VMware VSphere虚拟网络的深度研究
原址:https://www.ethanzhang.xyz/2023/05/30/VMware VSphere虚拟网络的深度研究/
# VMware VSphere虚拟网络的深度研究
1 开局一张图

2 关于Esxi的管理网络
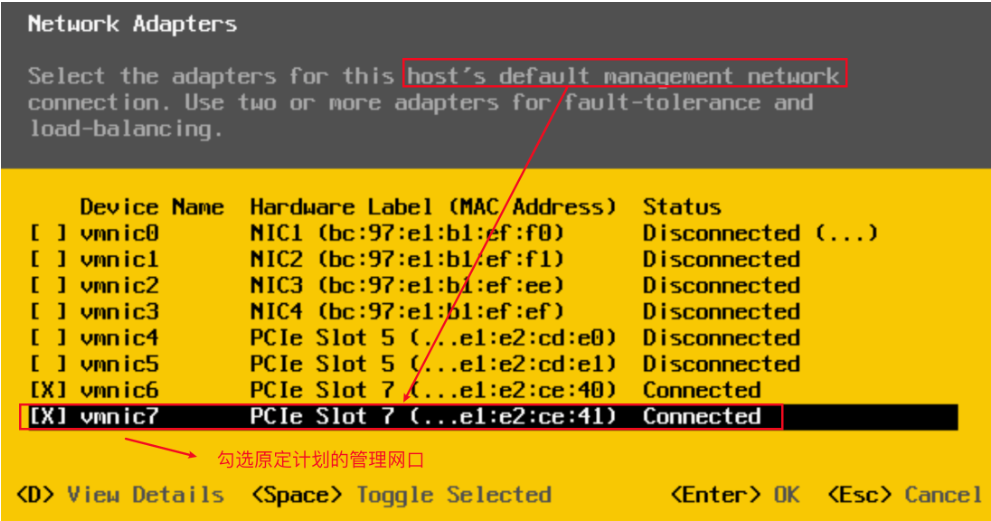
在安装ESXi过程中,我们是通过本地输入设备和显示器进行安装,在安装完成后,通过本地设置界面会提示你勾选管理网络对应的网络适配器
出于高可用性的考虑,我们可以选择2个或者多个网络适配器来进行容错和负载均衡
安装完ESXi主机后,会默认创建一个标准虚拟交换机【注意与后续分布式交换机区分】
物理网卡作为虚拟标准交换机的上行链路接口与物理交換机连接,以此可以对外提供服务
值得注意的是
1、此处Esxi的管理网络就是基于标准交换机,因此此时VCenter Server并没有安装,分布式虚拟交换机只能通过VCenter的界面进行创建
2、名称为Management Network是类型为VMkernel类型的端口组
3、名称为VM Network是类型为基于虚拟机的端口组,上述这里两个不同类型的端口组都是在同一个标准交换机下
4、下图中可以看出类型为VMkernel的端口组的名称为Management Network的网络,以及类型为基于虚拟机端口组的名称为VM Network的网络,上联口均为vmnic7,
5、因此在管理专网的带外管理主机可以通过本管理网络访问和管理Esxi主机或者该同一个标准交换机下的vCenter Server

3 关于物理服务器的物理网卡
在一般的生产环境下,一台物理服务器都会安装多块网卡,例如超融合平台往往会将所承载的业务流量、存储流量、管理流量、容灾流量进行物理隔离
标准交换机或者分布式虚拟交换机绑定了不同的上联物理网络适配器实现了各业务流量的物理隔离
端口组通过VLAN以及不同虚拟机连接不同的端口组,实现了业务的逻辑隔离
例如下图中,我们将业务流量和VMotion流量进行了合并,存储专网专门负责vSAN流量,管理专网专门负责管理流量

我们可以通过SSH登录到Esxi主机上,使用esxcfg-nics -l查看物理网卡的相关信息
注意后续使用其他命令查看VMkernel适配器的区别
[root@localhost:~] esxcfg-nics -l
Name PCI Driver Link Speed Duplex MAC Address MTU Description
vmnic0 0000:17:00.0 bnxtnet Up 10000Mbps Full bc:97:e1:b2:25:2a 1500 Broadcom BCM57416 NetXtreme-E 10GBASE-T RDMA Ethernet Controller
vmnic1 0000:17:00.1 bnxtnet Up 10000Mbps Full bc:97:e1:b2:25:2b 1500 Broadcom BCM57416 NetXtreme-E 10GBASE-T RDMA Ethernet Controller
vmnic2 0000:01:00.0 ntg3 Down 0Mbps Half bc:97:e1:b2:25:28 1500 Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet
vmnic3 0000:01:00.1 ntg3 Down 0Mbps Half bc:97:e1:b2:25:29 1500 Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet
vmnic4 0000:65:00.0 bnxtnet Up 1000Mbps Full bc:97:e1:e2:cd:d0 1500 Broadcom BCM57416 NetXtreme-E 10GBASE-T RDMA Ethernet Controller
vmnic5 0000:65:00.1 bnxtnet Down 0Mbps Half bc:97:e1:e2:cd:d1 1500 Broadcom BCM57416 NetXtreme-E 10GBASE-T RDMA Ethernet Controller
vmnic6 0000:b3:00.0 bnxtnet Up 10000Mbps Full bc:97:e1:e2:bd:50 9000 Broadcom BCM57416 NetXtreme-E 10GBASE-T RDMA Ethernet Controller
vmnic7 0000:b3:00.1 bnxtnet Up 10000Mbps Full bc:97:e1:e2:bd:51 9000 Broadcom BCM57416 NetXtreme-E 10GBASE-T RDMA Ethernet Controller
或者通过VSphere管理平台查看物理服务器的网络适配器的相关信息
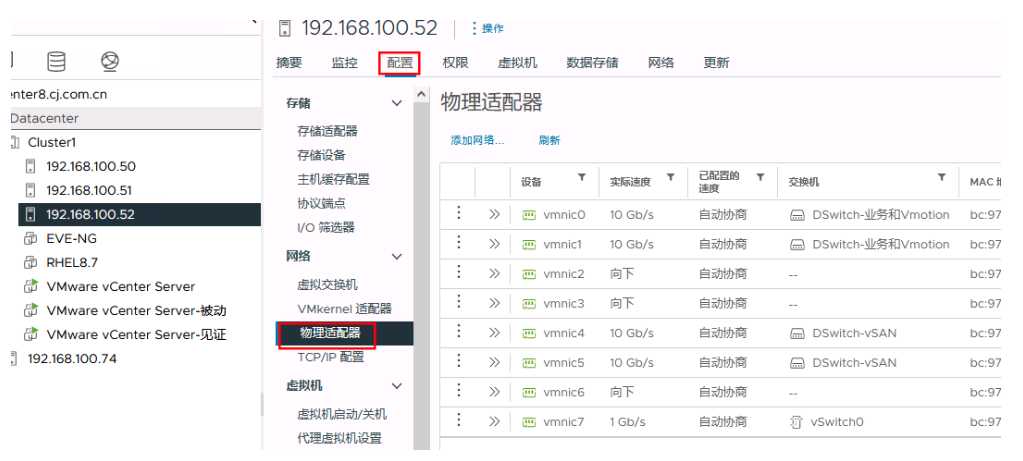
4 ESXi主机网络VLAN实现
我们在实际生产环境中,我们会遇到在物理交换机连接Esxi主机的各个交换机端口,在配置端口类型的选择上,是选择Access类型还是Trunk类型?
其实就是涉及到VSphere对于VLAN的标记模式的概念
官网文档中对于VLAN标记模式的定义
vSphere 在 ESXi 中支持三种 VLAN 标记模式:外部交换机标记 (EST)、虚拟交换机标记 (VST) 和虚拟客户机标记 (VGT)
| 标记模式 | 交换机端口组上的 VLAN ID | 描述 |
|---|---|---|
| EST | 0 | 物理交换机可执行 VLAN 标记。为了访问物理交换机上的端口,会连接主机网络适配器。 |
| VST | 介于 1 和 4094 之间。 | 虚拟交换机可在数据包离开主机前执行 VLAN 标记。主机网络适配器必须连接到物理交换机上的中继端口。 |
| VGT | 4095(适用于标准交换机)Distributed Switch 的范围和各个 VLAN | 虚拟机可执行 VLAN 标记。虚拟交换机在虚拟机网络堆栈和外部交换机之间转发数据包时,会保留 VLAN 标记。主机网络适配器必须连接到物理交换机上的中继端口。vSphere Distributed Switch 支持修改 VGT。为安全起见,可以将 Distributed Switch 配置为仅传递属于特定 VLAN 的数据包。注:对于 VGT,必须在虚拟机的客户机操作系统上安装 802.1Q VLAN 中继驱动程序。 |
总结:
1、EST模式就是物理交换机连接ESXi主机配置Access模式,只需要在物理交换机对应的端口划入相应VLAN即可。缺点:非常不灵活
2、实际生产一般采用VST模式,就是在物理交换机上将连接ESXi主机的端口配置成trunk模式,而在端口组的VLAN属性上设置VLAN ID,承载不同业务的虚拟机又配置了不同端口组的网络适配器,即划分不同的业务VLAN中,从而实现业务的隔离
例如下图,分布式端口组业务-VLAN64表示VLAN ID为64的端口组设置

5 分布式虚拟交换机和标准交换机
在VSphere中,虚拟交换机目前就包括两种:标准交换机 vSphere Standard Switch和分布式交换机 vSphere Distributed Switch
5.1 标准交换机
标准交换机vSphere Standard Switch是为单台主机配置的虛拟交换机,它无法同时为多台主机进行配置,所以当集群存在数量过多的主机时,运维效率不高
每个端口组可使用一个或多个物理网卡来处理其网络流量,如果某个端口组没有与其连接的物理网卡,则相同端口组上的虚拟机只能彼此进行通信,而无法与外部网络进行通信
注意
1、在安装完成ESXi后,系统会自动创建一个标准交换机vSwitch0,这个虛拟交换机的主要功能是提供管理、虛拟机与外界通信等功能
2、在生产环境中,一般会根据应用需要,创建多个标准交换机对各种流量进行分离,提供冗余以及负载均衡
3、标准交换机可以在Esxi管理界面或者VCenter Server上进行设置
4、分布式虚拟交换机只能在VCenter Server上进行设置
5.2 分布式交换机
1、与标准交换机在使用上最显著的区别就是:不需要针对单台主机进行配置,所有连接的主机之问的配置均一致
2、分布式大大提高了运维的效率
分布式交换机只能在VCenter Server上进行配置
在VCenter的清单-网络中查看虚拟分布式交换机
下图有2台虚拟分布式交换机
DSwitch-vSAN处理vSAN流量,DSwitch-业务和Vmotion处理业务流量以及VMotion流量
每台虚拟分布式交换机对有1个上行链路端口组,连接着与物理交换机相连的物理网络适配器
除此之外,DSwitch-vSAN虚拟分布式交换机还有1个分布式端口组,连接着VMkernel适配器

DSwtich-业务和VMotion虚拟分布式交换机有3个分布式端口组,包括2个业务用分布式端口组,一个用于虚拟机使用来处理业务流量,另一个处理VMotion流量,连接着VMkernel适配器

5.3 标准交换机和分布式交换机区别
| 功能描述 | 标准交换机 | 虚拟交换机 |
|---|---|---|
| 入站流量调整 | 否 | 是 |
| 虚拟机网络端口阻止 | 否 | 是 |
| 专用 VLAN | 否 | 是 |
| 基于负载的绑定 | 否 | 是 |
| 访问 NSX-T 端口组 | 否 | 是 |
| vSphere vMotion虛拟网络连接状态迁移 | 否 | 是 |
| 端口级别的策略设置 | 否 | 是 |
5.3.1 管理颗粒度区别
下图可以清晰看到设置的颗粒程度的不同,分布式交换机更加的灵活以及功能更加丰富
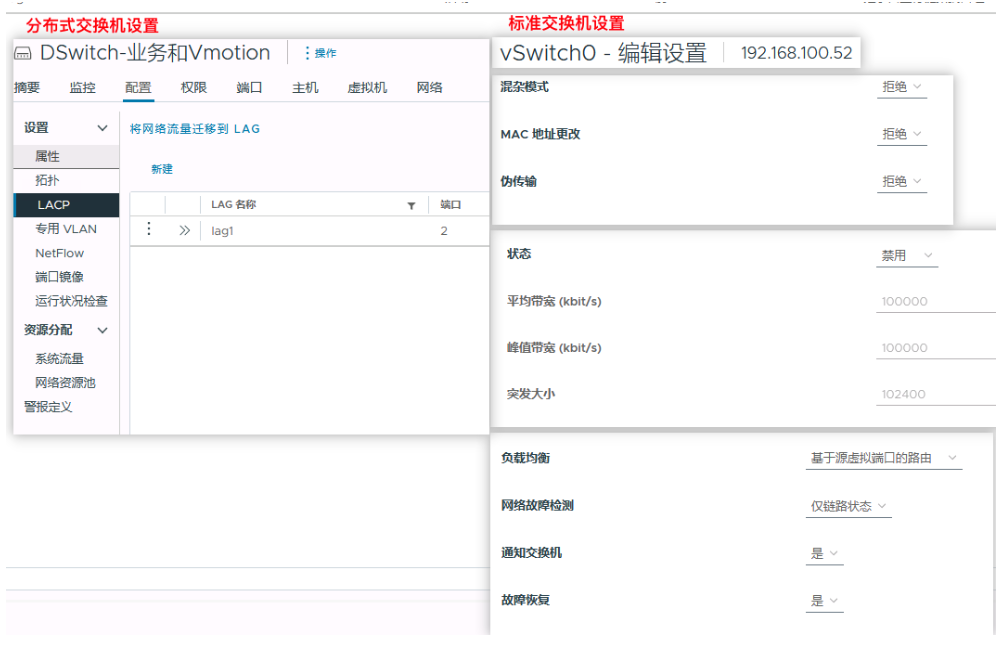
分布式虚拟交换机相比较标准交换机具备完备的管理界面和功能
查看基于端口的状态信息

查看基于主机的状态信息

5.3.2 管理对象区别
从使用上,两者最大的区别是管理对象的区别
标准交换机是基于单台主机,而分布式虚拟交换机是基于多台主机
标准交换机因为是基于单个主机的,因此只能在单个主机上进行查看和设置

分布式交换机可以在清单-网络中进行统一的查看和设置

标准交换机只能基于单个主机进行单独操作
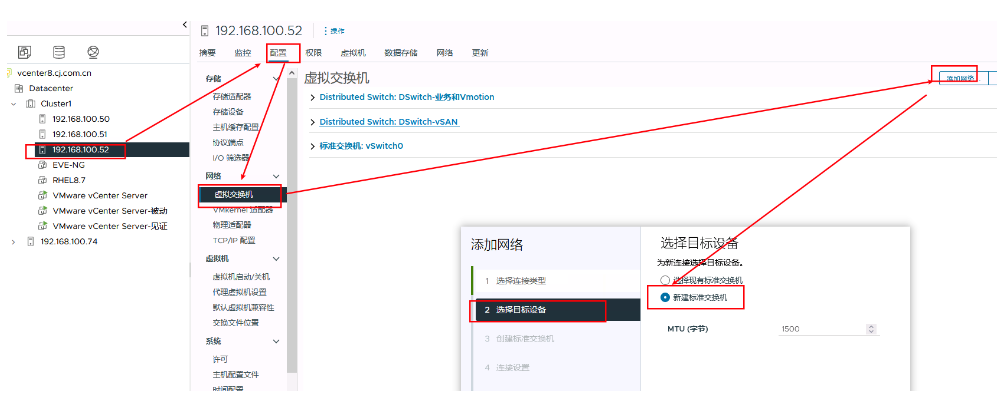
分布式交换机可以在网络设置中统一新建

分布式虚拟交换机是基于多台主机,建立完分布式交换机后,必须执行添加和管理主机操作,将需要使用该虚拟交换机的主机添加至新创建的分布式交换机中

特别注意一点就是,VSS对标准LACP支持不好,只支持思科交换机,而VDS对LACP协议支持较为广泛
6 关于上行链路端口组
只有在分布式交换机上才有上行链路端口组概念
如下图所示

上行链路端口组可以替代端口级别配置替代网络策略
另外根据VLAN实现,上行链路端口组的VLAN设置一般为VLAN中继
6.1 关于上行链路、端口组等关系

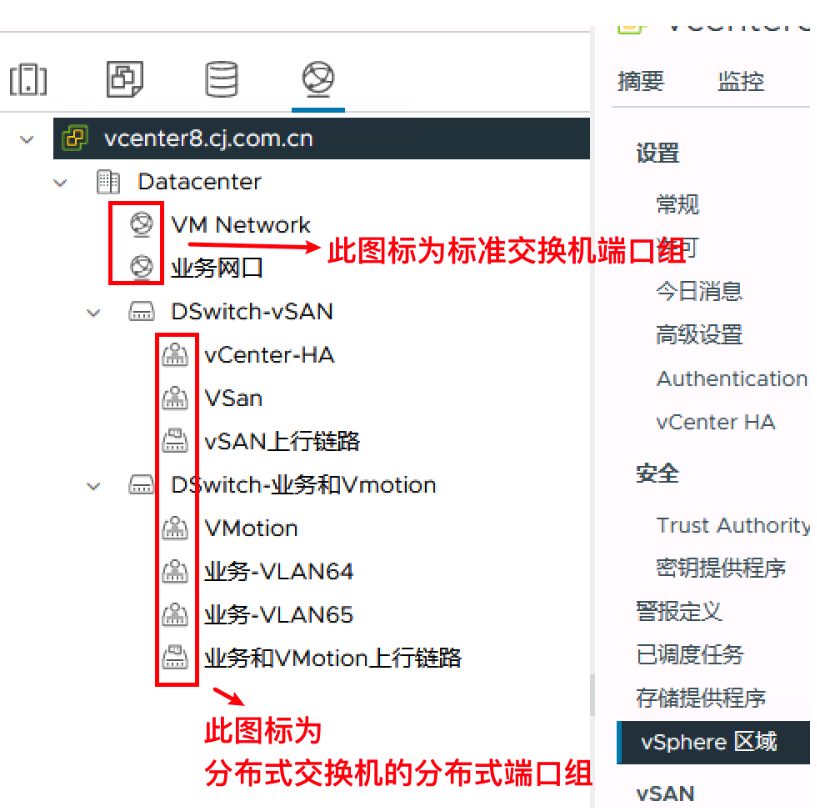
7 关于端口组概念
端口组Port Group,在一个标准交换机和分布式交换机中,可以创建一个或多个Port Group
并且针对不同的Port Group进行VLAN以以及流量控制等方面的配置,然后将虚拟机划入不同的Port Group,这样可以提供不同优先级的网络使用率
标准交换机和分布式交换机的端口组的概念和作用大部分时候其实是一致的,只不过在分布式交换机中被定义成分布式端口组
注意对比两者图标的不同
7.1 几个非常重要的概念
1、对于标准交换机或分布式交换机,他们的上行链路和所在服务器物理网卡是一一对应的,所以才能实现将存储流量、业务流量、容灾流量、管理流量进行物理隔离
2、端口组的作用是可以想象成虚拟交换机的下行端口,所以才能针对不同的业务进行VLAN以及流量的控制,将各业务流量进行逻辑隔离。
3、在同一个标准交换机或分布式交换机的各端口组的流量在出各物理节点的时候,都是走相同的单个物理网络适配器或多个物理网络适配器(如果配置了负载均衡的时候)

4、为虚拟机添加网络从某种程度上可以理解为为虚拟机配置哪个网络适配器
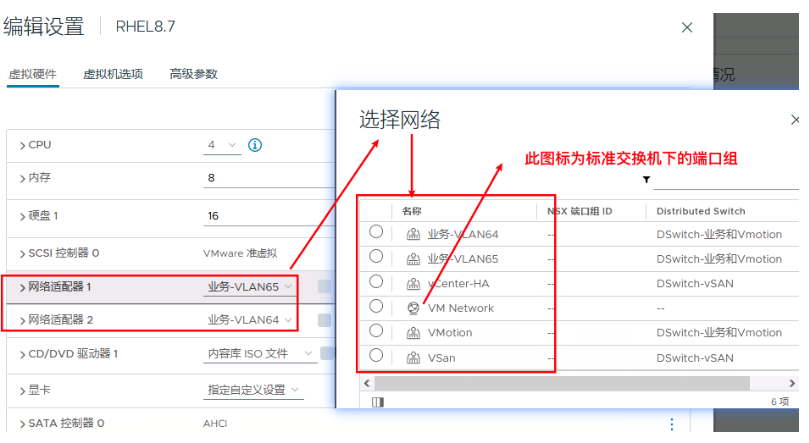
5、端口组有一个很重要的概念,就是绑定和故障切换策略
7.2 标准交换机端口组和分布式端口组区别
因为标准交换机是基于单个物理节点的,因此默认情况下标准交换机的设置为默认选项,除非标准交换机下的端口组勾选了替代选项

标准交换机有关安全的设置是和在分布式端口组中功能是相对应的

分布式端口组的设置选项

8 关于绑定和故障切换策略
关于绑定和故障切换策略一定是在端口组中进行配置,包括标准交换机的端口组以及分布式交换机下的分布式端口组
标准交换机也可以进行绑定和故障切换策略进行相关设置
8.1 负载均衡策略
负载均衡策略确定网络流量如何在网卡组中的网络适配器之间分布
vSphere 虚拟交换机仅对出站流量进行负载均衡,输入流量由物理交换机上的负载均衡策略控制。
以下是各种负载平衡算法
8.1.1 基于源虚拟端口的路由
基于源虚拟端口的路由是 vSphere 标准交换机和 vSphere Distributed Switch 上的默认负载平衡方法
它会将虚拟机的虚拟网卡和物理网卡进行绑定,当组中虚拟网卡数大于物理网卡数时,流量分布均匀,资源消耗低,因为在大多数情况下,虚拟交换机仅计算虚拟机上行链路一次。
劣势:虚拟机一旦开机,就会与上行链路的物理适配器进行绑定,就是无法做到负载均衡,除非活动物理网络适配器出现故障
8.1.2 基于源 MAC 哈希的路由
这种方式与基于源虛拟端口负载均衡方式相似,如如果虚拟机只使用一个物理网卡,那么它的源MAC地址是不会发生任何变化,系统分配物理网卡以及绑定后,虚拟机流量始终走虚拟交换机分配的物理网卡,不管这个物理网卡流量是否过载,除非当分配的这个物理网卡故障后才会尝试走另外活动的物理网卡
劣势:虚拟机会使用相同的上行链路,因为 MAC 地址是静态地址。启动或关闭虚拟机不会更改虚拟机使用的上行链路,也是无法做到负载均衡
8.1.3 基于 IP 哈希的路由
虚拟交换机可根据每个数据包的源和目标 IP 地址选择虚拟机的上行链路
要计算虚拟机的上行链路,虚拟交换机会获取数据包中源和目标 IP 地址的最后一个八位字节并对其执行 XOR 运算,然后根据网卡组中的上行链路数将所得的结果用于另一个计算。结果是一个介于 0 和组中上行链路数减一之间的数字。例如,如果网卡组有四个上行链路,则结果是一个介于 0 和 3 之间的数字,因为每个数字与组中的一个网卡相关联。对于非 IP 数据包,虚拟交换机会从 IP 地址所在的帧或数据包中提取两个 32 位二进制值
任何虚拟机都可根据源和目标 IP 地址使用网卡组中的任何上行链路。因此,每台虚拟机都可以使用网卡组中任何上行链路的带宽。如果虚拟机在包含大量独立虚拟机的环境中运行,则 IP 哈希算法可在组中的网卡之间均匀地分布流量。当虚拟机与多个目标 IP 地址通信时,虚拟交换机可为每个目标 IP 生成不同的哈希。因此,数据包可以使用虚拟交换机上的不同上行链路,从而可能实现更高的吞吐量
但是,如果环境中包含的 IP 地址较少,则虚拟交换机可能会始终通过组中的一个上行链路传递流量。例如,如果一个应用程序服务器访问一个数据库服务器,则虚拟交换机会始终计算同一个上行链路,因为只存在一个源-目标对
优势:真正实现了负载均衡
注意:
在ESXi主机网络上使用基于IP哈希算法的负载均衡,还必须满足一个前提,就是物理交换机必须支持链路聚合协议(LACP) ,同时要求端口必须处于同物理交换机
如果物理交换机不支持LACP,则无法实现基于IP哈希的路由
特别注意:
1、标准交换机VSS对LACP支持不好,只支持思科交换机
2、VDS可以支持标准LACP
3、在 IP 哈希负载均衡策略中,连接到活动上行链路的所有物理交换机端口都必须采用链路聚合模式
4、应为使用同一上行链路集的所有端口组设置 IP 哈希负载均衡
5、当选择链路聚合组 (LAG) 作为唯一的活动上行链路时,LAG 的负载均衡模式将替代端口组的负载均衡模式
LAG 的负载均衡模式将替代端口组的负载均衡模式的理解:
例如,在使用 LACP 的情况下将故障恢复设置为是或否时不存在任何明显行为差异,因此认为LAG 设置优先于端口组设置
8.1.4 基于物理网卡负载的路由
仅适用于 vSphere Distributed Switch
Distributed Switch 将使用虚拟机端口 ID 和网卡组中的上行链路数目来计算虚拟机的上行链路。Distributed Switch 将每 30 秒测试一次上行链路,如果上行链路的负载超过 75% 的使用率,则拥有最高 I/O 的虚拟机的端口 ID 将移到其他上行链路
8.1.5 使用明确故障切换顺序
虚拟交换机始终使用“活动适配器”列表中按故障切换顺序位于最前列且符合故障切换检测标准的上行链路
如果活动列表中没有可用的上行链路,则虚拟交换机将使用备用列表中的上行链路
8.2 关于网络故障检测
仅链路状态:仅取决于网络适配器提供的链路状态。该选项可用于检测故障,如电缆移除和物理交换机电源故障。
信标探测:发出并侦听组中所有网卡上的信标探测,使用此信息并结合链路状态来确定链路故障。ESXi 每秒发送一次信标数据包。网卡必须处于活动/活动或活动/备用配置中,因为“未使用”状态中的网卡不会加入信标探测。
8.3 通知交换机
虚拟机启动、虛拟机进行vMotion操作、虚拟机MAC地址发生变化等情况发生时,物理交换机会收到用反向地址解析协议RARP表示的变化通知
物理交换机是否知道取决于通知交换机的设置,设置为是则立即知道,设置为否则不知道
RARP会更新物理交换机的查询表,并且在故障恢复事件时提供最短延迟时间
9 关于VMkernel
VMkernel 网络层提供与主机的连接,并处理 vSphere vMotion、IP 存储、Fault Tolerance、vSAN 等其他服务的标准系统流量
这里有一个很重要的概念,就是创建VMkernel适配器过程中,上行链路可以是标准交换机或者是分布式交换机,但VMkernel适配器相当于是插在ESXi主机上的

我们在某台主机上查看VMkernel适配器,进行验证

或者通过SSH登录到该节点,使用esxcfg-vmknic -l进一步验证
[root@localhost:~] esxcfg-vmknic -l
Interface Port Group/DVPort/Opaque Network IP Family IP Address Netmask Broadcast MAC Address MTU TSO MSS Enabled Type NetStack
vmk0 Management Network IPv4 192.168.100.52 255.255.0.0 192.168.255.255 bc:97:e1:e2:ce:41 1500 65535 true STATIC defaultTcpipStack
vmk0 Management Network IPv6 fe80::be97:e1ff:fee2:ce41 64 bc:97:e1:e2:ce:41 1500 65535 true STATIC, PREFERRED defaultTcpipStack
vmk1 2 IPv4 10.0.0.52 255.255.255.0 10.0.0.255 00:50:56:63:a6:33 9000 65535 true STATIC defaultTcpipStack
vmk1 2 IPv6 fe80::250:56ff:fe63:a633 64 00:50:56:63:a6:33 9000 65535 true STATIC, PREFERRED defaultTcpipStack
vmk2 35 IPv4 10.0.1.52 255.255.255.0 10.0.1.255 00:50:56:61:cd:a7 1500 65535 true STATIC defaultTcpipStack
vmk2 35 IPv6 fe80::250:56ff:fe61:cda7 64 00:50:56:61:cd:a7 1500 65535 true STATIC, PREFERRED defaultTcpipStack
vmk3 VMkernel-test IPv4 N/A N/A N/A 00:50:56:64:95:73 1500 65535 true NONE defaultTcpipStack
vmk3 VMkernel-test IPv6 fe80::250:56ff:fe64:9573
9.1 VMkernel的服务概念
通过为VMKernel启用特定服务,为 vCenter Server 与 ESXi 主机之间的管理流量和 vMotion、IP 存储、Fault Tolerance 等服务的系统流量提供网络支撑
可以看到,默认ESXi刚安装完毕后,启用任何一个网络适配器作为管理口的设置,默认管理服务是打开状态

下图是承载vSAN的服务,VMKernel的启用状态
如果要承载VSAN流量必须启用VSAN服务同时通过IPv4设置的地址,确保各个物理节点能够正常通讯,将vSAN存储数据进行传输s

9.2 VMKernel流量类型
专门针对每种流量类型使用单独的 VMkernel 适配器
对于 Distributed Switch,专门针对每个 VMkernel 适配器使用单独的分布式端口组,意味着分布式交换机的VMkernel是必须在端口组内进行添加,如下图

管理流量
承载着 ESXi 主机和 vCenter Server 以及主机对主机 High Availability 流量的配置和管理通信。默认情况下,在安装 ESXi 软件时,会在主机上为管理流量创建 vSphere 标准交换机以及 VMkernel 适配器。为提供冗余,可以将两个或更多个物理网卡连接到 VMkernel 适配器以进行流量管理
vMotion 流量
容纳 vMotion。源主机和目标主机上都需要一个用于 vMotion 的 VMkernel 适配器。将用于 vMotion 的 VMkernel 适配器配置为仅处理 vMotion 流量。为了实现更好的性能,可以配置多网卡 vMotion。要拥有多网卡 vMotion,可以将两个或更多端口组专门用于 vMotion 流量,每个端口组必须分别有一个与其关联的 vMotion VMkernel 适配器。然后可以将一个或多个物理网卡连接到每个端口组。这样,有多个物理网卡用于 vMotion,从而可以增加带宽
注:vMotion 网络流量未加密。应置备安全专用网络,仅供 vMotion 使用
置备流量
处理虚拟机冷迁移、克隆和快照迁移传输的数据
IP 存储流量和发现
处理使用标准 TCP/IP 网络和取决于 VMkernel 网络的存储类型的连接。此类存储类型包括软件 iSCSI、从属硬件 iSCSI 以及 NFS。如果 iSCSI 具有两个或多个物理网卡,则可以配置 iSCSI 多路径。 ESXi 主机支持 NFS 3 和 4.1
Fault Tolerance 流量
处理主容错虚拟机通过 VMkernel 网络层向辅助容错虚拟机发送的数据。vSphere HA 集群中的每台主机上都需要用于 Fault Tolerance 日志记录的单独 VMkernel 适配器
vSphere Replication 流量
处理源 ESXi 主机传输至 vSphere Replication 服务器的出站复制数据。在源站点上使用一个专用的 VMkernel 适配器,以隔离出站复制流量
vSphere Replication NFC 流量
处理目标复制站点上的入站复制数据
vSAN 流量
加入 vSAN 集群的每台主机都必须有用于处理 vSAN 流量的 VMkernel 适配器
vSphere Backup NFC
专用备份 NFC 流量的 VMKernel 端口设置。启用 vSphere Backup NFC 服务时,NFC 流量将通过 VMKernel 适配器
NVMe over TCP
专用 NVMe over TCP 存储流量的 VMkernel 端口设置。启用 NVMe over TCP 适配器时,NVMe over TCP 存储流量将通过 VMkernel 适配器
NVMe over RDMA
专用 NVMe over RDMA 存储流量的 VMkernel 端口设置。启用 NVMe over RDMA 适配器时,NVMe over RDMA 存储流量将通过 VMkernel 适配器
注:NVMe over TCP和NVMEe over RDMA,均是和存储有关系
10 链路聚合
以太网链路聚合Eth-Trunk简称链路聚合,它通过将多条以太网物理链路捆绑在一起成为一条逻辑链路,从而实现增加链路带宽的目的。同时,这些捆绑在一起的链路通过相互间的动态备份,可以有效地提高链路的可靠性
10.1 链路聚合优势
1、增加带宽
链路聚合接口的最大带宽可以达到各成员接口带宽之和
2、提高可靠性
当某条活动链路出现故障时,流量可以切换到其他可用的成员链路上,从而提高链路聚合接口的可靠性
3、负载分担
在一个链路聚合组内,可以实现在各成员活动链路上的负载分担
10.2 设备支持的链路聚合方式
同一设备:是指链路聚合时,同一聚合组的成员接口分布在同一设备上。
堆叠设备:是指在堆叠场景下,成员接口分布在堆叠的各个成员设备上。
跨设备:是指E-Trunk基于LACP(单台设备链路聚合的标准)进行了扩展,能够实现多台设备间的链路聚合,或者称之为M-LAG*(Multichassis Link Aggregation Group)即跨设备链路聚合组
10.3 链路聚合类型
根据是否启用链路聚合控制协议LACP,链路聚合分为手工负载分担模式、静态LACP模式和动态LACP模式
静态LACP模式下,需手工创建Eth-Trunk,手工加入Eth-Trunk成员接口,但活动接口的选择是由LACP协商确定的,配置相对灵活
动态LACP模式Eth-Trunk:活动接口的选择完全由LACP 协议通过协商完成。这就意味着启用了动态LACP 协议的两台直连设备上,不需要创建Eth-Trunk 接口,也不需要指定哪些接口作为聚合组成员接口,两台设备会通过LACP 协商自动完成链路的聚合操作
动态LACP模式一般用于交换机与服务器互连的场景。其他场景下,建议部署静态LACP模式Eth-Trunk,如果部署动态LACP,则网络会有成环风险
10.4 标准交换机启用链路聚合组
可以在交换机上使用双端口 LACP 静态端口通道,并在 vSphere Standard Switch 上使用两个活动上行链路
几个注意事项
基于 IP 哈希的负载均衡不支持备用上行链路。需要将所有的备用上行链路更改为活动状态
在 IP 哈希负载均衡策略中,连接到活动上行链路的所有物理交换机端口都必须采用链路聚合模式
应为使用同一上行链路集的所有端口组设置 IP 哈希负载均衡

如果端口组进行了替代设置
所有端口组继承在 vSwitch 级别设置的绑定和故障切换策略。您可以覆盖单个端口组绑定和故障切换策略,使其与父 vSwitch 不同,但请确保为所有端口组使用相同的上行链路组实现 IP 哈希负载均衡
10.5 分布虚拟交换机创建动态LACP
分布式虚拟交换机配置相对复杂
10.5.1 首先在 vDS 上创建 LAG
负载均衡模式选择:源和目标 IP 地址、TCP/UDP 端口和 VLAN

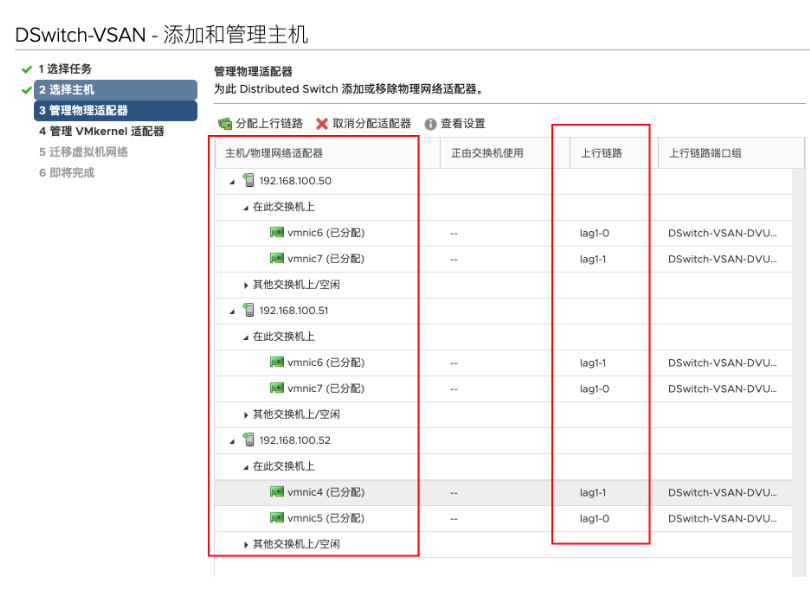
10.5.2 将物理上行链路添加到 LAG
vSAN 主机已添加到 vDS。将单个 vmnic 分配给相应的 LAG 端口
- 右键单击 vDS,然后选择添加和管理主机…
- 选择管理主机网络,然后添加连接的主机。
- 在管理物理适配器上,选择相应的适配器并将其分配给 LAG 端口
- 将 vmnic0 从上行链路 1 位置迁移到 LAG1 上的端口 0
对 vmnic1 重复上述过程,将其分配到第二个 LAG 端口位置 lag1-1
10.5.3 编辑端口组并配置绑定和故障切换策略
确保 LAG 组 lag1 位于活动上行链路位置,并确保其余上行链路处于未使用位置
选择链路聚合组(LAG) 作为唯一的活动上行链路时LAG 的负载均衡 模式将覆盖端口组的负载均衡模式因此,基于IP哈希的路由策路不会起到任何作用

注意:
LAG 负载均衡策略会替代 vSphere 分布式端口组的绑定和故障切换策略
在使用 LACP 的情况下将故障恢复设置为是或否时不存在任何明显行为差异,LAG 设置优先于端口组设置
再次强调:在分布式虚拟交换机中,如果采用动态LACP,必须将lag作为唯一的活动上行链路,否则网络仍无法正常通讯
11 关于MTU以及MTU值修改影响实验
巨帧减少了由传输数据引起的 CPU 负载,使用巨型帧以提高 CPU 性能,往往在vSAN等一些地方需要设置MTU=9000
重要说明:
更改 vSphere Distributed Switch 的 MTU 大小时,作为上行链路分配的物理网卡会关闭并重新启动
这会导致使用上行链路的虚拟机或服务出现 5 到 10 毫秒的短暂网络中断
网络必须端到端支持巨帧(包括物理网络适配器、物理交换机和存储设备)
任何一个环节出现问题,都无法进行巨型帧的传输
11.1 测试环境介绍
创建了1台分布式交换机【网络名称为:DSwitch-业务和Vmotion】,包括端口组VMotion,然后在各ESXi节点添加了VMKernel适配器,启用了VMotion服务器
通过登录管理网络地址为192.168.100.52地址的ESXi主机,使用vmkping工具,带-d -s参数对另外一个管理网络地址为192.168.100.51地址的ESXi主机`进行自定义MTU值的ping连通性访问实验,来介绍各个环节中对MTU最大传输单元的影响
其中-d参数表示IP不分片,-s参数表示ICMP报文中所带数据大小,单位:字节
各服务器所连接的物理交换机均已启用了巨型帧支持,这里就不把这个影响进行做实验测试
| 主机/交换机名 | 管理网络地址 | VMotion端口组下的VMKernel IPv4地址 |
|---|---|---|
| ESXi主机1 | 192.168.100.51 | 网络名为:vmk2,IPv4地址:10.0.1.51 |
| ESXi主机2 | 192.168.100.52 | 网络名为:vmk2,IPv4地址:10.0.1.52 |
| 分布式交换机 | 网络名称为:DSwitch-业务和Vmotion |
11.2 实验1 VMKernel的MTU设置影响
实验1:如果将在192.168.100.52ESXi主机和在192.168.100.51ESXi主机任何一台的vmk2 VMKernel的MTU值设置为默认1500

在192.168.100.52ESXi主机上通过vmkping访问192.168.100.51进行测试,当MTU超过1473时【为什么是1473,后续有描述】,访问失败
[root@localhost:~] vmkping -d -s 1473 10.0.1.51
PING 10.0.1.51 (10.0.1.51): 2000 data bytes
sendto() failed (Message too long)
sendto() failed (Message too long)
sendto() failed (Message too long)
--- 10.0.1.51 ping statistics ---
3 packets transmitted, 0 packets received, 100% packet loss
此时将vmk2 VMKernel所在分布式虚拟交换机的全局MTU设置为8000[暂时不设置为9000,后续实验使用]

继续将在192.168.100.52ESXi主机和在192.168.100.51ESXi主机的vmk2 VMKernel的MTU值设置均为默认9000
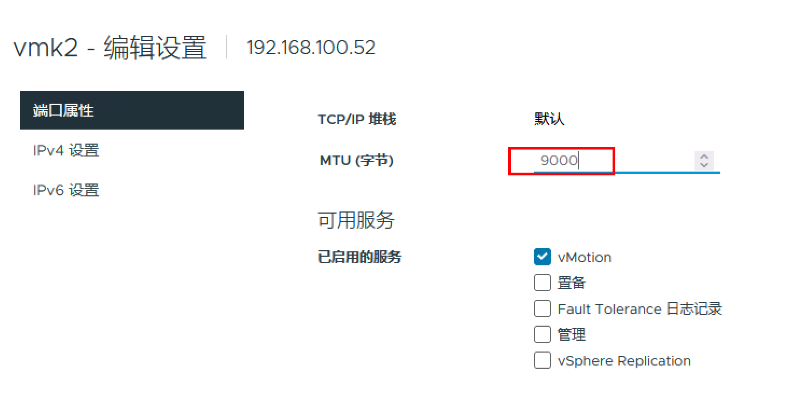
[root@localhost:~] vmkping -d -s 7972 10.0.1.51
PING 10.0.1.51 (10.0.1.51): 7972 data bytes
7980 bytes from 10.0.1.51: icmp_seq=0 ttl=64 time=0.431 ms
7980 bytes from 10.0.1.51: icmp_seq=1 ttl=64 time=0.519 ms
7980 bytes from 10.0.1.51: icmp_seq=2 ttl=64 time=0.402 ms
只要MTU不超过7972,均能成功访问
11.3 实验2 分布式虚拟交换机的MTU设置影响
在将vmk2 VMKernel所在分布式虚拟交换机的全局MTU设置为8000,MTU超过7972,访问失败
[root@localhost:~] vmkping -d -s 7973 10.0.1.51
PING 10.0.1.51 (10.0.1.51): 7973 data bytes
--- 10.0.1.51 ping statistics ---
3 packets transmitted, 0 packets received, 100% packet loss
此时修改将vmk2 VMKernel所在分布式虚拟交换机的全局MTU设置为9000,访问成功

[root@localhost:~] vmkping -d -s 8972 10.0.1.51
PING 10.0.1.51 (10.0.1.51): 8972 data bytes
8980 bytes from 10.0.1.51: icmp_seq=0 ttl=64 time=0.472 ms
8980 bytes from 10.0.1.51: icmp_seq=1 ttl=64 time=0.481 ms
8980 bytes from 10.0.1.51: icmp_seq=2 ttl=64 time=0.464 ms
--- 10.0.1.51 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.464/0.472/0.481 ms
11.4 总结
1、网络必须端到端支持巨帧(包括物理网络适配器、物理交换机和存储设备),任何一个环节出现问题,都无法进行巨型帧的传输
2、VMKernel的MTU设置、分布式交换机的MTU设置【标准交换机设置原理一样,详见下图】均影响了整个链路的环节
3、如果虚拟机要使用巨型帧,则虚拟机也必须做相应设置,虚拟机的巨型帧支持设置方法如下:
1、要在虚拟机上启用巨帧支持,该虚拟机需要增强型 VMXNET 适配器
2、即在虚拟机适配器类型下拉菜单中,选择 VMXNET 2(增强型)或 VMXNET 3
11.5 ping命令中MTU参数大小与实际配置MTU大小关系
在实验1和实验2过程中,我们会发现一个规律,即vmkping命令所带的-s参数所表示的MTU的大小如果超过了所设置的任何环节MTU值中最小值减去28个字节就会显示丢包
原因是因为ESXi操作系统所用的vmkping命令和Linux操作系统所使用的ping命令一样,同样使用ICMP协议
windows的ping命令使用UDP协议,UDP协议报文头部也是8个字节
ICMP协议自身包头为8个字节,ICMP是承载在IP协商上的,IP协议的包头为20个字节
MTU其实属于2层的一个概念,它的目的是限定【MAC帧中数据部分(payload)的大小】的值,换句话说就是影响到【第3层的整个IP封包的大小】
MTU = IP封包的大小
vmkping命令所携带-s参数是站在ICMP协议层的角度,所携带的数据字节大小
因此当使用vmkping -d -s 1473或者vmkping -d -s 8973时候,站在二层MTU的数据大小已经是1501和9001了,如果此时VMKernel的MTU设置、分布式交换机的MTU设置设置是1500或者9000,则会造成网卡或者虚拟交换机的丢弃


 浙公网安备 33010602011771号
浙公网安备 33010602011771号