# import time
# def index(x,y):
# time.sleep(3)
# print("index %s %s"%(x,y))
# def wrapper(): # (1)定义装饰器,解决了冗余问题
# start = time.time()
# index(1,2) # (2)被装饰对象是index() 调用方式改了,并且此处的参数写死了
# stop = time.time()
# print(stop - start)
#
# wrapper() # (3)运行结果: index 1 2 3.000020 980834961
# 方案三的优化1:解决index内的参数写死的问题。
import time
def index(x,y):
time.sleep(2)
print("index %s %s"%(x,y))
def wrapper(a,b): # (3)将变量给wrapper(a,b) (5)a=111,b=222
start = time.time()
# index(111,222) # 这块的参数写死了,怎么写活?(1)使用变量a,b
index(a,b) # (2)使用变量a,b (6)index(111,222)
stop = time.time()
print(stop-start)
# wrapper(111,222) # (4)传入实参。111,222
wrapper(333,444) # index 333 444 2.0000224113464355
# 方案三的优化2:在优化1的基础上把被装饰对象index写活了。
# 将index的参数写活了。我要把index(x,y)改成index(x,y,z)呢?使用*args和**kwargs解决
import time
def index(x,y,z):
time.sleep(1)
print("index %s %s %s"%(x,y,z))
def wrapper(*args,**kwargs): # (2)将wrapper(a,b)改为wrapper(*args,**kwargs) (3)形式参数汇总*args(1,),**kwargs{"z":2,"y":3}
start = time.time()
# index(a,b) # (1)将index(a,b)改成index(*args,**kwargs)
index(*args,**kwargs) #(4)形式参数汇总*args(1,),**kwargs{"z":2,"y":3}
stop = time.time()
print(stop-start)
wrapper(1,z=2,y=3) # (3)传入实参 (5)运行结果:index 1 3 2 3.000891923904419...# 方案三的优化3:
# 如果多个函数都想实现wrapper()功能:
"""例如:index1(),index2(),index3(),那么每一个都要使用wrapper()如下
def wrapper(*args,**kwargs):
start = time.time()
index1(*args,**kwargs)
stop = time.time()
print(stop - start)
def wrapper(*args,**kwargs):
start = time.time()
index2(*args,**kwargs)
stop = time.time()
print(stop - start)
def wrapper(*args,**kwargs):
start = time.time()
index3(*args,**kwargs)
stop = time.time()
print(stop - start)
...
"""
# # 这样代码又冗余了,这里的index()也被写死了,如何写活?把index可以换成任意名称
# 先看一下运行流程
import time
def index(x,y,z): #(5)index启动运行,传参时不报错,运行时识别是由有错
time.sleep(1)
print("index %s %s %s"%(x,y,z))
def wrapper(*args,**kwargs): # (3)每一次给wrapper传参其实都是给index传参
start = time.time()
index(*args,**kwargs) # (1)这里的index不能写死。(4)每一次给wrapper传参都是给index传值
stop = time.time()
print(stop-start)
wrapper(111,222,333,444) # (2)传入实参
# 针对上面代码中(1)的index不能写死
# 方案三的优化3:把被装饰对象index写活了
import time
def index(x,y,z):
time.sleep(1)
print("index %s %s %s"%(x,y,z))
# print(index) # (18)查看原名index的内存地址 <function index at 0x000001C1CCF195E0>
def outter(func): # (5)闭包缩进wrapper代码 (9)为把参数写活outter()里传入func (11) func=index的内存地址
# func = index # (3)定义变量名func=index 的内存地址 (8)这里的func也写死了,注释
def wrapper(*args,**kwargs): # (1)先定义这个函数形式参数汇总 *args(1,) **kwargs{"z":3,"y":2}
start = time.time()
# index(*args,**kwargs) # (1)这里的index()被写死了,先注释。
func(*args, **kwargs) # (2)把index名称改成func。 (12)index的内存地址()
stop = time.time()
print(stop - start)
return wrapper # (4) wrapper原本是属于全局的, 会被缩进一个包内,如果还想使用wrapper的内存地址到全局,所以return wrapper的内存地址
# f = outter(index) # (6)先调出outter()拿到wrapper的把内存地址到全局,
# (7)赋值给f,那么f=当初那个wrapper函数的内存地址
# (10)f = outter(index的内存地址),此时的index传给了func。
# f(x=1,y=2,z=3) # (13)运行f()。(14)传入参数f(x=1,y=2,z=3)。得到结果:x=1,y=2,z=3 1.0001122951507568
# (15)总结回顾:上面14步修改了调用方式f(x=1,y=2,z=3),在没有加入装饰的时候我们直接可以使用index(x=1,y=2,z=3)方式,
# 我们加入了装饰虽然没有修改源代码,但是调用方式发生改变了,如何做看似不变?
index = outter(index) # (16)偷梁换柱把(7)(13)中的f换成index,并把(7)(13)注释。
index(x=1,y=2,z=3) # (17)偷梁换柱把f换成index,对于调用者来说,还是index,名称没有变化,但是内存地址变了,使用(18)(19)验证index的内存地址
# print(index) # (19)查看偷梁换柱后的index地址:<function outter.<locals>.wrapper at 0x000001D80B509700>,与(18)作比较说明不是一个地址
# (20)此时index(x=1,y=2,z=3)的调用方式看似没有改变(其实被偷梁换柱改变了内存地址)。
# (21)此时的outter()就是装饰器
# 在方案三的优化3的基础上,需求:要解决多个被装饰对象的调用
import time
def index(x,y,z):
time.sleep(1)
print("index %s %s %s"%(x,y,z))
def home(name): # (1)我定义一个新的函数
time.sleep(1)
print("welcome %s to home page" %name)
def outter(func):
# func = index
def wrapper(*args,**kwargs): #
start = time.time()
func(*args,**kwargs) #
stop = time.time()
print(stop-start)
return wrapper
index = outter(index) # (2)index=wrapper的内存地址
# 需求:我们要调用home
home("lsj") # (3)没有使用装饰器时直接调用
home = outter(home) # (4)# 使用装饰器:此时home=wrapper的内存地址,
# 思考一下此时的index和home都指向了wrapper的内存地址,但是这两个地址是否相同?答:肯定不同。
print("==================")
home(name="lsj") # (5)使用装饰器后传参
运行结果:
welcome lsj to home page
==================
welcome lsj to home page
1.0009613037109375
# 方案三的优化3:装饰器达到的效果:让使用者完全感知不出来有任何变化
import time
def index(x,y,z):
time.sleep(1)
print("index %s %s %s"%(x,y,z))
def home(name):
time.sleep(1)
print("welcome %s to home page" %name)
return 123 # (2)定义home的返回值
def outter(func):
def wrapper(*args,**kwargs): #
start = time.time()
func(*args,**kwargs) # (6)注释
res = func(*args,**kwargs) # (7)把func()的结果赋值给res
stop = time.time()
print(stop-start)
return res # (8) 返回res 此时解决(5)结果是None的问题。总结:加入装饰器跟被装饰对象一摸一样,以假乱真
return wrapper
res = home("lsj") # (1)在不用装饰器的情况下调用home。(3)我们要取得home的返回值 res = home("lsj")
print("在不使用装饰器的情况下调用home得到返回值-->",res) # welcome lsj to home page 返回值--> 123
# (4)使用装饰器后在调用home
home = outter(home) # 回答(5)的问题,偷梁换柱:home这个名字指向的是wrapper函数的内存地址。
res1=home('lsj1') # 回答(5)的问题:res=wrapper('lsj'),看似实在调用home的内存地址,其实是在调用wrapper的内存地址,
# 我们要把wrapper伪装成home:在参数层面上我们已经成功了,但是在返回值上不成功,
# 此时的wrapper返回值是None,所以(5)处返回的None。如何解决?给wrapper加返回值
print("使用装饰器后调用home得到返回值-->",res1) # (5)使用装饰器后调用home得到返回值--> None 这里为啥是空?
# 语法糖:让你开心的语法,可以帮你省事。
import time
# 装饰器。注意装饰器要放在最上面否则报错:NameError: name 'timmer' is not defined
def timmer(func):
# func = xxxx
def wrapper(*args,**kwargs):
start = time.time()
res = func(*args,**kwargs)
stop = time.time()
print(stop - start)
return res
return wrapper
# 在被装饰对象正上方的单独一行写@装饰器名字,可以替代偷梁换柱的功能
@timmer # index = outter(index),如果不想使用装饰器,可以注释掉
def index(x,y,z):
time.sleep(2)
print("index %s %s %s"%(x,y,z))
@timmer # home = outter(home)
def home(name):
time.sleep(2)
print('welcome %s to home page' %name)
return 123
# 偷梁换柱:home这个名字指向wrapper函数的内存地址
# 我们先装饰下index
# index = outter(index)
# 我们装饰一下home
# home = outter(home)
index(x=1,y=2,z=3)
home('lsj')
# 思考题:叠加多个装饰器,加载顺序与运行顺序
@deco1 # index=deco1(deco2.wrapper的内存地址)
@deco2 # deco2.wrapper的内存地址=deco2(deco3.wrapper的内存地址)
@deco3 # deco3.wrapper的内存地址=deco3(index)
def func():
pass
# 一、叠加多个装饰器的加载、运行分析(了解***)
# @deco1 # index=deco1(deco2.wrapper的内存地址)
# @deco2 # deco2.wrapper的内存地址=deco2(deco3.wrapper的内存地址)
# @deco3 # deco.wrapper的内存地址=deco3(index)
# def index():
# pass
def deco1(func1): # func1=wrapper2的内存地址
def wrapper1(*args,**kwargs):
print("第一个装饰器运行:deco1.wrapper")
res1 = func1(*args,**kwargs)
return res1
return wrapper1
def deco2(func2): # func2=wrapper3的内存地址
def wrapper2(*args,**kwargs):
print("第二个装饰器运行:deco2.wrapper")
res2 = func2(*args,**kwargs)
return res2
return wrapper2
def deco3(x):
def outter3(func3): # func3 = 被装饰对象index(x,y)函数的内存地址
def wrapper3(*args,**kwargs):
print("正在运行==>deco3.wrapper3")
res3 = func3(*args,**kwargs)
return res3
return wrapper3
return outter3
# 加载顺序是自下而上运行
@deco1 # 第三步:deco1(index=wrapper2的内存地址) ==> index=wrapper1的内存地址
@deco2 # 第二步:index=deco2(index=wrapper3的内存地址) ==> index=wrapper2的内存地址
@deco3(111) # 第一步:===> @outter3==>index=outter3(index) ==> index=wrapper3的内存地址
def index(x,y):
print("from index %s:%s" % (x,y))
index(1,2) # 不使用语法糖的运行结果:from index 1:2
