



【属性的查找与绑定】
类有两种属性:数据属性和函数属性
1. 类的数据属性是所有对象共享的
2. 类的函数属性是绑定给对象用的
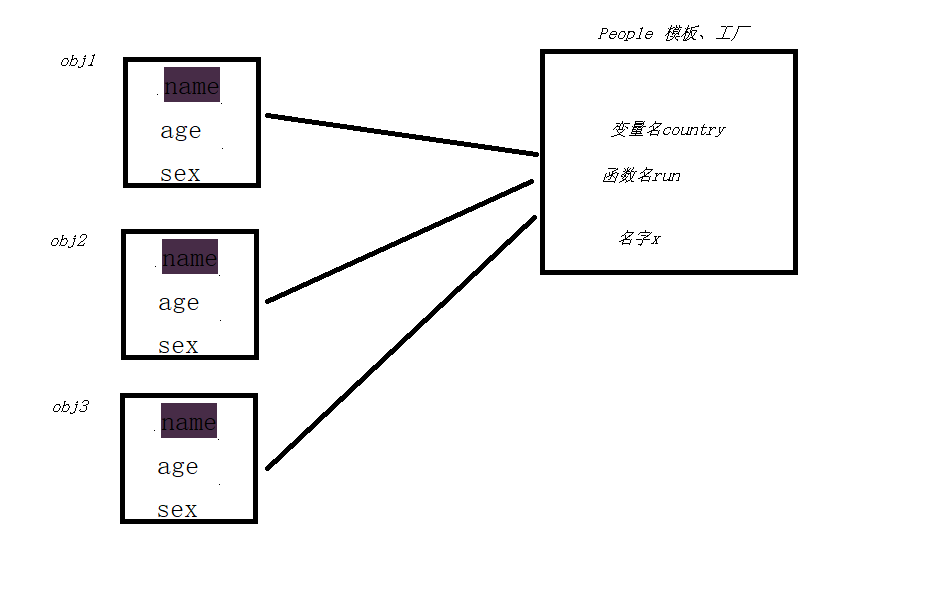
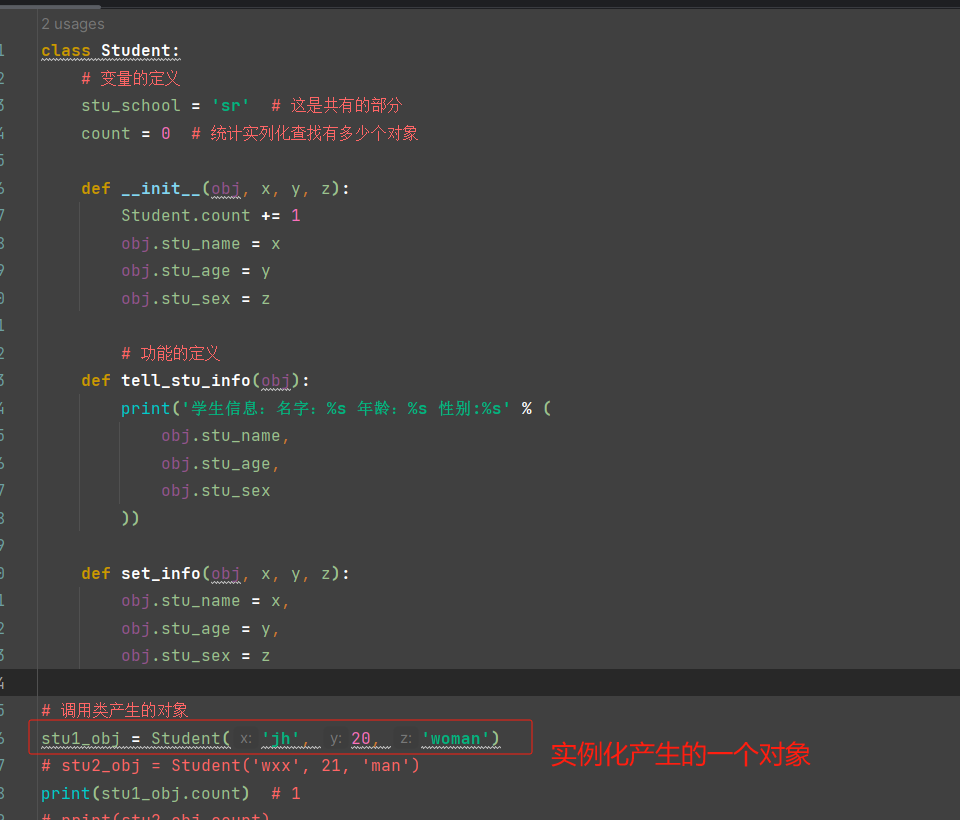
类可以访问到:有数据属性和函数属性
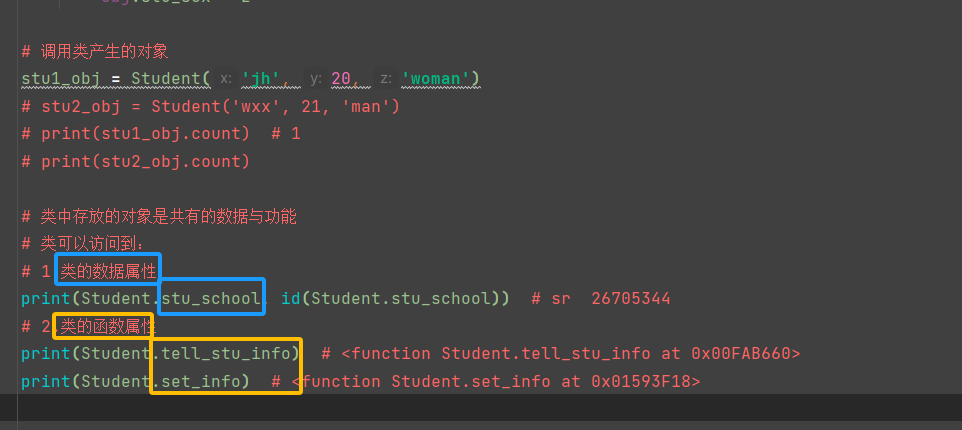
二.但其实类中的东西是给对象用的
1.类的数据属性是共享给索引对象用的,大家访问的地址都一样,如果类的值改了,对象也跟着改
2.类的函数属性是绑定给对象用的类调用自己的函数属性必须严格按照函数的用法来,有几个参数需要传几个参数
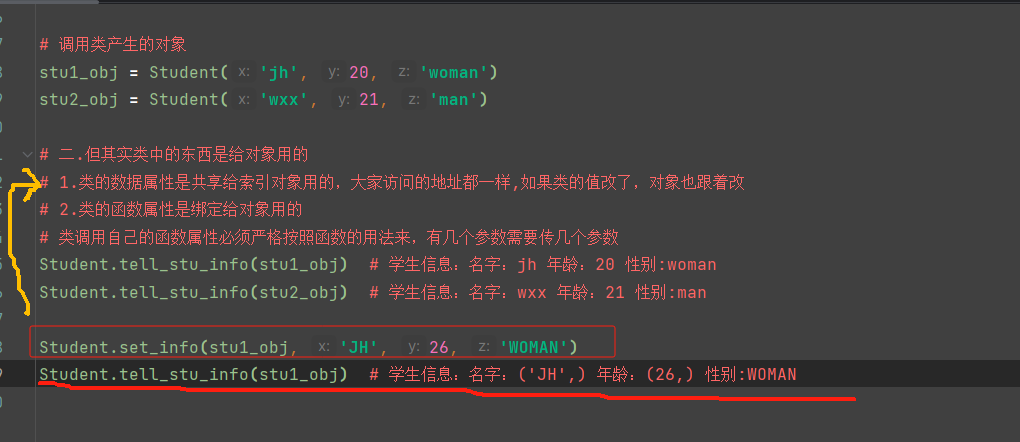
三、绑定方法的特殊指出在于:谁来调用绑定方法就会将谁当作第一个参数自动传入
对比:

总结: 查找顺序:在obj.name会先从obj自己的名称空间里找name,找不到则去类中找,类也找不到就找父类...最后都找不到就抛出异常
【面向对象的三大特征】
【封装】
定义:
1. 封装(Encapsulation)(最核心)
所谓封装(也就是整合),就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,
对不可信的类或者对象隐藏信息。
示范:
1 # =======将封装的属性进行隐藏操作(变形操作) 2 # 在属性名前面加__就会对外隐藏属性 3 class Foo: 4 x = 1 5 __y = 2 6 7 def f1(self): # _Foo__f1 8 print('from test') 9 10 11 print(Foo.x) 12 print(Foo.f1) 13 14 # 报错:AttributeError: type object 'Foo' has no attribute '__y',这就是隐藏属性 15 print(Foo.y) 16 print(Foo.__y)
====================================================================
那怎么显示隐藏属性呢?
