

【面向对象的编程思想:】
1.面向过程:核心是过程二字,过程指的是解决问题的步骤,即先干什么再干什么......
面向过程的设计就好比精心设计好一条流水线,是一种机械式的思维方式。
2.面向对象:核心是对象二字
对象的终极奥义就是将程序“整合”
对象是‘’容器‘’,用来盛放数据与功能的
2.1. 封装(Encapsulation)
所谓封装,就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的类或者对象隐藏信息。
class num():
def test(self,参数):
pass
2.2. 继承(Inheritance)
继承是指这样一种能力:它可以使用现有类的所有功能,并在无须重新编写原来的类的情况下对这些功能进行扩展。
2.3. 多态(Polymorphism)
所谓多态,就是指一个类实例的相同方法在不同情形下有不同的表现形式。多态机制使具有不同内部结构的对象可以共享相同的外部接口。
3.面向过程的优缺点:
优点:复杂度的问题流程化,进而简单化(一个复杂的问题,分成一个个小的步骤去实现,实现小的步骤将会非常简单)
缺点:可扩展性差,一套流水线或者流程就是用来解决一个问题,生产汽水的流水线无法生产汽车,即便是能,也得是大改,改一个组件,牵一发而动全身
4.面向对象的优缺点:
优点:1.解决了程序的扩展性 2.对某一个对象单独修改,会立刻反映到整个体系中,如对游戏中一个人物参数的特征和技能修改都很容易
缺点:1.)(设计复杂)编程的复杂度远高于面向过程,不了解面向对象而立即上手基于它设计程序,极容易出现过度设计的问题
比如管理linux系统的shell脚本就不适合用面向对象去设计,面向过程反而更加适合。
2)无法向面向过程的程序设计流水线式的可以很精准的预测问题的处理流程与结果,
面向对象的程序一旦开始就由对象之间的交互解决问题,即便是上帝也无法准确地预测最终结果。
5.面向对象编程:类、对象
1.先找出对象
2.然后总结归纳出类
3.先定义类
4.后调用类产生的对象(调用类的过程又称之为实例化)
=======类(也是容器)类起名字时候用驼峰体
类即类别、种类,是面向对象设计最重要的概念,对象是特征与技能的结合体,
而类则是一系列对象相似的特征与技能的结合体
类中最常见的是:变量与函数的定义,但是类体其实是可以包含其他任意代码的
=============类体代码是在类定义阶段就会立即执行,会产生类的名称空间
我们开始用面向对象改写

属性的访问
1 # 先定义类 2 class Student: 3 # 变量的定义 4 stu_school = 'sr' 5 6 # 功能的定义 7 def tell_stu_info(stu_obj): 8 print('学生信息:名字 %s 年龄 %s 性别 %s' % ( 9 stu_obj['stu_name'], 10 stu_obj['stu_age'], 11 stu_obj['stu_gender'] 12 )) 13 14 def set_info(stu_obj, x, y, z): 15 stu_obj['stu_name'] = x, 16 stu_obj['stu_age'] = y, 17 stu_obj['stu_gender'] = z 18 19 20 # 再调用类 21 print(Student.__dict__) # 查看类中所有的属性和方法 22 print(Student.__dict__['stu_school']) # 查看类中的变量 23 24 print('=====上述调用类太复杂======') 25 26 # 直接调用类中的方法:属性访问的语法 27 print(Student.set_info) # <function Student.set_info at 0x0086B660> 28 29 # 属性访问的语法: 30 1.访问数据属性 31 2.访问函数属性
产生对象的几种方式
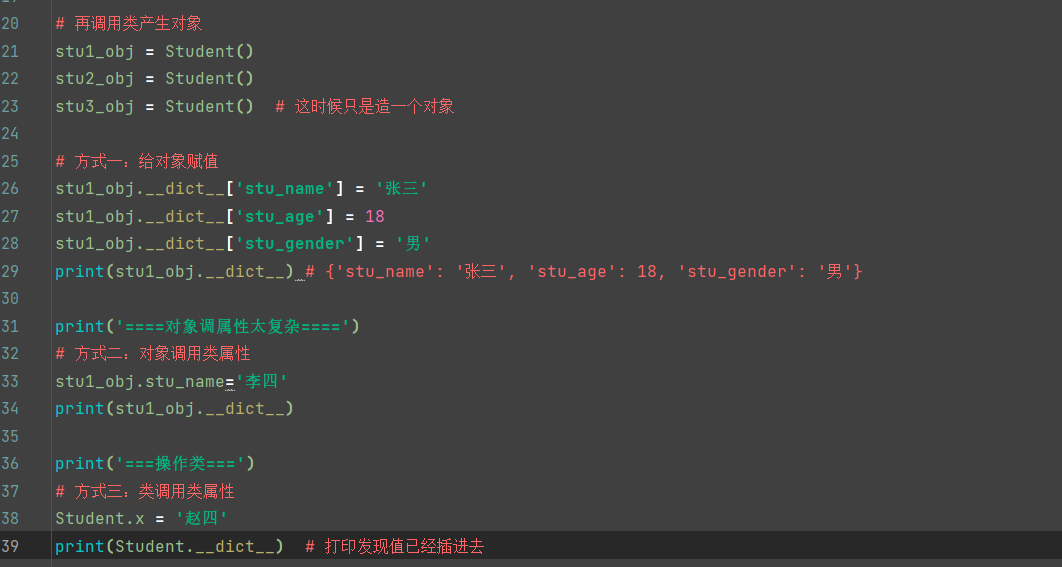
。
。
--------------------------------------------------------------------------------
但发现上面代码冗余,还要属性查找顺序比较复杂
解决办法一:
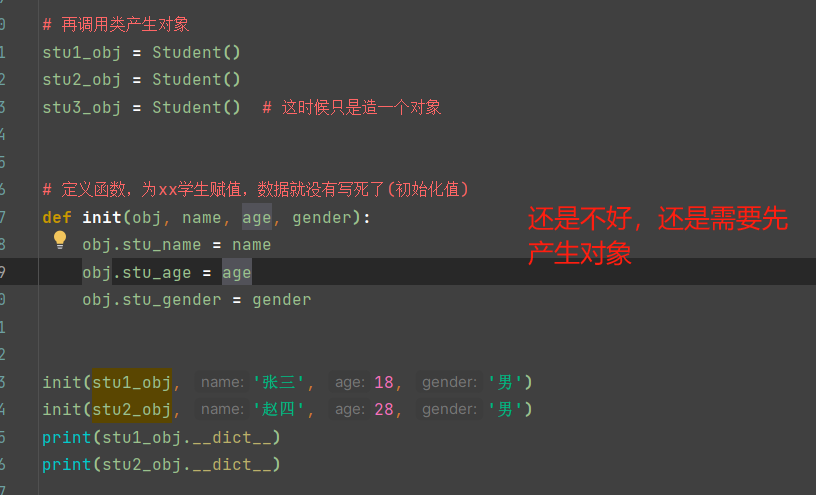
解决方案二及会遇到的问题
定义到类内部
1 # 先定义类 2 class Student: 3 # 变量的定义 4 stu_school = 'sr' 5 ===============================================================
定义到类内部 6 # 方法的定义,只有在类调用的阶段才会触发 7 # 如果我们传4个值,这时候会报错 8 # TypeError: __init__() missing3 required positional arguments: 'x', 'y', and 'z' 9 # 这时候告诉我们要传3个值,但是__init__(obj, x, y, z)里有4个参数,原因是因为解释器自动给我们传了obj:stu1这个值 10 def __init__(obj, name, age, gender): 11 obj.stu_name = name 12 obj.stu_age = age 13 obj.stu_gender = gender 14 ============================================================================================ 15 # 功能的定义 16 def tell_stu_info(stu_obj): 17 print('学生信息:名字 %s 年龄 %s 性别 %s' % ( 18 stu_obj['stu_name'], 19 stu_obj['stu_age'], 20 stu_obj['stu_gender'] 21 )) 22 23 def set_info(stu_obj, x, y, z): 24 stu_obj['stu_name'] = x, 25 stu_obj['stu_age'] = y, 26 stu_obj['stu_gender'] = z 27 28 29 # 调用类产生对象,调用类的过程又称之为实例化 30 stu1_obj = Student('王五', 18, '男') # 为name,age,gender传值 31 stu2_obj = Student('刘亦菲', 17, '女') 32 print(stu1_obj.__dict__) 33 print(stu2_obj.__dict__)
总结:
一:调用类产生对象
调用类的过程又称为实例化,发生三件事:
1.先产生一个空对象
2.python会自动调用类中的__init__方法,然后将空对象已经调用类时()内传入的参数一同传给__init__方法
3.返回初始完的对象
二:总结__Init__方法
1.会在调用类时自动触发执行,用来为对象初始化字节独有的数据
2.__Init__内应该存放是为对象初始化属性的功能,但是是可以存放任意其他代码,想要在类调用时就立刻执行的代码都可以放到该方法内
3.__Init__方法必须返回None
