
【纯手撸web框架】
1 1.web框架的本质 2 理解1: 连接前端与数据库的中间介质 3 理解2: socket服务端 4 --------------------------------------------- 5 2.手写web框架 6 1.编写socket服务端代码 7 2.浏览器访问响应无效>>>:HTTP协议 8 3.根据网址后缀的不同获取不同的页面内容 9 4.想办法获取到用户输入的后缀>>>:请求数据 10 5.请求首行 11 GET /login HTTP/1.1 12 GET请求 13 朝别人索要数据 14 POST请求 15 朝别人提交数据 16 6.处理请求数据获取网址后缀 17 18 19 第一步:python代码创建服务端 20 浏览器输入 127.0.0.1:8880 就可以看到服务端发来的hello web消息 21 22 import socket 23 24 server = socket.socket() 25 server.bind(('127.0.0.1', 8880)) 26 server.listen(5) 27 28 while True: 29 conn, addr = server.accept() 30 data = conn.recv(1024) 31 # print(data) 二进制数据 32 print(data.decode('utf-8')) 33 # 获取字符串中特定的内容 34 conn.send(b'HTTP/1.1 200 OK\r\n\r\nhello web') 35 conn.close() 36 37 38 ------------------------------------------------------------------------------------- 39 第二步:根据网址后缀的不同获取不同的页面内容 40 上面的代码无论后缀敲什么,只要前面的ip与端口号对的,就一直在页面上显示的hello web 41 想实现 浏览器输入 127.0.0.1:8880/xxxx 42 根据ip与端口号后面的输入的 /xxxx后缀 的不同,网页实现出现不同的内容!!! 43 想办法在服务端获取到用户输入的后缀>>>:从接收到的客户端 请求数据 里面找!!! 44 用户输入的后缀 藏在请求首行里面了!!! 45 处理请求数据获取网址后缀, 46 就是现在想办法从接收到的一大串的请求数据里面精准的拿到请求首行里面藏着的网址后缀!!! 47 48 49 50 while True: 51 conn, addr = server.accept() 52 data = conn.recv(1024) 53 # print(data) 二进制数据 54 data = data.decode('utf-8') # 字符串 55 # 获取字符串中特定的内容,按照空格切割字符串并取第一个索引值 56 conn.send(b'HTTP/1.1 200 OK\r\n\r\nhello web') 57 current_path = data.split(' ')[1] 58 # print(current_path) 59 # 第三步:通过判断来返回不同内容 60 # 根据拿到的后缀名,判断,然后发送不同的消息给客户端 61 # 这样就实现了用户输入的网页后缀不同,而显示不同的网页内容的效果了!!! 62 if current_path == '/index': 63 conn.send(b'hello index') 64 with open('mysq.html', 'rb') as f: 65 conn.send(f.read()) 66 elif current_path == '/login': 67 conn.send(b'hello login') 68 else: 69 conn.send(b'not found') 70 conn.close()
针对我们自己写的框架,发现很多问题:
1.代码冗余
2.手动处理http格式的数据,并且只能拿到url后缀,其他数据获取繁琐
3.并发的问题
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
这时候我们就借助于第三方模块wsgiref模块
【wsgiref模块】
