WebMagic入门尝试 ——爬取博客的标题
通过这两天的学习,对WebMagic有了初步的掌握,这里分享的这个小项目是用于爬取我个人博客的所有标题,我尽量说的详细些,希望可以帮到和我一样的初学者。
思路:
首先确定爬取目标,那就是我的博客https://www.cnblogs.com/liuleliu/中所有的标题。
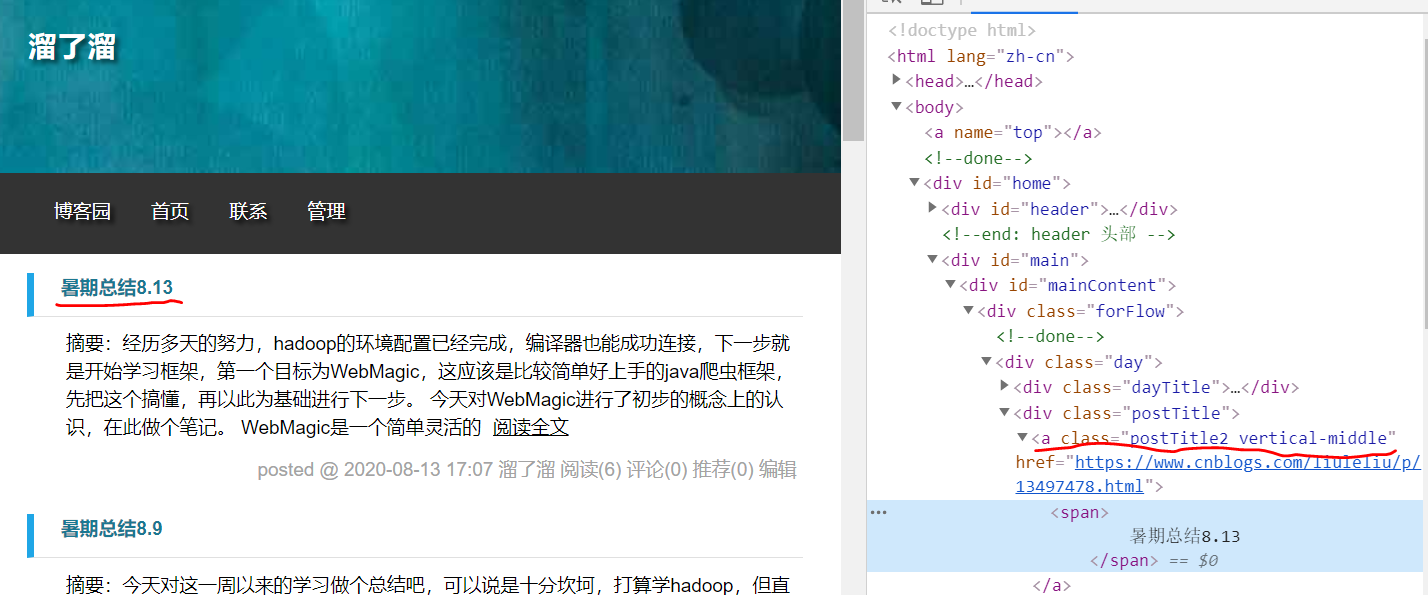
通过观察网页代码可发现,标题存放于class="postTitle2 vertical-middle" 的<a>所包含的<span>中
因此就可以由此得出提取其中标题的语句:
page.getHtml().css("a.postTitle2.vertical-middle span","text").all()
其中page在WebMagic中是我们所爬取到的页面,.getHtml().css("a.postTitle2.vertical-middle span","text")是利用css选择器来提取元素 .all是获取页面中所有符合要求的元素
其实这就是核心功能了,但实际情况是我的博客不只一页,这样处理只能爬取一页的数据,因此之后我们要获得其他的页面
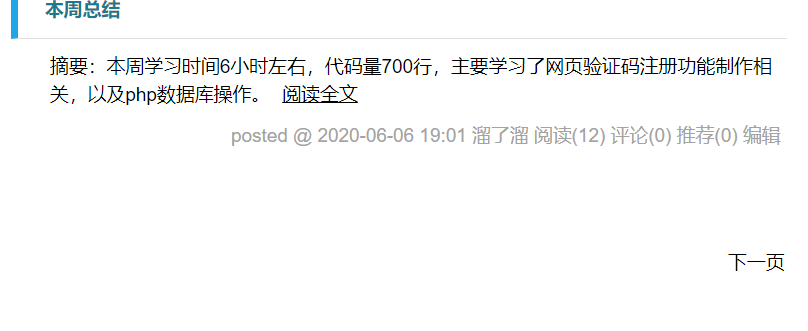
通过观察可以看到,每一页都可以通过‘下一页’跳转到下一页,因此我们每爬取一个页面的时候,把其中‘下一页’的连接添加入处理队列就可以了。
但是又发现第一页和其他页面的‘下一页’不一样,因此就需要在代码里进行一下判断,然后再分别处理,,这里采取的判断方式就是根据他们的网页代码中‘下一页’的所在位置所在类的不同进行区分:
//判断是否为首页
String next= page.getHtml().css("div#nav_next_page a").links().get();
if(next!=null) page.addTargetRequest(next);//是首页,将下一页的url加入处理队列
else{
//不是首页,判断是否有下一页,有的话将下一页放入处理队列
List<Selectable> pages=page.getHtml().css("div.pager a").nodes();
//获取跳转链接的列表最后一位,即‘下一页’的url
next=pages.get(pages.size()-1).links().toString();
if(next!=null) page.addTargetRequest(next);
}
当然,如果博客这里只有一页的话便不会把任何url加入队列,最终爬虫只会对第一页的数据进行提取。
下面是完整代码:
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.pipeline.FilePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.scheduler.FileCacheQueueScheduler;
import us.codecraft.webmagic.selector.Selectable;
import java.util.List;
public class MyProcessor implements PageProcessor {
//爬虫初始化时的url
static String url="https://www.cnblogs.com/liuleliu/default.html";
//对爬虫进行配置
private Site site = Site.me().
setRetryTimes(3). //设置重试间隔
setSleepTime(100);//设置重试次数
public Site getSite() {
return site;
}
public void process(Page page) {
//判断是否为首页
String next= page.getHtml().css("div#nav_next_page a").links().get();
if(next!=null) page.addTargetRequest(next);//是首页,将下一页的url加入处理队列
else{
//不是首页,判断是否有下一页,有的话将下一页放入处理队列
List<Selectable> pages=page.getHtml().css("div.pager a").nodes();
//获取跳转链接的列表最后一位,即‘下一页’的url
next=pages.get(pages.size()-1).links().toString();
if(next!=null) page.addTargetRequest(next);
}
//获取标题,并放入键对中
page.putField("title",page.getHtml().css("a.postTitle2.vertical-middle span","text").all());
}
public static void main(String[] args) {
Spider.create(new MyProcessor()).addUrl(url)
//设置爬取结果存储形式和位置,这里将结果同时输出到console页面
.addPipeline(new ConsolePipeline()).addPipeline(new FilePipeline("C:\\Users\\20514\\Desktop\\3"))
//使用文件保存抓取的URL,可以在关闭程序并下次启动时,从之前抓取的URL继续抓取。需指定路径,会建立.urls.txt和.cursor.txt两个文件。
.setScheduler(new FileCacheQueueScheduler("C:\\Users\\20514\\Desktop\\3"))
//启用五个线程执行爬虫
.thread(5)
//执行爬虫
.run();
}
}
执行效果:
控制台:

储存的文件: