C语言学习:宽字符串与窄字符串的转换
什么也不设置, 看一下代码运行结果。


1 #include <io_utils.h> 2 #include <string.h> 3 #include <stdlib.h> 4 #include <wchar.h> 5 #include <wctype.h> 6 #include <locale.h> 7 8 int main() { 9 // support for wide string 10 { 11 PRINT_BOOL(iswalpha(L'A')); 12 PRINT_BOOL(iswdigit(L'2')); 13 14 wchar_t *wcs = L"你好 Hello"; 15 size_t length = wcslen(wcs); 16 PRINT_INT(length); 17 18 wchar_t src[] = L"HelloWorld"; 19 wchar_t *dest = malloc(sizeof(wchar_t) * 11); 20 wmemset(dest, 0, 11); 21 wmemcpy(dest, src, 11); 22 _putws(dest); 23 wmemcpy(dest + 3, dest + 1, 4); 24 _putws(dest); 25 free(dest); 26 } 27 28 // conversions 29 // char *new_locale = setlocale(LC_ALL, "zh_CN.utf8"); 30 // if (new_locale) { 31 // puts(new_locale); 32 // } 33 34 { 35 char mbs[] = "你好"; 36 wchar_t wcs[10]; 37 mbstowcs(wcs, mbs, 10); 38 wprintf(L"%s\n", wcs); 39 printf("%s\n","dafdasfddsaf"); 40 } 41 return 0; 42 }
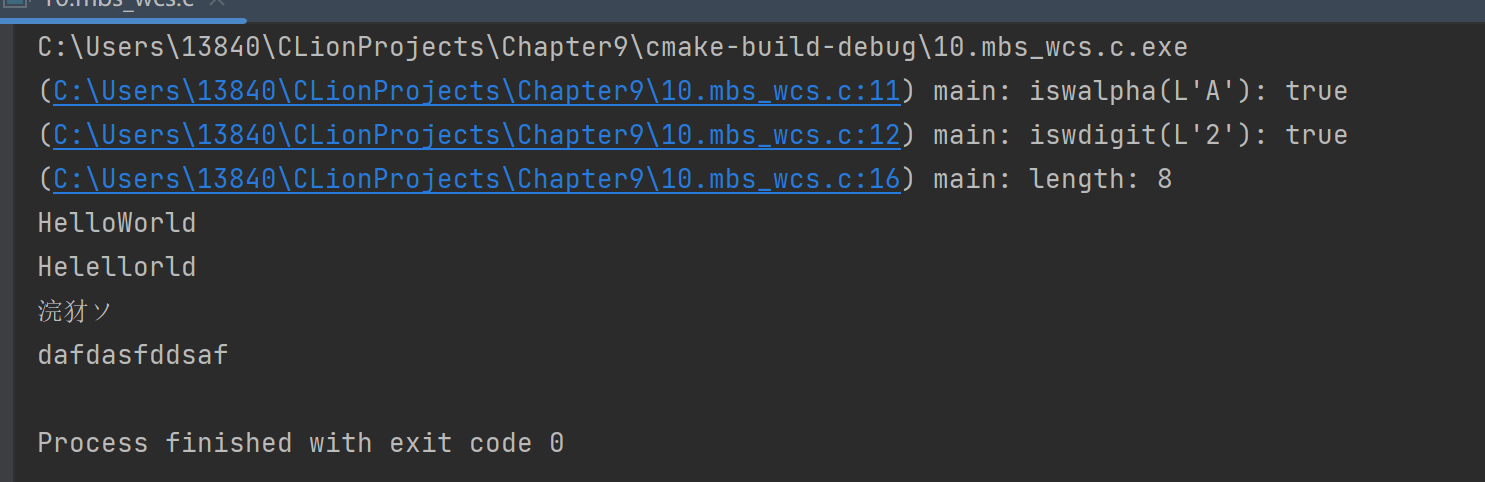
可以看到字符串长度是9, 但其实是8, 中文乱码了。 我们的文件编码是utf-8。

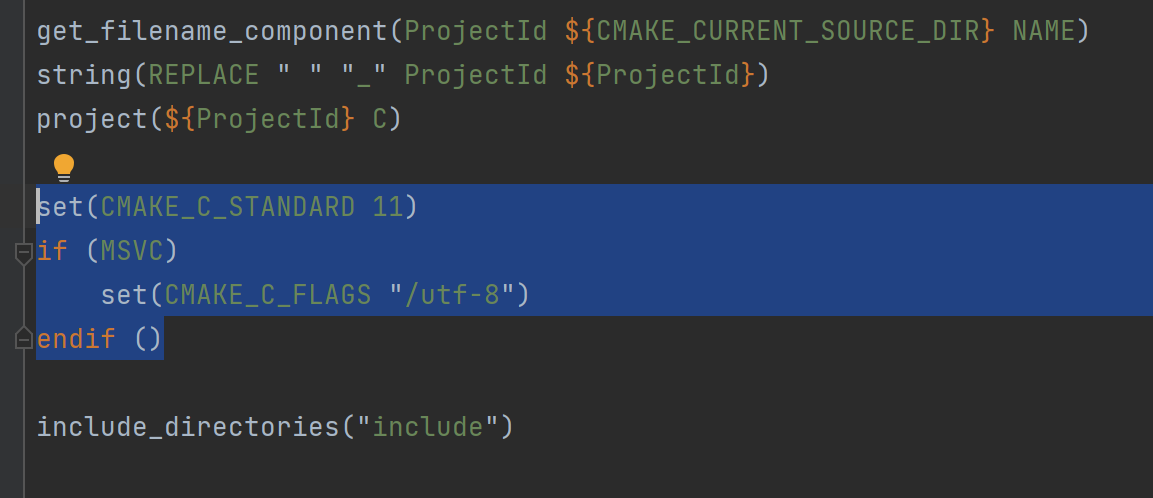
设置cmake的编码(可以参考最后一张图片的代码来设置编码),发现字符串的长度现在是对了, 但是中文还是乱码。
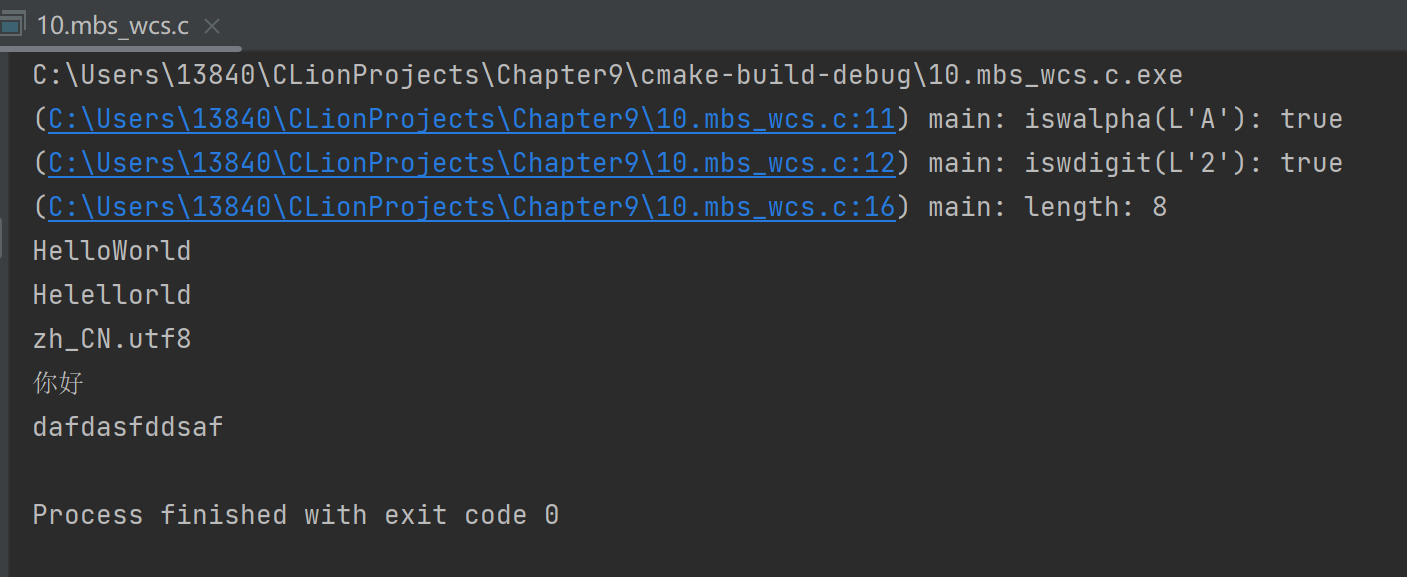
设置locale,代码如下
1 #include <io_utils.h> 2 #include <string.h> 3 #include <stdlib.h> 4 #include <wchar.h> 5 #include <wctype.h> 6 #include <locale.h> 7 8 int main() { 9 // support for wide string 10 { 11 PRINT_BOOL(iswalpha(L'A')); 12 PRINT_BOOL(iswdigit(L'2')); 13 14 wchar_t *wcs = L"你好 Hello"; 15 size_t length = wcslen(wcs); 16 PRINT_INT(length); 17 18 wchar_t src[] = L"HelloWorld"; 19 wchar_t *dest = malloc(sizeof(wchar_t) * 11); 20 wmemset(dest, 0, 11); 21 wmemcpy(dest, src, 11); 22 _putws(dest); 23 wmemcpy(dest + 3, dest + 1, 4); 24 _putws(dest); 25 free(dest); 26 } 27 28 // conversions 29 char *new_locale = setlocale(LC_ALL, "zh_CN.utf8"); 30 if (new_locale) { 31 puts(new_locale); 32 } 33 34 { 35 char mbs[] = "你好"; 36 wchar_t wcs[10]; 37 mbstowcs(wcs, mbs, 10); 38 wprintf(L"%s\n", wcs); 39 printf("%s\n","dafdasfddsaf"); 40 } 41 return 0; 42 }
结果,完全正确 了。
设置CMAKE的编码参数
-DCMAKE_C_FLAGS="UTF-8"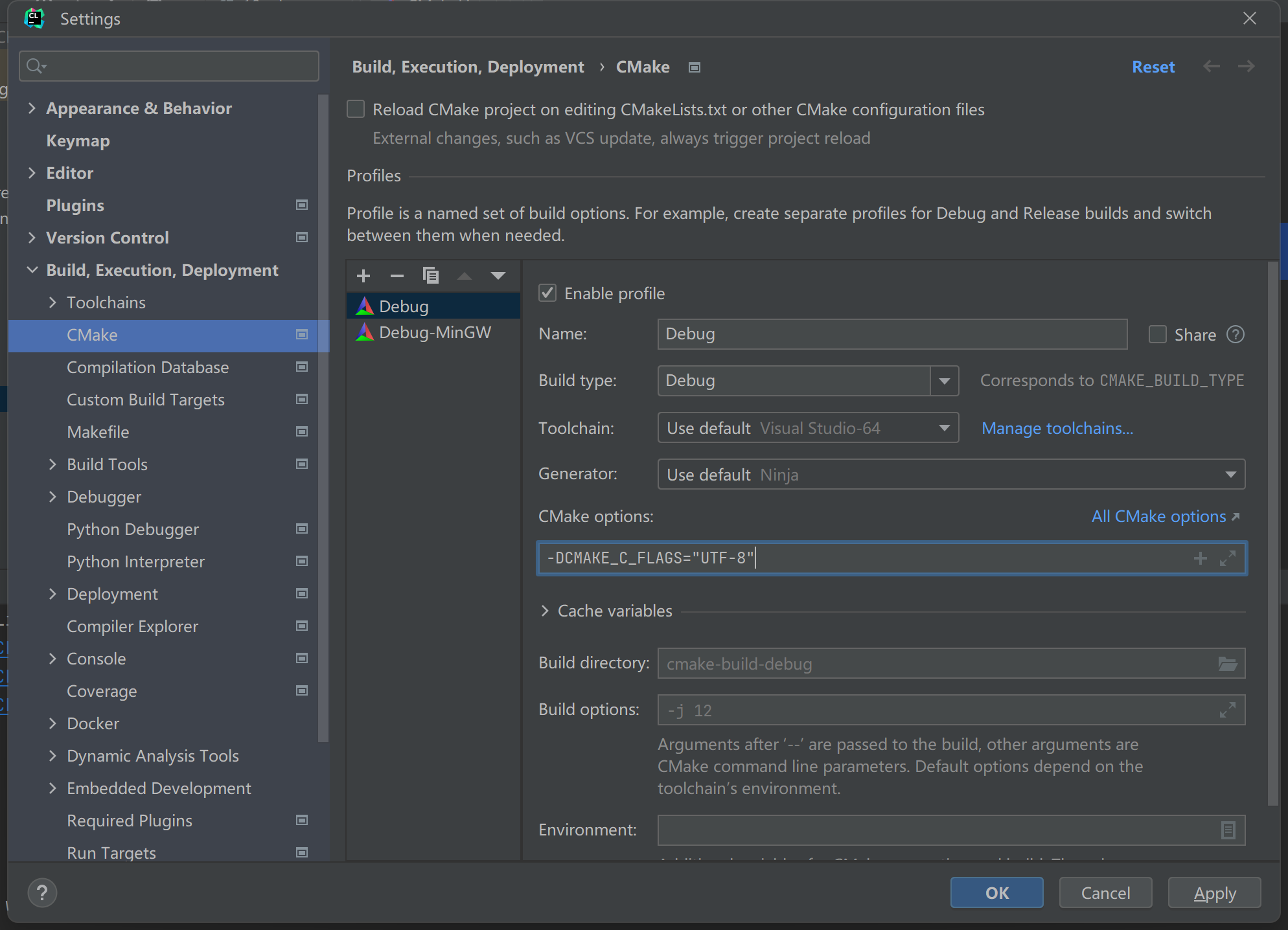
或者在CMakeLists.txt 文件中设置。