1 内置模块 很多web框架底层使用的模块 2 3 Web服务器网关接口(Web Server Gateway Interface,缩写为WSGI) 4 是为Python语言定义的Web服务器和Web应用进程或框架之间的一种简单而通用的接口。 5 自从WSGI被开发出来以后,许多其它语言中也出现了类似接口。 6 7 reference 参考;提及 8 ---------------------------------- 9 功能1:封装了socket代码!!! 10 功能2:处理了请求数据!!! 11 --------------------------------------------------- 12 13 1.固定代码启动服务端 14 2.查看处理之后的request大字典 15 3.根据不同的网址后缀返回不同的内容>>>:研究大字典键值对 16 4.立刻解决上述纯手撸的两个问题 17 5.针对最后一个问题代码如何优化 18 19 20 # 模块可以直接导入 21 from wsgiref.simple_server import make_server 22 23 24 def run(env, response): 25 ''' 26 :param env: 请求相关的所有数据 27 :param response: 响应相关的所有数据 28 :return:返回给浏览器的数据 29 ''' 30 # print(env) # 打印请求的相关数据,大字典,wsgiref模块帮我们处理好http格式的数据 31 response('200 OK', []) # 响应首行,响应头 32 return [b'hello'] # 响应体 33 34 35 if __name__ == '__main__': 36 server = make_server('127.0.0.1', 8000, run) 37 ''' 38 会实时监听127.0.0.1:8000地址,只要有客户端来, 39 都会交给run函数处理(加括号触发run函数的运行) 40 41 flask启动源码 42 make_server('127.0.0.1', 8000, obj) 43 触发__call__ 44 ''' 45 server.serve_forever() # 启动服务端

根据不同的网站后缀返回不同的内容
1 from wsgiref.simple_server import make_server 2 3 4 def run(env, response): 5 ''' 6 :param env: 请求相关的所有数据 7 :param response: 响应相关的所有数据 8 :return:返回给浏览器的数据 9 ''' 10 # print(env) # 打印请求的相关数据,大字典,wsgiref模块帮我们处理好http格式的数据 11 response('200 OK',[]) 12 # 从env中取出请求的路径 13 path = env.get('PATH_INFO') 14 if path == '/index': 15 return [b'hello index'] 16 elif path == '/login': 17 return [b'hello login'] 18 return [b'404 not found'] 19 20 21 if __name__ == '__main__': 22 server = make_server('127.0.0.1', 8000, run) 23 server.serve_forever() # 启动服务端
继续优化-------代码封装
1 from wsgiref.simple_server import make_server 2 3 4 # 如果网站有很多个url,处理办法 5 def index(env): 6 return 'index' 7 8 9 def login(env): 10 return 'login' 11 12 13 def not_found(env): 14 return 'not found' 15 16 17 # url与函数的对应关系 18 urls = [ 19 ('/index', index), 20 ('/login', login), 21 ] 22 23 24 def run(env, response): 25 ''' 26 :param env: 请求相关的所有数据 27 :param