
Java Spark读取Hbase
本文记录Spark读取Hbase基本操作,及读取多版本Hbase数据示例。
Hbase数据示例如下:
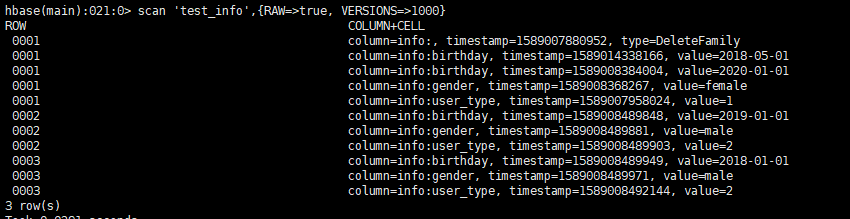
示例代码如下
package org.HbaseLearn.Util; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableInputFormat; import org.apache.hadoop.hbase.protobuf.ProtobufUtil; import org.apache.hadoop.hbase.protobuf.generated.ClientProtos; import org.apache.hadoop.hbase.util.Base64; import org.apache.hadoop.hbase.util.Bytes; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.RowFactory; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.sql.types.StructField; import org.apache.spark.sql.types.StructType; import scala.Tuple2; import java.io.IOException; import java.util.ArrayList; import java.util.Arrays; import java.util.Iterator; import java.util.List; import org.apache.spark.sql.SparkSession; import org.apache.log4j.Level; import org.apache.log4j.Logger; public class ReadSpark { private static JavaSparkContext jsc; public static void main(String[] args) throws InterruptedException { Logger.getLogger("org").setLevel(Level.ERROR); SparkSession spark = SparkSession.builder().master("yarn").master("local").appName("hello-wrold") // .config("spark.some.config.option", "some-value") .getOrCreate(); jsc = new JavaSparkContext(spark.sparkContext()); Configuration conf = HBaseConfiguration.create(); Scan scan = new Scan(); // 指定列,可以不写相当于select * from XX byte[] family_bytes = "info".getBytes(); byte[] birthday_bytes = "birthday".getBytes(); byte[] gender_bytes = "gender".getBytes(); byte[] user_type_bytes = "user_type".getBytes(); scan.addFamily(family_bytes); scan.addColumn(family_bytes, birthday_bytes); scan.addColumn(family_bytes, gender_bytes); scan.addColumn(family_bytes, user_type_bytes); // 设置读取的最大的版本数 scan.setMaxVersions(3); try { // 将scan编码 ClientProtos.Scan proto = ProtobufUtil.toScan(scan); String scanToString = Base64.encodeBytes(proto.toByteArray()); // 表名 String tableName = "test_info"; conf.set(TableInputFormat.INPUT_TABLE, tableName); conf.set(TableInputFormat.SCAN, scanToString); // ZooKeeper集群 conf.set("hbase.zookeeper.quorum", "node35,node34,node26"); conf.set("hbase.zookeeper.property.clientPort", "2181"); conf.set("hbase.master", "master"); // 将HBase数据转成RDD JavaPairRDD<ImmutableBytesWritable, Result> HBaseRdd = jsc.newAPIHadoopRDD(conf, TableInputFormat.class, ImmutableBytesWritable.class, Result.class); // 再将以上结果转成Row类型RDD JavaRDD<Row> HBaseRow = HBaseRdd.map(new Function<Tuple2<ImmutableBytesWritable, Result>, Row>() { private static final long serialVersionUID = 1L; @Override public Row call(Tuple2<ImmutableBytesWritable, Result> tuple2) throws IOException { Result result = tuple2._2; String rowKey = Bytes.toString(result.getRow()); String birthday = Bytes.toString(result.getValue(family_bytes, birthday_bytes)); String gender = Bytes.toString(result.getValue(family_bytes, gender_bytes)); String user_type = Bytes.toString(result.getValue(family_bytes, user_type_bytes)); return RowFactory.create(rowKey, birthday, gender, user_type); } }); // 顺序必须与构建RowRDD的顺序一致 List<StructField> structFields = Arrays.asList( DataTypes.createStructField("user_id", DataTypes.StringType, true), DataTypes.createStructField("birthday", DataTypes.StringType, true), DataTypes.createStructField("gender", DataTypes.StringType, true), DataTypes.createStructField("user_type", DataTypes.StringType, true)); // 构建schema StructType schema = DataTypes.createStructType(structFields); // 生成DataFrame Dataset<Row> HBaseDF = spark.createDataFrame(HBaseRow, schema); HBaseDF.show(); // 获取birthday多版本数据 JavaRDD<Row> multiVersionHBaseRow = HBaseRdd .mapPartitions(new FlatMapFunction<Iterator<Tuple2<ImmutableBytesWritable, Result>>, Row>() { private static final long serialVersionUID = 1L; @Override public Iterator<Row> call(Iterator<Tuple2<ImmutableBytesWritable, Result>> t) throws Exception { // TODO Auto-generated method stub List<Row> rows = new ArrayList<Row>(); while (t.hasNext()) { Result result = t.next()._2(); String rowKey = Bytes.toString(result.getRow()); // 获取当前rowKey的family_bytes列族对应的所有Cell List<Cell> cells = result.getColumnCells(family_bytes, birthday_bytes); for (Cell cell : cells) { String birthday = Bytes.toString(CellUtil.cloneValue(cell)); rows.add(RowFactory.create(rowKey, birthday, cell.getTimestamp())); } } return rows.iterator(); } }); List<StructField> multiVersionStructFields = Arrays.asList( DataTypes.createStructField("rowKey", DataTypes.StringType, true), DataTypes.createStructField("birthday", DataTypes.StringType, true), DataTypes.createStructField("timestamp", DataTypes.LongType, true)); // 构建schema StructType multiVersionSchema = DataTypes.createStructType(multiVersionStructFields); // 生成DataFrame Dataset<Row> multiVersionHBaseDF = spark.createDataFrame(multiVersionHBaseRow, multiVersionSchema); multiVersionHBaseDF.show(); } catch (Exception e) { e.printStackTrace(); } finally { if (spark != null) { spark.close(); } } spark.close(); } }
运行结果
+-------+----------+------+---------+
|user_id| birthday|gender|user_type|
+-------+----------+------+---------+
| 0001|2018-05-01|female| 1|
| 0002|2019-01-01| male| 2|
| 0003|2018-01-01| male| 2|
+-------+----------+------+---------+
+------+----------+-------------+
|rowKey| birthday| timestamp|
+------+----------+-------------+
| 0001|2018-05-01|1589014338166|
| 0001|2020-01-01|1589008384004|
| 0002|2019-01-01|1589008489848|
| 0003|2018-01-01|1589008489949|
+------+----------+-------------+
pom依赖如下
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase</artifactId>
<version>1.0.0</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.1.2</version>
</dependency>
