
Python的数据类型
一、数据类型初识
数据类型的转换操作:
认识%s 是验证String类型数据
%d int
%f float %.2f保留两位小数的浮点型数据
使用type()可以输出其类型
2 是一个整数的例子。
长整数 不过是大一些的整数。
3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。
(-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4为实数,j为虚数,数学中表示复数是什么?。
int(整型)
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
1 或 0
"hello world
python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的+号每出现一次就会在内从中重新开辟一块空间。
字符串格式化输出
|
1
2
3
4
|
name = "alex"print "i am %s " % name #输出: i am alex |
PS: 字符串是 %s;整数 %d;浮点数%f
- 移除空白
- 分割
- 长度
- 索引
- 切片
|
1
2
3
|
name_list = ['alex', 'seven', 'eric']或name_list = list(['alex', 'seven', 'eric']) |
基本操作:
- 索引
- 切片
- 追加
- 删除
- 长度
- 切片
- 循环
- 包含
|
1
2
3
|
ages = (11, 22, 33, 44, 55)或ages = tuple((11, 22, 33, 44, 55)) |
|
1
2
3
|
person = {"name": "mr.wu", 'age': 18}或person = dict({"name": "mr.wu", 'age': 18}) |
常用操作:
- 索引
- 新增
- 删除
- 键、值、键值对
- 循环
- 长度
总结:
集合
主要作用:
- 去重
- 关系测试, 交集\差集\并集\反向(对称)差集
-
1234567891011121314151617181920
>>> a={1,2,3,4}>>> b={3,4,5,6}>>> a{1,2,3,4}>>>type(a)<class'set'>>>> a.symmetric_difference(b){1,2,5,6}>>> b.symmetric_difference(a){1,2,5,6}>>>>>>>>> a.difference(b){1,2}>>> a.union(b){1,2,3,4,5,6}>>> a.issua.issubset( a.issuperset(>>> a.issubset(b)False
元组
只读列表,只有count, index 2 个方法
作用:如果一些数据不想被人修改, 可以存成元组,比如身份证列表
字典
key-value对
- 特性:
- 无顺序
- 去重
- 查询速度快,比列表快多了
- 比list占用内存多
为什么会查询速度会快呢?因为他是hash类型的,那什么是hash呢?
哈希算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。如果散列一段明文而且哪怕只更改该段落的一个字母,随后的哈希都将产生不同的值。要找到散列为同一个值的两个不同的输入,在计算上是不可能的,所以数据的哈希值可以检验数据的完整性。一般用于快速查找和加密算法
dict会把所有的key变成hash 表,然后将这个表进行排序,这样,你通过data[key]去查data字典中一个key的时候,python会先把这个key hash成一个数字,然后拿这个数字到hash表中看没有这个数字, 如果有,拿到这个key在hash表中的索引,拿到这个索引去与此key对应的value的内存地址那取值就可以了。
二、基本数据类型
1、整型:int
(1)整型的作用:用来记录人的年龄,出生年份,学生人数等整数相关的状态。
(2)整型的定义:
age=18 # 本质 age=int(18)
birthday=1990
2、浮点型:(floating point numbers,或者简称为 floats )
(1)浮点型的作用:用来记录人的身高,体重,薪资等小数相关的状态。
(2)浮点型的定义:

# float 浮点型(小数)
# 表达方式一
floatvar = 3.14 # 本质是floatvar=float(3.14)
print(floatvar)
res = type(floatvar)
print(res)
# 表达方式二 (科学计数法)
floatvar = 3.98e3 # 3.98乘以10的3次方(小数点向右移动3位) 结果:3980
floatvar = 3.98e-3 # 3.98乘以10的-3次方(小数点向左移动3位) 结果:0.00398
print(floatvar)
res = type(floatvar)
print(res)
注意:名字+括号的意思就是调用某个功能,比如
# print(...)调用打印功能
# int(...)调用创建整型数据的功能
# float(...)调用创建浮点型数据的功能
数字类型的使用:
(1)算数运算:
a = 1
b = 2
print(a + b)
输出
3
(2)比较大小:
a = 1
b = 2
print(a > b)
输出
False
3、布尔型:bool
(1)布尔型的作用:用来记录真假这两种状态。
(2)布尔型的定义:
>>> is_ok = True
>>> is_ok = False
(3)布尔型的使用:通常用来当作判断的条件,我们将在if判断中用到它。
4、复数:complex
(1)复数的作用:
(2)复数的定义:
complex_num = 3 + 4j # j:科学家定义一个数的平方是-1就说这个数是j
print(complex_num)
5、字符串类型:str
(1)字符串的作用:用来记录人的名字,家庭住址,性别等描述性质的状态。
(2)字符创的定义:
name = "lsj" # 本质:name = str("lsj")
sex = '男' # 本质:sex = str('男')
hobbies = """女""" # 本质:hobbies = str("""女""")
(3)用单引号、双引号、多引号,都可以定义字符串,本质上引号里面存放任意形式的内容这三种形式没有区别的,但是要注意引号的使用。
# 1、需要考虑引号嵌套的配对问题
msg = "My name is lsj , I'm 18 years old!" #内层有单引号,外层就需要用双引号
#2、多引号可以写多行字符串
msg = '''
\'念奴娇。赤壁怀古\'
大江东去,浪淘尽,千古风流人物。
故垒西边,人道是,三国周郎赤壁。
乱石穿空,惊涛拍岸,卷起千堆雪。
江山如画,一时多少豪杰。
遥想公瑾当年,小乔初嫁了,雄姿英发。
羽扇纶巾,谈笑间,樯橹灰飞烟灭。
故国神游,多情应笑我,早生华发
'''
(4)字符串的简单使用
# 字符串也可以进行"相加"和"相乘"运算。
a = "a"
b = "b"
print(a + b) # ab字符串的拼接
c = a * 3
print(c) # 字符串重复
(5)字符串的数据类型转换:str()可以将任意数据类型转换成字符串类型
# 列表转换成字符串:list->str
l = [1,2,3]
print(l,type(l)) # [1, 2, 3] <class 'list'>
l_s = str(l) # list->str
print(l_s,type(l_s)) # [1, 2, 3] <class 'str'>
# 字典转换成字符串:dict->str
d = {"name":"jason","age":18}
print(d,type(d)) # {'name': 'jason', 'age': 18} <class 'dict'>
d_s = str(d)
print(d_s,type(d_s)) # {'name': 'jason', 'age': 18} <class 'str'>
# 元组转换成字符串;tuple->str
t = (1,2,3)
print(t,type(t)) # (1, 2, 3) <class 'tuple'>
t_s = str(t)
print(t_s,type(t_s)) # (1, 2, 3) <class 'str'>
(6)字符串的骚操作
# 字符串的一些操作
# 0123456789101112
# str1 = 'hello python!'
# -12 -1
# 1.按索引取值(正向取,反向取):
# 1.1 正向取值(从左往右)
# z = str1[6]
# print(z,id(z)) # p 34200464
# 1.2 反向取(负号表示从右往左)
# f = str1[-4]
# print(f,id(f)) # h 36862920
# 1.3 对于str来说,只能按照索引取值,不能改其值
# u = str1[0] = 'H' # 我意思是把h改称H
# print(u)
# u = str1[0] = 'H' # 报错TypeError
# TypeError: 'str' object does not support item assignment
# 2.切片(顾头不顾尾,步长)
# 2.1 顾头不顾尾:取出索引为0到8的所有字符
# print(str1[0:9]) # hello pyt
# 2.2 步长:0:9:2,第三个参数2代表步长,会从0开始,每次累加一个2即可,所以会取出索引0、2、4、6、8的字符
# print(str1[0:9:2]) # hlopt
# 2.3 反向切片,-1表示从右往左依次取值
# print(str1[::-1]) # !nohtyp olleh
# 3.长度len
# 3.1 获取字符串的长度,即字符的个数,但凡存在于引号内的都算作字符)
# print(len(str1)) # 空格也算字符 13
# 4.成员运算 in 和 not in
# 4.1 int:判断hello 是否在 str1里面
# print('hello' in str1) # True
# print('hl' in str1) # False 虽然h和l都在str1里面,不是连续的片段
# 4.2 not in:判断lsj 是否不在 str1里面
# print('lsj' not in str1) # True
# 5.strip移除字符串首尾指定的字符(默认移除空格)
# 5.1 括号内不指定字符,默认移除首尾空格
# str2 = ' life is short! '
# print(str2.strip()) # life is short!
# 5.2 括号内指定字符,移除首尾指定的字符
# str3 = '**tony**'
# print(str3.strip('*')) # tony
# 6.切分split
# 6.1 括号内不指定字符,默认以空格作为切分符号
# str4='hello world'
# print(str4.split()) # ['hello', 'world']
# 6.2 括号内指定分隔字符,则按照括号内指定的字符切割字符串
# str5 = '127.0.0.1'
# print(str5.split('.'))
# ['127', '0', '0', '1'] # 注意:split切割得到的结果是列表数据类型
# 7.循环
# str7 = '今天你好吗?'
# print(str7)
# for line in str7: # 依次取出字符串中每一个字符
# print(line)
"""
今
天
你
好
吗
?
"""
(7)重点掌握的字符串的操作
# 1、字符串中关键字strip, lstrip, rstrip操作
str1 = '**lsj***'
print(str1.strip('*')) # 移除左右两边的指定字符
# lsj
print(str1.lstrip('*')) # 只移除左边的指定字符
# lsj***
print(str1.rstrip('*')) # 只移除右边的指定字符
# **lsj
# 2、字符串中关键字lower(),upper()
str2 = 'My nAme is Lsj!'
print(str2.lower()) # 将英文字符串全部变小写
# my name is lsj!
print(str2.upper()) # 将英文字符串全部变大写
# MY NAME IS LSJ!
# 3、字符串中关键字startswith(),endswith()
str3 = 'lsj study python !'
# startswith()判断字符串是否以括号内指定的字符开头,结果为布尔值True或False
print(str3.startswith('l')) # True
print(str3.startswith('j')) # False
# endswith()判断字符串是否以括号内指定的字符结尾,结果为布尔值True或False
print(str3.endswith('on')) # False
print(str3.endswith('!')) # True
# # 4、字符串中关键字split,rsplit,执行后类型由字符串类型转换到列表类型。
# # split会按照从左到右的顺序对字符串进行切分,可以指定切割次数
# str4 = 'C:/a/b/c/d.txt'
# f_g_4 = str4.split('/',1)
# print(type(str4),type(f_g_4),f_g_4) # <class 'str'> <class 'list'> ['C:', 'a/b/c/d.txt']
#
# # rsplit刚好与split相反,从右往左切割,可以指定切割次数
# str5 = 'a|b|c'
# f_g_5 = str5.rsplit('|',1)
# print(type(str5),type(f_g_5),f_g_5) # <class 'str'> <class 'list'> ['a|b', 'c']
# # 5.join # 从可迭代对象中取出多个字符串,然后按照指定的分隔符进行拼接,拼接的结果为字符串
# print('%'.join('hello')) # 从字符串'hello'中取出多个字符串,然后按照%作为分隔符号进行拼接
# # h%e%l%l%o
# print('|'.join(['lsj','18','read'])) # 从列表中取出多个字符串,然后按照|作为分隔符号进行拼接
# # lsj|18|read
# 7.replace# 用新的字符替换字符串中旧的字符
# str7 = 'my name is lsj, my age is 18!' # 将lsj的年龄由18岁改成73岁
# str7 = str7.replace('18', '73') # 语法:replace('旧内容', '新内容')
# print(str7) # my name is lsj, my age is 73!
# 可以指定修改的个数
# str7 = 'my name is lsj, my age is 18!'
# str7 = str7.replace('my', 'MY',1) # 只把一个my改为MY
# print(str7) # 'MY name is lsj, my age is 18!'
# 8.isdigit # 判断字符串是否是纯数字组成,返回结果为True或False
# str8 = '5201314'
# print(str8.isdigit()) # True
# str8 = '123g123'
# print(str8.isdigit()) # False
(8)了解字字符串的操作
# 1.find,rfind,index,rindex,count
# msg = 'lsj say hello'
# 1.1 find:从指定范围内查找子字符串的起始索引,找得到则返回数字1,找不到则返回-1
# print(msg.find('s',1,3)) # 1 在索引为1和2(顾头不顾尾)的字符中查找字符o的索引
# print(msg.find('a',1,3)) # -1
# # 1.2 index:同find,但在找不到时会报错
# msg.index('e',2,4) # 报错ValueError
# msg.index('e',2,4) # 报错ValueError
# ValueError: substring not found
# # 1.3 rfind与rindex:略
# # 1.4 count:统计字符串在大字符串中出现的次数
# msg = "hello everyone"
# print(msg.count('e')) # 统计字符串e出现的次数
# 4
# print(msg.count('e',1,6)) # 字符串e在索引1~5范围内出现的次数
# 1
# # 2.center,ljust,rjust,zfill
name='lsj'
