

OO第一单元作业总结
在这三周的时间里,我们围绕着求导这个主题,以难度逐渐递增的方式,完成了三次作业。我下面就对我的这三次作业做一个简单的分析
第一次作业
(1)简单分析
第一次作业的需要求导的多项式比较简单,一个多项式是由加减号链接各个项组成的,而项的种类只有常数项和带系数的幂函数。毕竟我们是第一次接触面向对象编程,因此那稍微简单一点的题进行尝试也是正常的。我对于类创建正如题目中所叙述的方式一样,首先有一个表达式类,而表达式是由项构成的,因此我们可以创建项类,那么表达式类就是一个项类的数组。那么项类的构建我认为我做的是没有问题的。但是由于对面向对象方法的不熟悉,我的项类其实只是一个空壳,没有写求导的方法,这个问题在写第二次作业的时候才意识到。
(2)程序结构
以下是UML类图和Metrics分析
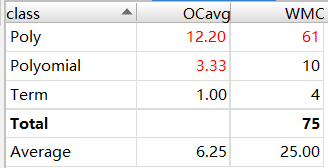
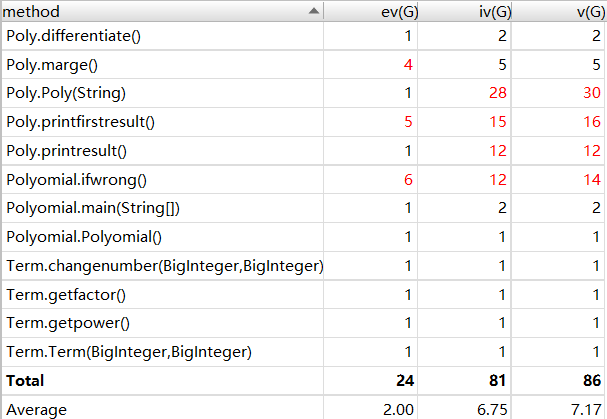
我有几个类的v(G)非常的高,原因就是我的项的类里是没有方法的,导致我的表达式类里频繁调用项类里的内容。这个问题还是很严重的。
(3)bug分析
这次作业我犯了一个很严重的错误,那就是我忘了在正则表达式的开头加空格,这样如果最开头是以空格开始,且后面的符号数是两个,我就会把表达式判断成非法的。这个问题导致我在强侧中错了一个点,而且互测也被两个人找到bug。
而对于找bug而言,我就是用自己在写代码时想到的一些可能出现bug的地方构造测试用例,并且认真阅读他人的代码。
---恢复内容结束---
在这三周的时间里,我们围绕着求导这个主题,以难度逐渐递增的方式,完成了三次作业。我下面就对我的这三次作业做一个简单的分析
第一次作业
(1)简单分析
第一次作业的需要求导的多项式比较简单,一个多项式是由加减号链接各个项组成的,而项的种类只有常数项和带系数的幂函数。毕竟我们是第一次接触面向对象编程,因此那稍微简单一点的题进行尝试也是正常的。我对于类创建正如题目中所叙述的方式一样,首先有一个表达式类,而表达式是由项构成的,因此我们可以创建项类,那么表达式类就是一个项类的数组。那么项类的构建我认为我做的是没有问题的。但是由于对面向对象方法的不熟悉,我的项类其实只是一个空壳,没有写求导的方法,这个问题在写第二次作业的时候才意识到。
(2)程序结构
以下是UML类图和Metrics分析
我有几个类的v(G)非常的高,原因就是我的项的类里是没有方法的,导致我的表达式类里频繁调用项类里的内容。这个问题还是很严重的。
(3)bug分析
这次作业我犯了一个很严重的错误,那就是我忘了在正则表达式的开头加空格,这样如果最开头是以空格开始,且后面的符号数是两个,我就会把表达式判断成非法的。这个问题导致我在强侧中错了一个点,而且互测也被两个人找到bug。
而对于找bug而言,我就是用自己在写代码时想到的一些可能出现bug的地方构造测试用例,并且认真阅读他人的代码。
第二次作业
(1)简单分析
第二次作业跟第一次作业相比,添加了三角函数,而且结构也比之前的复杂了,引入了因子的概念。我概括出来如下:多项式是由加减号连接项构成的,项是由乘号连接因子构成的,因子有幂函数因子,常数因子,三角函数因子三种。用这种方法构造类,是十分有结构的。
(2)程序结构
以下是UML类图和Metrics分析



(3)读取数据
我想在这里说一下我读取数据的方法,我通过对表达式构成的一些分析,抽象出加减号+一个因子/乘号+一个因子,如果是加减号+一个因子,说明之前的一项已经结束。而如果是乘号+一个因子,就说明一项还没有结束。而表达式就是由加减号+因子/乘号+因子构成的,这样就能很轻松的判断数据的合法性以及读取并存储数据。
(4)bug分析
很遗憾的是,这次我没有找到别人的bug,好消息是自己也没有被发现bug。我觉得,就求导过程来说,按照一定层次来写,是不容易犯错误的,我写的时候没有想到可能会出bug的点,因此我也没有测出别人的bug。
(5)优化
相较于第一次特别简单的优化,这次的优化就很复杂了。由于三角函数的引入,导致可能很长的三角函数表达式,会被优化为较短的表达式。而我感觉自己能力有限,因此对于这方面并没有做优化。依然和第一次作业一样的优化。例如*1,*0,+0,^1,^0,合并同类项这些。因此在性能分上只得到了部分的分数。
第三次作业
(1)简单分析
第三次作业与第二次相比,大的结构上其实并没有太大的变化,只是因子的种类发生了很大的变化。难点就在因子的种类上面,多了嵌套因子(sin里面不仅仅只有x,也可以是其它因子),表达式因子(一个表达式在最外面加了括号后也可以作为因子)。其实根据老师上课给出的类图,其实求导是一个很有逻辑的事情,我们只需要对每种因子类写出求导方法,整个表达式求导只需调用最外层表达式的求导方法即可。但是这次作业的难点在于数据处理(优化根本就没有在我的考虑范围内)。原因是题目里说的表达式中嵌套因子和表达式因子,是一个递归的过程,我们不太好能够写出一个正则去匹配它。那么如何读取数据,构造出一个便于求导的表达式树呢?我在下面会说一下我的方法。
(2)程序结构
这次我又犯了和第一次作业一样的错误,只不过位置不同,这次发生在表达式处理上。我没有将表达式处理的递归过程放在底层类里,导致我的处理过程写的无法扩展和维护。这同时也导致我的有些类的长度过长。
以下是UML类图和Metrics分析