print(Foo.__dict__)
print(Foo._Foo__y) # 显示隐藏属性
但是不推荐这样取查找
隐藏属性的特点:

在不改变原本功能的基础上,如何让使用者使用到功能:
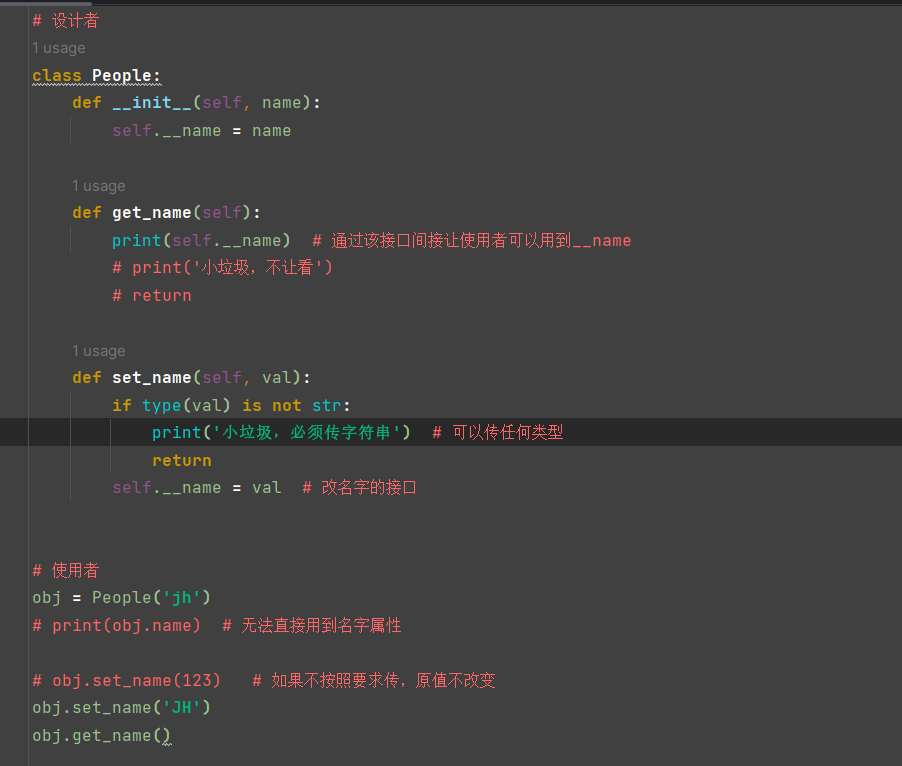
。
。
。
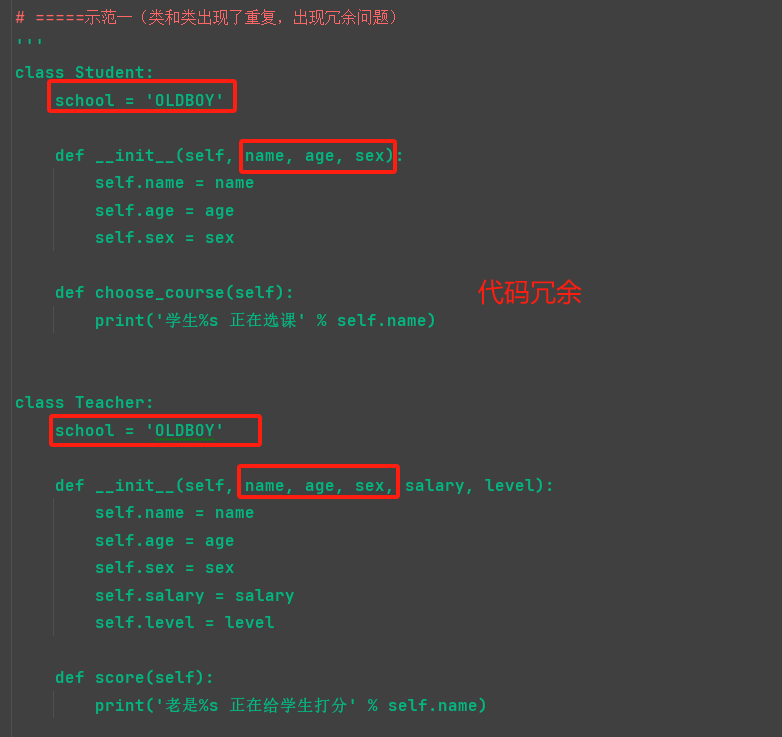
2.【继承】
# 什么是继承? 1.继承是一种创建新类的方式,新建的类可以继承一个或多个父类(python支持多继承),父类又可称为基类或超类,新建的类称为派生类或子类。 PS1:在python2当中有经典类与新式类之分: 新式类:继承object类的子类,以及该子类的子子类 经典类:没有继承object类的子类,以及该子类的子子类 PS2:在python3当中没有继承任何类,那么会默认继承object(内在的类)类,所以python3中所以的类都是新式类 print(Parent1.__bases__) # (<class 'object'>,) print(Parent2.__bases__) # (<class 'object'>,) 2.子类会“”遗传”父类的属性,从而解决代码重用问题(比如练习7中Garen与Riven类有很多冗余的代码) 为何要用继承:用来解决类与类之间代码冗余问题 python的多继承: 优点:子类可以同时遗传多个父类的属性,最大限度地重复用代码 缺点:1.违背人的思维习惯:继承表达的是一直什么“是”什么的关系 2.代码可读性会变差 3.扩展性变差(不建议使用多继承),有可能会引发菱形问题 如果涉及到一个子类不可避免的要重用多个父类的属性,应该使用Mixins 派生重名的,以自己的为准
格式:
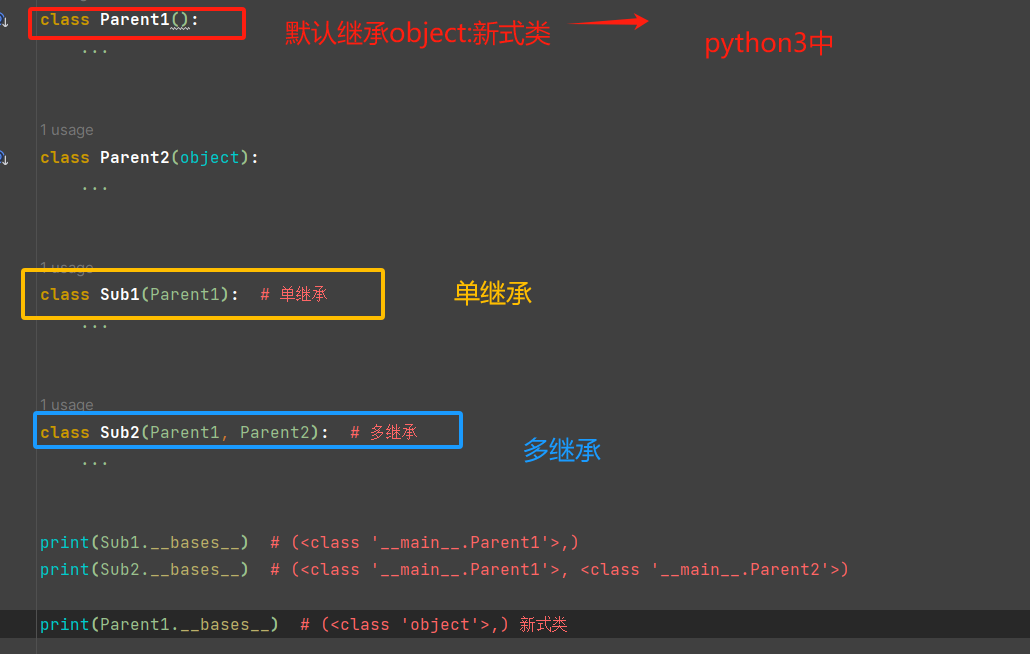
继承的实现
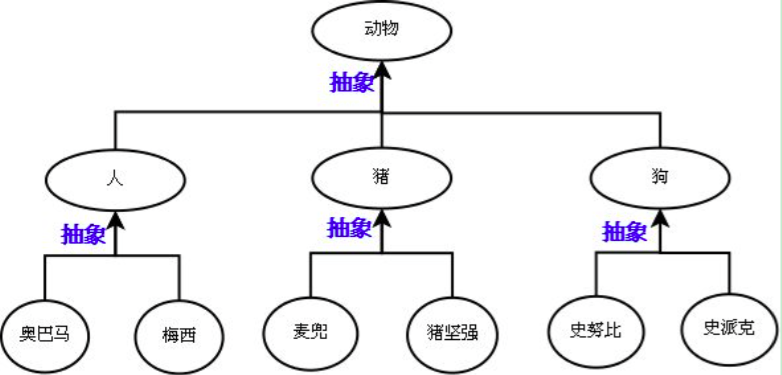
继承:是基于抽象的结果,通过编程语言去实现它,肯定是先经历抽象这个过程,才能通过继承的方式去表达出抽象的结构。
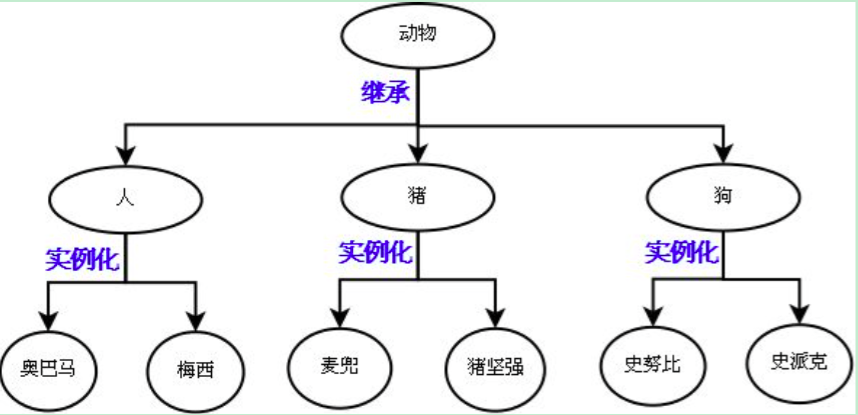
