


(一些框架介绍)

1 # 1 sqlalchemy 企业级orm框架 2 官网:https://www.sqlalchemy.org/ 3 # 2 python界的orm框架 4 -1 django-orm #只能django框架用 5 -2 peewee # 小型orm框架:https://docs.peewee-orm.com/en/latest/peewee/quickstart.html 6 -----同步orm框架----- 7 -3 sqlalchemy # 企业级,使用非常广泛:https://docs.sqlalchemy.org/en/20/orm/quickstart.html # 可以用在flask上,还可以用在fastapi 8 ---中间态---- 9 -4 Tortoise ORM # fastapi用的比较多 10 11 # 3 django ,flask---》同步框架--》新版本支持异步 12 13 # 4 fastapi,sanic,tornado---》异步框架--》支持同步的写法--》如果在异步框架上写同步 14 -众多第三方库---》都是同步的--》导致异步框架性能发挥不出来 15 -redis:aioredis --》redis-py 16 -mysql:aiomysql --》pymysql
[快速使用]
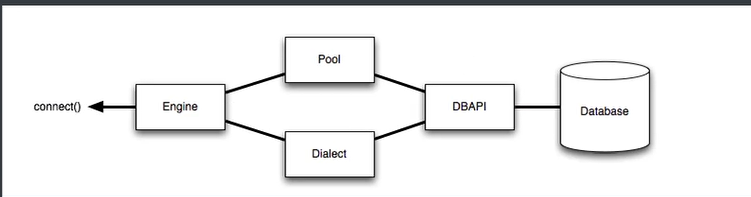
1 # 1 安装 pip install sqlalchemy 2 - 2.0.30版本 3 4 # 2 架构 5 Engine,框架的引擎 6 Connection Pooling ,数据库连接池 7 Dialect,选择连接数据库的DB API种类 8 SQL Exprression Language,SQL表达式语言 9 10 # 3 链接不同数据库 11 3.1 postgresql 12 # default 13 engine = create_engine("postgresql://scott:tiger@localhost/mydatabase") 14 # psycopg2 15 engine = create_engine("postgresql+psycopg2://scott:tiger@localhost/mydatabase") 16 # pg8000 17 engine = create_engine("postgresql+pg8000://scott:tiger@localhost/mydatabase") 18 19 3.2 Mysql 20 # default 21 engine = create_engine("mysql://scott:tiger@localhost/foo") 22 # mysqlclient (a maintained fork of MySQL-Python) 23 engine = create_engine("mysql+mysqldb://scott:tiger@localhost/foo") 24 # PyMySQL 25 engine = create_engine("mysql+pymysql://scott:tiger@localhost/foo") 26 27 3.3 oracle 28 engine = create_engine("oracle://scott:tiger@127.0.0.1:1521/sidname") 29 engine = create_engine("oracle+cx_oracle://scott:tiger@tnsname") 30 31 3.4 Microsoft SQL Server 32 pyodbc 33 engine = create_engine("mssql+pyodbc://scott:tiger@mydsn") 34 pymssql 35 engine = create_engine("mssql+pymssql://scott:tiger@hostname:port/dbname") 36 37 3.5 sqlite 38 Unix/Mac - 4 initial slashes in total 39 engine = create_engine("sqlite:////absolute/path/to/foo.db") 40 Windows 41 engine = create_engine("sqlite:///C:\\path\\to\\foo.db") 42 Windows alternative using raw string 43 engine = create_engine(r"sqlite:///C:\path\to\foo.db")
【sqlalchemy 原生操作】
1 import threading 2 # 1 创建 engin 3 from sqlalchemy import create_engine 4 5 engine = create_engine( 6 "mysql+pymysql://root:199721@127.0.0.1:3306/choose_classes?charset=utf8", 7 max_overflow=0, # 超过连接池大小外最多创建的连接 8 pool_size=5, # 连接池大小 9 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 10 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) 11 ) 12 13 14 # 2 原生操作mysql---》用了连接池---》就可以不用dbutils模块了 15 def task(): 16 conn = engine.raw_connection() 17 cursor = conn.cursor() 18 cursor.execute( 19 "select * from school" 20 ) 21 result = cursor.fetchall() 22 print(result) 23 cursor.close() # 把链接放回到链接池 24 conn.close() 25 26 27 for i in range(20): 28 t = threading.Thread(target=task) 29 t.start()