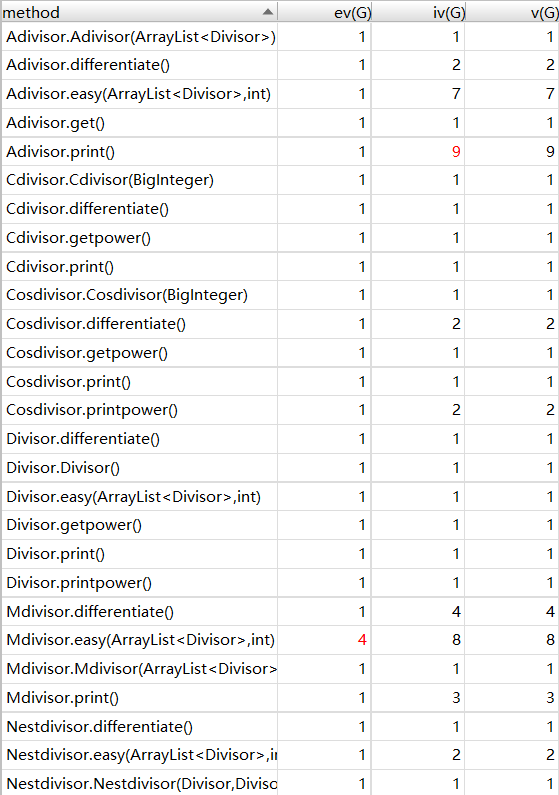
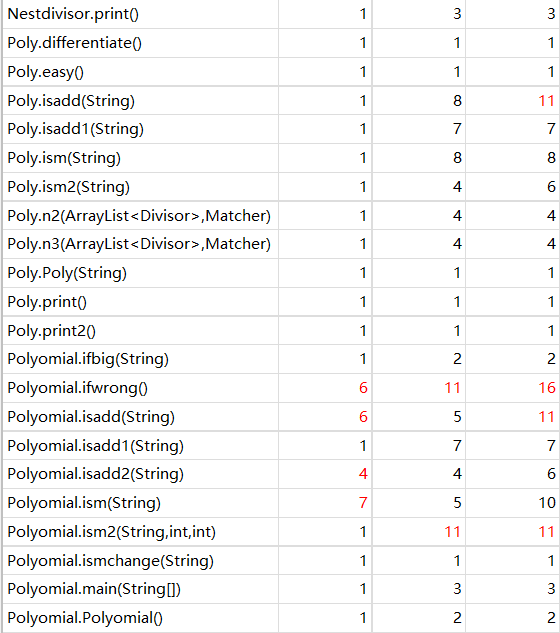

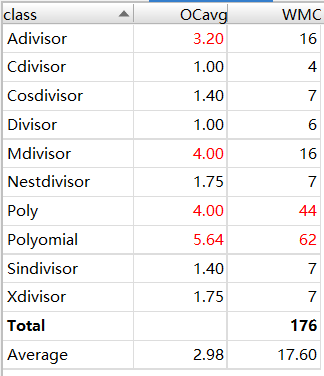
(3)bug分析
这次我依然没有发现别人的bug,自己也没有被发现bug。
(4)读取数据
在之前的两次作业中,我并没有进行对字符串的处理,就能够通过分析,找到所有正确表达式是由一种或两种正则循环构成的。因子我只要通过对输入循环匹配我所写的正则,即可判断数据并处理数据。但是这次我发现这个方法并不能直接实行。我想通过加号分开所有的项,通过乘号分开所有的因子,知道找到最底层不需要进行递归操作就能判断正确性的因子。举个例子,我先通过加号分开输入的所有部分,如果每部分是因子,那么这个输入就是合法的。而对于每个项,我用乘号分开所有部分,如果每部分都是因子,这个项就是合法的。而因子中又有嵌套因子,表达式因子,会继续调用我之前用加号分开所有部分的方法,这样就构成了递归。问题在于可能有干扰的+-号和乘号,比如指数上的+-号,表达式因子里的加减号和乘号。因此在进行我上面所说的分离步骤之前,要对这些干扰进行替换,先用其他符号替代。
(5) 优化
这次由于结构复杂+因子种类繁多,优化变的十分复杂,因此我只做了对于指数为1,0项为0的优化,以及多层括号的优化,并没有合并同类项。这些优化并没有用,我的性能分依然是0分。
总结
通过这三次作业,我意识到自己对于面向对象的感觉还是有待提高的,在之后的作业中我也会多多学习,争取获得进步。
