[Kafka] - Kafka内核理解:消息的收集/消费机制
一、Kafka数据收集机制
Kafka集群中由producer负责数据的产生,并发送到对应的Topic;Producer通过push的方式将数据发送到对应Topic的分区
Producer发送到Topic的数据是有key/value键值对组成的,Kafka根据key的不同的值决定数据发送到不同的Partition,默认采用Hash的机制发送数据到对应Topic的不同Partition中,配置参数为{partitioner.class}
Producer发送数据的方式分为sync(同步)和async(异步)两种,默认为同步方式,由参数{producer.type}决定;当为异步发送模式的时候Producer提供重试机制,默认失败重试发送3次
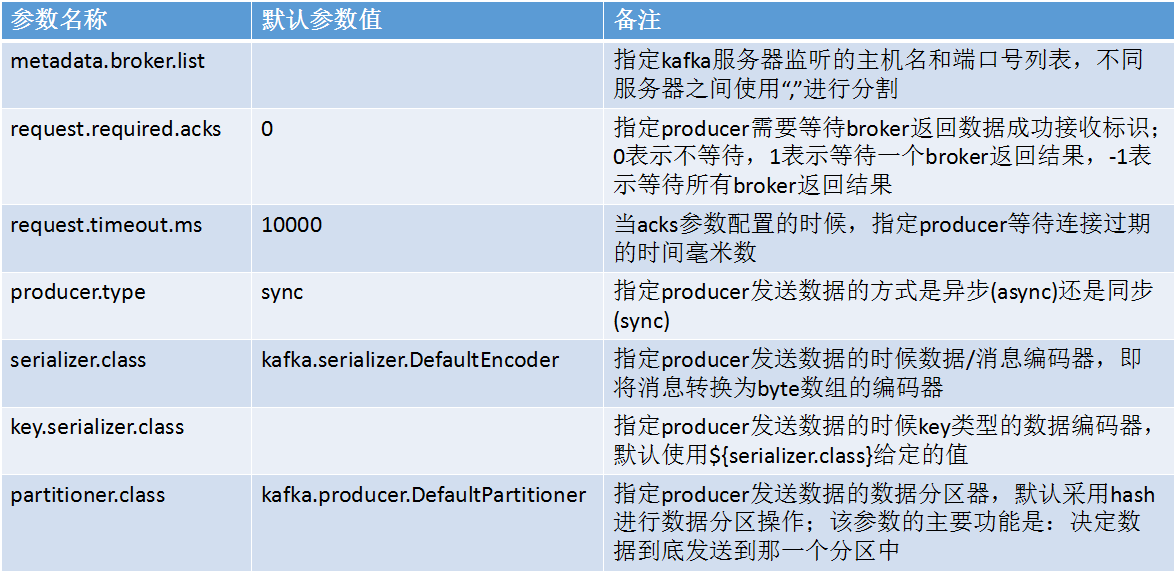
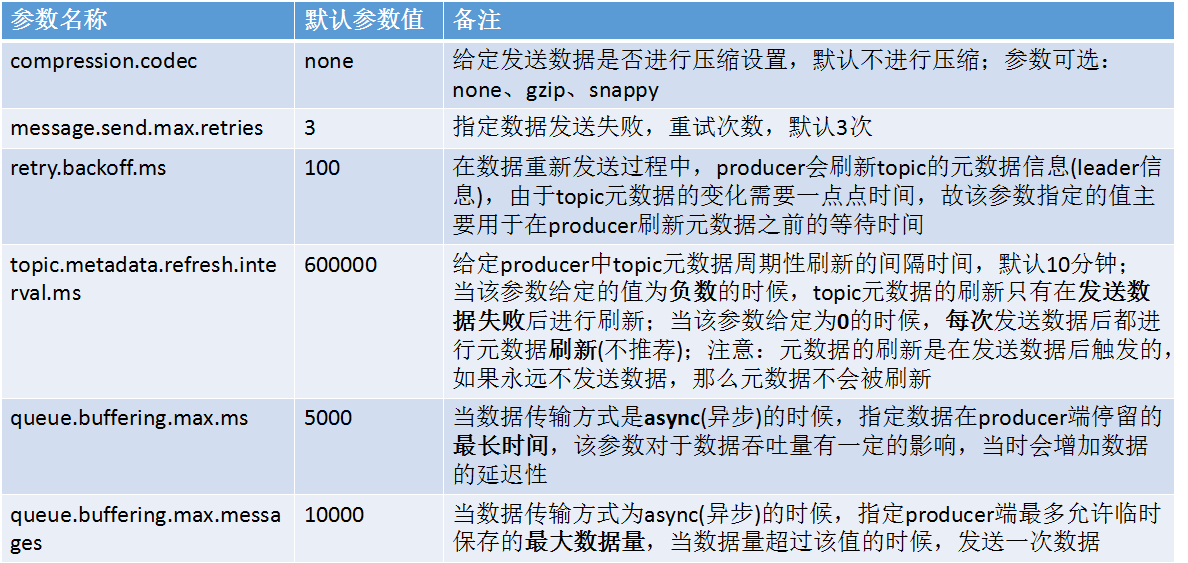