# 执行顺序:从上到下即:wrapper1-->wrapper2-->wrapper3
# index(1,2) # 第一步:调用wrapper1(1,2)
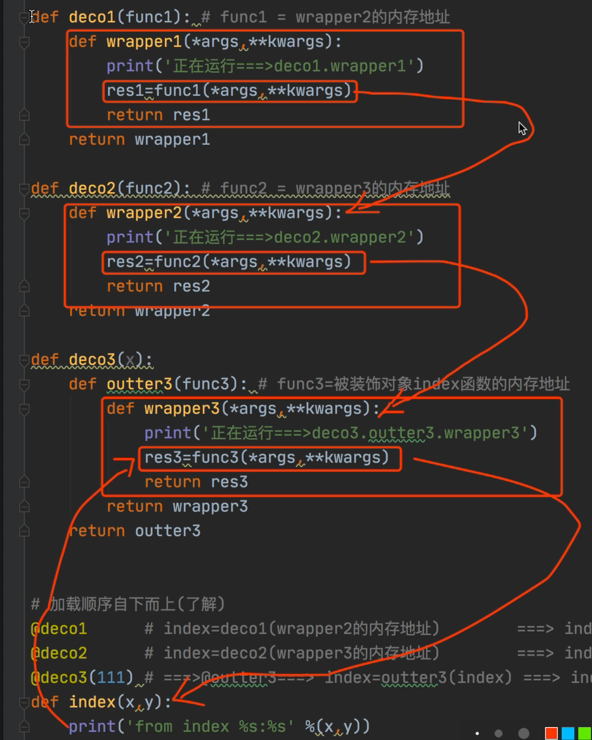
# 运行结果如下:
第一个装饰器运行:deco1.wrapper
第二个装饰器运行:deco2.wrapper
正在运行==>deco3.wrapper3
from index 1:2
# 无参装饰器的基本模板
def outter(func): # 做了啥?拿到wrapper的内存地址
def wrapper(*args,**kwargs): # 作用:1、调用原函数。2、为其加入新的功能。闭包函数指的是wrapper
res = func(*args,**kwargs) # 使用*args,**kwargs把参数写活
return res # 伪装一个返回值=原返回值
return wrapper
# 需求:计算运行时间差的装饰器
import time
def timmer(func): # 做了啥?拿到wrapper的内存地址
def wrapper(*args,**kwargs): # 作用:1、调用原函数。2、为其加入新的功能。
start = time.time()
res = func(*args,**kwargs) #
stop = time.time()
print(stop - start)
return res # 伪装一个返回值=原返回值
return wrapper
@timmer # index = timmer(index)
def index(x):
time.sleep(2)
print("from index %s"%x)
index("lsj")
# 需求:认证功能的装饰器
# (1)先写模板
def auth(func):
def wrapper(*args,**kwargs):
# 1、调用原函数
# 2、为其增加新功能
#(2)调用功能之前验证用户名和密码
name = input("your name>>:").strip()
password = input("your password>>:").strip()
if name == "lsj" and password=="123":
res = func(*args,**kwargs)
return res
else:
print("账号或者密码错误!!!")
return wrapper
@auth #
def index(x):
print("from index %s"%x)
index("lsj")
有参装饰器的实现(其实是在无参的基础上再套一层)
# 有参装饰器的准备知识
# 为函数传参的两种情况:1、直接传参。2、使用闭包(套)传参
# 由于语法糖@ 的限制outter函数只能有一个参数,并且该参数只用来接收被装饰对象的内存地址
def outter(func): # 思考此时的outter参数能不能动?不能动
# func = 被装饰对象函数的内存地址
def wrapper(*args,**kwargs): # 为啥要用套函数?起因是函数体内需要func,而此处不能通过参数传递,所以外边在套一层
res = func(*args,**kwargs)
return res
return wrapper
@outter # index = outter(index) 其实这里的变量名index=wrapper
def index(x,y):
print(x,y)
# 偷梁换柱后
# index的参数是什么样,wrapper的参数就应该是什么样子
# index的返回值是什么样,wrapper的返回值就应该是什么样子
# index的属性是什么样,wrapper的属性就应该是什么样子
# 使用 from functools import wraps
# 山炮一玩法不用语法糖
def auth(func,db_type): # 认证功能的装饰器
def wrapper(*args,**kwargs):
name = input("your name>>>:").strip()
password = input("your password>>:").strip()
if db_type == "flie": # 账号和密码的来源都是文件。需要判断db_type从哪传过来的?
