
架构设计:系统间通信(12)——RPC实例Apache Thrift 中篇
(接上文《架构设计:系统间通信(11)——RPC实例Apache Thrift 上篇》)
3、Aapche Thrift详解
在《架构设计:系统间通信(10)——RPC的基本概念》一文中,我专门介绍了一款RPC规范的具体实现中哪些要素和性能息息相关。包括了RPC通讯采用的数据封装格式、RPC通讯采用的网络IO模型和RPC所采用的请求处理方式。这个小节我们对Apache Thrift中的这三个要素,这样读者就可以知晓为什么Apache Thrift的性能如此高效了。
3-1、Aapche Thrift与消息格式
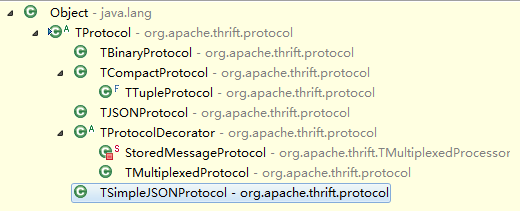
Apache Thrift支持多种消息格式封装。这些消息格式是如果进行编码和解码的是不需要使用者关心的,只需要根据自己的需要制定不同的消息封装格式即可。Apache Thrift所有消息格式封装的实现,都继承与TProtocol这个抽象类,如下图所示:

3-1-1、TBinaryProtocol
二进制流的编码格式。由于需要支持跨语言,所以Apache Thrift支持有限的几种通用类型,包括基本类型(Float、Double、Integer、Long、String、Short)、集合类型(Map、Set、List)还有Pojo类型(实际上就是前两者若干类型的组合形式)。
那么这个类所生成的二进制流和传统的java序列化后生成的二进制流有什么样的区别(或者是优势)呢?我们可以通过阅读TBinaryProtocol的源代码进行研究。
我们以TBinaryProtocol中,对Integer的序列化过程进行详细的解释,来对比java提供的其他几种序列化的方式找到不同。首先java中,如果要将一个Integer对象通过网络发送出去,要做的第一件事情就是序列化,那么我们常用的序列化方式有两种,如下所示:
- java中序列化Integer对象的第一种方法:
Integer integerObject = 10066329;
integerObject.toString().getBytes();- java中序列化Integer对象的第二种方法:
ByteArrayOutputStream aStream = new ByteArrayOutputStream();
ObjectOutputStream oStream = new ObjectOutputStream(aStream);
oStream.writeObject(integerObject);
aStream.toByteArray();第一种方式是将Integer对象中的值序列化;第二种方式,是将Integer整个对象序列化。这两种方式虽然都产生byte[],实际上性质是完全不一样的。我们来看一下这两种方式产生的byte[]的内容:
- 序列化Integer的值:
[49, 48, 48, 54, 54, 51, 50, 57]
- 序列化整个Integer对象:
[-84, -19, 0, 5, 115, 114, 0, 17, 106, 97, 118, 97, 46, 108, 97, 110, 103, 46, 73, 110, 116, 101, 103, 101, 114, 18, -30, -96, -92, -9, -127, -121, 56, 2, 0, 1, 73, 0, 5, 118, 97, 108, 117, 101, 120, 114, 0, 16, 106, 97, 118, 97, 46, 108, 97, 110, 103, 46, 78, 117, 109, 98, 101, 114, -122, -84, -107, 29, 11, -108, -32, -117, 2, 0, 0, 120, 112, 0, -103, -103, -103]
第一种方式序列化后,byte数组有8个byte元素(因为是首先转换成字符串的,所以实际上这个大小会随着Integer值的大小增加而增加);第二中方式序列化后,byte数组一共有 > 20 个byte元素,其中除了记录Integer的值以外,还包括描述这个类型的其他属性。
那么我们再来看看TBinaryProtocol中,是如何序列化Integer类型的。首先我们来看一下TBinaryProtocol进行Integer序列化的这部分源代码,如下图所示:
private byte[] i32out = new byte[4];
public void writeI32(int i32) throws TException {
i32out[0] = (byte)(0xff & (i32 >> 24));
i32out[1] = (byte)(0xff & (i32 >> 16));
i32out[2] = (byte)(0xff & (i32 >> 8));
i32out[3] = (byte)(0xff & (i32));
trans_.write(i32out, 0, 4);
}计算过程可以通过下图来表示:
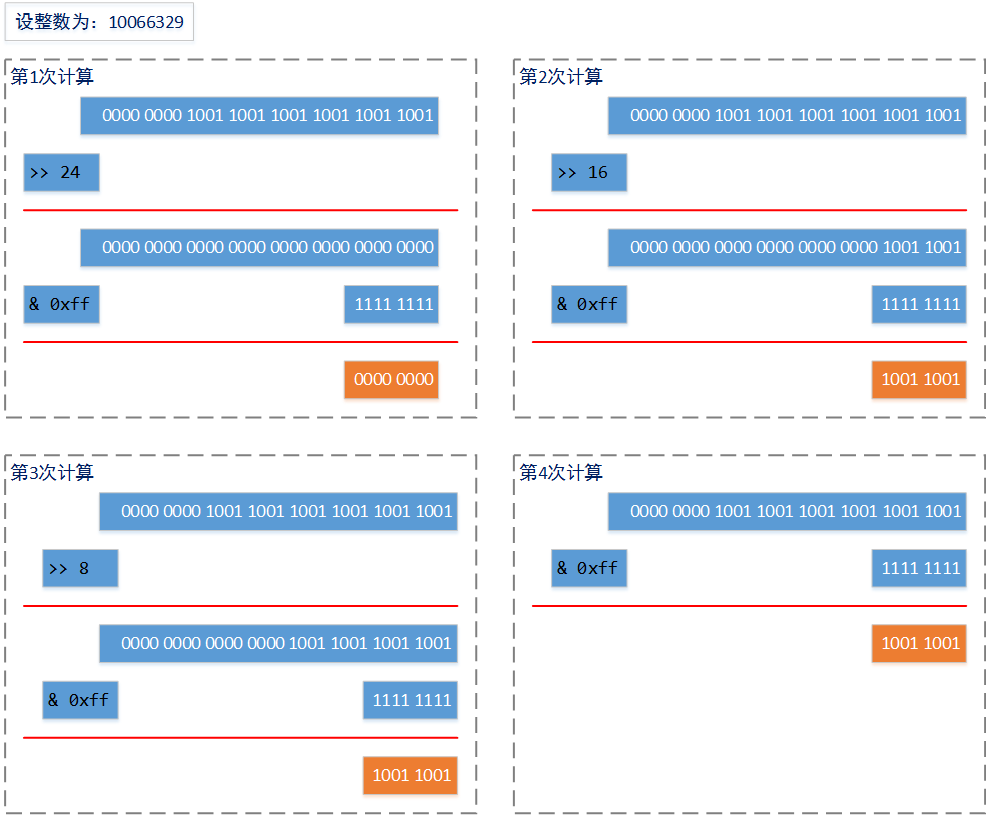
通过4次位计算,得到了一个长度为4个byte数组,并且这个数组的大小并不会随着整数大小的增加而变化。并且位运算的速度是所有计算中速度最快的一种计算。反序列化的过程相似,对这个大小为4的byte[]数组重新进行位计算即可:
((buf[off] & 0xff) << 24) |
((buf[off+1] & 0xff) << 16) |
((buf[off+2] & 0xff) << 8) |
((buf[off+3] & 0xff));由于本文的篇幅和写作目的所限,不能一一介绍TBinaryProtocol的各种序列化方式,但是通过对TBinaryProtocol中Integer的序列化过程,我们可以找到TBinaryProtocol处理过程的优势,包括速度和大小的优势。所以,如果您的使用环境对序列化过程没有特别的要求(例如后面要提到的大量的负数情况),那么直接使用TBinaryProtocol进行数据格式的封装的就可以了。
byte是一个8位二进制描述(一个字节),在java中,一个int需要4个byte进行表示,而。“0x”的前缀表示16进制数字,那么0xff的二进制表示就是 1111 1111;“&”是“与”运算符,这个运算符用于二进制计算,1 & 1 = 1,其余情况都 = 0;“<<” 表示左移运算,0011 << 2 = 1100;”>>”表示右移运算,1100 >> 2 = 0011;
3-1-2、TCompactProtocol
使用zigzag编码方式紧凑传输协议。zigzag编码的优势在于记录数字类型(整数、单精度浮点和双精度浮点),最特别的是zigzag编码对负数的记录。在计算机中,都会使用很大的数字表示负数,为了保证节约传输量,zigzag编码采用正数与负数交错的方式,把负数转换为一个正数进行记录。下面我们具体来分析一下TCompactProtocol中对32位整数的序列化方式,以下是TCompactProtocol中对32为整数的处理代码:
/**
* Write an i32 as a zigzag varint.
*/
public void writeI32(int i32) throws TException {
writeVarint32(intToZigZag(i32));
}
/**
* Convert n into a zigzag int. This allows negative numbers to be
* represented compactly as a varint.
