

【import time】

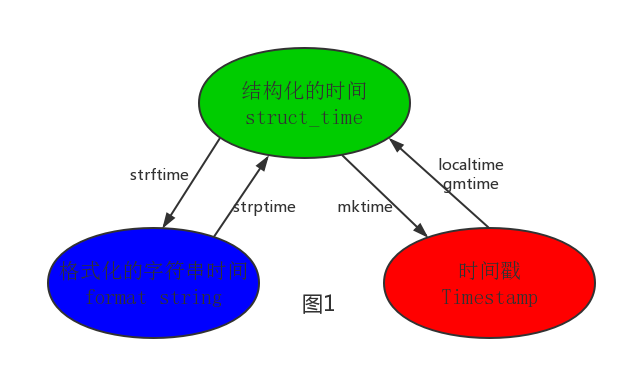
1 1.时间戳:从1970年到现在经过的秒数 2 import time 3 print(time.time()) 4 作用:用于时间间隔的计算 5 6 2.按照某种格式显示时间 7 212023--02 19:13:27 显示的是你打印时候的时间 8 print(time.strftime('%Y-%m-%d %H:%M:%S')) # 2023-12-02 19:13:27 9 print(time.strftime('%Y-%m-%d %X')) #212023--02 19:13:27 10 作用:用来展示时间 11 12 3.结构化的时间 13 import time 14 res=time.localtime() 15 print(res) # time.struct_time(tm_year=2023, tm_mon=12, tm_mday=2, tm_hour=19, tm_min=17, tm_sec=13, tm_wday=5, tm_yday=336, tm_isdst=0) 16 # 如果想取某一个月 17 print(res.tm_mon) # 12 18 作用:可以用于获取时间的某一个部分 19 20 =============================== 21 ============================时间模块的转换 22 ===使用:结构话时间可以和时间戳进行互相转换,也可以和格式化时间互相转换, 23 但是时间戳和格式化时间不可以进行相互转换,需要通过结构化时间转换 24 1.结构化时间转换为时间戳格式 25 import time 26 s_time=time.localtime() 27 print(time.mktime(s_time)) # 1701517495.0 28 2.时间戳转为结构化时间格式 29 ==localtime中国时间 30 import time 31 t_time=time.time() 32 print(time.localtime()) # 中国时间 33 # ()传的是秒进去,也就是时间戳time.struct_time(tm_year=2023, tm_mon=12, tm_mday=2, tm_hour=19, tm_min=50, tm_sec=27, tm_wday=5, tm_yday=336, tm_isdst=0) 34 print(time.localtime(time.time())) # 或是这种写法 35 ====gmtime世界标准时间 36 import time 37 t_time=time.time() 38 print(time.gmtime(t_time)) #time.struct_time(tm_year=2023, tm_mon=12, tm_mday=2, tm_hour=11, tm_min=55, tm_sec=15, tm_wday=5, tm_yday=336, tm_isdst=0) 39 和中国时间差了8个小时 40 41 3.结构化时间转换为格式化时间 42 import time 43 s_time=time.localtime() 44 print(time.strftime('%Y-%m-%d %X',s_time)) # 2023-12-02 20:02:11 45 4.格式化时间转换为结构化时间 46 import time 47 g_time=time.localtime() 48 print(time.strptime('2023-12-02 20:05:11','%Y-%m-%d %X')) 49 #time.struct_time(tm_year=2023, tm_mon=12, tm_mday=2, tm_hour=20, tm_min=5, tm_sec=11, tm_wday=5, tm_yday=336, tm_isdst=-1) 50 51 ==========格式化时间转换为时间戳 52 ==案例:充7周的会员 53 import time 54 t_time=time.strptime('2023-12-02 20:32:11','%Y-%m-%d %X') # 格式化时间转为结构化时间 55 s_time=time.mktime(t_time)+7*86400 # 然后结构化时间转换为时间戳 56 print(s_time) # 1702125131.0 57 58 =======时间戳转换为格式化时间 59 import time 60 s_time=time.strftime('%Y-%m-%d %X',time.localtime()) 61 print(s_time) #2023-12-02 20:45:15 62 63 ===了解知识点 64 # import time 65 # print(time.asctime()) # 相当于格式话时间 strftime Sun Dec 17 13:42:26 2023
【import datetime】
1 ========================datetime(一部到位获取到时间),还可以获取到几天或是几周之后的时间 2 import datetime 3 # print(datetime.datetime.now()) # 2023-12-02 19:26:04.049013 4 # print(datetime.datetime.now()+datetime.timedelta(days=2)) #2023-12-04 19:30:45.944956,获取到2天之后的时间,(week=?) 5 print(datetime.datetime.now()-datetime.timedelta(days=3)) # 2023-11-29 19:34:48.697906,获取3天之前的时间 6 =====时间戳可以转换为格式化时间 7 # 将时间戳转换为格式化时间 8 import datetime 9 print(datetime.datetime.fromtimestamp(22222)) #1970-01-01 14:10:22
======================
补充
print(datetime.datetime.now()) # 2024-05-03 18:47:26.227360
print(datetime.datetime.utcnow()) # 世界标准时间 2024-05-03 10:47:26.227360
【 random】
1 import random 2 3 print(random.randint(1, 16)) # 随机取,返回的是随机的整数类型,顾头顾尾 4 print(random.random()) # 取的是大于0小于1之间的随机小数 0.4392174936453791 5 print(random.randrange(1, 4)) # 也是取整数,只能取到1-3中的随机一个,顾头不顾尾 6 print(random.choice([1, 'aa', 'bb'])) # 选取列表当中的指定的任意随机数 7 print(random.sample([22, 33, 'ccc'], 2)) # 指定列表里的元素随机抽取2个值,K代表随机选取的数量 8 print(random.uniform(1, 3)) # 取指定范围之间的小数
l = [11, 33, 2, 8, 10]
random.shuffle(l) # 随机洗牌
print(l)
案例(获取随机字符串)
1 import random 2 3 res = "" 4 for i in range(6): # 随机返回6个数 5 English = chr(random.randint(65, 90)) # chr是十进制转换,十进制中大写字母A-Z是(60-90),小写字母是(97-122) 6 english = chr(random.randint(97, 122)) 7 num = str(random.randint(0, 9)) 8 s = random.choice([English, num, english]) # 随机字符=【字母,数字】 9 res += s 10 print(res) # 3G5Dv7 11 12 13 # ===============================================上述做成一个函数 14 def make_choice(size): 15 res = "" 16 for i in range(size): 17 English = chr(random.randint(65, 90)) # chr是十进制转换,十进制中大写字母A-Z是(60-90),小写字母是(97-122) 18 english = chr(random.randint(97, 122)) 19 num = str(random.randint(0, 9)) 20 s = random.choice([English, english, num]) 21 res += s 22 return res 23 24 25 print(make_choice(6)) # zQTvUY
【OS模块】
1 import os 2 3 print(os.getcwd()) # 获取当前工作目录,也就是当前脚本的目录路径 4 os.chdir('/path/to/your/directory') # 改变当前脚本工作目录路径 5 print(os.curdir) # 获取当前目录:(’.‘) 6 print(os.pardir) # 获取当前目录的父目录字符串名:(‘..’) 7 print(os.makedirs('dirname1/dirname2')) # 创建多级文件夹(makedirs),如子文件夹,子子文件夹 8 print(os.removedirs('dirname1/dirname2')) # 若目录为空,则删除,并递归到上一级目录 9 print(os.mkdir('name1')) # 创建单级文件夹(mkdir) 10 print(os.rmdir('name1')) # 删除单级文件夹 11 print(os.listdir()) # 列出当前文件夹下的所有文件及文件夹 12 os.remove('文件名') # 删除一个文件 13 os.rename() # 重命名文件夹/文件 14 print(os.stat('时间_os模块.py')) # 获取文件的状态信息 15 print(os.sep) # 输出操作系统特定的路径分隔符,win下为‘\’,linux下为‘/’ 16 print(os.linesep) # 输出当前平台使用的行终止符,win下为'\n',linux下为'\n'# os.pathsep # 输出用于分割文件路径的字符串 17 print(os.name) # 输出字符串指示当前使用平台。win->'nt'; linux->'posix'# os.system() # 运行shell命令,直接显示 18 print(os.environ) # 获取系统的环境变量 19 print(os.path.abspath('时间_os模块.py')) # 获取文件的绝对路径 20 print(os.path.dirname('run.py')) # 获取当前文件所在文件夹路径 21 print(os.path.basename('时间_os模块.py')) # 获取当前文件名 22 print(os.path.split('时间_os模块.py')) # 获取当前文件所在文件夹路径和文件名 23 print(os.path.exists('时间_os模块.py')) # 判断文件是否存在,返回布尔值 24 print(os.path.isabs('时间_os模块.py')) # 判断是否是绝对路径,返回布尔值 25 print(os.path.isfile('时间_os模块.py')) # 判断是否是文件,返回布尔值 26 print(os.path.isdir('时间_os模块.py')) # 判断是否是文件夹,返回布尔值 27 os.path.join() # 拼接文件路径 28 print(os.path.getatime('run.py')) # 获取文件或目录的最后访问时间 29 print(os.path.getmtime('时间_os模块.py')) # 获取文件或目录的最后修改时间 30 print(os.path.getsize('时间_os模块.py')) # 获取文件的大小,以字节为单位
----------------------------------------------------------------------------------------------------------------
# print('----------os.path.join()用法----------')
path_1 = r'C:\Users\靳小洁\PycharmProjects\pythonProject\Day22' # 父级
path_2 = r'奥里给.json' # 父级下的子级(父级文件下的文件夹)
# 目标r'C:\Users\靳小洁\PycharmProjects\pythonProject\Day22\奥里给.json'
total_path = os.path.join(path_1, path_2)
print('拼接成完整路径:{}'.format(total_path))
==============================================================================
print('----------os.listdir()用法,列出当前文件夹下的所有文件及文件夹----------')
file_name_list = os.listdir(path_1)
print(file_name_list)
# print('----------完整路径拼接----------')
# 1.遍历文件名列表中的元素
# 2.使用os.path.join()用法把初始路径和文件拼接到一起
for i in file_name_list:
res = os.path.join(path_1, i)
print(res)
================================================================================
from pathlib import Path
res=Path('/a/b/c')/'d/e.txt'
print(res) # 拼接 \a\b\c\d\e.txt
【sys模块】
sys模块主要与python解释器打交道
1 import sys 2 3 print(sys.path) # 获取python解释器默认路径 4 print(sys.getrecursionlimit()) # 获取python解释器默认最大递归深度:1000 5 sys.setrecursionlimit(2000) # 修改python解释器默认最大递归深度 6 print(sys.version) # 解释器版本信息 7 # 3.6.8 (tags/v3.6.8:3c6b436a57, Dec 23 2018, 23:31:17) [MSC v.1916 32 bit (Intel)] 8 9 print(sys.platform) # 平台信息 win32(了解即可)
==============================================================
print(sys.argv) # 命令行参数List,第一个元素是文件名
sys.exit(0) # 退出程序,正常退出时exit(0)
print(sys.stdout.write('123')) # 输出到屏幕
【读取文件的两种方式】
1 ======原本文件读取方式 2 src_file=input('原文件路径').strip() 3 dst_file=input('目标文件路径').strip() 4 with open(r'%s' %src_file,mode='rb') as f_read,\ 5 open(r'%s'%dst_file,mode='wb') as f_write: 6 for lin in f_read: 7 f_write.write(line) 8 =======现在读取文件方式 9 import sys 10 src_file=sys.argv[1] #src_file=input('原文件路径').strip() 11 dst_file=sys.argv[2] #等同于dst_file=input('目标文件路径').strip(),使用者自己传的
【案例:打印进度条】
1 # =======【%-50s %'#' 】是固定模式,左对齐,长度为50,可改 2 # =====进度条静态图 3 print('[%-40s]' % '#') 4 print('[%-40s]' % '##') 5 print('[%-40s]' % '###') 6 7 8 =========================================进度条动态图 9 import time 10 11 12 def progress(): 13 res = '' 14 for i in range(20): 15 res += '#' 16 time.sleep(0.2) 17 print('\r[%-40s]' % res, end='') # 不换行(\r),每次都是从头开始打印(动态图) 18 19 20 progress() 21 22 =========================================无函数写法 23 import time 24 25 recv_size = 0 # 收的大小 26 total_size = 33333 27 while recv_size < total_size: 28 time.sleep(0.05) 29 # 下载了1024字节的数据 30 recv_size += 1024 31 # 打印进度条,可以打印的长度 32 percent = recv_size / total_size 33 res = int(40 * percent) * '#' 34 print('\r[%-50s] %d%%' % (res, int(100 * percent)), end='') 35 36 ====================================有函数写法进阶版 37 38 import time 39 40 41 def progress(percent): 42 if percent > 1: 43 percent = 1 44 res = int(40 * percent) * '#' 45 print('\r[%-50s] %d%%' % (res, int(100 * percent)), end='') 46 47 48 recv_size = 0 49 total_size = 33333 50 while recv_size < total_size: 51 time.sleep(0.05) 52 recv_size += 1024 53 percent = recv_size / total_size 54 progress(percent) 55 # [######################################## ] 100%
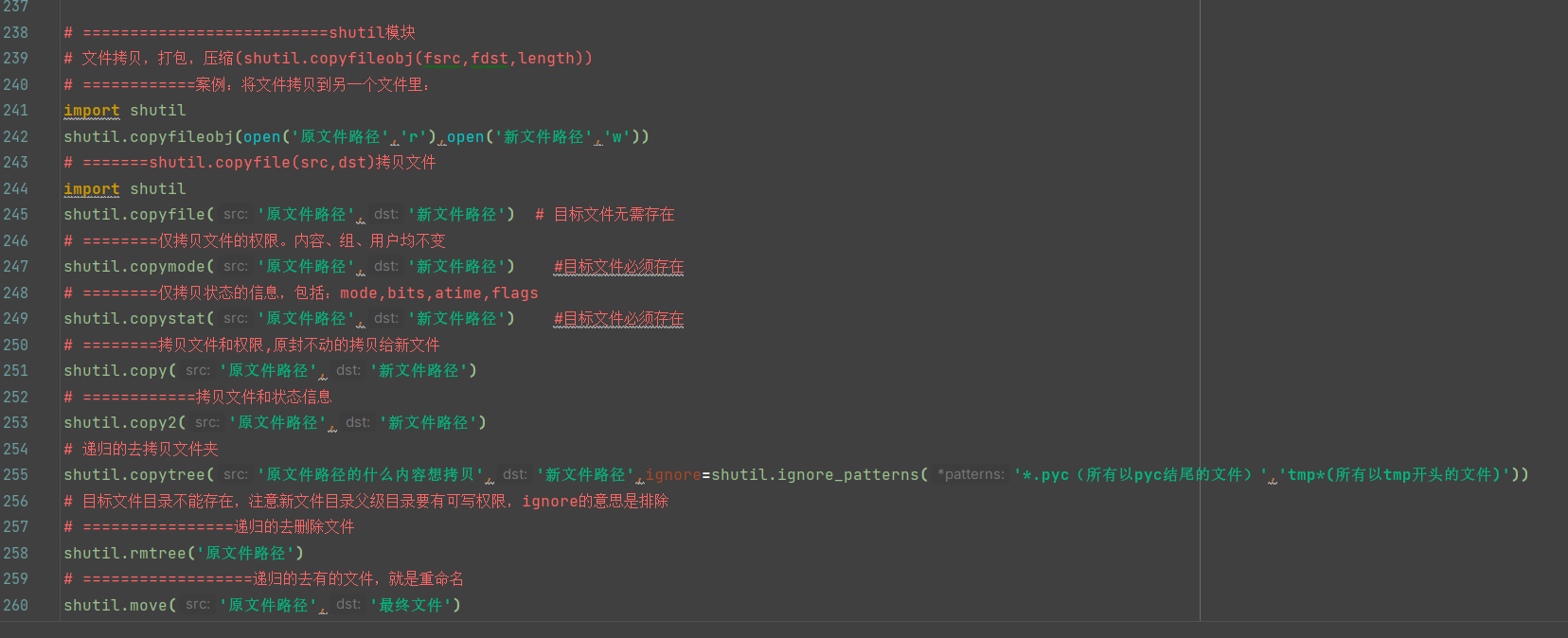
【shuilt模块】
【json序列化与反序列化】
序列化:是指把内存的数据类型转换成一个特定的格式(json格式或是 pickle格式)内容,该格式的内容可以用于存储或者传输给其他平台使用
反序列化:把序列化的结果再返还回原来的数据类型
内存中的数据类型------->序列化------------->特定格式
内存中的数据类型-------<序列化-------------<特定格式
=====土如办法
{'aaa':111}----->序列化str({'aaa':111})----->"{'aaa':111}"
{'aaa':111}<-----反序列化eval("{'aaa':111}")<-----"{'aaa':111}"
序列化得到结果---特定的格式内容有两种用途:1,用于存档,2。传输给其他平台使用
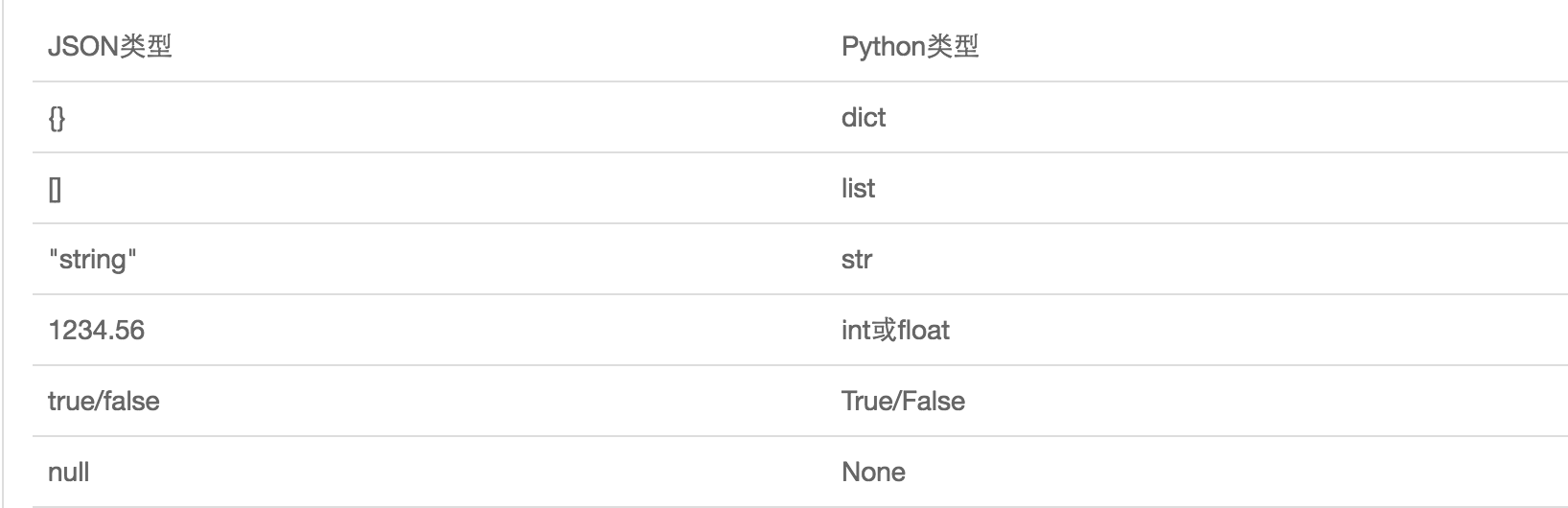
python java
列表 特定格式 数组
强调:针对用途1的特定格式:可是一致专用的格式=》pickle只有python可以识别
针对用途2的特定格式:应该是一种通用,能够被所有语言识别的格式=》json


双引号是json格式字符串的标志!!!!!!
1 ===================json的序列化 2 import json 3 4 res = json.dumps(True) 5 print(res, type(res)) # true <class 'str'> 6 7 res = json.dumps([1, 'aaa', True, False]) # 列表类型 8 print(res, type(res)) # [1, "aaa", true, false] <class 'str'> 9 10 11 # ================================反序列化 12 import json 13 14 res = json.dumps([1, 'aaa', True, False]) # 列表类型序列化 15 print(type(res)) # <class 'str'> 16 l = json.loads(res) # 反序列化 17 print(l, type(l)) # [1, 'aaa', True, False] <class 'list'>
案例:
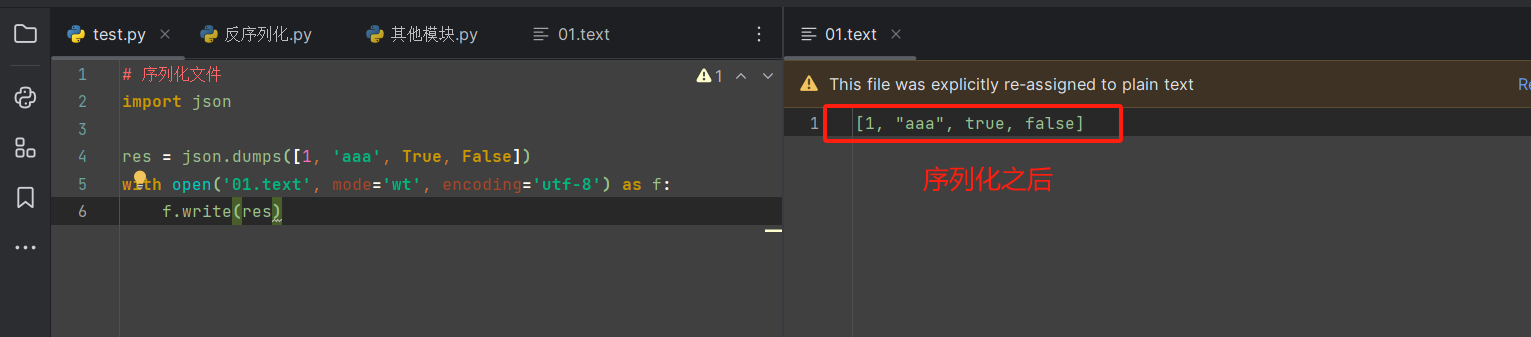
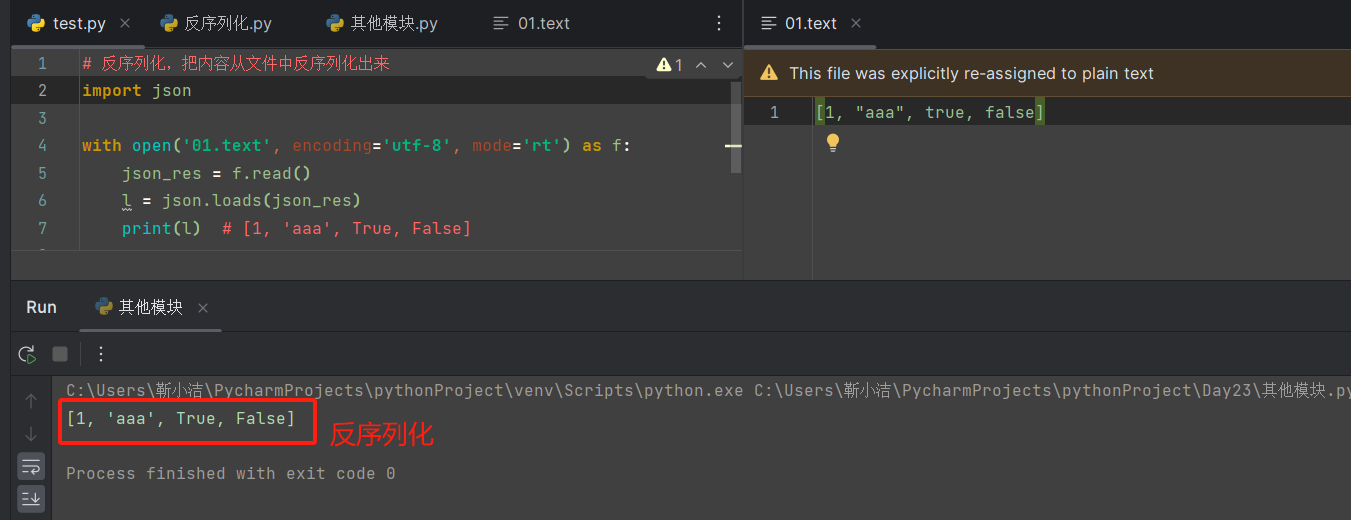
1 # ============上述案例简单写法 2 # =====(序列化写入文件:json.dump) 3 import json 4 5 with open('01.text', mode='wt', encoding='utf-8') as f: 6 json.dump([1, 'aaa', True, False], f) # 传两个参数,前面是序列化的内容,第二个参数是打开的文件对象,[1, "aaa", true, false] 7 # =====反序列化json.load 8 with open('01.text', mode='rt', encoding='utf-8') as f: 9 l = json.load(f) 10 print(l)
json总结
dump 倾倒;倾卸 ;,转存(计算机数据)
load载入
json 模块就4个方法
dumps loads
-----------------------
dump load
-----------------------
dump相当于是dumps()和write()方法的结合!!!!
load相当于是loads()和read()方法的结合!!!!
----------------------
json模块的主要功能是将序列化数据从文件里读取出来或者存入文件。
其中dump()是将数据存入文件中,load()是用于读取文件。
----------------------
而dumps()和loads()是对python对象进行操作。
dumps()是将python对象编码成json字符串。
loads()是将json字符串解码成python对象。
---------------------
json.dumps()和json.dump()的区别
json.dumps() 是把python对象转换成json对象的一个过程,生成的是字符串。
json.dump() 是把python对象转换成json对象生成一个fp的文件流,和文件相关。
=====================================================================================
【pickle模块】
1 import pickle 2 3 # ===序列化 4 res = pickle.dumps({1, 2, 3, 4, 5}) 5 print(res,type(res)) # <class 'bytes'> 6 # ====反序列化 7 s = pickle.loads(res) 8 print(s, type(s)) # <class 'set'> 9 10 --------------------------------------------文件 11 f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes' 12 12 f.write(j) #-------------------等价于pickle.dump(dic,f) 13 13 14 14 f.close() 15 15 #-------------------------反序列化 16 16 import pickle 17 17 f=open('序列化对象_pickle','rb') 18 18 19 19 data=pickle.loads(f.read())# 等价于data=pickle.load(f) 20 20 21 21 22 22 print(data['age'])
序列化文件类型
dump、load
1 import pickle 2 3 # 打开一个文件用于写入,这里我们使用二进制模式 'wb' 4 with open('反序列化.pkl', 'wb') as f: 5 # 使用 pickle.dump() 方法将数据序列化并写入文件 6 pickle.dump('你好啊', f,protocol=pickle.HIGHEST_PROTOCOL) 7 8 with open('反序列化.pkl', 'rb') as f : 9 # 使用pickle.load()方法从文件中反序列化出对象 10 data = pickle.load(f) 11 print(data)
【xml模块】
1 ======格式 2 <?xml version="1.0" encoding="UTF-8"?> 3 <root> 4 <person id="1"> 5 <name>John Doe</name> 6 <age>30</age> 7 <email>john@example.com</email> 8 </person> 9 <person id="2"> 10 <name>Jane Smith</name> 11 <age>25</age> 12 <email>jane@example.com</email> 13 </person> 14 </root> 15 在这个示例中,XML文档的根元素是<root>。它包含两个子元素<person>,每个<person>元素都有三个子元素:<name>、<age>和<email>。 16 每个<person>元素还有一个id属性,用于标识不同的人员。 17 XML文档具有以下特点: 18 可扩展性:XML的标签是自定义的,可以根据需要进行扩展和定义。 19 结构性:XML文档具有树形结构,由根元素和子元素组成。 20 可读性:XML文档使用标签来描述数据,易于人类阅读和理解。 21 可验证性:XML文档可以使用DTD(Document Type Definition)或XMLSchema进行验证,以确保文档的结构和内容符合规范。 22 跨平台性:XML是一种通用的数据格式,可以在不同的平台和系统之间进行交换和共享。 23 =======案例 24 import xml.etree.ElementTree as ET 25 26 # 创建一个XML文档 27 root = ET.Element("root") 28 doc = ET.SubElement(root, "doc") 29 30 # 添加属性 31 doc.set("name", "example") 32 33 # 添加子元素 34 item = ET.SubElement(doc, "item") 35 item.set("name", "item1") 36 item.text = "This is item 1" 37 38 # 保存XML文档到文件 39 tree = ET.ElementTree(root) 40 tree.write("example.xml") 41 在这个示例中,我们首先创建了一个根元素,然后创建了一个子元素,并给它添加了一个属性和一个文本内容。 42 最后,我们将整个XML文档保存到文件中。
【shelve模块】
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve # 打开一个 shelve 数据库(如果文件不存在,它将被创建) with shelve.open('mydata') as db: # 写入数据 db['name'] = 'Alice' db['age'] = 30 db['info'] = {'city': 'New York', 'country': 'USA'} # 注意:当我们退出 with 块时,数据会自动被保存到磁盘上 ====================================== import shelve # 打开 shelve 数据库 with shelve.open('mydata') as db: # 读取数据 print(db['name']) # 输出: Alice print(db['age']) # 输出: 30 print(db['info']) # 输出: {'city': 'New York', 'country': 'USA'} # 同样,当我们退出 with 块时,不需要手动保存数据 ======================================= import shelve # 打开 shelve 数据库 with shelve.open('mydata') as db: # 修改数据 db['age'] = 31 # 删除数据 del db['info'] # 现在,数据库中的 'age' 被更新为 31,'info' 被删除
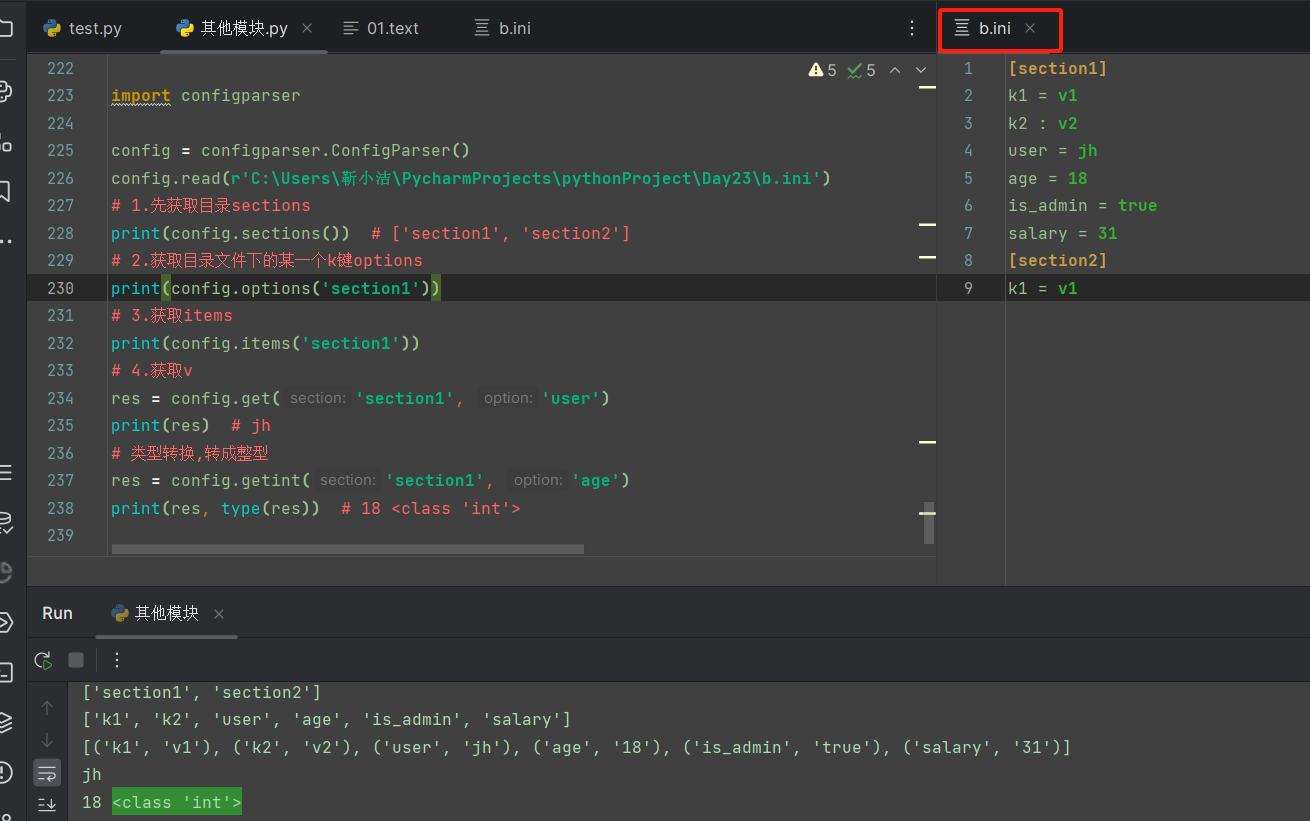
【configparser模块】
configparser 是 Python 的一个内置模块,用于读取和写入配置文件。这些配置文件通常被称为 "INI" 文件,因为它们使用了一种类似于 Windows INI 文件的格式。
configparser 模块的主要用途是提供一种方便的方式来处理配置文件,这些文件可能包含多个部分(或称为“节”),每个部分包含多个键值对。
# 目录
# [section1] 这是一伙的
# 配置象
# k1 = v1 注释:#或是;
# k2: v2
# user = jh
# age = 18
# is_admin = true
# salary = 31
# [section2] 这是另一伙的
【hash模块】
hash一类算法,该算法接受传入的内容,经过运算得到一串hash值
hash值特点:
1.只要传入的内容一样,得到的hash值必然一样=======》要用铭文传输密码文件的完整性校验
2.不能由hash值返解成内容========》把密码做成hash值,不应该在网络传输明文密码
3.只要使用的hash算法不变,无论校验的内容有多大,得到的hash值产犊是固定的
=========用途
12345abc====>md5====》hash字符串
1.特点2用于密码密文传输与验证
2.特点1、3用于文件完整性的校验
1 import hashlib 2 3 m = hashlib.md5() 4 m.update('hello'.encode('utf-8')) 5 m.update('world'.encode('utf-8')) # 原材料 6 res = m.hexdigest() # 转成hash值 7 print(res) # fc5e038d38a57032085441e7fe7010b0 8 9 # # 校验 10 m1 = hashlib.md5() 11 m1.update('hello'.encode('utf-8')) 12 m1.update('wor'.encode('utf-8')) 13 m1.update('ld'.encode('utf-8')) 14 res = m1.hexdigest() 15 print(res) # fc5e038d38a57032085441e7fe7010b0
hashlib.XXX() 选择XXX加密算法
.update() 传入明文数据
.hexdigest() 获取加密密文
==========================================
密码加盐
import hashlib
m = hashlib.md5()
m.update('天王'.encode('utf-8'))
m.update('jj123456'.encode('utf-8')) # 密码
m.update('盖地虎'.encode('utf-8'))
res = m.hexdigest() # 转成hash值
print(res)
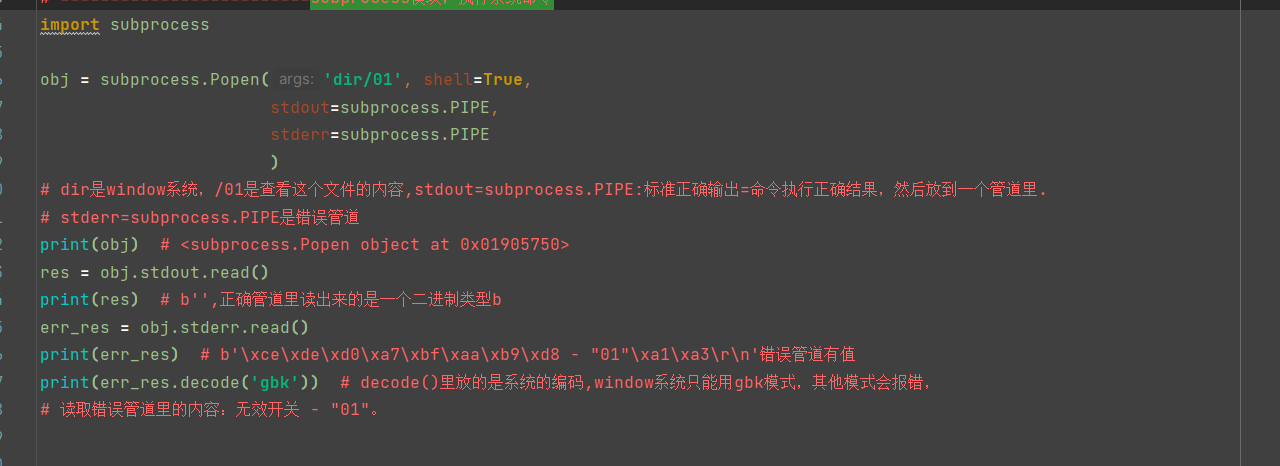
【subprocess模块,执行系统命令】
【Loging日志模块】
1.输出日志及级别
logging.debug('调试日志') # level=10
logging.info('消息') # level=20
logging.warning('警告') # level=30
logging.error('错误') # level=40
logging.critical('严重错误') # level=50 # 从上而下,越来越严重
设置日志级别为:logging.setLevel("DEBUG")
2.日志的一些格式
logging.basicConfig(
level=logging.DEBUG, # 设置日志级别
# 日志返回格式
format='%(asctime)s-%(levelname)s-%(module)s:%(message)s',
# 时间格式
datefmt='%Y-%m-%d %H:%M:%S %p',
# 日志的输出位置:1.终端 2.文件
filename='001.log', # 把日志放到文件中(之前默认打印到终端上)
# 既往终端输出,也输出到文件中
handlers=[logging.StreamHandler(), logging.FileHandler('001.log')]
)
3.日志配置setting
%(name)s:Logger的名字,并非用户名,详细查看
%(levelno)s:数字形式的日志级别
%(levelname)s:文本形式的日志级别
%(pathname)s:调用日志输出函数的模块的完整路径名,可能没有
%(filename)s:调用日志输出函数的模块的文件名
%(module)s:调用日志输出函数的模块名
%(funcName)s:调用日志输出函数的函数名
%(lineno)d:调用日志输出函数的语句所在的代码行
%(created)f:当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d:输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s:字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d:线程ID。可能没有
%(threadName)s:线程名。可能没有
%(process)d:进程ID。可能没有
%(message)s:用户输出的消息
日志字典的配置settings
1 # =================日志的配置 2 ''' 3 4 %(name)s:Logger的名字,并非用户名,详细查看 5 6 %(levelno)s:数字形式的日志级别 7 8 %(levelname)s:文本形式的日志级别 9 10 %(pathname)s:调用日志输出函数的模块的完整路径名,可能没有 11 12 %(filename)s:调用日志输出函数的模块的文件名 13 14 %(module)s:调用日志输出函数的模块名 15 16 %(funcName)s:调用日志输出函数的函数名 17 18 %(lineno)d:调用日志输出函数的语句所在的代码行 19 20 %(created)f:当前时间,用UNIX标准的表示时间的浮 点数表示 21 22 %(relativeCreated)d:输出日志信息时的,自Logger创建以 来的毫秒数 23 24 %(asctime)s:字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 25 26 %(thread)d:线程ID。可能没有 27 28 %(threadName)s:线程名。可能没有 29 30 %(process)d:进程ID。可能没有 31 32 %(message)s:用户输出的消息 33 34 ''' 35 36 import os 37 38 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \ 39 '[%(levelname)s][%(message)s]' # 其中name为getlogger指定的名字 40 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' 41 test_format = '[%(asctime)s] %(message)s' 42 logfile_dir = os.path.dirname(os.path.abspath(__file__)) # log文件的目录 43 logfile_name = 'all2.log' # log文件名 44 # 如果不存在定义的日志目录就创建一个 45 if not os.path.isdir(logfile_dir): 46 os.mkdir(logfile_dir) 47 # log文件的全路径 48 logfile_path = os.path.join(logfile_dir, logfile_name) 49 50 # 3.日志配置字典 51 LOGGING_DIC = { 52 'version': 1, 53 'disable_existing_loggers': False, 54 # 日志输出格式 55 'formatters': { 56 'standard': { 57 'format': standard_format 58 }, 59 'simple': { 60 'format': simple_format 61 }, 62 'test': { 63 'format': test_format 64 }, 65 }, 66 'filters': {}, 67 # 是日志的接收者,不同的handler会将日志输出到不同的地方 68 'handlers': { 69 # 打印到终端的日志 70 'console': { 71 'level': 'DEBUG', 72 'class': 'logging.StreamHandler', # 打印到屏幕 73 'formatter': 'simple' # 日志格式 74 }, 75 # 打印到文件的日志,收集info及以上的日志 76 # 正常日志? 77 # 'default': { 78 # 'level': 'DEBUG', 79 # 'class': 'logging.FileHandler', 80 # 'formatter': 'standard', 81 # 'encoding': 'utf-8', 82 # 'filename': logfile_path, 83 # }, 84 'other': { 85 'level': 'DEBUG', 86 'class': 'logging.FileHandler', # 保存到文件 87 'filename': 'all2.log', # 文件名 88 'encoding': 'utf-8', 89 'formatter': 'test' # 日志输出格式 90 91 } 92 }, 93 # 产生者,产生的日志会传递给handler然后控制输出 94 'loggers': { 95 'kkk': { 96 'handlers': ['other', 'console'], # 这里把上面定义的两个handler都加在一起 97 'level': 'DEBUG', # loggers(第一层日志级别关限制)----》handlers(第二层日志级别关限制) 98 'propagate': False # 默认为真,向更高level的logger传递,通常设置为假 99 }, 100 'bbb': { 101 'handlers': ['console', ], # 这里把上面定义的两个handler都加在一起 102 'level': 'DEBUG', # loggers(第一层日志级别关限制)----》handlers(第二层日志级别关限制) 103 'propagate': False # 默认为真,向更高level的logger传递,通常设置为假 104 }, 105 } 106 }
日志字典的使用
''' 拿到日志的产生者即loggers: kkk bbb ''' # 但是需要先导入日志配置字典LOGGING_DIC import settings from logging import config, getLogger config.dictConfig(settings.LOGGING_DIC) logger1 = getLogger('kkk') logger1.info('这是一条输入到终端和文件的日志') logger2 = getLogger('bbb') logger2.info('这是只输出到终端的日志') # ===================补充 # 日志名的命名(区别日志业务归属的一种非常重要的标志) # 日志轮转(日志记录着程序员运行过程中的关键信息)
# 创建一个handler,用于写入日志文件,每5MB轮转一次,保留3个备份
handler = RotatingFileHandler('app.log', maxBytes=5*1024*1024, backupCount=3)
==============================================================================================
标准记录日志格式
'default': {
'level': 'DEBUG',
# 'class': 'logging.FileHandler', # 保存到文件
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,日志轮转
'maxBytes': 5, # 日志大小 5M
'backupCount': 3, # 最多备份3个
'formatter': 'standard',
'encoding': 'utf-8',
'filename': 'all.log',
},
【re模块】
1 ''' 2 正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。 3 或者说:正则就是用来描述一类事物的规则。(在Python中)它内嵌在Python中,并通过 re 模块实现。 4 正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行 5 6 ''' 7 8 import re 9 10 # 匹配字母数字及下划线 11 print(re.findall('\w', 'abc123_*()-=')) # ['a', 'b.ini', 'c', '1', '2', '3', '_'] 12 # 匹配非字母数字下划线 13 print(re.findall('\W', 'abc123_*()-=')) # ['*', '(', ')', '-', '='] 14 # 匹配任意空白字符,等价于 [t\n\r\f] 15 print(re.findall('\s', 'aS\rbc\t\n12\f3_*()-=')) # ['\r', '\t', '\n', '\x0c'] 16 # 匹配任意非空字符 17 print(re.findall('\S', 'aS\rbc\t\n12\f3_*()-=')) # ['a', 'S', 'b.ini', 'c', '1', '2', '3', '_', '*', '(', ')', '-', '='] 18 # 匹配任意数字,等价于[0-9] 19 print(re.findall('\d', 'aS\rbc\t\n12\f3_*()-=')) # ['1', '2', '3'] 20 # 匹配任意非数字 21 print(re.findall('\D', 22 'aS\rbc\t\n12\f3_*()-=')) # ['a', 'S', '\r', 'b.ini', 'c', '\t', '\n', '\x0c', '_', '*', '(', ')', '-', '='] 23 # 匹配字符串开始 24 print(re.findall('\Aajh', 'ajhwxlis dcm')) # ['ajh'] ,如果对不上,则返回空 25 # 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串 26 print(re.findall('sb\Z', 'ajhwxlisb' 27 ' dcm sb')) # ['sb'] 28 # 匹配字符串的开头 29 print(re.findall('^h', 'hello wxx 123')) # ['h'] 30 # 匹配字符串的末尾。 31 print(re.findall('3$', 'hello jh 123')) # ['3'] 32 # 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符 33 print(re.findall('a.b.ini', 'a1b')) # ['a1b'] 34 # [] 匹配指定字符一个。 35 print(re.findall('a[1*-]b.ini', 'a1b a*b.ini a-b.ini')) # []内的都为普通字符了,且如果-没有被转意的话,应该放到[]的开头或结尾 36 print(re.findall('a[^1*-]b.ini', 'a1b a*b.ini a-b.ini a=b.ini')) # []内的^代表的意思是取反,所以结果为['a=b.ini'] 37 # 匹配0个或多个的表达式。* 38 print(re.findall('ab*', 'a')) # ['a'] 39 # 匹配1个或多个的表达式+ 40 print(re.findall('ab+', 'abbb')) # ['abbb'] 41 # 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式? 42 print(re.findall('ab?', 'abbb')) # ['ab'] 43 # 匹配n到m次由前面的正则表达式定义的片段,贪婪方式{n,m} 44 print(re.findall('ab{2}', 'abbb')) # ['abb'] 45 46 # .*?为非贪婪匹配:推荐使用 47 print(re.findall('a.*?b.ini', 'a1b22222222b')) # ['a1b'] 48 # .*默认为贪婪匹配 49 print(re.findall('a.*b.ini', 'a1b22222222b')) # ['a1b22222222b'] 50 # =========================案例 取出下列的整数和小数 51 re.findall('\d+\.?\d+', "asdfasdf123as1.13dfa12adsf1asdf3")


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)