【sqlalchemy操作表】
1 from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index 2 import datetime 3 # 第一步:创建基类,以后所有类,都必须继承基类 4 5 # 1 老版本创建基类(不建议) 6 # from sqlalchemy.ext.declarative import declarative_base 7 # Base = declarative_base() 8 9 # 2 新版本创建基类 10 from sqlalchemy.orm import DeclarativeBase 11 12 13 class Base(DeclarativeBase): 14 pass 15 16 17 # 第二步:写个类,继承 18 # 第三步:写字段:传统方式,类型方式 19 class User(Base): 20 __tablename__ = 'user' # 指定表名 21 id = Column(Integer, primary_key=True, autoincrement=True) 22 name = Column(String(32), index=True, nullable=False) # name列varchar32,索引,不可为空 23 email = Column(String(32), unique=True) # email 列,varchar32,唯一 24 # datetime.datetime.now不能加括号,加了括号,以后永远是当前时间 25 ctime = Column(DateTime, default=datetime.datetime.now) 26 extra = Column(Text, nullable=True) 27 28 29 if __name__ == '__main__': 30 from sqlalchemy import create_engine 31 32 engine = create_engine( 33 "mysql+pymysql://root:199721@127.0.0.1:3306/test2?charset=utf8", 34 max_overflow=0, # 超过连接池大小外最多创建的连接 35 pool_size=5, # 连接池大小 36 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 37 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) 38 ) 39 # 第四步:创建表(不能创建库,只能新增或删除表,不能增加删除字段) 40 Base.metadata.create_all(engine) 41 42 # 第五步:删除表 43 # Base.metadata.drop_all(engine)

【增删查改】
模型表:
1 from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index 2 import datetime 3 # 第一步:创建基类,以后所有类,都必须继承基类 4 5 # 1 老版本创建基类(不建议) 6 # from sqlalchemy.ext.declarative import declarative_base 7 # Base = declarative_base() 8 9 # 2 新版本创建基类 10 from sqlalchemy.orm import DeclarativeBase 11 12 13 class Base(DeclarativeBase): 14 pass 15 16 17 # 第二步:写个类,继承 18 # 第三步:写字段:传统方式,类型方式 19 class User(Base): 20 __tablename__ = 'user' # 指定表名 21 id = Column(Integer, primary_key=True, autoincrement=True) 22 name = Column(String(32), index=True, nullable=False) # name列varchar32,索引,不可为空 23 email = Column(String(32), unique=True) # email 列,varchar32,唯一 24 # datetime.datetime.now不能加括号,加了括号,以后永远是当前时间 25 ctime = Column(DateTime, default=datetime.datetime.now) 26 extra = Column(Text, nullable=True) 27 28 def __str__(self): 29 return self.name 30 31 # 放在别的对象里面触发的是repr 32 def __repr__(self): 33 return self.name 34 35 36 if __name__ == '__main__': 37 from sqlalchemy import create_engine 38 39 engine = create_engine( 40 "mysql+pymysql://root:199721@127.0.0.1:3306/test2?charset=utf8", 41 max_overflow=0, # 超过连接池大小外最多创建的连接 42 pool_size=5, # 连接池大小 43 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 44 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) 45 ) 46 # 第四步:创建表(不能创建库,只能新增或删除表,不能增加删除字段) 47 Base.metadata.create_all(engine) 48 49 # 第五步:删除表 50 # Base.metadata.drop_all(engine)
1 from models import User 2 # 第一步:创建engine 3 from sqlalchemy import create_engine 4 5 engine = create_engine( 6 "mysql+pymysql://root:199721@127.0.0.1:3306/test2?charset=utf8", 7 max_overflow=0, # 超过连接池大小外最多创建的连接 8 pool_size=5, # 连接池大小 9 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 10 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) 11 ) 12 13 # 第二步:创建 session对象---老方式 14 # from sqlalchemy.orm import sessionmaker 15 # Session = sessionmaker(bind=engine) 16 # session=Session() 17 # 第二步:创建 session对象---新方式(推荐) 18 from sqlalchemy.orm import Session 19 20 session = Session(engine) 21 22 # 第三步:使用session对象 23 # 1 新增 24 user1 = User(name='jh', email='333@qq.com') 25 user2 = User(name='cxx', email='335@qq.com') 26 # session.add(user) 27 session.add_all([user1, user2]) 28 session.commit() # 提交事务 29 session.close() 30 31 # 2 搜索--》简单 32 res = session.query(User).filter_by(name='cxx').all() 33 res = session.query(User).filter_by(id=1).all() 34 print(res) # [<models.User object at 0x000002601E3A8610>] 35 print(res[0]) 36 # 打印的都是对象,重写方法 37 # def __repr__(self): 38 # return self.name 39 40 # 3 删除 41 res = session.query(User).filter_by(name='cxx').delete() 42 print(res) 43 session.commit() 44 45 # 4 修改 46 res = session.query(User).filter_by(id=1).update({'name': 'ooo'}) 47 session.commit() 48 user = session.query(User).filter_by(id=1).first() 49 print(user.id) 50 user.name = 'uuii' 51 session.add(user) # [id字段在不在] 如果对象不存在,就是新增,如果对象存在,就是修改 52 session.commit()
【表关系】
一对多关系
模型表基于上述模型表新增
1 from sqlalchemy.orm import relationship 2 3 # 一对多关系 4 class Hobby(Base): 5 __tablename__ = 'hobby' 6 id = Column(Integer, primary_key=True) 7 caption = Column(String(50), default='篮球') 8 9 def __str__(self): 10 return self.caption 11 12 13 class Person(Base): 14 __tablename__ = 'person' 15 nid = Column(Integer, primary_key=True) 16 name = Column(String(32), index=True, nullable=True) 17 # hobby指的是tablename而不是类名 18 hobby_id = Column(Integer, ForeignKey("hobby.id")) # 一个爱好,可以被多个人喜欢,一个人只能喜欢一个爱好 19 20 # 跟数据库无关,不会新增字段,只用于快速链表操作 21 # 类名,backref用于反向查询 22 hobby = relationship('Hobby', backref='pers') 23 24 def __str__(self): 25 return self.name 26 27 def __repr__(self): 28 return self.name
1 from models import Person, Hobby 2 # 第一步:创建engine 3 from sqlalchemy import create_engine 4 5 engine = create_engine( 6 "mysql+pymysql://root:199721@127.0.0.1:3306/test2?charset=utf8", 7 max_overflow=0, # 超过连接池大小外最多创建的连接 8 pool_size=5, # 连接池大小 9 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 10 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) 11 ) 12 13 # 第二步:创建 session对象---老方式 14 from sqlalchemy.orm import Session 15 16 session = Session(engine) 17 18 if __name__ == '__main__': 19 # 笨办法增加 20 # 1 先增加一个hobby 21 hobby = Hobby() 22 session.add(hobby) 23 session.commit() 24 # 2 增加Person---》必须要有hobby_id 25 person = Person(name='wxx', hobby_id=1) 