


【慢查询】

1 # 1 我们配置一个时间,如果查询时间超过了我们设置的时间,我们就认为这是一个慢查询 2 # 2 慢查询是一个先进先出的队列,固定长度,保存在内存中--->通过设置慢查询,以后超过我们设置时间的命令,就会放在这个队列中 3 # 3 后期我们通过查询这个队列,过滤出 慢命令--》优化慢命令 4 5 6 # 4 实操: 7 1 配置慢查询 8 # 设置记录所有命令 9 config set slowlog-log-slower-than 0 10 # 最多记录100条 11 config set slowlog-max-len 100 12 # 持久化到本地配置文件 13 config rewrite 14 15 2 查看慢查询队列 16 slowlog get [n] #获取慢查询队列 17 ''' 18 日志由4个属性组成: 19 1)日志的标识id 20 2)发生的时间戳 21 3)命令耗时 22 4)执行的命令和参数 23 ''' 24 slowlog len #获取慢查询队列长度 25 slowlog reset #清空慢查询队列 26 27 28 # mysql : slow_query_log
。
。
【pipline命令管道】
1 #1 Redis的pipeline(管道)功能在命令行中没有,但redis是支持pipeline的,而且在各个语言版的client中都有相应的实现 2 3 # 2 pipeline期间将“独占”链接,多个命令,放到一个pipline(管道中),要么都执行,要么都不执行 4 5 # 3 python中使用pipline 6 import redis 7 8 pool = redis.ConnectionPool(host='192.168.241.129', port=6379, password='jh123') 9 conn = redis.Redis(connection_pool=pool) 10 # pipe = r.pipeline(transaction=False) 11 # 创建pipeline 12 pipe =conn.pipeline(transaction=True) 13 # 开启事务 14 pipe.multi() 15 16 pipe.set('name', 'jh') 17 # 其他代码,可能出异常 18 pipe.set('role', 'nb') 19 20 pipe.execute() 21 22 23 # 4 事务四大特性 24 -原子性 25 -持久性 26 -一致性 27 -隔离性 28 # 6 redis有没有事务,能不能有这四大特性? 29 -因为redis,能实现事务的四大特性---》咱们说它支持 30 -通过pipline实现原子性--》通过pipline可以实现事务 31 -pipline只支持单实例,集群环境,不支持---》集群环境不支持事务 32 33 34 # 7 原生操作,实现乐观锁 35 36 # 7.1 mutil 开启事务,放到管道中一次性执行 37 multi # 开启事务 38 set name xxxx 39 set age 18 40 exec ,然后再去查,就发现数据改了 41 42 43 # 7.2 模拟事务回顾 ,乐观锁 44 # 在开启事务之前,先watch 45 watch age 46 multi 47 decr age 48 exec 49 50 # 另一台机器 51 multi 52 decr age 53 exec # 先执行,上面的执行就会失败(乐观锁,被wathc的事务不会执行成功) 54 55 56 57 # 7.3 使用redis实现乐观锁 58 59 60 ## 利用redis的乐观锁,实现秒杀系统的数据同步(基于watch实现), 61 ## 用户1 62 import redis 63 conn = redis.Redis(host='192.168.241.129',port=6379) 64 with conn.pipeline() as pipe: 65 # 先监视,自己的值没有被修改过 66 conn.watch('count') 67 # 事务开始 68 pipe.multi() 69 old_count = conn.get('count') 70 count = int(old_count) 71 input('我考虑一下') 72 if count > 0: # 有库存 73 pipe.set('count', count - 1) 74 75 # 执行,把所有命令一次性推送过去 76 ret = pipe.execute() 77 print(type(ret)) 78 print(ret) 79 ## 用户2 80 import redis 81 conn = redis.Redis(host='127.0.0.1',port=6379) 82 with conn.pipeline() as pipe: 83 # 先监视,自己的值没有被修改过 84 conn.watch('count') 85 # 事务开始 86 pipe.multi() 87 old_count = conn.get('count') 88 count = int(old_count) 89 if count > 0: # 有库存 90 pipe.set('count', count - 1) 91 # 执行,把所有命令一次性推送过去 92 ret=pipe.execute() 93 print(type(ret)) 94 95 # 注:windows下如果数据被修改了,不会抛异常,只是返回结果的列表为空,mac和linux会直接抛异常 96 97 # 秒杀系统核心逻辑测试,创建100个线程并发秒杀(代码有问题) 98 import redis 99 from threading import Thread 100 def choose(name, conn): 101 with conn.pipeline() as pipe: 102 # 先监视,自己的值没有被修改过 103 conn.watch('count') 104 # 事务开始 105 pipe.multi() 106 old_count = conn.get('count') 107 count = int(old_count) 108 # input('我考虑一下') 109 # time.sleep(random.randint(1, 2)) 110 if count > 0: # 有库存 111 pipe.set('count', count - 1) 112 113 # 执行,把所有命令一次性推送过去 114 ret = pipe.execute() 115 print(ret) 116 if len(ret) > 0: 117 print('第%s个人抢购成功' % name) 118 else: 119 print('第%s个人抢购失败' % name) 120 121 122 if __name__ == '__main__': 123 conn = redis.Redis(host='192.168.241.129', port=6379) 124 for i in range(100): 125 126 t = Thread(target=choose, args=(i, conn)) 127 t.start()
。
。
【发布订 1 # 发布订阅(观察者模式):发布者发布了消息,所有的订阅者都可以收到,就是生产者消费者模型
2 -生产者消费者 发布订阅模型 3 -生产者消费者 队列 4 5 # 原生实现 6 -发布消息: 7 publish channel message 8 -订阅(现有订阅者,然后发布者才有消息) 9 subscribe channel 10 -接收消息 11 -只要发布者一发布,订阅者都会受到 12 13 14 # python+redis实现 15 import redis 16 # 连接到Redis服务器 17 r = redis.Redis(host='localhost', port=6379, db=0) 18 # 发布者 19 20 r.publish('channel', 'message') 21 22 23 24 import redis 25 # 连接到Redis服务器 26 r = redis.Redis(host='localhost', port=6379, db=0) 27 # 订阅者 28 sub = r.pubsub() 29 sub.subscribe('channel') 30 for message in sub.listen(): 31 print(message)
if isinstance(message['data'],bytes):
print(message['data'].decode('utf-8'))
if message['data'].decode('utf-8')['type']=='下单':
print(message['data'].decode('utf-8')['user'],'发送短信')