示范:
解决上述问题:
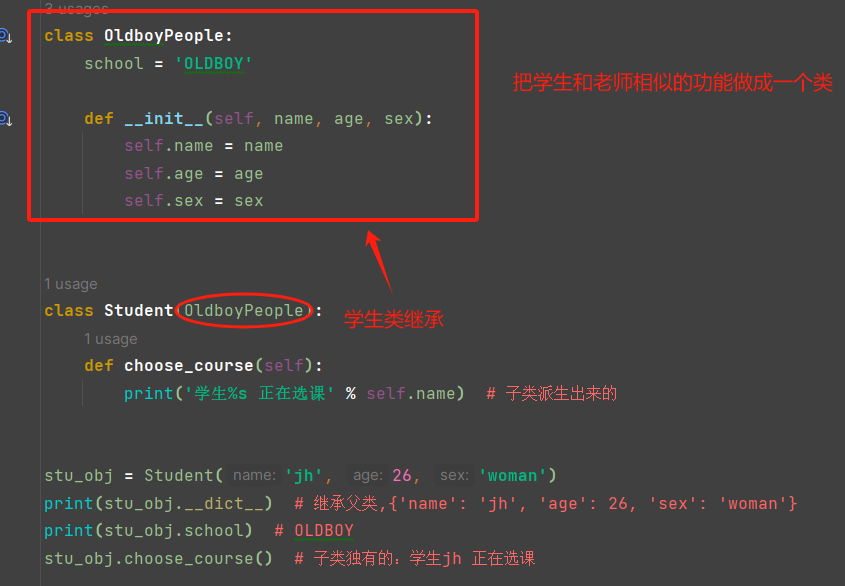
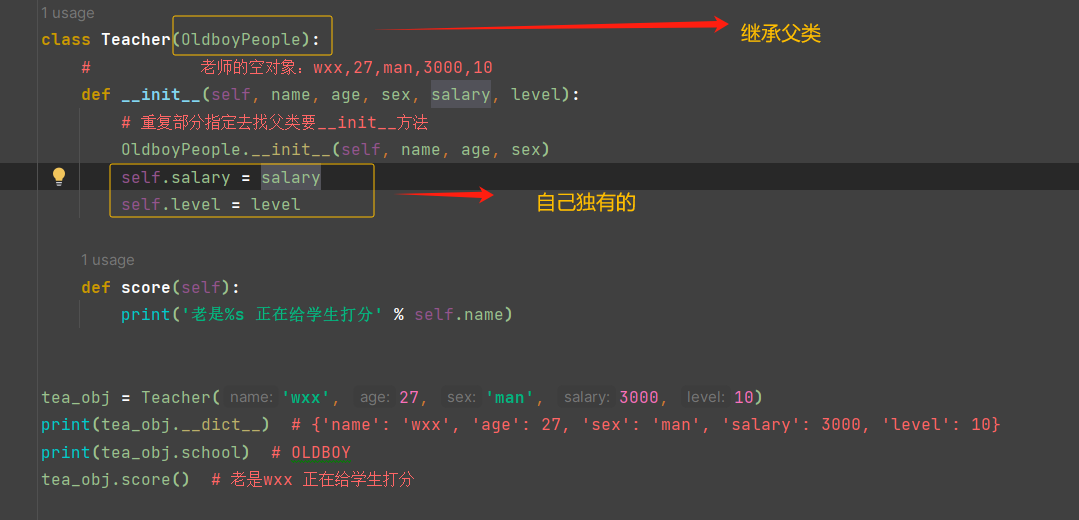
ps:
super()调用父类提供给自己的方法=》严格依赖继承关系
调用super()会得到一个特殊的对象,该对象会参照发起属性查找当前类的mro,去当前类的父类中找属性
super().__init__(name,age,sex)
单继承下的属性查找:
1.首先查找类本身(即当前类)中的属性或方法。
2.如果在类本身中没有找到属性或方法,那么Python会查找该类所继承的父类(也称为基类或超类)中的属性或方法。
3.如果在父类中没有找到属性或方法,Python会继续查找该父类的父类中的属性或方法,以此类推,直到找到为止。

【继承引发的菱形问题】
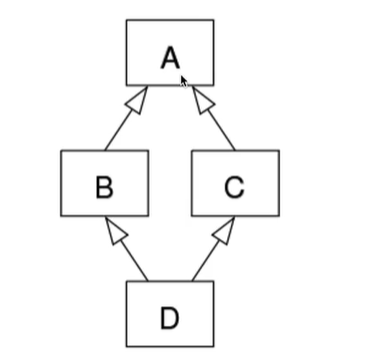
解释什么是菱形问题及属性查找顺序:
1 class A(object): 2 def test(self): 3 print('from A') 4 5 6 class B(A): 7 def test(self): 8 print('from B') 9 10 11 class C(A): 12 def test(self): 13 print('from C') 14 15 16 class D(B, C): 17 ... 18 19 20 obj = D() 21 obj.test() # from B
python到底是如何实现继承的呢?对于我们定义的每一个类,python都会计算出一个方法解析顺序(MRO)列表,该MRO列表就是一个简单的所有基类的线性顺序列表
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
====为了实现继承
为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。