26 session.add(person) 27 session.commit() 28 29 # 简便方法--》增加person的同时,增加了Hobby 30 person = Person(name='lqz', hobby=Hobby(caption='乒乓球')) 31 session.add(person) 32 session.commit() 33 hobby = session.query(Hobby).filter_by(id=1).first() 34 person = Person(name='xh', hobby=hobby) 35 session.add(person) 36 session.commit() 37 38 # 基于对象的跨表查询--->正向 39 person = session.query(Person).filter_by(nid=2).first() 40 print(person) 41 print(person.hobby_id) 42 print(person.hobby) 43 44 # 基于对象的跨表查询--->反向 45 hobby = session.query(Hobby).filter_by(id=1).first() 46 print(hobby.caption) 47 print(hobby.pers)
【多对多】
1 表模型 2 3 4 # 多对多 5 class Boy2Girl(Base): 6 __tablename__ = 'boy2girl' 7 id = Column(Integer, primary_key=True, autoincrement=True) 8 girl_id = Column(Integer, ForeignKey('girl.id')) 9 boy_id = Column(Integer, ForeignKey('boy.id')) 10 # ctime=Column(DateTime, default=datetime.datetime.now) 11 def __str__(self): 12 return '%s-%s' % (self.boy_id, self.girl_id) 13 14 15 class Girl(Base): 16 __tablename__ = 'girl' 17 id = Column(Integer, primary_key=True) 18 name = Column(String(64), unique=True, nullable=True) 19 def __str__(self): 20 return self.name 21 22 23 class Boy(Base): 24 __tablename__ = 'boy' 25 id = Column(Integer, primary_key=True, autoincrement=True) 26 name = Column(String(64), unique=True, nullable=True) 27 girls = relationship('Girl', secondary='boy2girl', backref='boys') 28 29 def __str__(self): 30 return self.name 31 32 ----------------------------------------------------------------------- 33 from models import Person, Hobby, Boy, Girl, Boy2Girl 34 # 第一步:创建engine 35 from sqlalchemy import create_engine 36 37 engine = create_engine( 38 "mysql+pymysql://root:199721@127.0.0.1:3306/test2?charset=utf8", 39 max_overflow=0, # 超过连接池大小外最多创建的连接 40 pool_size=5, # 连接池大小 41 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 42 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) 43 ) 44 45 # 第二步:创建 session对象---老方式 46 from sqlalchemy.orm import Session 47 48 session = Session(engine) 49 50 if __name__ == '__main__': 51 # 新增记录--笨办法 52 boy1 = Boy(name='张三') 53 boy2 = Boy(name='李四') 54 girl1 = Girl(name='小芳') 55 girl2 = Girl(name='小梅') 56 # 先将男孩和女孩添加到session中 57 session.add_all([boy1, boy2, girl1, girl2]) 58 session.commit() 59 # 往中间表中添加数据 60 res = Boy2Girl(girl_id=1, boy_id=1) 61 print(res) 62 session.add_all([res]) 63 session.commit() 64 65 # 简单方法新增 66 # 先查询 67 boys = session.query(Boy).filter(Boy.id >= 1).all() 68 girls = session.query(Girl).filter(Girl.id >= 1).all() 69 print(boys, girls) 70 # 让id为1的男生和id和所有姑娘建立关系 71 boy = session.query(Boy).filter(Boy.id == 1).all()[0] 72 boy.girls = girls 73 session.add(boy) 74 session.commit() 75 76 # 基于对象的跨表查询--正向查询 77 boy = session.query(Boy).filter(Boy.id == 1).all()[0] 78 print(boy.name) 79 print(boy.girls) 80 81 # 基于对象的跨表查询--反向查询 82 girl = session.query(Girl).filter(Girl.id == 1).all()[0] 83 print(girl.name) 84 print(girl.boys)