response: 响应相关的所有数据 28 :return:返回给浏览器的数据 29 ''' 30 # print(env) # 打印请求的相关数据,大字典,wsgiref模块帮我们处理好http格式的数据 31 response('200 OK', []) 32 # 从env中取出请求的路径 33 path = env.get('PATH_INFO') 34 # 遍历urls中的所有url 35 # 定义一个变量,存储匹配到的函数名 36 func = None 37 for url in urls: 38 if path == url[0]: 39 # 将url对应的函数名赋值给func 40 func = url[1] 41 break # 匹配到一个之后,应该立刻结束for循环 42 # 判断func是否为空 43 if func: 44 res = func(env) 45 else: 46 res = not_found(env) 47 return [res.encode('utf-8')] 48 49 50 if __name__ == '__main__': 51 server = make_server('127.0.0.1', 8000, run) 52 server.serve_forever() # 启动服务端 53 54 55 =============================================== 56 其实我们还可以继续封装,按照不同的功能进行拆分 57 58 59 1.网址后缀的匹配问题 60 61 2.每个后缀匹配成功后执行的代码有多有少,假如判断后执行的代码有很多行, 62 都写在一起就不对劲了!!!所以要封装成函数了!!! 63 64 面条版 函数版 模块版 65 66 3.将分支的代码封装成一个个函数 67 68 4.将网址后缀与函数名做对应关系 69 70 5.获取网址后缀循环匹配 71 72 6.如果想新增功能只需要先写函数再添加一个对应关系即可 73 ------------------------------------------------------- 74 7.根据不同的功能拆分成不同的py文件 75 views.py 存储核心业务逻辑(功能函数) 76 urls.py 存储网址后缀与函数名对应关系 77 templates目录 存储html页面文件 78 --------------- 79 8.为了使函数体代码中业务逻辑有更多的数据可用 80 81 82 83 wsgiref.py 84 85 from wsgiref.simple_server import make_server 86 # 拆分导入 87 from urls import urls 88 from views import * 89 90 91 def run(env, response): 92 response('200 OK', []) 93 path = env.get('PATH_INFO') 94 func = None 95 for url in urls: 96 if path == url[0]: 97 func = url[1] 98 break # 匹配到一个之后,应该立刻结束for循环 99 # 判断func是否为空 100 if func: 101 res = func(env) 102 else: 103 res = not_found(env) 104 return [res.encode('utf-8')] 105 106 107 if __name__ == '__main__': 108 server = make_server('127.0.0.1', 8000, run) 109 server.serve_forever() # 启动服务端 110 111 112 113 ------------------------------------------------------------------------ 114 views.py 115 116 # 和url及wsgiref相关联,拆分 117 118 def index(env): 119 return 'index' 120 121 122 def login(env): 123 return 'login' 124 125 126 def not_found(env): 127 return 'not found' 128 129 130 def xxx(env): 131 with open(r'C:\Users\靳小洁\PycharmProjects\pythonProject\Day59\mysq.html', 'r', encoding='utf-8') as f: 132 return f.read() 133 134 135 136 import datetime 137 138 139 def get_time(env): 140 current_time = datetime.datetime.now().strftime('%Y-%m-%d') 141 # 如何将后端获取到的数据传递给html文件 142 with open(r'template/03 mytime.html', 'r', encoding='utf-8') as f: 143 data = f.read() 144 # data就是一堆字符串 145 data = data.replace('abdcfgs', current_time) # 在后端将html页面处理好之后再返回给前端 146 return data 147 148 ---------------------------------------------------------------------------------------- 149 urls.py 150 151 # 和wsgiref文件相关联 152 from views import * 153 154 # url与函数的对应关系 155 156 157 urls = [ 158 ('/index', index), 159 ('/login', login), 160 ('/xxx', xxx), 161 ('/get_time', get_time), 162 ] 163 164 165 ---------------------------------------------------------------------------------- 166 html 167 168 <!DOCTYPE html> 169 <html lang="en"> 170 <head> 171 <meta charset="UTF-8"> 172 <title>Title</title> 173 </head> 174 <body> 175 <h1>你好啊</h1> 176 </body> 177 </html>
【动静态网页】
1 动态网页 2 页面数据来源于后端,实时获取 3 静态网页 4 页面数据直接写死 5 ------------------------------------------- 6 需求1: 7 后端获取当前时间展示到html页面上 8 9 10 ----------------------------------- 11 需求2: 12 数据是从数据库中获取的展示到html页面上 13 14 15 16 动态网页制作 17 18 views 19 20 import datetime 21 22 23 def get_time(env): 24 current_time = datetime.datetime.now().strftime('%Y-%m-%d') 25 # 如何将后端获取到的数据传递给html文件 26 with open(r'template/03 mytime.html', 'r', encoding='utf-8') as f: 27 data = f.read() 28 # data就是一堆字符串 29 data = data.replace('abc', current_time) # 在后端将html页面处理好之后再返回给前端 30 return data 31 32 33 ------------------------------- 34 urls.py 35 36 urls = [ 37 ('/get_time', get_time), 38 ] 39 40 ------------------------------ 41 wsgiref不变,和上面一样 42 43 ------------------------------------- 44 html代码 45 46 <!DOCTYPE html> 47 <html lang="en"> 48 <head> 49 <meta charset="UTF-8"> 50 <title>Title</title> 51 </head> 52 <body> 53 <h1>我真的是一个html文件</h1> 54 abc 55 </body> 56 </html>
。
。
【模板语法之Jinja2模块】
jinja2是默认的模仿Django模板的一个模板引擎, 由flask的作者开发 它速度快 被广泛使用,
并且提供了可选的沙箱模板来保证执行环境安全
-------------------- Jinja2是基于python的模板引擎,作为一个模板系统,它还提供了特殊的语法, 我们按照它支持的语法进行编写之后,就能使用jinja2模块进行渲染。
jinja2模块终端下载
pip3 install jinja2
(需求:将一个字典传递给html文件,并且可以在文件上方便快捷的操作字典数据)
1 jinja2模板的作用: 2 能够将python后端的一些数据,传递到html文件上,然后在文件上用一些特殊的语法,把数据给操作好,数据弄好后,发送给前端浏览去展示!!! 3 --------------------------------------------------- 4 html文件是不支持后端任何语法的,只支持html css js 语法 5 -------------------------------------------- 6 需求2代码实现 7 html文件 8 <body> 9 <h1>获取字典数据</h1> 10 <p>{{ d1 }}</p> # 拿到user_dict字典整体了 11 <p>{{ d1.name }}</p> # 拿到user_dict字典里面name对应的值了 12 <p>{{ d1['age'] }}</p> 13 <p>{{ d1.get('person_list') }}</p> 14 </body> 15 -------------------------------- 16 urls = [('/get_dict', get_dict_func),] 17 -------------------------------- 18 views.py文件 19 20 from jinja2 import Template 21 22 def get_dict_func(request): 23 user_dict = {'name': 'jason', 'age': 18, 'person_list': ['阿珍', '阿强', '阿香', '阿红']} 24 with open(r'templates/get_dict_page.html', 'r', encoding='utf8') as f: 25 data = f.read() 26 27 temp_obj = Template(data) # 将页面数据交给模板处理 28 res = temp_obj.render({'d1': user_dict}) 29 # render方法支持给html页面传一些东西!!! 30 # 比如:变量名是d1,值是user_dict字典数据的数据!!! 31 return res
前端、后端、数据库三者联动
1 views.py 2 3 from jinja2 import Template 4 5 import pymysql 6 7 8 def get_user(env): 9 # 去数据库中获取数据,传递给html页面,借助于模板语法,发送给浏览器 10 conn = pymysql.connect( 11 host='127.0.0.1', 12 user='root', # sql账号 13 password='199721', # 密码 14 charset='utf8', 15 port=3306, # 端口号 16 database='day5', # 哪个库 17 autocommit=True # 针对增删改查自动确认 18 19 ) 20 21 cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) 22 sql = 'select * from info;' 23 affect_rows = cursor.execute(sql) # 发送sql语句 24 data_list = cursor.fetchall() 25 print(data_list) 26 # 将获取到的数据传递给html文件 27 with open(r'C:\Users\靳小洁\PycharmProjects\pythonProject\Day59\template\05 get_user.html', 'r', 28 encoding='utf-8') as f2: 29 data = f2.read() 30 tmp = Template(data) # 把页面交给jinjia2模板语法取操作 31 res = tmp.render(user_list=data_list) 32 return res 33 34 35 if __name__ == '__main__': 36 get_user(111) 37 38 39 ============================================== 40 urls.py 41 42 urls = [ 43 ('/get_user', get_user) 44 ] 45 46 47 ============================================== 48 html 49 50 <!DOCTYPE html> 51 <html lang="en"> 52 <head> 53 <meta charset="UTF-8"> 54 <title>Title</title> 55 <script src="JQ.js"></script> 56 <link href="bootstrap-3.4.1-dist/css/bootstrap.min.css" rel="stylesheet"> 57 <script src="bootstrap-3.4.1-dist/js/bootstrap.min.js"></script> 58 <link rel="stylesheet" href="bootstrap-sweetalert-master/dist/sweetalert.css"> 59 <script src="bootstrap-sweetalert-master/dist/sweetalert.min.js"></script> 60 </head> 61 <body> 62 <!--用表格形式展示出来--> 63 <div class="container"> 64 <div class="row"> 65 <div class="col-md-8 col-md-offset-2"> 66 <h1 class="text-center">用户数据</h1> 67 <table class="table table-hover table-striped"> 68 <thead> 69 <tr> 70 <th>ID</th> 71 <th>name</th> 72 <th>password</th> 73 <th>hobby</th> 74 </tr> 75 </thead> 76 <tbody> 77 {% for user_dict in user_list %} 78 <tr> 79 <td>{{ user_dict.id }}</td> 80 <td>{{ user_dict.name }}</td> 81 <td>{{ user_dict.password }}</td> 82 <td>{{ user_dict.hobby }}</td> 83 </tr> 84 {% endfor %} 85 </tbody> 86 </table> 87 </div> 88 </div> 89 </div> 90 {{user_list}} 91 </body> 92 </html>

【python主流web框架】
django
特点:大而全,自带的功能特别特别多,类似于航空母舰
缺点:重量级,性能一般
flask
特点:小而精,功能相对较少,类似于游骑兵
第三方的模块特别特别多,如果将flask和第三方模块结合起来,可以盖过django,并且越来越像
缺点:比较依赖于第三方模块
tornado
特点:异步非阻塞,性能高,单线程,适合长连接,支持高并发
厉害到可以开发游戏服务器
缺点:功能相对较少,不支持ORM
补充
fastapi框架
特点:fastapi框架,支持异步,比较快,内置了很多高级的功能
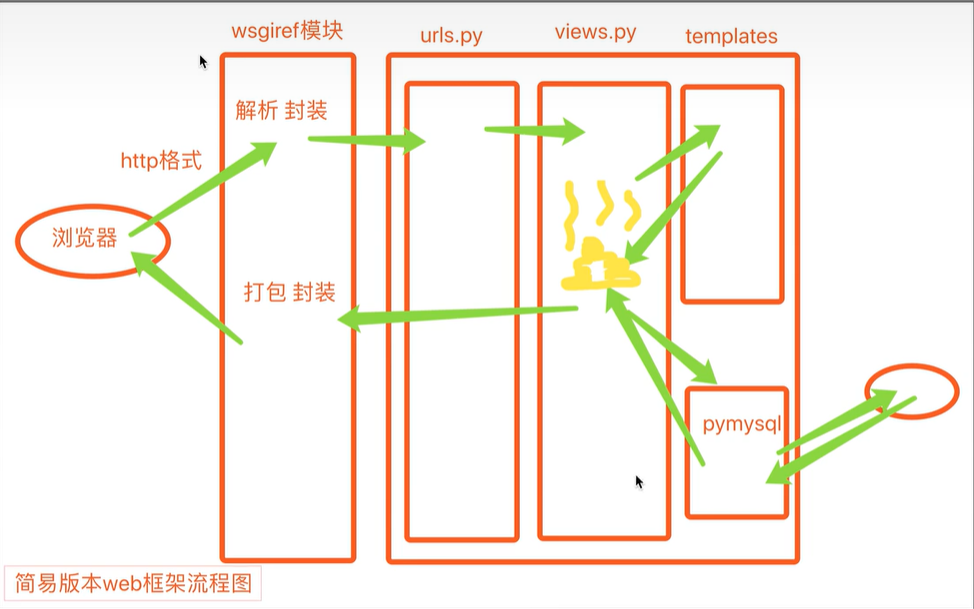
自定义框架可以分为三部分:
A部分:socket部分
B:路由与视图函数对应关系(路由匹配)
C:模板语法
django
A部分:用的是别人的 wsgiref模块
B部分:用的是自己的
C部分:用的是自己的(没有jinja2好用)
flask
A部分:用的是别人的 werkzeug模块(内部还是wsgiref)
B部分:自己写的
C部分:用的是别人的(jinja2)
torndoa
A.B.C都是自己写的
。
。
【django简介】
1 1.版本问题 2 django1.X:同步 1.11 3 django2.X:同步 2.2 4 django3.X:支持异步 3.2 5 django4.X:支持异步 4.2 6 ps:版本之间的差异其实不大 主要是添加了额外的功能 7 -------------------------------------------------------- 8 2.运行django注意事项: 9 10 1.django项目中所有的文件名目录名不要出现中文 11 12 2.计算机名称尽量也不要出现中文 13 14 3.一个pycharm页面,尽量就是一个完整的项目(不要嵌套 不要叠加) 15 16 4.不同版本的python解释器与不同版本的django可能会出现小问题
【django基本使用】
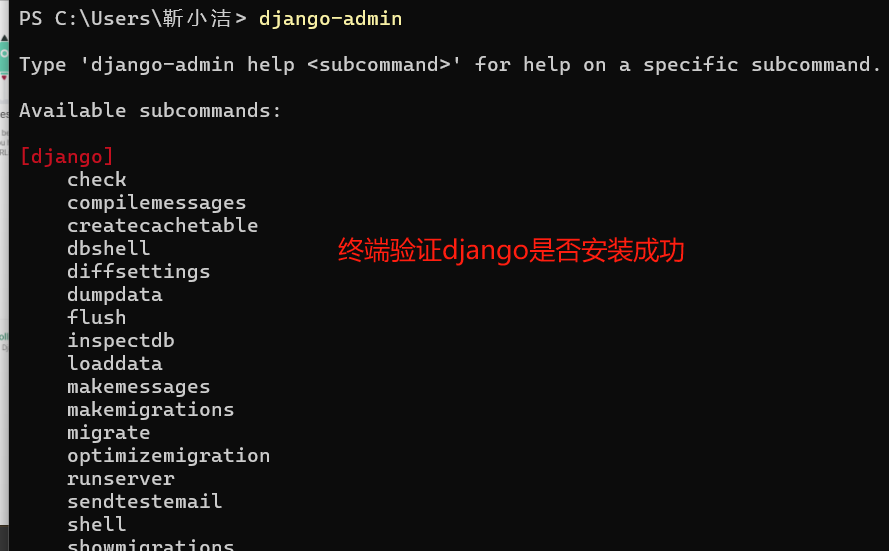
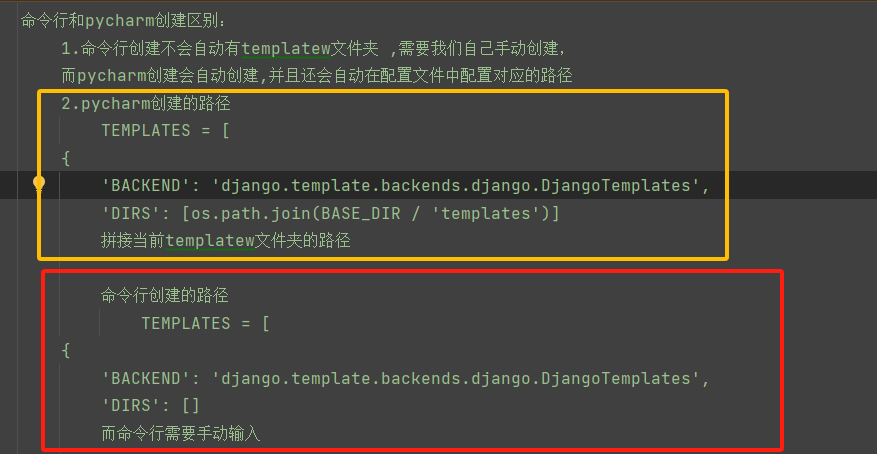
1 django版本安装 2 pip3 install django==3.2.18 3 如果已经安装了其他版本,无序卸载,直接重新安装,会自动卸载安装新的 4 验证是否安装成功的方式1:终端输入django-admin 5 6 常见命令: 7 8 1.创建django项目(就是一个ajango文件夹,里面自动包含了一些py文件!!!) 9 django-admin startproject 项目名 10 11 注意如果直接在C盘的目录下输入该命令,django文件夹就创在C盘目录下了 12 如果想要像python文件一样放到python的项目文件里面去,这样操作: 13 cd pythonProject 14 django-admin startproject 项目名 15 比如:django-admin startproject firstdjango 16 17 这样就在了pythonProject目录下,创建了djangoday01项目了!!! 18 19 --------------------------------------- 20 21 2.启动django项目 cmd命令 22 23 cd 项目名 24 python manage.py runserver 25 # 如果项目起不来,可能端口占用了,默认的是8000的端口 26 27 python manage.py runserver ip:port # 指代一个新的端口号 28 29 ---------------------------------------------------- 30 31 启动django项目 出现的报错信息: 32 django-admin startproject firstdjango 33 cd firstdjango 34 python manage.py runserver 35 Starting development server at http://127.0.0.1:8000/ 36 Quit the server with CTRL-BREAK. 37 Error: [WinError 10013] 以一种访问权限不允许的方式做了一个访问套接字的尝试。 38 ------------------ 39 这个时候换个端口就行了 40 python38 manage.py runserver 127.0.0.1:8999 41 42 ----------------------------------------------------- 43 ----------------------------------------------------- 44 45 4.pycharm自动创建django项目 46 会自动创建templates文件夹!!! 47 但是配置文件中可能会报错!!! 48 os.path.join(BASE_DIR,'templates')