# print(name.center(30,'-')) # 总宽度为30,字符串居中显示,不够用-填充
# -------------lsj-------------
# print(name.ljust(30,'*')) # 总宽度为30,字符串左对齐显示,不够用*填充
# lsj**************************
# print(name.rjust(30,'*')) # 总宽度为30,字符串右对齐显示,不够用*填充
# **************************lsj
# print(name.zfill(50)) # 总宽度为50,字符串右对齐显示,不够用0填充
# 0000000000000000000000000000000000000000000000lsj
# # 3.expandtabs
# name = 'lsj\thello' # \t表示制表符(tab键)
# print(name)
# lsj hello
# print(name.expandtabs(1)) # 修改\t制表符代表的空格数
# lsj hello
# # 4.captalize,swapcase,title
# # 4.1 captalize:首字母大写
# message = 'hello everyone nice to meet you!'
# print(message.capitalize())
# Hello everyone nice to meet you!
# 4.2 swapcase:大小写翻转
# message1 = 'Hi girl, I want make friends with you!'
# print(message1.swapcase())
# hI GIRL, i WANT MAKE FRIENDS WITH YOU!
#4.3 title:每个单词的首字母大写
# msg = 'dear my friend i miss you very much'
# print(msg.title())
# Dear My Friend I Miss You Very Much
# # 5.is数字系列
# #在python3中
num1 = b'4' #bytes
num2 = u'4' #unicode,python3中无需加u就是unicode
num3 = '四' #中文数字
num4 = 'Ⅳ' #罗马数字
#
# #isdigt:bytes,unicode # 判断是否都为数字
# print(num1.isdigit())
# # True
# print(num2.isdigit())
# # True
# print(num3.isdigit())
# # False
# print(num4.isdigit())
# False
# #isdecimal:uncicode(bytes类型无isdecimal方法)
print(num2.isdecimal())
# True
print(num3.isdecimal())
# False
print(num4.isdecimal())
# False
#
# #isnumberic:unicode,中文数字,罗马数字(bytes类型无isnumberic方法)
print(num2.isnumeric())
# True
print(num3.isnumeric())
# True
print(num4.isnumeric())
# True
#
# # 三者不能判断浮点数
num5 = '4.3'
print(num5.isdigit())
# False
print(num5.isdecimal())
# False
print(num5.isnumeric())
# False
# '''
# 总结:
# 最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景
# 如果要判断中文数字或罗马数字,则需要用到isnumeric。
# '''
#
# # 6.is其他
# name = 'tony123'
print(name.isalnum()) #字符串中既可以包含数字也可以包含字母
# True
print(name.isalpha()) #字符串中只包含字母
# False
print(name.isidentifier())
# True
print(name.islower()) # 字符串是否是纯小写
# True
print(name.isupper()) # 字符串是否是纯大写
# False
print(name.isspace()) # 字符串是否全是空格
# False
print(name.istitle()) # 字符串中的单词首字母是否都是大写
# False
6、列表类型:list[]
(1)列表的作用:按位置可以存放多个值,列表类型是用索引来对应值,索引代表的是数据的位置,从0开始计数
(2)列表的定义:
# 定义:在[]内,用逗号分隔开多个任意数据类型的值
l=[1,1.2,'a'] # l=list([1,1.2,'a'])
print(type(l)) # <class 'list'>
# 定义一个空列表
listvar = []
print(listvar, type(listvar)) # [] <class 'list'>
# (1) 定义一个普通的列表
# 正向索引下标 0 1 2 3 4
listvar = [1,3.14,False,3+4j,"你好帅哥"]
# 逆向索引下标 -5 -4 -3 -2 -1
(3)类型转换:但凡能够被for循环遍历的类型都可以当做参数传给list()转成列表,list()会跟for循环一样遍历出数据类型中包含的每一个元素然后放到列表中
# 使用for循环将字符串转转成列表
l = 'hello' r = [] for i in l: print(r.append(i)) print(r) # 使用list()将字符串转转成列表 res=list('hello') print(res,type(res))
# 使用list()将字典转成列表
# res=list({'k1':111,'k2':222,'k3':3333})
# print(res) # ['k1', 'k2', 'k3']
(4)列表的使用:
""" 特点: 可获取,可修改,有序 """ # (2) 获取列表当中的元素 res = listvar[3] # python特点,用下标-1 res = listvar[-1] # 获取列表中最后一个元素(通用写法) # len 获取容器类型数据的总长度(元素总个数) res = len(listvar) max_len = res - 1 print(max_len) # 4 val = listvar[max_len] print(val) # (3) 修改列表当中的元素 listvar[-4] = "太帅了" print(listvar)
(5)列表的内置方法:
# 1、按索引存取值(正向存取+反向存取):即可以取也可以改
# l=[111,'egon','hello']
# 正向取
# print(l[0]) # 111
# 反向取
# print(l[-1]) # hello
#2、 可以取也可以改:索引存在则修改对应的值
l[0]=222
print(l) # [222, 'egon', 'hello']
# 无论是取值操作还是赋值操作:索引不存在则报错
l[3]=333
# l[3]=333
# IndexError: list assignment index out of range
# 2、切片(顾头不顾尾,步长)
l = [111, 'lsj', 'hello', 'a', 'b', 'c', 'd', [1, 2, 3]]
print(l[0:3])
print(l[0:5:2]) # 0 2 4 开始值,结束值,步长
print(l[0:len(l)]) # 从头到尾取值
print(l[:]) # 从头到尾取值
# [111, 'lsj', 'hello', 'a', 'b', 'c', 'd', [1, 2, 3]]
new_l=l[:] # 切片等同于拷贝行为,而且相当于浅copy
print(id(l)) # 34933248
print(id(new_l)) # 34955200
# 浅copy
l = [111, 'lsj', 'hello', 'a', 'b', 'c', 'd', [1, 2, 3]]
l[-1][0]=1111111
print(l)
new_l=l[:]
print(new_l)
# 反向取值
print(l[::-1])
# 赋值操作
msg1='hello:lsj:<>:18[]==123'
print(msg1,id(msg1),type(msg1))
msg2=msg1[:]
print(msg2,id(msg2),type(msg2))
# 3、列表长度
# print(len([1, 2, 3])) # 3
# 4、成员运算in和not in
# print('aaa' in ['aaa', 1, 2]) # True
# print(1 in ['aaa', 1, 2]) # True
# 5、往列表中添加值
# 5.1 追加
l=[111,'lsj','hello']
l.append(3333)
print(l) # [111, 'lsj', 'hello', 3333]
l.append(4444)
print(l) # [111, 'lsj', 'hello', 3333, 4444]
# 5.2、插入值
l=[111,'lsj','hello']
l.insert(0,'alex') # 对索引是0的位置插入一个值
print(l) # ['alex', 111, 'lsj', 'hello']
# 5.3、extend添加值
new_l=[1,2,3]
l=[111,'lsj','hello']
l.append(new_l) # 列表后添加一个新的列表
print(l) # [111, 'lsj', 'hello', [1, 2, 3]]
# for循环代码实现
for item in new_l:
l.append(item)
print(l) # [111, 'lsj', 'hello', 1, 2, 3]
# extend实现了上述代码
l.extend(new_l)
l.extend('abc')
print(l) # [111, 'lsj', 'hello', 1, 2, 3, 'a', 'b', 'c']
# 7、删除
# 方式一:通用的删除方法,只是单纯的删除、没有返回值
# l = [111, 'lsj', 'hello']
# del l[1] # [111, 'hello']
# x =del l[1] # 抛出异常,不支持赋值语法。SyntaxError: invalid syntax
# print(l)
# 方式二:l.pop()根据索引删除,会返回删除的值
# l = [111, 'lsj', 'hello']
# l.pop() # 不指定索引默认删除最后一个
# l.pop()
# print(l)
# 返回删除的值
# res=l.pop(1)
# print(l)
# # 返回删除的值
# print(res)
# 方式三:l.remove()根据元素删除,返回None
# l = [111, 'lsj', [1,2,3],'hello']
# l.remove([1,2,3])
# print(l)
# res=l.remove('lsj')
# print(res) # None
# res=l.remove('l')
# print(res) # 如果所删除的值不存在报错:ValueError: list.remove(x): x not in list
# 8、循环
# l=[1,'aaa','bbb']
# for x in l:
# l.pop(1)
# print(x)
# 需要掌握操作
# l = [1, 'aaa', 'bbb','aaa','aaa']
# 1、l.count() # 根据括号里的参数统计出现的次数
# print(l.count('aaa')) # 3
# 2、l.index() # 根据括号里的参数查找索引值
# print(l.index('aaa')) # 索引位置1
# print(l.index('aaaaaaaaa')) # 找不到报错
# 3、l.clear() # 清空列表,返回[]空列表
# l.clear()
# print(l) # []
# 4、l.reverse():列表倒过来
# l = [1, 'lsj','alex','lxx']
# l.reverse()
# print(l)
# 5、l.sort(): 列表内元素必须是同种类型才可以排序
# l=[11,-3,9,2,3.1]
# l.sort() # 默认从小到大排,称之为升序
# print(l) # [-3, 2, 3.1, 9, 11]
# l.sort(reverse=True) # 从大到小排,设置为降序
# print(l) # [11, 9, 3.1, 2, -3]
# l=[11,'a',12]
# l.sort()
# l=['c','e','a']
# l.sort()
# print(l)
# 了解:字符串可以比大小,按照对应的位置的字符依次pk
# 字符串的大小是按照ASCI码表的先后顺序加以区别,表中排在后面的字符大于前面的
# print('a'>'b') # False
# print('abz'>'abcdefg') # True
# 了解:列表也可以比大小,原理同字符串一样,但是对应位置的元素必须是同种类型
# l1=[1,'abc','zaa']
# l2=[1,'abc','zb']
# print(l1 < l2) # True
# 补充
# 1、队列:FIFO,先进先出
# l=[]
# 入队操作,向列表中追加原始
# l.append('first')
# l.append('second')
# l.append('third')
# print(l) # ['first', 'second', 'third']
# # 出队操作,从列表中删除元素,从索引为0开始
# print(l.pop(0))
# print(l.pop(0))
# print(l.pop(0))
# 2、堆栈:LIFO,后进先出
# l=[]
# # 入栈操作
# l.append('first')
# l.append('second')
# l.append('third')
# print(l) # ['first', 'second', 'third']
# # 出队操作,默认从最后开始删除
# print(l.pop())
# print(l.pop())
# print(l.pop())
7、字典类型:dict{}
(1)字典的作用:(大前提:计算机存取数据是为了能取出来)字典类型是用key:value形式来存储数据,其中key可以对value有描述性的功能
(2)字典的定义:
{}内用逗号分隔开多个key:value,其中value可以使任意类型。key必须是不可变类型,且不能重复,多用字符串可描述性表示
# 1.定义一个字典
dictvar = {"top":"夏侯淳","middle":"安其拉","bottom":"程咬金","jungle":"李白","support":"蔡文姬"}
print(dictvar , type(dictvar))