【scoped线程安全】
# 1 如果我们把session 做成全局 单例
-每个视图函数,用同一个session,有问题
#2 如果在每个视图函数中,都对session实例化一次
-代码有点麻烦
# 3 全局就用一个session对象,它在不同线程中---》都是这个线程自己的
1 from models import User 2 import threading 3 # 第一步:创建engine 4 from sqlalchemy import create_engine 5 6 engine = create_engine( 7 "mysql+pymysql://root:199721@127.0.0.1:3306/sqlalchemy001?charset=utf8", 8 max_overflow=0, # 超过连接池大小外最多创建的连接 9 pool_size=5, # 连接池大小 10 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 11 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) 12 ) 13 14 # 第二步:创建 线程安全的 session 15 from sqlalchemy.orm import sessionmaker 16 from sqlalchemy.orm import scoped_session 17 18 Session = sessionmaker(bind=engine) 19 session = scoped_session(Session) 20 21 22 # 第三步:正常使用-->再flask中,使用全局的session即可,实现:不同线程使用线程自己的session对象 23 def task(se, i): 24 session = se() 25 session.add(User(name='xxx', email=f'{i}@qq.com')) 26 session.commit() 27 print('=========', session) 28 29 30 if __name__ == '__main__': 31 l = [] 32 for i in range(10): 33 t = threading.Thread(target=task, args=[session, i]) 34 t.start() 35 l.append(t) 36 for i in l: 37 i.join()
。
。
【更多查询】
1 from models import Person, Hobby, Boy, Girl, Boy2Girl, User 2 # 第一步:创建engine 3 from sqlalchemy import create_engine 4 5 engine = create_engine( 6 "mysql+pymysql://root:199721@127.0.0.1:3306/test2?charset=utf8", 7 max_overflow=0, # 超过连接池大小外最多创建的连接 8 pool_size=5, # 连接池大小 9 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 10 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) 11 ) 12 13 # 第二步:创建 session对象---老方式 14 from sqlalchemy.orm import Session 15 16 session = Session(engine) 17 18 if __name__ == '__main__': 19 # filter_by查询 写参数 20 res = session.query(User).filter_by(name='jh', id=9).all() # 返回列表 21 res = session.query(User).filter_by(name='jh').first() # 返回单条 22 23 # filter查询 写条件 24 res = session.query(User).where(User.id == 1).all() 25 res = session.query(User).filter(User.id == 1).all() 26 27 # between查询 28 res = session.query(User).filter(User.id.between(1, 10), User.name == 'jh').all() 29 30 # in 31 res = session.query(User).filter(User.id.in_([1, 2, 3])).all() 32 33 # ~ 除。。外 34 res = session.query(User).filter(~User.id.in_([1, 2, 3])).all() 35 36 # 二次筛选 37 res = session.query(User).filter(User.id.in_(session.query(User.id).filter_by(name='jh'))).all() 38 39 # and,or条件 40 from sqlalchemy import and_, or_ 41 42 res = session.query(User).filter(and_(User.id > 3, User.name == 'jh')).all() 43 res = session.query(User).filter(or_(User.id > 9, User.name == 'jh')).all() 44 res = session.query(User).filter( 45 or_(User.id < 2, 46 and_(User.name == 'wxx', User.id > 8), 47 User.extra != "") 48 ).all() 49 50 # 通配符,以j开头,不以j开头 51 res = session.query(User).filter(User.name.like('j%')).all() 52 res = session.query(User).filter(~User.name.like('j%')).all() 53 54 # 限制,用于分页,区间 55 res = session.query(User)[0:3] 56 # 拿第三页数据 57 res = session.query(User)[2:5] 58 59 # 排序,按照name降序排列 60 res = session.query(User).order_by(User.name.asc()).all() 61 # 第一个条件重复后,再按照第二个条件升序 62 res = session.query(User).order_by(User.name.desc(), User.id.asc()).all() 63 64 # 分组 65 from sqlalchemy.sql import func 66 67 res = session.query(User).group_by(User.name).all() 68 # 分组之后取最大id,id之和,最小id 69 res = session.query( 70 func.max(User.id), 71 func.sum(User.id), 72 func.min(User.id)).group_by(User.name).all() 73 74 # having筛选 75 res = session.query( 76 func.max(User.id), 77 func.sum(User.id), 78 func.min(User.id), User.name).filter(User.id >= 1).group_by(User.name).having(func.min(User.id) > 4).all() 79 80 # 笛卡尔积连表操作 81 res = session.query(Person, Hobby).filter(Person.hobby_id == Hobby.id).all() 82 83 # join表,默认是inner join 84 res = session.query(Person).join(Hobby).all() 85 # 外连isouter=True,表示Person left join Favor,没有连接, 86 res = session.query(Person).join(Hobby, isouter=True).all() 87 88 # 打印原生sql 89 res = session.query(Person).join(Hobby, isouter=True) 90 91 # 自己指定on条件,第二个参数,支持on多个条件,用and_ 92 res = session.query(Person).join(Hobby, Person.nid == Hobby.id, isouter=True).all() 93 94 print(res)
。
。
【flask-sqlalchemy使用】
1 # 有个第三方flask-sqlalchemy,帮助咱们快速的集成到flask中 2 3 4 # 使用flask-sqlalchemy模块的步骤 5 6 from flask_sqlalchemy import SQLAlchemy # 1 导入 7 db = SQLAlchemy() # 2 # SQLAlchemy类实例化生成db对象 8 # 后续我们去操作数据库的时候 db.session 生成的 9 # 就是原来的我们用scoped_session(Session类)生成的连接对象db_session 10 11 12 db.init_app(app) # 3 将db注册到app中 一般写在蓝图注册代码的下面 13 # 上面几几句话,一般写在项目的包文件下的__init__文件里 从创建app对象、生成db对象、注册蓝图对象、 14 # 最后将db对象注册到app对象中去,这样项目包下的__init__文件差不多也就写完了 15 16 17 # 4 视图函数中使用数据库连接对象, 18 # 直接导入__init__的db对象,用db.session 就拿到了连接对象了!!! 19 全局的db.session # 线程安全的 20 21 22 23 # 5 models.py 中模型类要继承Model 24 # 原来用sqlalchemy的时候模型类继承的是Base Base=declarative_base() c产生的 25 class User(db.Model): 26 username = db.Column(db.String(80), unique=True, nullable=False) 27 28 29 # 6 写字段,需要用db.Column() 原来sqlalchemy是直接 Column() 30 username = db.Column(db.String(80), unique=True, nullable=False) 31 32 33 34 # 7 配置文件中配置下连接地址与数据库连接池参数,就是我们之前生成的引擎对象的参数 35 # 这个样在生成db对象的时候,就已经把引擎的参数绑定进去了 36 SQLALCHEMY_DATABASE_URI = "mysql+pymysql://root@127.0.0.1:3306/ddd?charset=utf8" 37 SQLALCHEMY_POOL_SIZE = 100 # 设置连接池的大小,别设太小 38 SQLALCHEMY_POOL_TIMEOUT = 600 # 池中没有连接,最多等待时间,超过还没拿到就报错!!! 39 SQLALCHEMY_POOL_RECYCLE = 1800 # -1 表示不回收 1800秒后回收掉该连接对象 40 # 追踪对象的修改并且发送信号 41 SQLALCHEMY_TRACK_MODIFICATIONS = False 42 43 44 # 池数量设的小,超时等待时间也设定小,容易触发超时等待的报错,导致后端崩掉!!!