Kafka Producer相关参数:

二、Kafka数据消费机制
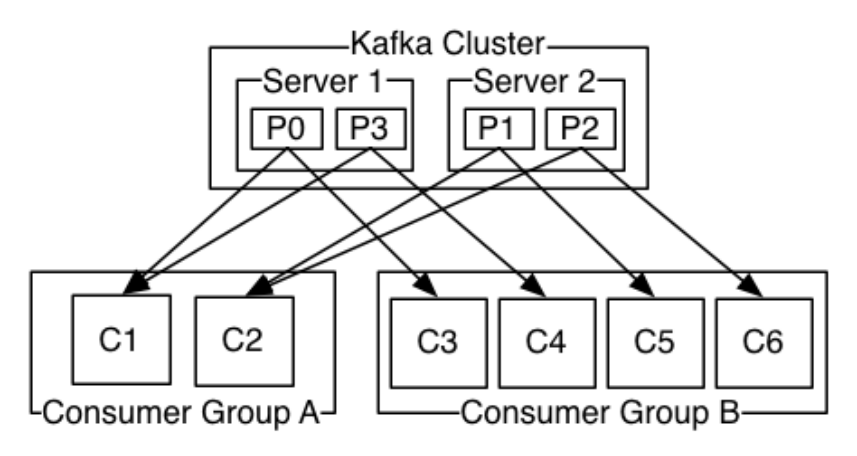
Kafka有两种模式消费数据:队列和发布订阅;在队列模式下,一条数据只会发送给customer group中的一个customer进行消费;在发布订阅模式下,一条数据会发送给多个customer进行消费
Kafka的Customer基于offset对kafka中的数据进行消费,对于一个customer group中的所有customer共享一个offset偏移量
Kafka中通过控制Customer的参数{group.id}来决定kafka是什么数据消费模式,如果所有消费者的该参数值是相同的,那么此时的kafka就是类似于队列模式,数据只会发送到一个customer,此时Kafka类似于负载均衡;否则就是发布订阅模式; 在队列模式下,可能会触发Kafka的Consumer Rebalance