# 从文件中取出账号密码进行验证,但是账号密码可能来自很多地方比如数据库
print("基于文件的验证")
if name == "lsj" and password == "123":
print("基于文件的验证")
print("login successful")
res = func(*args,**kwargs)
return res
else:
print("user or password error")
elif db_type == "mysql":
print("基于mysql的验证")
elif db_type == "ldap":
print("基于ldap的验证")
else:
print("不支持改db_type")
return wrapper
# 假如账号密码来源于文件
def index(x,y):
print("index-->%s:%s"%(x,y))
# 假如账号密码来源于数据库
def home(name):
print("index-->%s"%name)
# 假如账号密码来源于ldap
def transfer():
print("index-->%s")
index = auth(index,"file")
home = auth(home,"mysql")
transfer = auth(transfer,"ldap")
index(1,2)
home("lsj")
transfer()
# 山炮二:不用语法糖
def auth(db_type):
# db_type = "file" # 缩进后注释
def deco(func): # 认证功能的装饰器
def wrapper(*args,**kwargs):
name = input("your name>>>:").strip()
password = input("your password>>:").strip()
if db_type == "file": # 账号和密码的来源都是文件。需要判断db_type从哪传过来的?,这就要用的闭包再包一层
# 从文件中取出账号密码进行验证,但是账号密码可能来自很多地方比如数据库
print("基于文件的验证")
if name == "lsj" and password == "123":
print("基于文件的验证")
print("login successful")
res = func(*args,**kwargs)
return res
else:
print("user or password error")
elif db_type == "mysql":
print("基于mysql的验证")
elif db_type == "ldap":
print("基于ldap的验证")
else:
print("不支持改db_type")
return wrapper
return deco # 返回到全局
deco = auth(db_type="file") # file写死了
@deco # deco = auth(db_type="file")
# @auth # 假如账号密码来源于文件
def index(x,y):
print("index-->%s:%s"%(x,y))
deco = auth(db_type="mysql")
@deco # deco = auth(db_type="file")
# @auth # 假如账号密码来源于数据库
def home(name):
print("index-->%s"%name)
deco = auth(db_type="ldap")
@deco # deco = auth(db_type="file")
# @auth # 假如账号密码来源于ldap
def transfer():
print("transfer")
index(1,2)
home("lsj")
transfer()
# 使用语法糖
def auth(db_type): # 第三层:没有写死
# db_type = "file" # 缩进后注释
def deco(func): # 认证功能的装饰器 # 第二层:已写死
def wrapper(*args,**kwargs): # 第一层:已写死了
name = input("your name>>>:").strip()
password = input("your password>>:").strip()
if db_type == "file": # 账号和密码的来源都是文件。需要判断db_type从哪传过来的?,这就要用的闭包再包一层
# 从文件中取出账号密码进行验证,但是账号密码可能来自很多地方比如数据库
print("基于文件的验证")
if name == "lsj" and password == "123":
print("基于文件的验证")
print("login successful")
res = func(*args,**kwargs)
return res
else:
print("user or password error")
elif db_type == "mysql":
print("基于mysql的验证")
elif db_type == "ldap":
print("基于ldap的验证")
else:
print("不支持改db_type")
return wrapper
return deco # 返回到全局
# deco = auth(db_type="file") # file写死了
# @deco # deco = auth(db_type="file")
@auth(db_type="file") # 假如账号密码来源于文件。@deco-->index=deco(index)-->index=wrapper
def index(x,y):
print("index-->%s:%s"%(x,y))
index(1,2) # wrapper(1,2)
# deco = auth(db_type="mysql")
# @deco # deco = auth(db_type="file")
@auth(db_type="mysql") # 假如账号密码来源于数据库
def home(name):
print("index-->%s"%name)
# deco = auth(db_type="ldap")
# @deco # deco = auth(db_type="file")
@auth(db_type="ldap") # 假如账号密码来源于ldap
def transfer():
print("transfer")
# index(1,2)
# home("lsj")
# transfer()
# 有参装饰器的模板
def 有参装饰器(x,y,z):
def outter(func): # 无参装饰器模板
def wrapper(*args,**kwargs):
res = func(*args,**kwargs)
return res
return wrapper
return outter
@有参装饰器(1,y=2,z=3)
def 被装饰对象():
pass


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程