【flask-sqlalchemy 使用代码示范】
1 src目录下的init文件代码 2 3 from flask import Flask, request, current_app 4 from flask_cors import CORS 5 6 # 引入Flask-SQLAlchemy 7 from flask_sqlalchemy import SQLAlchemy 8 9 db = SQLAlchemy() # 实例化SQLAlchemy 10 11 # 引入蓝图 12 from .blueprints import auth 13 from .blueprints import organization 14 15 16 # 引入模型 17 from app_flask_service.models.flasksqlalchemy_models_app import * 18 19 import settings 20 import logging 21 import logging.handlers 22 23 24 # 创建app 25 def create_app(): 26 app = Flask(__name__) 27 CORS(app, resources=r'/*') #解决跨域的 28 app.debug = False 29 app.secret_key = 'shdtw' # 自定义的session秘钥 30 31 # 设置配置文件 32 product_cfg = settings.ProductionConfig() 33 app.config.from_object(product_cfg) 34 35 # 定义日志记录器 36 logging.basicConfig(level=logging.INFO) 37 logger = logging.getLogger('app') 38 logger.setLevel(logging.INFO) 39 40 # 配置 logger 写入 rotating日志文件 41 file_handler = logging.handlers.RotatingFileHandler('./logs/log_app.log', maxBytes=1024 * 1024 * 10, backupCount=5) 42 file_handler.setLevel(logging.INFO) 43 file_handler.setFormatter(logging.Formatter('%(asctime)s %(levelname)s %(message)s')) 44 logger.addHandler(file_handler) 45 46 47 # 注册蓝图 48 app.register_blueprint(auth.blueprint, url_prefix='/auth') 49 app.register_blueprint(organization.blueprint, url_prefix='/organization') 50 51 52 db.init_app(app) 53 54 return app 55 56 ----------------------------------------- 57 58 settings配置文件 59 60 TOKEN_EXPIRE_TIME = 3600 # token生成时设置的过期时间(秒) 61 62 APP_DB_CONF = { 63 'DB_type': 'mysql', 64 'DBAPI': 'pymysql', 65 'IP_address': '192.168.11.99', # 本机:'localhost', 生产环境:'58.40.119.146', 66 'port': '3306', # 本机:'3306', 生产环境:'xxxx', 67 'username': 'root', 68 'pwd': 'root123', 69 'path': 'shctwl_qr_jingan' 70 } 71 72 73 ## 基础信息配置信息 --> 74 75 def db_uri(config): 76 return "{db_type}+{dbapi}://{username}:{pwd}@{ip_address}:{port}/{path}".format( 77 db_type=config['DB_type'], 78 dbapi=config['DBAPI'], 79 username=config['username'], 80 pwd=config['pwd'], 81 ip_address=config['IP_address'], 82 port=config['port'], 83 path=config['path'] 84 ) 85 86 87 class BaseConfig(object): 88 JSON_AS_ASCII = False 89 JSON_SORT_KEYS = False 90 JSONIFY_MIMETYPE = "application/json;charset=utf-8" 91 92 SQLALCHEMY_DATABASE_URI = db_uri(APP_DB_CONF) + "?charset=utf8" # 数据库用户名:密码@host:port/数据库名?编码 93 SQLALCHEMY_TRACK_MODIFICATIONS = False # 如果设置成 True (默认情况),Flask-SQLAlchemy 将会追踪对象的修改并且发送信号。这需要额外的内存, 如果不必要的可以禁用它。 94 # SQLALCHEMY_ECHO = True 95 96 '''session绑定redis''' 97 ''' 98 SESSION_TYPE = 'redis' # session类型为redis 99 SESSION_KEY_PREFIX = 'session:' # 保存到session中的值的前缀 100 SESSION_PERMANENT = False # 如果设置为True,则关闭浏览器session就失效。 101 SESSION_USE_SIGNER = False # 是否对发送到浏览器上 session:cookie值进行加密 102 ''' 103 104 105 class ProductionConfig(BaseConfig): 106 SQLALCHEMY_POOL_SIZE = 100 107 SQLALCHEMY_POOL_TIMEOUT = 600 108 SQLALCHEMY_POOL_RECYCLE = 800 109 SQLALCHEMY_MAX_OVERFLOW = 50 # 控制在连接池达到最大值后可以创建的连接数。