*/
private int intToZigZag(int n) {
return (n << 1) ^ (n >> 31);
}
/**
* Write an i32 as a varint. Results in 1-5 bytes on the wire.
* TODO: make a permanent buffer like writeVarint64?
*/
byte[] i32buf = new byte[5];
private void writeVarint32(int n) throws TException {
int idx = 0;
while (true) {
if ((n & ~0x7F) == 0) {
i32buf[idx++] = (byte)n;
// writeByteDirect((byte)n);
break;
} else {
i32buf[idx++] = (byte)((n & 0x7F) | 0x80);
// writeByteDirect((byte)((n & 0x7F) | 0x80));
n >>>= 7;
}
}
trans_.write(i32buf, 0, idx);
}以上代码片段一共有一个对外的调用方法,和两个分别名为intToZigZag和writeVarint32的私有方法。从字面上的意义我们可以知道:当对一个32位整数进行编码时,首先将这个32位整数转成ZigZag编码格式,然后在序列化为“变长的32位整数”。那么这个处理的具体过程是什么样的呢?我们以一个较大的32位整数(161061273,二进制计数为:1001100110011001100110011001)为例,进行讲解:
首先将整个这个整数做成ZigZag编码格式:
然后进行“变长”处理:

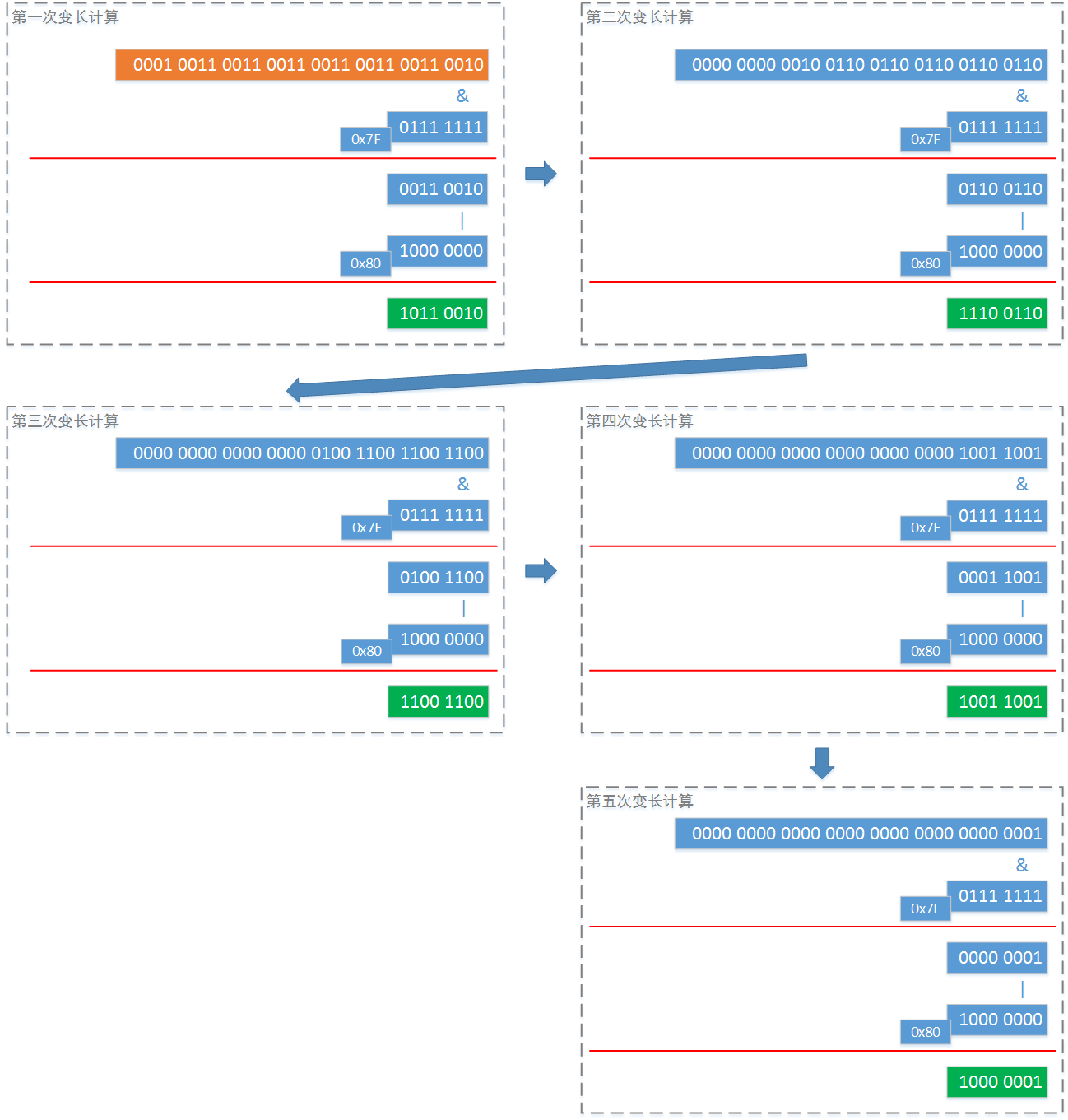
可以看到,上面的“变长”计算一共进行了5次,比TBinaryProtocol中的32位整数序列化还要多出一个byte。这是为什么呢?因为这个数字比较长。
但实际处理中,我们一般使用的数据都是比较小的。这也是为什么首先要使用ZigZag编码把某个负数的符号位从高位移动到低位的原因。实际上,在实际过程中,变长计算一般只会进行二至三次就完成。这样,在大多数情况下,完成一个32位整数的序列化,TCompactProtocol做使用的空间就比TBinaryProtocol要小。
那么经过分析,对于TCompactProtocol和TBinaryProtocol的选择的经验是:如果传输的信息中,基本都是字符串,那么使用TCompactProtocol还是使用TBinaryProtocol基本上都是差不多的;如果需要传输的信息中,会有较多的“低位数字”,那么建议使用TCompactProtocol。
3-1-3、其他传输格式封装:
当然Apache Thrift还提供其他的传输格式封装。不同的需求场景下,您可以使用根据需要选用这些信息传输格式:
3-2、Aapche Thrift与通信模型
Apache Thrift支持阻塞式同步IO通讯模型和非阻塞式异步IO通信模型。这里说明一下,我在这个系列的文章中,已经详细讲述了各种IO模型的特点和工作原理(请参见我另外几篇文章《架构设计:系统间通信(3)——IO通信模型和JAVA实践 上篇》、《架构设计:系统间通信(4)——IO通信模型和JAVA实践 中篇》、《架构设计:系统间通信(5)——IO通信模型和JAVA实践 下篇》)。所以读者您如果度过本人的拙作,那么您一定清楚,要发挥Apache Thrift性能上的优势,那么一定要在正式生产环境中采用Apache Thrift对非阻塞式异步IO通信模型的支持。下面的代码我们将向您展示Apache Thrift的这种特性:
在给出示例代码之前一定要再强调一次,Apache Thrift的服务器端和客户端一定要采用相同的通信模型。这就是说如果Apache Thrift的服务器端采用的是非阻塞异步通信模型,那么Apache Thrift客户端也一定要采用非阻塞异步通信模型,否则就无法通信。
- 服务器的非阻塞异步通信代码:
package testThrift.man;
import java.nio.channels.Selector;
import java.util.concurrent.Executors;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.log4j.BasicConfigurator;
import org.apache.thrift.TProcessor;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.server.THsHaServer;
import org.apache.thrift.transport.TNonblockingServerSocket;
import testThrift.iface.HelloWorldService;
import testThrift.iface.HelloWorldService.Iface;
import testThrift.impl.HelloWorldServiceImpl;
public class HelloNonServerDemo {
static {
BasicConfigurator.configure();
}
/**
* 日志
*/
private static Log LOGGER = LogFactory.getLog(HelloNonServerDemo.class);
public static final int SERVER_PORT = 8090;
public void startServer() {
try {
// log4j日志,如果您工程里面没有加入log4j的支持,请待用system.out
HelloNonServerDemo.LOGGER.info("HelloWorld TSimpleServer start ....");
// 服务执行控制器(告诉apache thrift,实现了HelloWorldService.Iface接口的是具体的哪一个类)
// HelloWorldServiceImpl类的代码,就不在赘述了,无论采用哪种通信模型,它的代码都不会变化
TProcessor tprocessor = new HelloWorldService.Processor<Iface>(new HelloWorldServiceImpl());
// 非阻塞异步通讯模型(服务器端)
TNonblockingServerSocket serverTransport = new TNonblockingServerSocket(HelloNonServerDemo.SERVER_PORT);
// Selector这个类,是不是很熟悉。
serverTransport.registerSelector(Selector.open());
THsHaServer.Args tArgs = new THsHaServer.Args(serverTransport);
tArgs.processor(tprocessor);
// 指定消息的封装格式(采用二进制流封装)
tArgs.protocolFactory(new TBinaryProtocol.Factory());
// 指定处理器的所使用的线程池。
tArgs.executorService(Executors.newFixedThreadPool(100));
// 启动服务
THsHaServer server = new THsHaServer(tArgs);
server.serve();
} catch (Exception e) {
HelloNonServerDemo.LOGGER.error(e);
}
}
/**
* @param args
*/
public static void main(String[] args) {
HelloNonServerDemo server = new HelloNonServerDemo();
server.startServer();
}
}- 客户端的非阻塞异步通信代码:
package testThrift.client;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.log4j.BasicConfigurator;
import org.apache.thrift.TException;
import org.apache.thrift.async.AsyncMethodCallback;
import org.apache.thrift.async.TAsyncClientManager;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.transport.TNonblockingSocket;
import testThrift.iface.HelloWorldService;
import testThrift.iface.Reponse;
import testThrift.iface.HelloWorldService.AsyncClient;
import testThrift.iface.HelloWorldService.AsyncClient.send_call;
import testThrift.iface.Request;
public class HelloNonClient {
static {
BasicConfigurator.configure();
}
/**
* 日志
*/
private static final Log LOGGER = LogFactory.getLog(HelloNonClient.class);
private static Object WAITOBJECT = new Object();
public static final void main(String[] args) throws Exception {
TNonblockingSocket transport = new TNonblockingSocket("127.0.0.1", 8090);
TAsyncClientManager clientManager = new TAsyncClientManager();
// 准备调用参数(这个testThrift.iface.Request,是我们通过IDL定义,并且生成的)
Request request = new Request("{\"param\":\"field1\"}", "\\mySerivce\\queryService");
// 这是客户端对非阻塞异步网络通信方式的支持。
// 注意使用的消息封装格式,一定要和服务器端使用的一致
HelloWorldService.AsyncClient asyncClient =
new HelloWorldService.AsyncClient.Factory(clientManager, new TBinaryProtocol.Factory()).getAsyncClient(transport);
// 既然是非阻塞异步模式,所以客户端一定是通过“事件回调”方式,接收到服务器的响应通知的
asyncClient.send(request,new AsyncMethodCallback<AsyncClient.send_call>() {
/**
* 当服务器正确响应了客户端的请求后,这个事件被触发
*/
@Override
public void onComplete(send_call call) {
Reponse response = null;
try {
response = call.getResult();
} catch (TException e) {
HelloNonClient.LOGGER.error(e);
return;
}
HelloNonClient.LOGGER.info("response = " + response);
}
/**
* 当服务器没有正确响应了客户端的请求,或者其中过程中出现了不可控制的情况。
* 那么这个事件会被触发
*/
@Override
public void onError(Exception exception) {
HelloNonClient.LOGGER.info("exception = " + exception);
}
});
//这段代码保证客户端在得到服务器回复前,应用程序本身不会终止
synchronized (HelloNonClient.WAITOBJECT) {
HelloNonClient.WAITOBJECT.wait();
}
}
}以上代码是可以直接工作的。读者可以直接在自己的工程中执行。运行的结果和Apache Thrift上一节中Apache Thrift阻塞模式下的运行结果是一致的,只是运行过程不一样。目前各种主流的RPC框架基本都支持非阻塞式异步IO网络通信,如果您有兴趣进行这些RPC框架的性能比较,一定要在相同的IO通信模型下进行。
3-3、Aapche Thrift与线程池
在之前的文章(《架构设计:系统间通信(10)——RPC的基本概念》),我们已经提到影响一款RPC框架性能的主要指标。除了RPC框架实现的数据封装格式、RPC框架支持的网络通信模型外,还有一个重要的指标就是它如何执行客户端的请求。
在Apache Thrift中,它使用线程池技术运行具体的接口实现,响应客户端请求(无论Apahce Thrift使用哪种数据封装格式、使用哪种网络通信模型)。
org.apache.thrift.server.THsHaServer.Args.executorService(ExecutorService executorService)可以看到,实际上Apache Thrift中设置线程池的方法,所要求的参数类型是java.util.concurrent.ExecutorService接口,也就是说只要实现了ExecutorService接口的类都可以被传入。一般我们常使用的是java.util.concurrent.ThreadPoolExecutor这个类。
4、下文预告
在本篇文章中,我们详细描述了Apache Thrift中和性能息息相关的三个要素:数据封装格式的实现、网络IO模型的支持 和 处理客户端请求的方式。正式有这些实现的细节,才使Apache Thrift成为一款主流的RPC框架。那么我们在正式生产环境中,应该如何使用RPC框架才科学呢?在下文中,我们将结合RPC的特点和我自己的工作经历,向各位读者进行介绍。