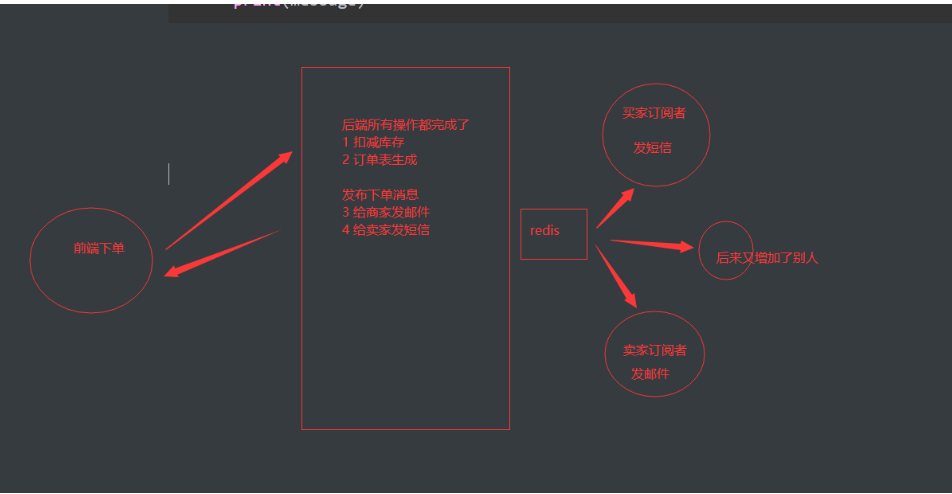
。
。
【bitmap位图】
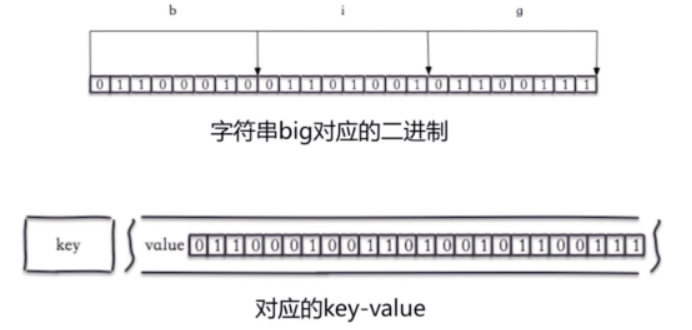
1 #1 本质是字符串 2 3 #2 操作比特位 4 b i g 5 01100011 01101001 01100111 6 set hello big #放入key位hello 值为big的字符串 7 getbit hello 0 #取位图的第0个位置,返回0 8 getbit hello 1 #取位图的第1个位置,返回1 如上图 9 10 # 我们可以直接操纵位 11 setbit key offset value #给位图指定索引设置值 12 setbit hello 7 1 #把hello的第7个位置设为1 这样,big就变成了cig 13 14 15 # 3 独立用户统计---》统计日活---》用户量足够大--》节约内存 16 -10亿用户 用户id1 2 3 10亿 17 18 1个bytes--》8个比特位---》能表示多少种变化? 19 2的7次方-1 :-128 到127之间 20 8个bytes--》64个比特位--》9223372036854775808 21 22 如果以集合存储:存一个用户,就要8个bytes---》存1亿用户 8 bytes*1亿 23 24 -统计日活,只要用户登录,就把用户id放到集合中 25 -晚上只需要统计一下 集合大小---》就能统计出日活 26 -使用集合存储---》1--》32位--》1亿用户 5千万左右---》需要 200MB空间 27 int8个比特位表示范围 -128--127之间 28 int16 29 int32 个比特位表示范围 -2的31次方---2的31次方 2147483648 30 31 -使用位图---》12.5MB空间 32 33 34 # 获取前3位中1的个数 35 bitcount name 0 3
。
。
1 # 1 基于HyperLogLog算法:极小的空间完成独立数量统计,本质还是字符串 2 3 # 2 4 -放值:pfadd uuids "uuid1" "uuid2" "uuid3" "uuid4" 5 -统计个数:pfcount uuids 6 -判断一个值是否在里面:pfadd uuids "uuid1"(返回1/0) 7 8 # 3 统计日活用户 9 10 # 4 去重:爬过的网址,就不爬了--》存一下爬过的 11 'www.baidu.com'--->放到 pfadd 中--》返回1,说明没爬过--》继续爬取--》如果返回0,不爬了 12 13 # 5 黑白名单 14 15 # 6 注意 16 百万级别独立用户统计,百万条数据只占15k 17 错误率 0.81% 18 无法取出单条数据,只能统计个数 19 20 # 7 类似于布隆过滤器,算法不一样
。
。
1 # 1 geo 地理位置信息 2 GEO(地理信息定位):存储经纬度,计算两地距离,范围等 3 北京:116.28,39.55 4 天津:117.12,39.08 5 可以计算天津到北京的距离,天津周围50km的城市,外卖等 6 7 # 2 经纬度哪里来? 8 - web端:js获取--》掉接口,传给后端 9 - 安卓,ios端:线程的代码 10 -微信小程序 11 12 # 3 js获取经纬度 13 if (navigator.geolocation) { 14 navigator.geolocation.getCurrentPosition(function(position) { 15 var latitude = position.coords.latitude; 16 var longitude = position.coords.longitude; 17 console.log("经度:" + longitude); 18 console.log("纬度:" + latitude); 19 }); 20 } else { 21 console.log("浏览器不支持Geolocation API"); 22 } 23 24 25 # 4 增加地理位置信息 26 geoadd key longitude latitude member #增加地理位置信息 27 28 geoadd cities:locations 116.28 39.55 beijing #把北京地理信息天津到cities:locations中 29 geoadd cities:locations 117.12 39.08 tianjin 30 geoadd