# 造字典的方式一:
# d={'k1':111,(1,2,3):222} # d=dict(...)
# print(d['k1']) # 111
# print(d[(1,2,3)]) # 222
# print(type(d)) # <class 'dict'>
# d={} # 默认定义出来的是空字典
# print(d,type(d)) # {} <class 'dict'>
# 造字典的方式二:
# d=dict(x=1,y=2,z=3)
# print(d,type(d)) # {'x': 1, 'y': 2, 'z': 3} <class 'dict'>
#3、造字典的方式三:数据类型转换:列表转换成字典
info=[
['name','egon'],
('age',18),
['gender','male']
]
res=dict(info) # 一行代码搞定上述for循环的工作
print(res) # {'name': 'egon', 'age': 18, 'gender': 'male'}
# 使用for循环制造字典
# d={}
# for k,v in info: # k,v=['name','egon'],
# d[k]=v
# print(d) # {'name': 'egon', 'age': 18, 'gender': 'male'}
# 造字典的方式四:快速初始化一个字典
keys=['name','age','gender']
# 使用for循环造字典
d={}
for k in keys:
d[k]=None
print(d) # {'name': None, 'age': None, 'gender': None}
# d={}.fromkeys(keys,None) # 一行代码搞定上述for循环的工作
# print(d) # {'name': None, 'age': None, 'gender': None}
#4、内置方法
#优先掌握的操作:
#1、按key存取值:可存可取
# d={'k1':111}
# print(d) # {'k1': 111}
# 针对赋值操作:key存在,则修改
# d['k1']=222
# print(d) # {'k1': 222}
# 针对赋值操作:key不存在,则创建新值
# d['k2']=3333
# print(d) #{'k1': 111, 'k2': 3333}
#2、长度len
# d={'k1':111,'k2':2222,'k1':3333,'k1':4444}
# print(d) # {'k1': 4444, 'k2': 2222}
# print(len(d)) 2
#3、成员运算in和not in:根据key
# d={'k1':111,'k2':2222}
# print('k1' in d) # True
# print('k1' not in d) # False
# print(111 in d) # False
# print(121 not in d) # True
#4、删除
# d={'k1':111,'k2':2222}
# 4.1 通用删除
# del d['k1']
# print(del d['k1']) # 语法无效:SyntaxError: invalid syntax
# print(d) # {'k2': 2222}
# 4.2 pop删除:根据key删除元素,返回删除key对应的那个value值
# res=d.pop('k2')
# print(d) # {'k1': 111}
# print(res) # 2222
# 4.3 popitem删除:随机删除,返回元组(删除的key,删除的value)
# res=d.popitem()
# print(d) # {'k1': 111}
# print(res) # 返回值是元组('k2', 2222)
#5、键keys(),值values(),键值对items() =>在python3中得到的是老母鸡
# d={'k1':111,'k2':2222}
# 在python2中,所有的key,占用更多空间
# d={'k1':111,'k2':2222}
# print(d.keys()) # dict_keys(['k1', 'k2'])
#6、循环
# k = ['k2', 'k1']
# d.values()
# print(d.values()) # dict_values([111, 2222])
# d.items()
# print(d.items()) # dict_items([('k1', 111), ('k2', 2222)])
# dict(d.items())
# print(dict(d.items())) # {'k2': 2222, 'k1': 111}
#7、for循环
d={'k1':111,'k2':2222}
# for k in d.keys():
# print(k) # k1 k2
#
# for k in d:
# print(k) # k1 k2
# for v in d.values():
# print(v) # 111 2222
# for k,v in d.items():
# print(k,v) # k1 111 k2 2222
# 转换成列表
# print(list(d.keys())) # ['k1', 'k2']
# print(list(d.values())) # [111, 2222]
# print(list(d.items())) # [('k1', 111), ('k2', 2222)]
#需要掌握的内置方法
# d={'k1':111}
#1、d.clear() # 清空,有返回值
# print(d.clear()) # None
# # 上面一行代码可以转换为下面的
# c = d.clear()
# print(c)
#2、d.update() # 更新操作,有则改之,无则加入
# d={'k1':111}
# d.update({'k2':222,'k3':333,'k1':111111111111111})
# print(d)
#3、d.get() :根据key取值,容错性好
# d={'k1':111}
# # print(d['k2']) # key不存在则报错,KeyError: 'k2'
#
# print(d.get('k1')) # 111
# print(d.get('k2')) # key不存在不报错,返回None
#4、d.setdefault()
# info={}
# if 'name' in info:
# ... # 等同于pass
# else:
# info['name']='lsj'
# print(info) # {'name': 'lsj'}
# 4.1 如果key有则不添加,返回字典中key对应的值
# info={'name':'lsj'}
# res=info.setdefault('name','lsj')
# print(info) # {'name': 'lsj'}
#
# print(res) # lsj
# # 4.2 如果key没有则添加,返回字典中key对应的值
# info={}
# res=info.setdefault('name','lsj')
# print(info) # {'name': 'lsj'}
# print(res) # lsj
(3)字典的使用:
# 字典dict
"""
特点:键值对存储的数据,表面上有序,实际上无序
语法: dictvar = {键1:值1,键2:值2,键3:值3 ... }
"""# 2.获取字典当中值
res = dictvar["middle"]
print(res)
# 3.修改字典当中的值
dictvar["bottom"] = "后裔"
print(dictvar)
8、集合类型:set()