当这些额外的 连接回收到连接池后将会被断开和抛弃。 110 111 SQLALCHEMY_ENGINE_OPTIONS = { 112 'pool_size': 100, 113 'pool_timeout': 600, 114 'pool_recycle': 800, 115 'max_overflow': 50, 116 'pool_pre_ping': True 117 } 118 119 120 class DevelopmentConfig(BaseConfig): 121 SQLALCHEMY_POOL_SIZE = 50 122 SQLALCHEMY_POOL_TIMEOUT = 300 123 SQLALCHEMY_POOL_RECYCLE = -1 124 SQLALCHEMY_MAX_OVERFLOW = 20 # 控制在连接池达到最大值后可以创建的连接数。当这些额外的 连接回收到连接池后将会被断开和抛弃。 125 126 127 class TestingConfig(BaseConfig): 128 SQLALCHEMY_POOL_SIZE = 50 129 SQLALCHEMY_POOL_TIMEOUT = 300 130 SQLALCHEMY_POOL_RECYCLE = -1 131 SQLALCHEMY_MAX_OVERFLOW = 20 # 控制在连接池达到最大值后可以创建的连接数。当这些额外的 连接回收到连接池后将会被断开和抛弃。 132 133 ---------------------------------------- 134 135 # 启动文件 service_server.py 136 import os, sys 137 138 sys.path.append(os.path.dirname(os.path.abspath(__file__))) 139 140 from gevent import monkey 141 142 monkey.patch_all() 143 144 from app_flask_service import * 145 from utils.uwsgi_server.server_gevent import * # 见下面的文件 146 147 # from utils.uwsgi_server.server_flask_debug import * 148 149 app = create_app() 150 151 if __name__ == "__main__": 152 print('垃圾品质识别系统接口服务启动……') 153 server = uwsgi_server(app=app, address='0.0.0.0', port=5000) 154 # server = uwsgi_server(app=app, address='0.0.0.0', port=39090) 155 server.start() 156 157 ---------------------------------------------- 158 159 # server_gevent.py文件 160 161 import os,sys 162 sys.path.append(os.path.dirname(os.path.abspath(__file__))) 163 164 from gevent.pywsgi import WSGIServer 165 166 import urllib3 167 urllib3.disable_warnings() 168 169 170 class uwsgi_server(): 171 def __init__(self,app,address='0.0.0.0',port=5000) -> None: 172 self.server = WSGIServer((address, port), app) 173 174 def start(self): 175 self.server.serve_forever()
使用flask-sqlalchemy模块的时候注意事项
# 一般把创app的代码都封装到create_app方法中
# 使用flask_sqlalchemy的时候,如果不在视图函数操作数据库或者使用Flask的全局变量,
# 需要先
app.app_context():
把操作数据库的代码写在这儿
# 不然会报错!!! 说什么不在请求上下文里面什么的!!!
。
。
【flask-migrate使用】
1 # 表发生变化,都会有记录,自动同步到数据库中 2 3 # 原生的sqlalchemy,不支持修改表的 4 # flask-migrate可以实现类似于django的 5 python manage.py makemigrations # 记录 6 python manage.py migrate # 真正的同步到数据库 7 8 ----------------------------------------------------------- 9 10 # 使用步骤 11 flask:2.2.2 flask-script:2.0.3 12 13 第一步:安装,依赖于flask-script 14 pip3.8 install flask-migrate==2.7.0 15 16 --------------------- 17 18 2 在app所在的py文件中 19 from flask_script import Manager 20 from flask_migrate import Migrate, MigrateCommand 21 manager = Manager(app) 22 Migrate(app, db) 23 manager.add_command('db', MigrateCommand) 24 manager.run() # 以后使用python manage.py runserver 启动项目 25 26 27 3 以后第一次执行一下 28 python manage.py db init # 生成一个migrations文件夹,里面以后不要动,记录迁移的编号 29 30 31 4 以后在models.py 写表,加字段,删字段,改参数 32 33 34 5 只需要执行 35 python manage.py db migrate # 记录 36 python manage.py db upgrade # 真正的同步进去
。
。
。
。
。
开源项目:
Pear Admin/Pear Admin Flask


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构