cities:locations 114.29 38.02 shijiazhuang 31 geoadd cities:locations 118.01 39.38 tangshan 32 geoadd cities:locations 115.29 38.51 baoding 33 34 35 # 5 获取天津的经纬度 geopos key member #获取地理位置信息 36 geopos cities:locations tianjin 37 # 根据经纬度--》文字 38 from geopy.geocoders import Nominatim 39 geolocator = Nominatim(user_agent="my_application") 40 def geolocate_point(latitude, longitude): 41 location = geolocator.reverse(f"{latitude}, {longitude}") 42 return location.address 43 # 示例使用经纬度 44 latitude = 39.983424 45 longitude = 116.307224 46 address = geolocate_point(latitude, longitude) 47 print(address) 48 49 # 6 统计两个地理位置之间的距离 50 geodist cities:locations beijing tianjin km #北京到天津的距离,89公里 51 52 # 7 统计某个地理位置方圆xx公里,有xx 53 georadiusbymember cities:locations beijing 150 km
。
。
【持久化】
1 # 1 什么是持久化 2 redis的所有数据保存在内存中,对数据的更新将异步的保存到硬盘上 3 4 # 2 持久化的实现方式 5 快照:某时某刻数据的一个完成备份, 6 -mysql的Dump:写一个mysql自动定时备份和清理前后端程序 7 -redis的RDB:某一刻,把内存中得数据,保存到硬盘上这个操作就是rbd的持久化 8 写日志:任何操作记录日志,要恢复数据,只要把日志重新走一遍即可 9 -mysql的 Binlog 10 -Redis的 AOF 11 12 # 3 redis有三种持久化方案 13 -rdb:快照 14 -aof:日志 15 -混合持久化:rdb+aof混合方案
。
rdb
1 # 4 rdb方案 :三种方式 2 1 人工同步:客户端 : save # 同步操作,会阻塞其他命令--》单线程架构 3 2 人工异步:客户端:bgsave # 异步操作,不会阻塞其他命令 4 3 配置文件 5 save 900 1 #配置一条 6 save 300 10 #配置一条 7 save 60 10000 #配置一条 8 9 save 60 5 10 11 # 5 最佳配置 12 #最佳配置 13 save 900 1 14 save 300 10 15 save 60 10000 16 dbfilename dump-6379.rdb #以端口号作为文件名,可能一台机器上很多reids,不会乱 17 dir ./bigdiskpath #保存路径放到一个大硬盘位置目录 18 stop-writes-on-bgsave-error yes #出现错误停止 19 rdbcompression yes #压缩 20 rdbchecksum yes #校验 21 22 23 # 6 确定 RDB问题 24 耗时,耗性能: 25 不可控,可能会丢失数据
1 # redis 持久化方案 2 -rdb:快照方案 3 -save 4 -bgsave 5 -配置文件 save 时间 条数 6 7 -xx.rdb 文件---》下次启动redis-server--》自动加载rdb到内存中 8 9 -lastsave :查看最后执行持久化的时间戳 10 11 -stop-writes-on-bgsave-error:当磁盘满时,是否关闭redis的写操作 12 13 -aof:日志方案(删除,新增,修改) 14 -自动记录日志 15 -xx.aof 文件 16 -aof策略 17 -always:redis–》写命令刷新的缓冲区—》每条命令fsync到硬盘—》AOF文件 18 -everysec(默认值):redis——》写命令刷新的缓冲区—》每秒把缓冲区fsync到硬盘–》AOF文件 19 -no:redis——》写命令刷新的缓冲区—》操作系统决定,缓冲区fsync到硬盘–》AOF文件 20 -配置文件: 21 appendonly yes #将该选项设置为yes,打开 22 appendfilename "appendonly.aof" #文件保存的名字 23 appendfsync everysec #采用第二种策略 24 no-appendfsync-on-rewrite yes 25 26 -两种方案同时用? 27 -没有任何问题 28 -其实 RDB 和 AOF 两种方式也可以同时使用,在这种情况下,如果 redis 重启的话,则会优先采用 AOF 方式来进行数据恢复,这是因为 AOF 方式的数据恢复完整度更高