----------------------------------------------------------------------
文件目录
1.创建django项目
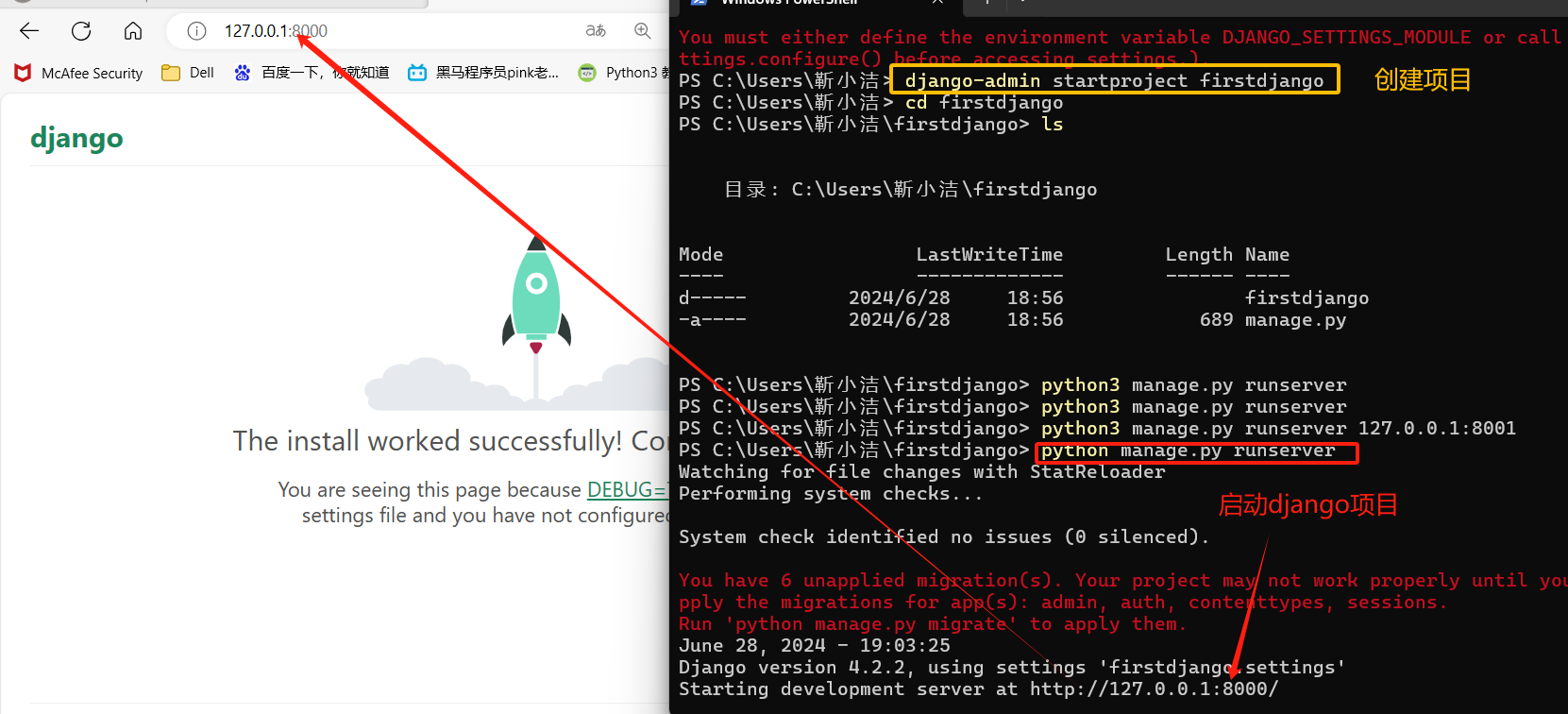
django-admin startproject 项目名称(firstdjango)
firstdjango文件夹
manage.py django的入口文件
mysite文件夹
__init__.py
settings.py 配置文件
urls.py 路由与视图函数对应关系
wsgi.py wsgiref模块
db.sqlite3 自带的sqlite3数据库文件
-------------------------------------------------------------------------
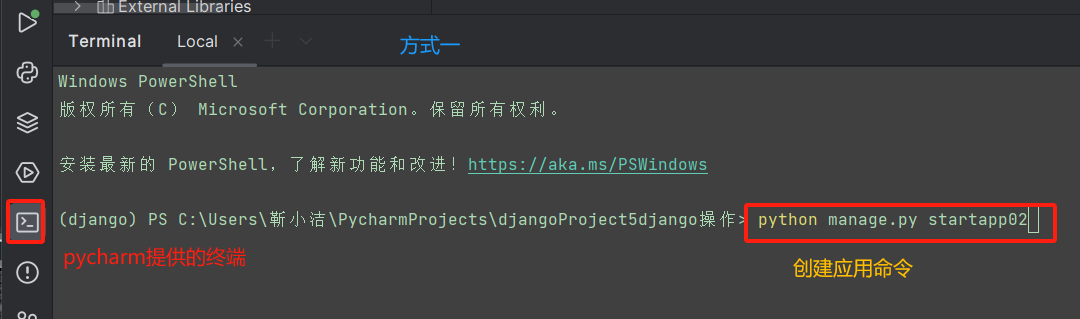
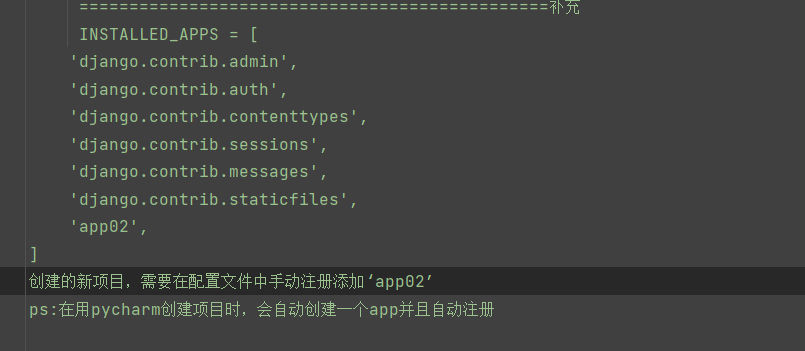
创建应用:python manage.py startapp 应用名称
app01文件夹:
admin.py django自带的后台管理系统
apps.py 注册使用
migrations文件夹 数据库迁移记录
models.py 模型类(orm),数据库相关的
tests.py 测试文件
views.py 视图函数(视图层)
出现下面页面则表示安装成功
(命令操作django)
(pycharm操作django)
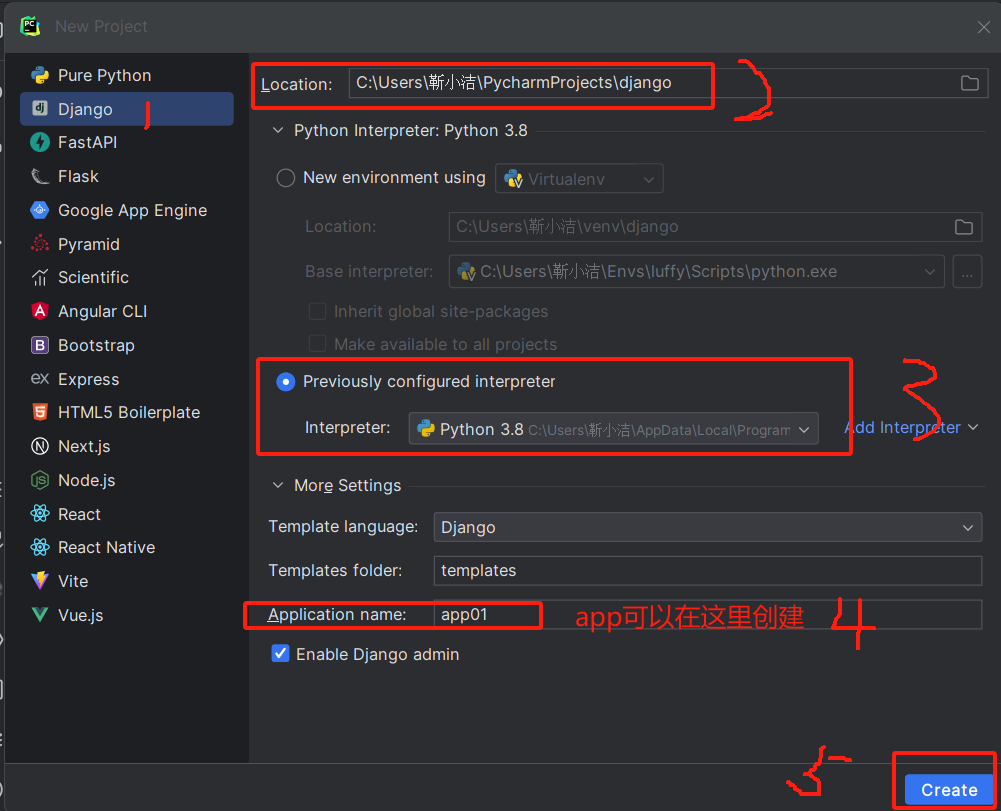
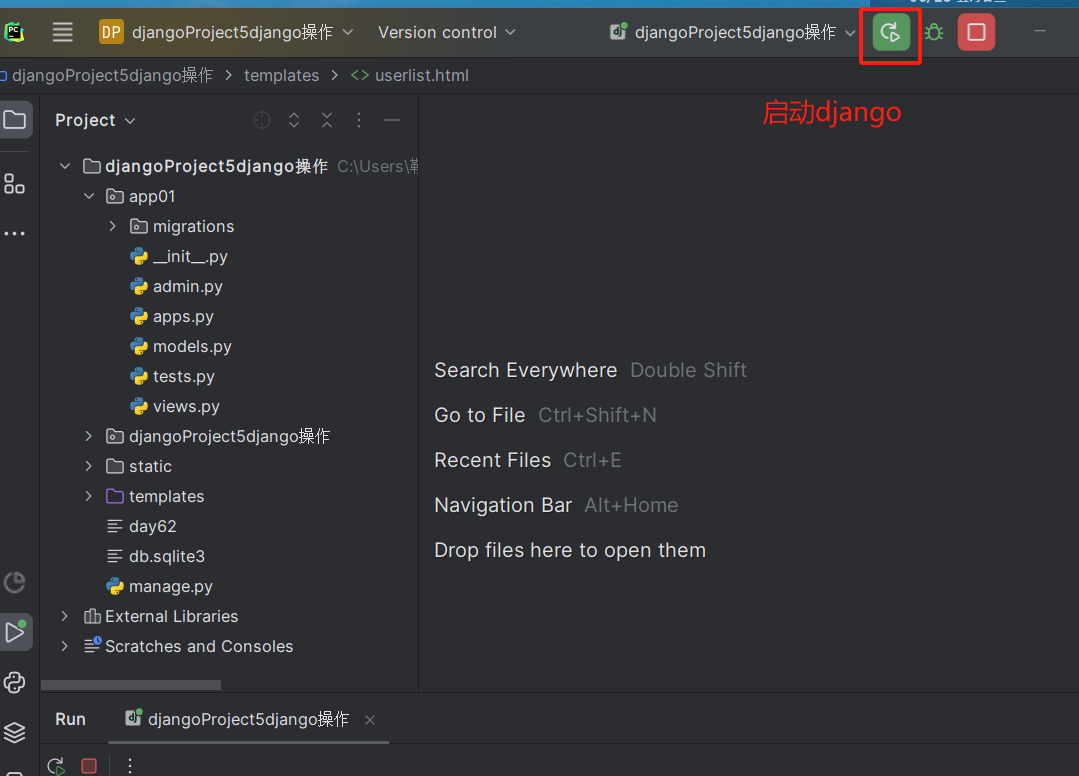
(创建应用)
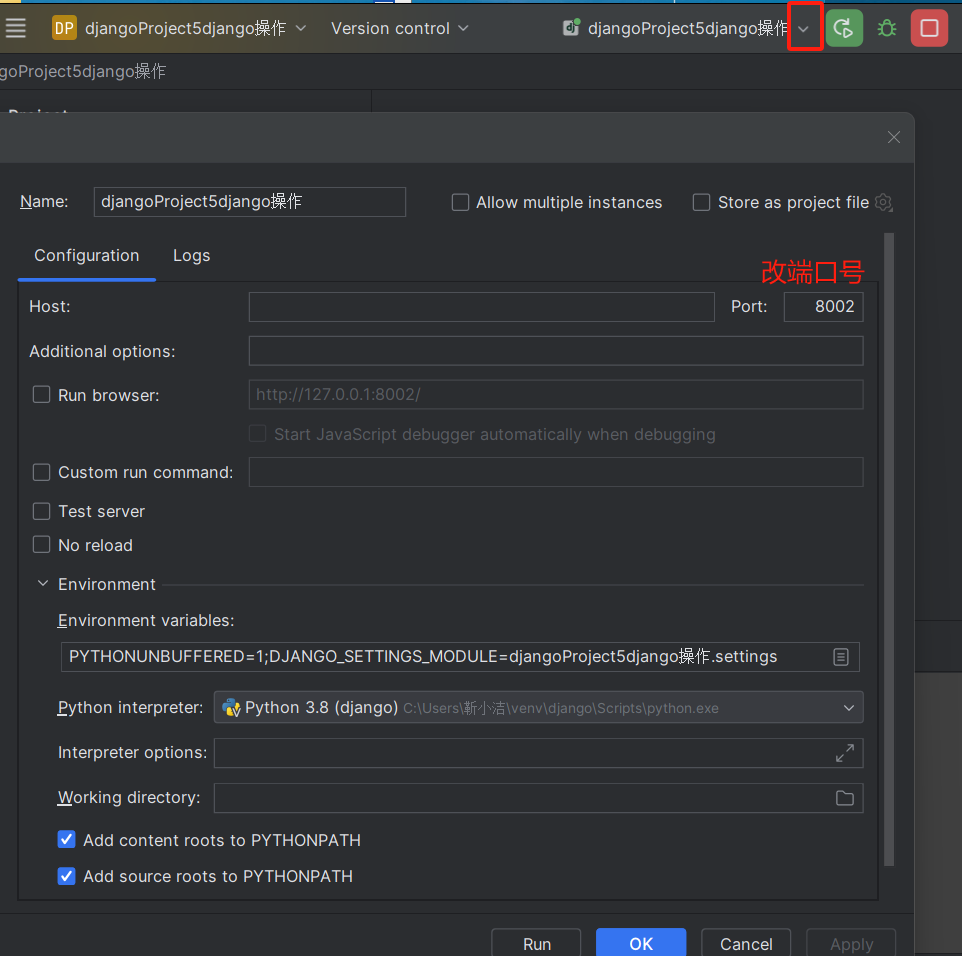
(改端口号)
(命令行和pycharm操作djagngo的区别)
(补充)
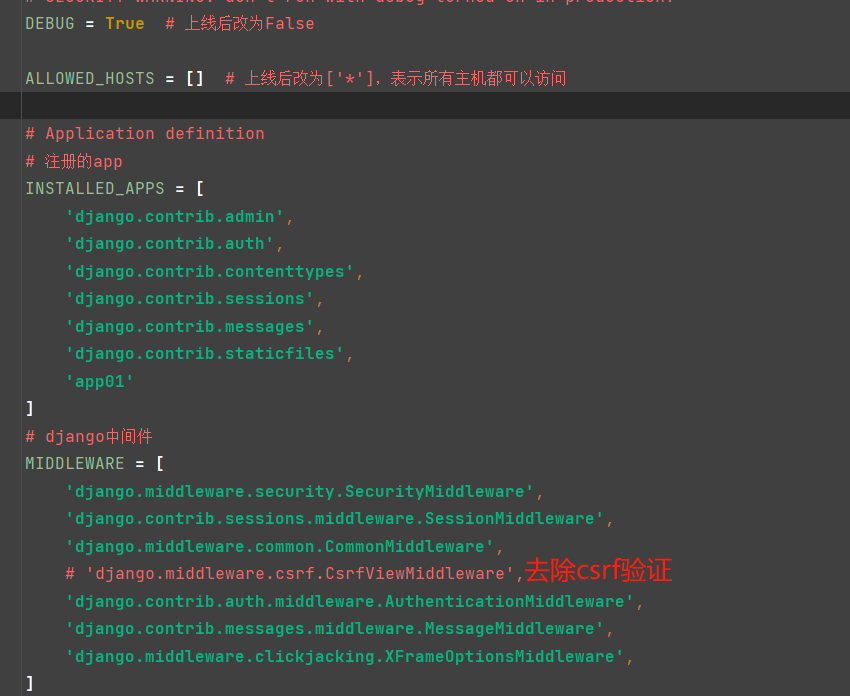
(settings里面的配置文件)
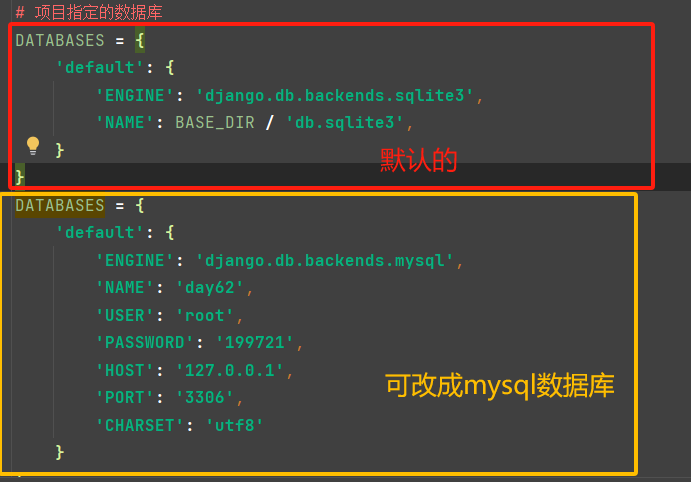
。
。
。
【django小白必会的三板斧】
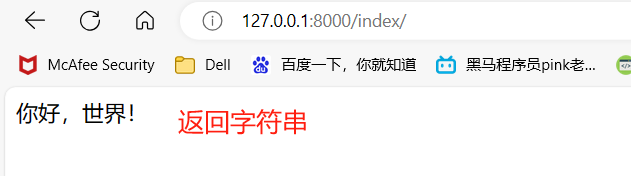
HttpResponse 负责 返回字符串类型的数据
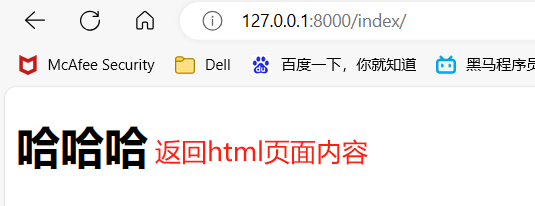
render 负责 返回html页面并且支持传值
redirect 负责 重定向可以到指定的网址,也能到自己的网址!!
1 views.py 2 3 from django.shortcuts import render, HttpResponse, redirect 4 5 6 # Create your views here. 7 def index(request): 8 ''' 9 :param request:请求相关的所有数据对象,比env厉害 10 :return:render返回html页面内容、HttpResponse返回字符串类型的数据、redirect重定向 11 ''' 12 return HttpResponse("你好,世界!") 13 14 return render(request, "django frist.html") 15 16 return redirect("https://www.baidu.com") 17 18 # 跳转到自己写的网址 19 return redirect("/home/") 20 21 22 ------------------------------------------------------------------------- 23 urls.py 24 25 urlpatterns = [ 26 path('admin/', admin.site.urls), 27 # 写我们自己的路由与视图函数对应关系 28 path('index/', views.index), 29 path('home/', views.home), 30 ]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号