(1)集合的作用:(1)去重(有一定的局现性)。(2)关系运算。所谓关系是:交、差、并、补。
(2)集合的定义:在{}内用逗号分隔开多个元素,多个元素满足以下三个条件
1. 集合内元素必须为不可变类型
2. 集合内元素无序
3. 集合内元素没有重复
# 定义一个集合
# s={1,2} # 本质是s=set({1,2})
# print(s)
# 注意1:列表类型是索引对应值,字典是key对应值,均可以取得单个指定的值,
# 而集合类型既没有索引也没有key与值对应,所以无法取得单个的值,
# 而且对于集合来说,主要用于去重与关系元素,根本没有取出单个指定值这种需求。
# 注意2:{}既可以用于定义dict,也可以用于定义集合,但是字典内的元素必须是key:value的格式,
# 现在我们想定义一个空字典和空集合,该如何准确去定义两者?
# 定义空字典
d = {} # 默认是空字典
print(d,type(d)) # {} <class 'dict'>
# 定义空集合
s = set() # 这才是定义空集合
print(s,type(s)) # set() <class 'set'>
# 集合的几个特点:
# 1、集合内元素必须为不可变类型
# 2、集合内元素无序
# 3、集合内元素不能重复,输出的结果会在自动去重
# s={1,[1,2]} # 集合内元素必须为不可变类型,否则报错:TypeError: unhashable type: 'list'
# s={1,'a','z','b',4,7} # 集合内元素无序
# print(s) # {1, 4, 7, 'a', 'z', 'b'}
# s={1,1,1,1,1,1,'a','b'} # 集合内元素没有重复
# print(s) # 得到结果自动去重{1, 'a', 'b'}
# 3、类型转换:但凡能被for循环的遍历的数据类型
# 强调:遍历出的每一个值都必须为不可变类型,都可以传给set()转换成集合类型
# s = set({1,2,3})
# print(s) # {1, 2, 3}
# set():字符串转换成集合
# res=set('hellolllll')
# print(res) # {'o', 'e', 'h', 'l'}
# 集合中的每一个值都必须为不可变类型,否则报错
# print(set([1,1,1,1,1,1])) # {1}
# print(set([1,1,1,1,1,1,[11,222]])) # 报错 TypeError: unhashable type: 'list'
# 使用set()字典转换成集合,得出的结果是字典key的集合
# print(set({'k1':1,'k2':2})) # {'k1', 'k2'}
# 4、内置方法
# =========================关系运算符=========================
# friends1 = {"zero","kevin","jason","egon","lsj"}
# friends2 = {"Jy","ricky","jason","egon","lsj"}
# 4.1 取交集&和intersection()效果同:两者共同的好友
# res = friends1 & friends2
# print(res) # {'jason', 'egon', 'lsj'}
# print(friends1.intersection(friends2)) #{'jason', 'egon', 'lsj'}
# 4.2 取并集/合集,|和union()功能同:两者所有的好友
# print(friends1 | friends2)
# print(friends1.union(friends2))
# {'zero', 'kevin', 'lsj', 'ricky', 'Jy', 'jason', 'egon'}
# 4.3 取差集,-和difference()功能同,但是前后有顺序:取friends1独有的好友
# print(friends1 - friends2) # {'zero', 'kevin'}
# print(friends1.difference(friends2)) # {'zero', 'kevin'}
# 取差集有顺序区分,取friends2独有的好友
# print(friends2 - friends1) # {'Jy', 'ricky'}
# print(friends2.difference(friends1)) # {'Jy', 'ricky'}
# 4.4 对称差集^和symmetric_difference()功能同: 求两个用户独有的好友们(即去掉共有的好友)
# print(friends1 ^ friends2) # {'kevin', 'ricky', 'Jy', 'zero'}
# print(friends1.symmetric_difference(friends2)) # {'kevin', 'ricky', 'Jy', 'zero'}
# 4.5 父子集 > ,<:包含的关系
# s1={1,2,3}
# s2={1,2,4}
# 不存在包含关系,下面比较均为False
# print(s1 > s2) # False
# print(s1 < s2) # False
# s1={1,2,3}
# s2={1,2}
# print(s1 > s2) # True 当s1大于或等于s2时,才能说是s1是s2他爹
# 总结>和issuperset()功能同,<和issubset()功能同
# print(s1.issuperset(s2)) # True
# print(s2.issubset(s1)) # s2 < s1 =>True
# == 互为父子
# s1={1,2,3}
# s2={1,2,3}
# print(s1 == s2) # True s1与s2互为父子
# print(s1.issuperset(s2)) # True
# print(s2.issuperset(s1)) # True
# =========================去重=========================
# 1、只能针对不可变类型去重
# print(set([1,1,1,1,2])) # {1, 2}
# 2、无法保证原来的顺序
# l=[1,'a','b','z',1,1,1,2]
# l=list(set(l))
# print(l) # [1, 2, 'z', 'a', 'b']
# 使用for循环创建一个新的列表,要求不能有重复数据 # l=[ # {'name':'lili','age':18,'sex':'male'}, # {'name':'jack','age':73,'sex':'male'}, # {'name':'tom','age':20,'sex':'female'}, # {'name':'lili','age':18,'sex':'male'}, # {'name':'lili','age':18,'sex':'male'}, # ] # new_l=[] # for dic in l: # if dic not in new_l: # new_l.append(dic) # print(new_l) """ [{'name': 'lili', 'age': 18, 'sex': 'male'}, {'name': 'jack', 'age': 73, 'sex': 'male'}, {'name': 'tom', 'age': 20, 'sex': 'female'}] """
# 其他操作 # ''' # # 1.集合的长度len() # s={'a','b','c'} # print(len(s)) # 3 # # # 2.成员运算 # print('c' in s) # True # # # 3.循环 # for item in s: # print(item) # """ # b # a # c # """
# 其他内置方法 # s={1,2,3} # 需要掌握的内置方法1:discard # s.discard(4) # 删除元素不存在do nothing # print(s.discard(4)) # 返回None # s.remove(4) # 删除元素不存在则报错 KeyError: 4 # # 需要掌握的内置方法2:update # s.update({1,3,5}) # print(s) # {1, 2, 3, 5} # 需要掌握的内置方法3:pop()随机删除 # res=s.pop() # print(res) # 1 # 需要掌握的内置方法4:add()无则加之 # s.add(4) # print(s) # {1, 2, 3, 4} # s.add(3) # 有则不报错 # print(s) # {1, 2, 3} # s={1,2,3} # 判断两个集合是否完全独立(这里完全指的是没有共同元素) # res=s.isdisjoint({3,4,5,6}) # 两个集合完全独立、没有共同部分,返回True # print(res) # 有一个相同元素则返回False # 差集并跟新原集合 # res = s.difference_update({3,4,5}) # s=s.difference({3,4,5}) # print(res) # s=s.difference({3,4,5}) # print(s) # {1, 2}
9、元组类型:tuple()
(1)元组的作用:按照索引/位置存放多个值,只用于读不用于改
(2)元组的定义:()内用逗号分隔开多个任意类型的元素
# t=(1,1.3,'aa') # t=tuple((1,1.3,'aa'))
# print(t,type(t)) # (1, 1.3, 'aa') <class 'tuple'>
(3)元组的使用:
# x=(10) # 单独一个括号代表包含的意思
# print(x,type(x)) # 10 <class 'int'>
# t=(10,) # 如果元组中只有一个元素,必须加逗号
# print(t,type(t)) # (10,) <class 'tuple'>
# t=(1,1.3,'aa') # t=(0->值1的内存地址,1->值1.3的内存地址,2->值'aaa'的内存地址,)
# # t[0]=11111 # TypeError: 'tuple' object does not support item assignment
# print(t) # (1, 1.3, 'aa')
# t=(1,[11,22]) # t=(0->值1的内存地址,1->值[1,2]的内存地址,)
# print(id(t[0]),id(t[1])) # 8791464990368 6880704
# t[0]=111111111 # 不能改,报错
# t[1]=222222222 # 不能改,报错
#
# t[1][0]=11111111111111111
# print(t) # (1, [11111111111111111, 22])
# print(id(t[0]),id(t[1])) # 8791464990368 31391424
#3、类型转换
# print(tuple('hello')) #字符串转换成元组 ('h', 'e', 'l', 'l', 'o')
# print(tuple([1,2,3])) #列表转换成元组(1, 2, 3)
# print(tuple({'a1':111,'a2':333})) # 字典转换成元组('a1', 'a2')
#4、内置方法
#优先掌握的操作:
#1、按索引取值(正向取+反向取):只能取,不能改
# t=('aa','bbb','cc')
# print(t[0]) # aa
# print(t[-1]) # cc
#
# #2、切片(顾头不顾尾,步长)
# t=('aa','bbb','cc','dd','eee')
# print(t[0:3]) # ('aa', 'bbb', 'cc')
# print(t[::-1]) # ('eee', 'dd', 'cc', 'bbb', 'aa')
#3、长度len()
# t=('aa','bbb','cc','dd','eee')
# print(len(t)) # 5
#4、成员运算in和not in
# t=('aa','bbb','cc','dd','eee')
# print('aa' in t) # True
# print('ee' in t) # False
# print('f' not in t) # True
# print('eee'not in t) # False
#5、循环
# t=('aa','bbb','cc','dd','eee')
# for x in t:
# print(x)
# """
# aa
# bbb
# cc
# dd
# eee
# """
#6、index(),按值取出索引
# t=(2,3,111,111,111,111)
# # print(t.index(111)) # 2
# print(t.index(1111111111)) # 按参数去出索引,不存在则报错,ValueError: tuple.index(x): x not in tuple
# 7、count() # 按参数统计个数
# t=(2,3,111,111,111,111)
# print(t.count(111)) # 4
二、数据类型转换
1、数据类型转换
(1)int可以将由纯整数构成的字符串直接转换成整型,若包含其他任意非整数符号,则会报错
i_num = "123"
print(i_num,type(i_num)) # 123 <class 'str'>
res = int(i_num)
print(res,type(res)) # 123 <class 'int'>
i_num = "123.4adf" # 错误演示:字符串内包含了非整数符号.
print(i_num,type(i_num)) # 123.4adf <class 'str'>
res = int(i_num)
print(res,type(res))
输出
res = int(i_num)
ValueError: invalid literal for int() with base 10: '123.4adf'
(2)进制转换
# 进制转换
# 十进制转换成其他进制
x = 20
print(x,type(x)) # 20 <class 'int'>
# 十进制转换成二进制
print(bin(20),type(bin(20))) # 0b10100 <class 'str'>
# 十进制转换成八进制
print(oct(20),type(oct(20))) # 0o24 <class 'str'>
# 十进制转换成十六进制
print(hex(20),type(hex(20))) # 0x14 <class 'str'>
# 其他进制转换成十进制
# 二进制转换成十进制
print(int("0b10100",2)) # 20
# 八进制转换成十进制
print(int("0o24",8)) # 20
# 十六进制转换成十进制
print(int("0x14",16)) # 20
(3)float同样可以用来做数据类型的转换
f = '12.34'
print(f,type(f)) # 12.34 <class 'str'>
res = float(f)
print(res,type(res)) # 12.34 <class 'float'>
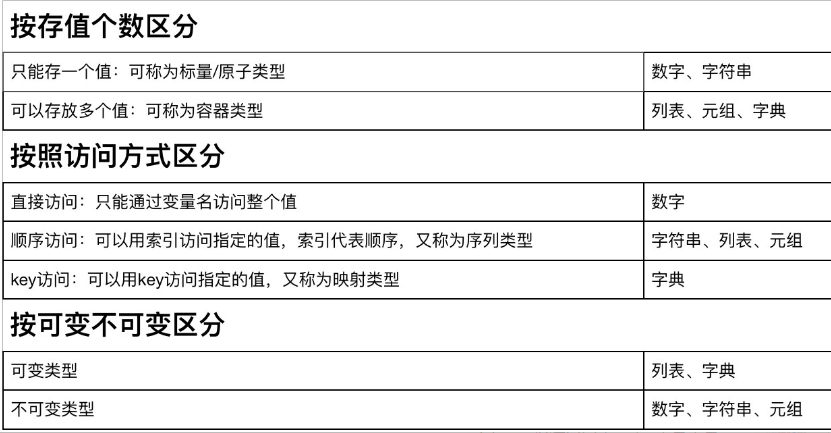
数据类型的总结


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程