。
aof
1 # 1 客户端每写入一条命令,都记录一条日志,放到日志文件中,如果出现宕机,可以将数据完全恢复 2 # 2 AOF的三种策略日志不是直接写到硬盘上,而是先放在缓冲区,缓冲区根据一些策略,写到硬盘上always:redis–》写命令刷新的缓冲区—》每条命令fsync到硬盘—》AOF文件everysec(默认值):redis——》
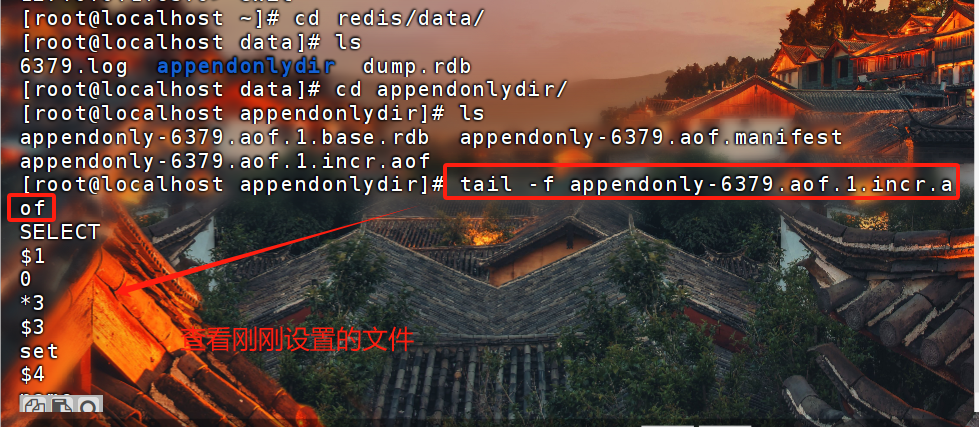
写命令刷新的缓冲区—》每秒把缓冲区fsync到硬盘–》AOF文件no:redis——》写命令刷新的缓冲区—》操作系统决定,缓冲区fsync到硬盘–》AOF文件 3 # 3 配置文件appendonly yes #将该选项设置为yes,打开appendfilename "appendonly-${port}.aof" 4 #文件保存的名字appendfsync everysec 5 #采用第二种策略dir /bigdiskpath 6 #存放的路径no-appendfsync-on-rewrite yesappendonly yesappendfilename "appendonly.aof"appendfsync everysecno-appendfsync-on-rewrite yes 7 8 # 4 放在了文件中appendonly.aof.1.base.rdb :永久的appendonly.aof.1.incr.aof :临时的appendonly.aof.manifest: 哪些文件存了数据
(AOF重写)
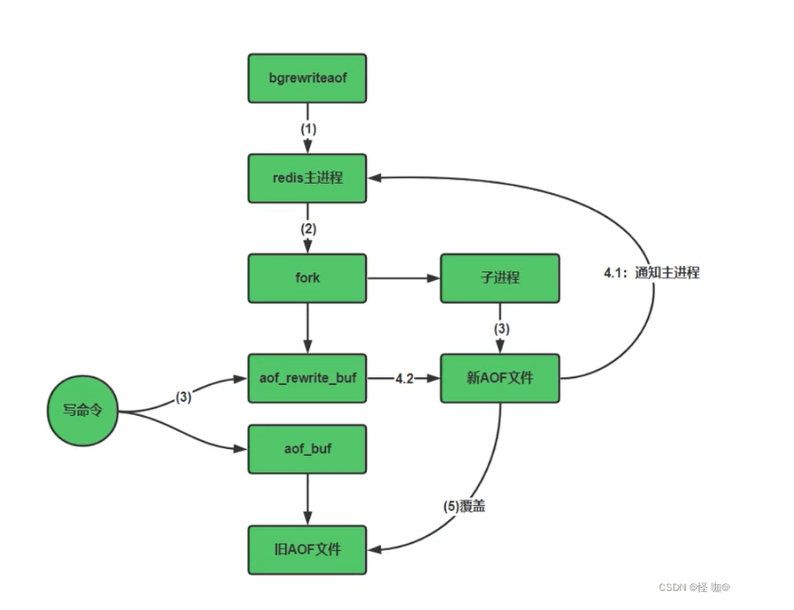
1 一. aof重写策略解释 2 3 # 1 Redis 在长期运行的过程中,aof 文件会越变越长。如果机器宕机重启,“重演”整个 aof 文件会非常耗时,导致长时间 Redis 无法对外提供服务。因此就需要对 aof 文件做一下“瘦身”运动【把失效的或可以合并的日志合并】 4 5 # 2 为了让 aof 文件的大小控制在合理的范围内,Redis 提供了 AOF 重写机制,手动执行BGREWRITEAOF命令,开始重写 aof 文件,如下所示: 6 7 127.0.0.1:6379> BGREWRITEAOF 8 Background append only file rewriting started 9 ''' 10 通过 bgrewriteaof 操作后,服务器会生成一个新的 aof 文件,该文件具有以下特点: 11 12 新的 aof 文件记录的数据库数据和原 aof 文件记录的数据库数据完全一致; 13 新的 aof 文件会使用尽可能少的命令来记录数据库数据,因此新的 aof 文件的体积会小很多; 14 AOF 重写期间,服务器不会被阻塞,它可以正常处理客户端发送的命令。 15 即使 Bgrewriteaof 执行失败,也不会有任何数据丢失,因为旧的 AOF 文件在 Bgrewriteaof 成功之前不会被修改 16 17 ''' 18 19 二.触发aof重写 20 -手动:BGREWRITEAOF 21 22 -自动: 23 #默认配置项 24 auto-aof-rewrite-percentage 100 25 auto-aof-rewrite-min-size 64mb #表示触发AOF重写的最小文件体积,大于或等于64MB自动触发。 26 ''' 27 该配置项表示:触发重写所需要的 aof 文件体积百分比,只有当 aof 文件的增量大于 100% 时才进行重写,也就是大一倍。比如,第一次重写时文件大小为 64M,那么第二次触发重写的体积为 128M,第三次重写为 256M,以此类推。