Kafka的数据是按照分区进行排序的(插入的顺序),也就是每个分区中的数据是有序的。在Consumer进行数据消费的时候,也是对分区的数据进行有序的消费的,但是不保证所有数据的有序性(多个分区之间)
Consumer Rebalance:当一个consumer group组中的消费者数量和对应Topic的分区数量一致的时候,此时一个Consumer消费一个Partition的数据;如果不一致,那么可能出现一个Consumer消费多个Partition的数据或者不消费数据的情况,这个机制是根据Consumer和Partition的数量动态变化的
Consumer通过poll的方式主动从Kafka集群中获取数据
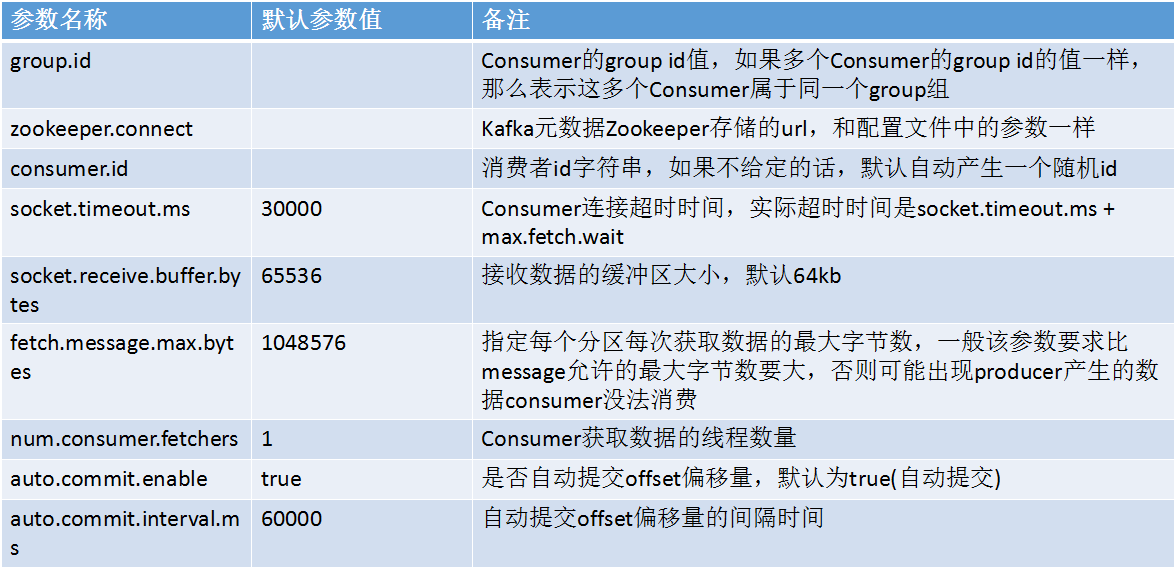
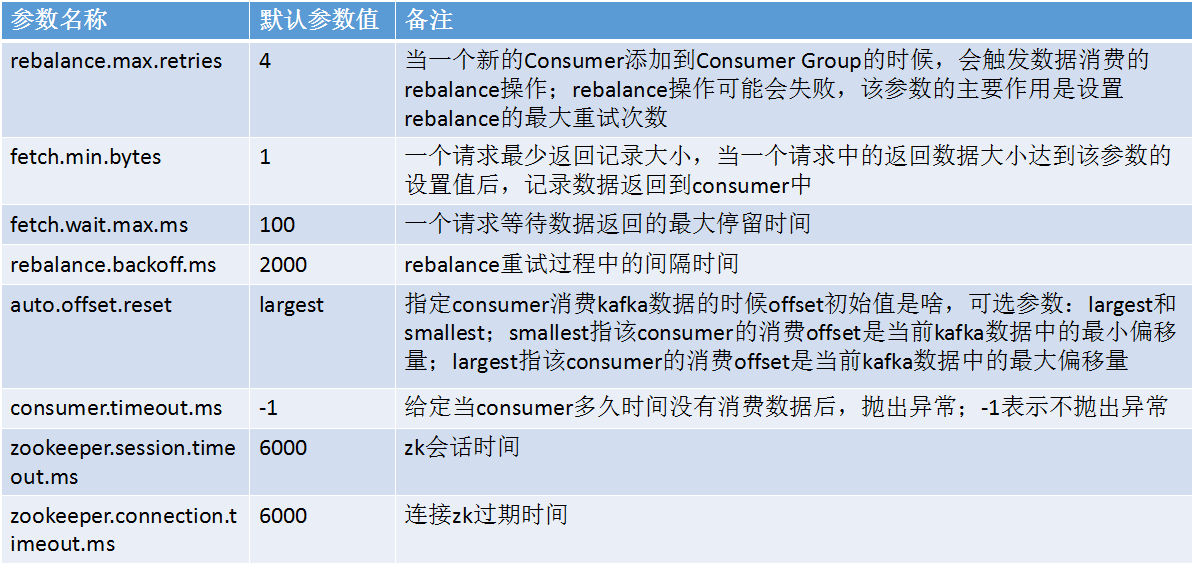
Kafka Consumer相关参数说明: