python爬取网页图片并保存到本地
先把原理梳理一下:首先我们要爬取网页的代码,然后从中提取图片的地址,通过获取到的地址来下载数据,并保存在文件中,完成。
下面是具体步骤:
先确定目标,我挑选的是国服守望先锋的官网的英雄页面,我的目标是爬取所有的英雄的图片
页面是这样的
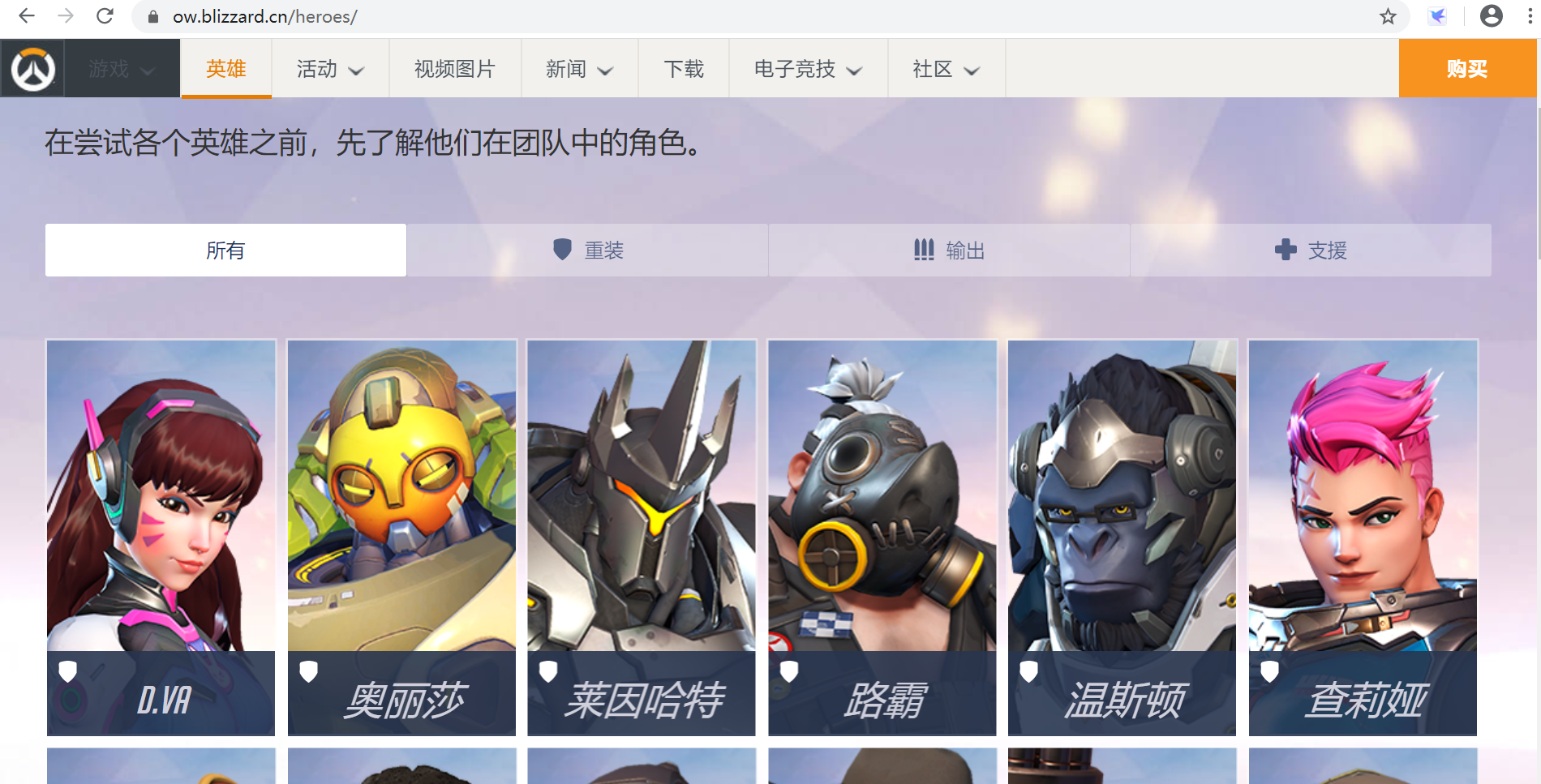
首先做的就是得到它的源代码找到图片地址在哪里
这个函数最终会返回网页代码
def getHtml(url):
html = requests.get(url)
return html.text
将其先导入文本文件观察
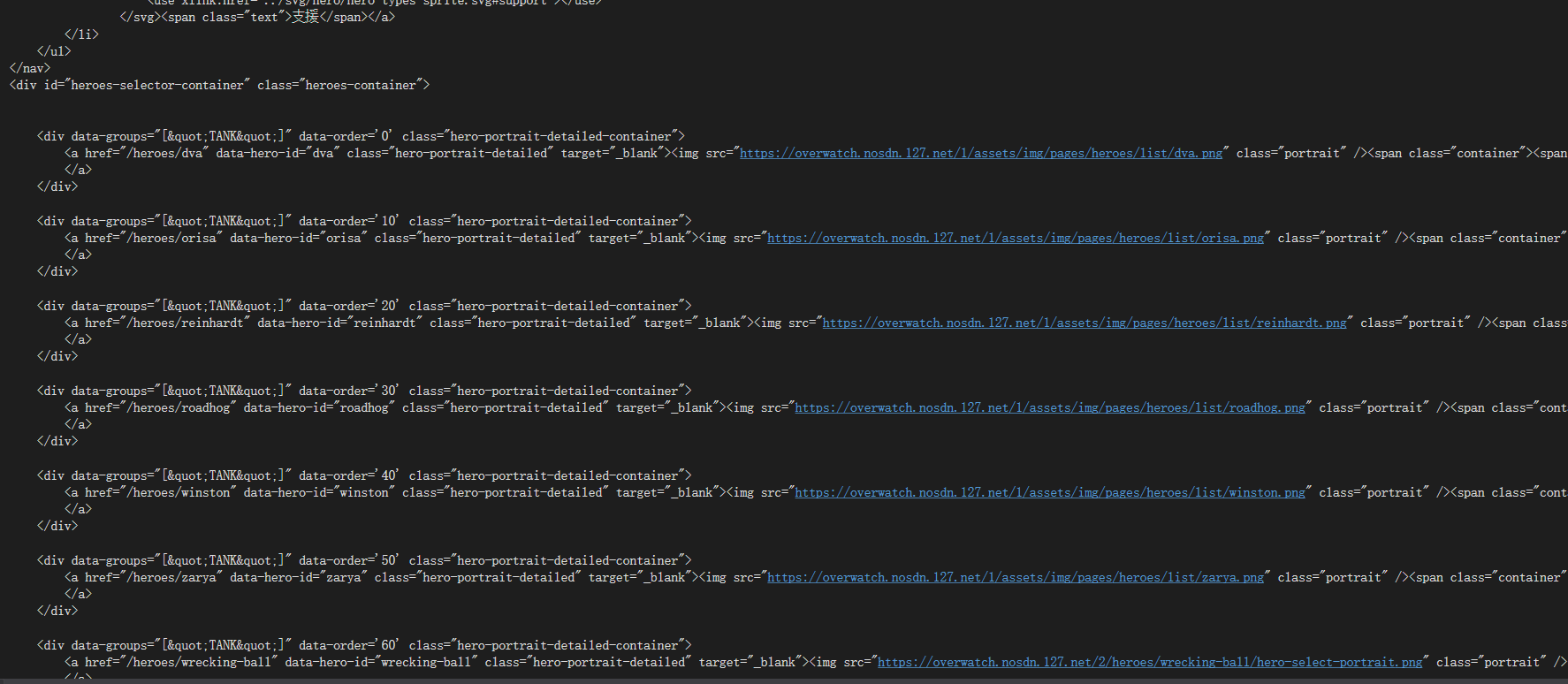
发现图片的地址所在位置格式是这样
<img src="https://overwatch.nosdn.127.net/1/assets/img/pages/heroes/list/zarya.png" class="portrait" />
因此就可以依此写出正则表达式,并从网页代码中将图片地址提取出来
imagelist=re.findall('img src="(.*?)" class="portrait"',html)
上面这句话得到的就是图片地址的集合
之后要做的就是遍历集合中的地址,依此下载并保存到目标的文件夹中
下面是项目完整代码
# -*- coding: utf-8 -*-
'''
Created on 2020年3月12日
@author: 20514
'''
import requests
import re
#打开网页,获取网页源码
def getHtml(url):
html = requests.get(url)
return html.text
def getImag(html):
imagelist=re.findall('img src="(.*?)" class="portrait"',html)
pat = 'list/(.*?).png'
ex = re.compile(pat)
i=1
for url in imagelist:
print('Downloding:'+url)
#从图片地址下载数据
image=requests.get(url)
# 获取英雄名(这里可以自己为文件取名就行,下面的name变量是从图片地址中提取到的英雄名)
pat = 'list/(.*?).png'
ex = re.compile(pat)
if ex.search(url):
name=ex.search(url).group(1)
else:
pat ='heroes/(.*?)/hero-select'
ex = re.compile(pat)
if ex.search(url):
name=ex.search(url).group(1)
else:
name='new'+str(i)+'?'
i=i+1
#在目标路径创建相应文件
f=open('C:\\Users\\20514\\Desktop\\owhero\\'+name+'.png','wb')
#将下载到的图片数据写入文件
f.write(image.content)
f.close()
return '结束'
print('获取ow官网英雄图片')
url='https://ow.blizzard.cn/heroes/'
print('正在获取图片')
html=getHtml(url)
print('下载图片中')
print(getImag(html))
print('下载完成')
效果:
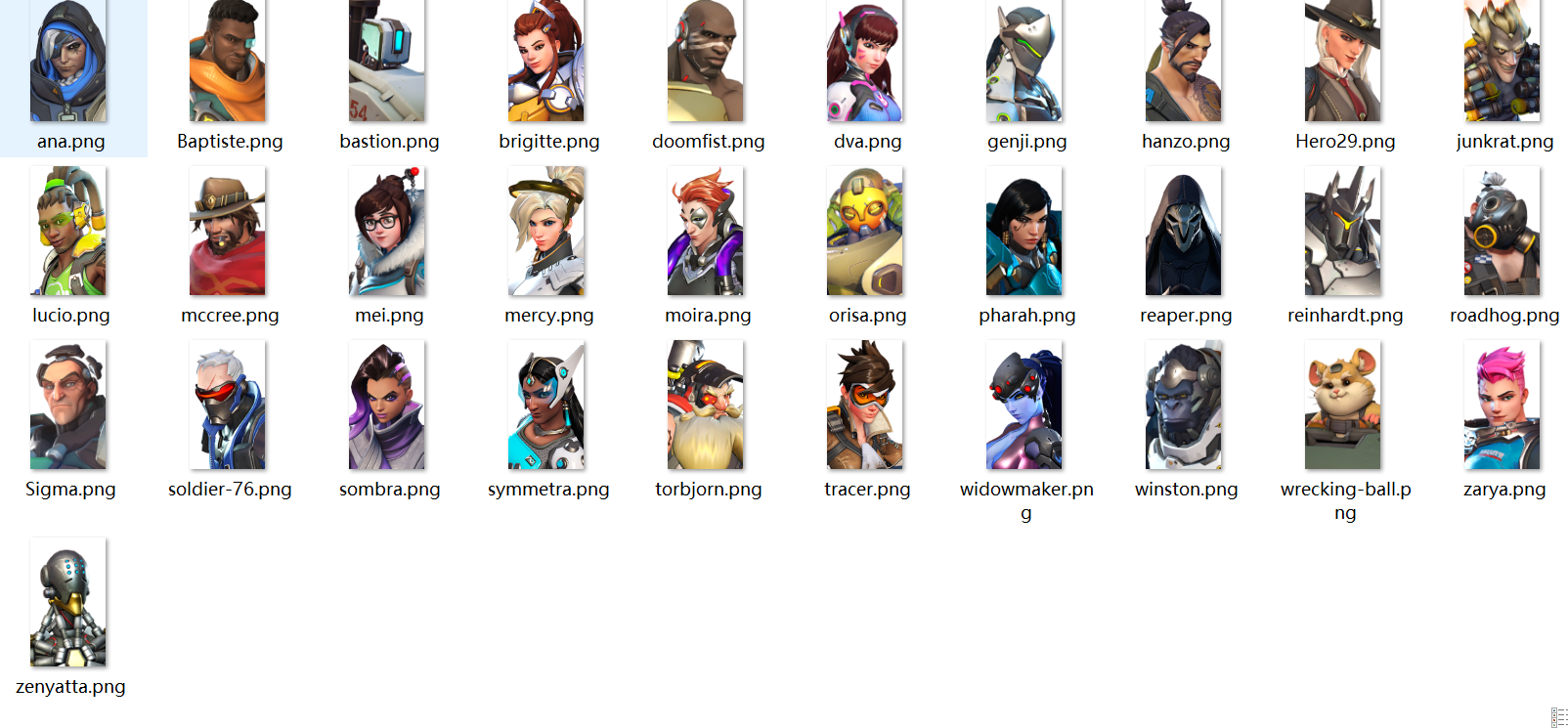
-------------------------------------------------------------------------------------------------------------------------------------
近几天学了点通过python爬取网页的知识,不得不说跟java相比起来,这方面python真的方便太多了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号