如果将百分比值设置为 0 就表示关闭 AOF 自动重写功能 28 ''' 29 30 # 3 其他配置 31 ''' 32 no-appendfsync-on-rewrite:重写时,不会执行appendfsync操作 33 34 该参数表示在正在进行AOF重写时不会将AOF缓冲区中的数据同步到旧的AOF文件磁盘,也就是说在进行AOF重写的时候,如果此时有写操作进来,此时写操作的命令会放在aof_buf缓存中(内存中),而不会将其追加到旧的AOF文件中,这么做是为了避免同时写旧的AOF文件和新的AOF文件对磁盘产生的压力。 35 36 默认是ON,表示关闭,即在AOF重写时,会对AOF缓冲区中的数据做同步磁盘操作,这在很大程度上保证了数据的安全性。但是遇到重写操作,可能会发生阻塞。(数据安全,但是性能降低) 37 38 如果no-appendfsync-on-rewrite为yes,不写入aof文件,只写入缓存,用户请求不会阻塞,但是在这段时间如果宕机会丢失这段时间的缓存数据。(降低数据安全性,提高性能) 39 '''
。
。
【混合持久化(7.x默认自动开启)】
1 # 混合持久化原理:目的是为了加快恢复 2 在开启混合持久化的情况下,AOF 重写时会把 Redis 的持久化数据,以 RDB 的格式写入到 AOF 文件的开头,之后的数据再以 AOF 的格式化追加的文件的末尾 3 4 # 配置是: 5 appendonly yes 6 appendfilename "appendonly-6379.aof" 7 appendfsync everysec 8 no-appendfsync-on-rewrite yes 9 aof-use-rdb-preamble yes #开启了混合持久化 10 ====================================================== 11 12 # 总结: 13 1 使用混合持久化 14 -开启rdb,开启aof 15 -aof-use-rdb-preamble yes # 内部原理--》只要触发aof重写,会把rdb放在aof的开头 16 17 # aof 文件作用 18 xx.manifest : 存放了,哪些aof文件合并起来是总的【保存了所有aof合rdb文件】 19 xx.2.incr.aof:存放了 aof的日志,没有rdb的二进制 20 xx.aof.2.base.rdb :存放的是 rdb的二进制文件 21 2 数字表示,aof重写了几次
。
。
【主从】
1 # 一. 什么是主从复制 2 从库复制主库的数据,保证主库和从库数据一直一致,从库只能读。 3 # 1.1 问题 4 机器故障;容量瓶颈;QPS瓶颈 5 机器故障:主从,哨兵 6 容量瓶颈:集群 7 QPS瓶颈:主从 8 # 1.2 主从架构 9 一主一从,一主多从 10 # 1.3 作用 11 做读写分离 12 做数据副本 13 # 1.4 注意 14 一个master可以有多个slave 15 一个slave只能有一个master 16 数据流向是单向的,从master到slave【以后slave只用来读,不用来写了】 17 18 # 二. 主从复制流程 19 1. 副本库(从库,slave)通过slaveof 127.0.0.1 6379命令,连接主库,并发送SYNC给主库 20 2. 主库收到SYNC,会立即触发BGSAVE,后台保存RDB,发送给副本库 21 3. 副本库接收后会应用RDB快照 22 4. 主库会陆续将中间产生的新的操作,保存并发送给副本库 23 5. 到此,我们主复制集就正常工作了 24 6. 再此以后,主库只要发生新的操作,都会以命令传播的形式自动发送给副本库. 25 7. 所有复制相关信息,从info信息中都可以查到.即使重启任何节点,他的主从关系依然都在. 26 8. 如果发生主从关系断开时,从库数据没有任何损坏,在下次重连之后,从库发送PSYNC给主库 27 9. 主库只会将从库缺失部分的数据同步给从库应用,达到快速恢复主从的目的 28 29 # 3 主库是否要开启持久化:无所谓,为了防止数据丢失,都会开启 30 31 # 4 实操 32 - 1 命令: 33 #链接主从复制:在 6380的redis上执行 34 slaveof 127.0.0.1 6379 35 # 断开主从复制 36 slaveof no one 37 - 2 配置文件 38 slaveof 127.0.0.1 6379 39 slave-read-only yes 40 masterauth "jh123" ,这是主节点密码,如果不配置,从节点获取不到主节点的信息 41 42 # 5 通过info查看主从信息 43 44 # 6 主从复制的辅助配置 45 min-slaves-to-write 2 46 min-slaves-max-lag 3 47 #那么在从服务器的数量少于2个,或者三个从服务器的延迟(lag)值都大于或等于3秒时,主服务器将拒绝执行写命令
。
Python的主从 操作
1 # 1 redis.py 原生操作 自己处理 2 conn1=链接主库 3 conn2=链接从库 4 5 conn1.set('name','zzz') 6 7 print(conn2.get('name')) 8 9 10 # 2 django中缓存使用 11 CACHES = { 12 "default": { 13 "BACKEND": "django_redis.cache.RedisCache", 14 "LOCATION": "redis://localhost:6379/0", 15 "OPTIONS": { 16 "CLIENT_CLASS": "django_redis.client.DefaultClient", 17 } 18 }, 19 "redis1": { 20 "BACKEND": "django_redis.cache.RedisCache", 21 "LOCATION": "redis://localhost:6379/0", 22 "OPTIONS": { 23 "CLIENT_CLASS": "django_redis.client.DefaultClient", 24 } 25 } 26 } 27 from django.core.cache import caches 28 caches['redis1'].set("name",'xx') # 写 29 res=caches['default'].get('name') # 读 30 requirepass "jh123" 31 32 ### 主从复制时,如果主库有密码,从库要配置 33 34 masterauth 'jh123'
。
。
【哨兵】
1 ##################### 1 一主两从######################################## 2 -在三台机器,写配置文件,启动即可(三台机器要联通) 3 ##### ##### ##### 主库##### ##### ##### 4 daemonize yes 5 bind 0.0.0.0 6 pidfile "/var/run/redis.pid" 7 port 6379 8 dir "/root/redis/data" 9 logfile "6379.log" 10 protected-mode no 11 requirepass "654321" 12 save 60 5 13 appendonly yes 14 appendfilename "appendonly-6379.aof" 15 appendfsync everysec 16 no-appendfsync-on-rewrite yes 17 aof-use-rdb-preamble yes 18 masterauth '654321' 19 20 ##### ##### ##### 从库1##### ##### ##### 21 daemonize yes 22 bind 0.0.0.0 23 pidfile "/var/run/redis.pid" 24 port 6379 25 dir "/root/redis/data" 26 logfile "6379.log" 27 protected-mode no 28 requirepass "654321" 29 save 60 5 30 31 appendonly yes 32 appendfilename "appendonly-6379.aof" 33 appendfsync everysec 34 no-appendfsync-on-rewrite yes 35 aof-use-rdb-preamble yes 36 37 slaveof 主库地址 6379 38 masterauth "654321" 39 slave-read-only yes 40 41 42 ##### ##### ##### 从库2##### ##### ##### 43 daemonize yes 44 bind 0.0.0.0 45 pidfile "/var/run/redis.pid" 46 port 6379 47 dir "/root/redis/data" 48 logfile "6379.log" 49 protected-mode no 50 requirepass "654321" 51 save 60 5 52 53 appendonly yes 54 appendfilename "appendonly-6379.aof" 55 appendfsync everysec 56 no-appendfsync-on-rewrite yes 57 aof-use-rdb-preamble yes 58 59 slaveof 主库地址 6379 60 masterauth "654321" 61 slave-read-only yes 62 63 64 ######2 一主多从存在的问题### 65 #1 主从复制,主节点发生故障,需要做故障转移,可以手动转移:让其中一个slave变成master:哨兵 66 #2 主从复制,只能主写数据,所以写能力和存储能力有限:集群 67 68 69 #### 3 哨兵原理 70 可以做故障判断,故障转移,通知客户端(其实是一个进程),客户端直接连接sentinel的地址 71 1 多个sentinel发现并确认master有问题 72 2 选举触一个sentinel作为领导 73 3 选取一个slave作为新的master 74 4 通知其余slave成为新的master的slave 75 5 通知客户端主从变化 76 6 等待老的master复活成为新master的slave 77 78 79 80 ## 4 搭建步骤 81 ## 4.1 哨兵1 配置文件 82 port 26379 83 daemonize yes 84 dir data 85 protected-mode no 86 bind 0.0.0.0 87 logfile "redis_sentinel.log" 88 89 sentinel monitor mymaster 127.0.0.1 6379 2 90 sentinel auth-pass mymaster "654321" 91 sentinel down-after-milliseconds mymaster 30000 92 sentinel parallel-syncs mymaster 1 93 sentinel failover-timeout mymaster 180000 94 ## 4.2 哨兵2 配置文件 95 port 26380 96 daemonize yes 97 dir data 98 protected-mode no 99 bind 0.0.0.0 100 logfile "redis_sentinel.log" 101 sentinel monitor mymaster 127.0.0.1 6379 2 102 sentinel auth-pass mymaster "654321" 103 sentinel down-after-milliseconds mymaster 30000 104 sentinel parallel-syncs mymaster 1 105 sentinel failover-timeout mymaster 180000 106 ## 4.2 哨兵3 配置文件 107 port 26381 108 daemonize yes 109 dir data 110 protected-mode no 111 bind 0.0.0.0 112 logfile "redis_sentinel.log" 113 114 sentinel monitor mymaster 127.0.0.1 6379 2 115 sentinel auth-pass mymaster "654321" 116 sentinel down-after-milliseconds mymaster 30000 117 sentinel parallel-syncs mymaster 1 118 sentinel failover-timeout mymaster 180000 119 120 ### 4.4 启动3个哨兵 121 redis-sentinel ./sentinel_26379.conf 122 redis-sentinel ./sentinel_26380.conf 123 redis-sentinel ./sentinel_26381.conf 124 125 126 ### 4.5 链接哨兵 127 redis-cli -p 26379 128 # info 查看状态 129 130 131 ## 4.6 停止主库 132 -自动切换


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构