而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
1.子类会先于父类被检查
2.多个父类会根据它们在列表中的顺序被检查
3.如果对下一个类存在两个合法的选择,选择第一个父类
【关于mro在python2和3中的不同之处及相同之处】
1.在非菱形继承的背景下,属性查找顺序是一样的:都是一个一个的分支找下去,最后找到object
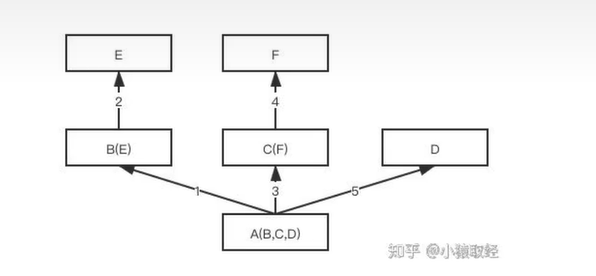
1 class E: 2 def test(self): 3 print('from E') 4 5 6 class F: 7 def test(self): 8 print('from F') 9 10 11 class B(E): 12 def test(self): 13 print('from B') 14 15 16 class C(F): 17 def test(self): 18 print('from C') 19 20 21 class D: 22 def test(self): 23 print('from D') 24 25 26 class A(B, C, D): 27 def test(self): 28 print('from C')
print(A.mro())
# [<class '__main__.A'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.F'>, <class '__main__.D'>, <class 'object'>]
---------------------------------------------------------------------------------------------------------------------------------------
2.菱形继承的背景下,在经典类和新式类中属性查找顺序是不一样的:
经典类:深度优先,会在检索第一条分支的时候就直接一条道走到黑,即会检索到大脑袋(共同的父类)
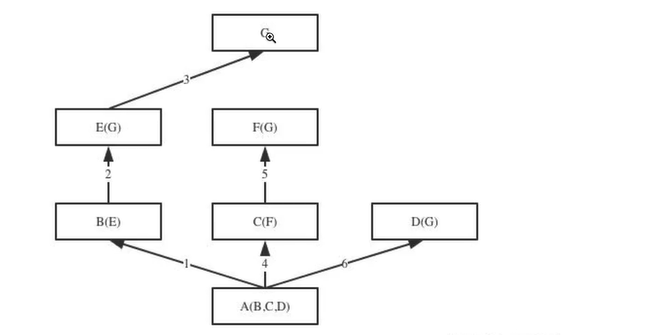
class G(): def test(self): print('from G') class E(G): ... # def test(self): # print('from E') class F(G): def test(self): print('from F') class B(E): ... # def test(self): # print('from B') class C(F): def test(self): print('from C') class D(G): def test(self): print('from D') class A(B, C, D): ... # def test(self): # print('from A') print(A.mro()) obj = A() obj.test() # from C
新式类:广度优先,会在检索第一条分支的时候检索到大脑袋
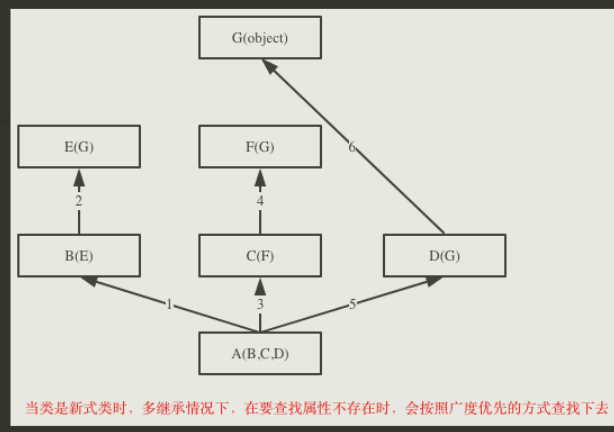
class G(object):
def test(self):
print('from G')
class E(G):
...
# def test(self):
# print('from E')
class F(G):
def test(self):
print('from F')
class B(E):
...
# def test(self):
# print('from B')
class C(F):
...
# def test(self):
# print('from C')
class D(G):
def test(self):
print('from D')
class A(B, C, D):
...
# def test(self):
# print('from A')
print(A.mro())
obj = A()
obj.test() # from F
# =================================总结
# ====多继承到底要不要用?
要用,但要规避几点问题:
1.继承结构不要过于复杂
2.推荐使用mixins机制:要在多继承的背景下满足继承的什么”是“什么的关系
【mixins机制】
# 多继承的正确打开方式:mixins机制 # mixins机制核心:1.就是在多继承背景下尽可能的提升多继承的可读性 # PS:让多继承满足人的思维习惯=》什么”是“什么 # (python当中常量的命名一般用字母大写来规范) class Vehicle: # 交通工具类 ... class FlyableMixin: # 放民航飞机和直升机共同的属性:飞 def fly(self): ... class CivilAircraft(FlyableMixin, Vehicle): # 民航飞机 ... class Helicopter(FlyableMixin, Vehicle): # 直升飞机 ... class Car(Vehicle): # 汽车并不会飞 ...
3.【多态】
3.1多态指的是一类事物有多种形态
3.2为何要有多态=>> 多态会带来什么样的特性
多态性指的是可以在不考虑对象具体类型的情况下,而直接使用对象
class Animal: # 统一所有子类的方法 def say(self): print('动物基本的发声频率', end=' ') class People(Animal): def say(self): super().say() print('啊啊啊啊啊啊啊') class Dog(Animal): def say(self): super().say() print('汪汪汪汪汪') class Pig(Animal): def say(self): super().say() print('哼哼哼') obj1 = People() obj2 = Dog() obj3 = Pig() # ====定义统一的接口,接收传入的动物对象 def animal_say(animal): animal.say() animal_say(obj1) animal_say(obj2) animal_say(obj3)

