


架构设计:系统存储(22)——图片服务器:详细设计(2)
(接上文《架构设计:系统存储(20)——图片服务器:需求和技术选型(2)》)
3、重要的代码片段
图片服务系统工程的示例代码放置在 http://download.csdn.net/detail/yinwenjie/9740380 这里,读者可以自行进行下载。
3-1、Nginx中的Proxy Cache配置
根据前文对图片服务系统的系统架构规划,Nginx充当了第三级缓存的作用和对图片请求服务的负载均衡作用,所以在Nginx配置文件中,至少需要对Nginx Proxy Cache功能和UpStream功能进行配置。以下为主要的Rewrite部分和负载均衡部分的配置:
......
upstream imageserver {
server 192.168.61.1:8080;
server 192.168.61.2:8080;
#建议配置健康检查部分
}
......
server {
......
location /imageQuery {
# 后续还要增加proxy cache部分的配置
# cluster loader
proxy_pass http://imageserver;
}
......
}请记得按照我们在负载均衡专题中讨论的Nginx优化细节进行其它配置信息的调整工作《架构设计:负载均衡层设计方案(2)——Nginx安装》,以下配置信息是和Proxy Cache相关的配置信息:
......
proxy_cache_path /nginxcache/imagecache levels=1:2 keys_zone=imagecache:500m inactive=300s max_size=1g;
server {
......
# 带有特效参数的
location ~* ^/image/(.*)\.(jpg|jpeg|png|gif)&(.*)$ {
# rewrite
rewrite ^/image/(.*)\.(jpg|jpeg|png|gif)&(.*)$ /imageQuery/$1.$2?special=$3 last;
}
# 不带有特效参数的
location ~* ^/image/(.*)\.(jpg|jpeg|png|gif)$ {
# rewrite
rewrite ^/image/(.*)\.(jpg|jpeg|png|gif)$ /imageQuery/$1.$2 last;
}
# 重写后的访问路径
location /imageQuery {
# proxy cache
proxy_cache imagecache;
proxy_cache_valid 200 304 300s;
proxy_cache_key $uri$query_string;
# cluster loader
proxy_pass http://imageserver;
}
......
}为了便于客户端拼凑字符串,图片服务系统向客户端提供了一个约定俗成的url地址结构,然客户端可以在原始图片的url后面使用“&”符号给出要求处理的图片特效,类似如下的结构
http://imagenginxproxy/image/20170114/e1733711-8e4d-4d9e-b230-dd22898313ef.png&zoomimage%7Cratio%3D0.9-%3Emarkimage%7CmarkValue%3Dwww.yinwenjie.net111当Nginx收到这个请求后,将会rewrite这个url到图片服务层的真实url地址,并且将请求得到的数据通过Proxy Cache进行缓存。关于upstream功能的配置和rewrite功能的配置,我们已经在负载均衡专题中进行了讲解,这里就不再赘述了。这里主要再说明一下Proxy Cache的一些基本配置(关于Proxy Cache模块的更多配置项,可参考官方文档:http://nginx.org/en/docs/http/ngx_http_proxy_module.html。):
proxy_cache_path:这个参数指定Nginx Proxy Cache的主要配置项目,其中“/nginxcache/imagecache”表示Proxy Cache存储数据的主要目录,注意这个目录必须已经存在,否则启动时会报错;levels参数指定hash结构层次,例如“levels=1:2”表示有两级hash目录结构,其中第一级目录结构有一个字符,第二级目录结构有两个字符;keys_zone参数描述了proxy cache的名称和最大可使用的内存大小,这个名称在Nginx节点中必须是唯一的,而内存大小视实际情况进行设定,例如这里设置的就是500MB;inactive参数是指当数据持续多长时间没有被后,就删除这个缓存数据,这里设置“inactive=300s”表示300秒的过期时间,注意这个过期时间不要超过Redis中数据的过期时间,否则Redis的数据缓存就不起作用了,并且这个时间需要和proxy_cache_valid的时间区分开来。max_size参数是指Proxy Cache可以使用的最大磁盘空间,例如设置成“max_size=1g”,表示最大可以使用1GB的硬盘空间,很明显这个空间在正式环境下还应该加大。
proxy_cache_valid:该参数可以为不同的HTTP响应码,设置不同的缓存时间。例如在以上的配置信息中设置了“proxy_cache_valid 200 304 300s”表示当Nginx反向代理收到的HTTP响应码为200或者304时,才进行数据缓存,缓存时间为300秒——无论这300秒的时间内是否有请求,都是缓存300秒,这个就和proxy_cache_path设置项中的inactive参数的意义就不一样了。您还可以使用多个proxy_cache_valid为不同的HTTP响应码设置不同的缓存过期时间,例如:
..... # http200 和 302的缓存时间为5分钟 proxy_cache_valid 200 302 5m; # http 404的缓存时间为4分钟 proxy_cache_valid 404 4m; ....proxy_cache_key:Nginx Proxy Cache模块缓存数据的原理,还是建立K-V的映射关系。使用这个参数可以设定Proxy Cache模块计算Key的依据。例如下面的设置,就是使用HTTP请求的URL地址(不带参数)作为Key的计算依据:
proxy_cache_key $uri但是作为图片服务的上层缓存模块来说,我们不能这样进行设置。这是因为同一张图片的不同特效要求,其URL地址都是一样的,只是参数不一样而已。否则同一张图片的不同显示效果,将会被Nginx缓存视为统一返回数据:
以下两个URL代表的特效,将会出现缓存错误 /imageQuery/20170114/e1733711-8e4d-4d9e-b230-dd22898313ef.png?special=zoomimage|ratio=0.55 /imageQuery/20170114/e1733711-8e4d-4d9e-b230-dd22898313ef.png?special=zoomimage|ratio=0.9正确的设置方式,是必须指定Proxy Cache模块在进行Key计算时,要参考URL的参数设置。所以以下设置方式才是正确的:
...... #其中$query_string,就代表URL中的参数信息 proxy_cache_key $uri$query_string; ......
3-2、责任链进行图片处理
前文我们还提到,我们将基于责任链模式以生产线的方式,进行客户端要求的特效处理过程。本小节我们对这部分主要的代码进行说明。在示例的工程中,我们已经实现了三个图片特效:图片等比例缩放操作、图片裁剪操作和字符串性质的水印操作:
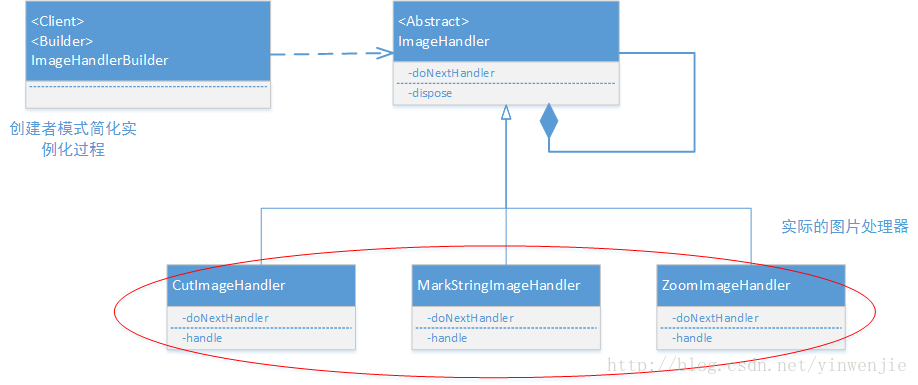
上图给出的类图中,除了前文介绍的责任链模式外还有一个创建者用来简化整个生产线的构建过程。创建者模式在很多组件中都有使用,例如Protobuf中创建对象所使用的手段就是先创建一个创建者,然后再由这个创建者进行实际对象的创建:
......
// Protobuf中的实力创建:
MessageS.Message.Builder messageBuilder = MessageS.Message.newBuilder();
// 用户名
messageBuilder.setUserName(username);
// 商品id
messageBuilder.setBusinessCode(buid);
// 等一系列其它属性值
......
// 再进行实际对象的创建
MessageS.Message messagePB = messageBuilder.build();
......以下是ImageHandler抽象类的部分定义,和ZoomImageHandler图片缩放处理器的重要代码片段:
- dispose抽象方法定义:
/**
* 这个dispose方法,就是子类需要主要实现的方式。<br>
* 如果处理过程中,不需要变更画布的尺寸,则可以在处理后将srcImage代表的画布直接返回<br>
* 如果在处理过程中,需要变更画布尺寸,则可以在实现的方法中创建一个新的画布,并进行返回
* @param srcImage 从上一个处理器传来的处理过得图片信息(画布信息)
* @return 处理完成后一定要返回一个画布。
*/
public abstract BufferedImage dispose(BufferedImage srcImage);- ZoomImageHandler缩放操作实现:
......
public BufferedImage dispose(BufferedImage srcImage) {
/*
* 处理过程为
* 1、首先确定外部输入的是按比例缩放还是按照一个高宽数值缩放
* 2、如果是按照一个高宽数值缩放,则要首先计算一个缩放比例
* 3、构建一个新的画布,并按照指定的比例或者计算出来的比例进行缩放操作
* */
int sourceWith = srcImage.getWidth();
int sourceHeight = srcImage.getHeight();
//得到合适的压缩大小,按比例。
int localDestWith,localDestHeight;
// 如果条件成立,说明是按照比例缩小
if(ratio != -1) {
localDestWith = Math.round((sourceWith * ratio));
localDestHeight = Math.round((sourceHeight * ratio));
}
// 否则是按照输入的宽、高重新计算一个比例,再进行缩小
else {
float localRatio;
// 如果发现输入的目标高宽大于图片的原始高宽,则按照ratio==1处理
if(sourceWith <= this.destWith || sourceHeight <= this.destHeight) {
localDestHeight = sourceHeight;
localDestWith = sourceWith;
}
// 按照高计算
else if(sourceWith > sourceHeight) {
localRatio = new BigDecimal(this.destHeight).divide(new BigDecimal(sourceHeight), 2, RoundingMode.HALF_UP).floatValue();
localDestHeight = (int)(sourceHeight * localRatio);
localDestWith = (int)(sourceWith * localRatio);
}
// 否则按照宽计算
else {
localRatio = new BigDecimal(this.destWith).divide(new BigDecimal(sourceWith), 2, RoundingMode.HALF_UP).floatValue();
localDestHeight = (int)(sourceHeight * localRatio);
localDestWith = (int)(sourceWith * localRatio);
}
}
// 快速缩放算法
Image destImage = srcImage.getScaledInstance(localDestWith, localDestHeight, Image.SCALE_FAST);
// RGB位深为24位,适合互联网显示
BufferedImage outputImage = new BufferedImage(localDestWith, localDestHeight, BufferedImage.TYPE_INT_RGB);
Graphics graphics = outputImage.getGraphics();
graphics.drawImage(destImage, 0, 0, null);
graphics.dispose();
// 继续进行下一个处理
BufferedImage nextResults = this.doNextHandler(outputImage);
if(nextResults == null) {
return outputImage;
}
return nextResults;
}
......3-3、Redis缓存操作
3-3-1、Redis Cluster Client对Byte[]操作
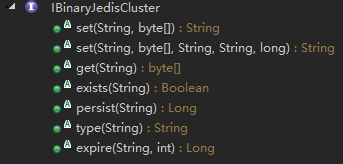
在这个示例的图片服务系统中,对于Redis的操作有两个关键点。首先Redis官方推荐的JAVA客户端实现Jedis,提供了一个redis.clients.jedis.JedisCluster类对Redis Cluster进行操作。问题是这里面只提供了针对String类型的Value进行操作,读者可以查看JedisCluster类的源代码进行验证。还好Jedis中的这部分代码不难懂,那么要满足我们图片服务系统中对byte类型的Value进行操作的要求,我们可以仿照JedisCluster类的实现自行实现一个,分别是IBinaryJedisCluster接口和BinaryJedisClusterImpl实现。这里的代码我们不需要按照JedisCluster类中实现对Redis中所有数据接口的操作,只需要实现我们系统中需要的Redis操作即可:
- 以下是IBinaryJedisCluster接口:
- 以下是BinaryJedisClusterImpl类中的部分实现代码:
......
/**
* Redis Cluster 客户端操作实现,这个类参考自JedisCluster而来<br>
* 源自JedisCluster对JedisClusterCommand的封装只能对String类型的value进行处理
* 不能对byte[]形式的value进行处理
* @author yinwenjie
*/
public class BinaryJedisClusterImpl implements IBinaryJedisCluster, Closeable {
public static final short HASHSLOTS = 16384;
private static final int DEFAULT_TIMEOUT = 2000;
private static final int DEFAULT_MAX_REDIRECTIONS = 20;
......
@Override
public String set(final String key, final byte[] value, final String nxxx, final String expx, final long time) {
return new JedisClusterCommand<String>(connectionHandler, maxRedirections) {
@Override
public String execute(Jedis connection) {
return connection.set(key.getBytes(), value, nxxx.getBytes(), expx.getBytes(), time);
}
}.run(key);
}
@Override
public byte[] get(final String key) {
return new JedisClusterCommand<byte[]>(connectionHandler, maxRedirections) {
@Override
public byte[] execute(Jedis connection) {
return connection.get(key.getBytes());
}
}.run(key);
}
......
@Override
public Boolean exists(final String key) {
return new JedisClusterCommand<Boolean>(connectionHandler, maxRedirections) {
@Override
public Boolean execute(Jedis connection) {
return connection.exists(key);
}
}.run(key);
}
......
}3-3-2、保证Key的数据在5KB以内
在前文的系统设计章节,我们还介绍到Redis对超过10KB的Value信息有较高的读写延迟,而我们存储到Redis中的图片信息又都比较大(20KB是普片现象,200KB也是可能的),在设计章节中提到的处理办法是将一个图片信息拆分为多个Value存储到Redis Cluster中的不同节点上。以下是进行Value存储时的主要代码片段:
......
@Override
public void saveCache(String imageURL, byte[] imagebytes) throws BusinessException {
/*
* 1、经过合法性验证后,处理的第一步就是判断imagebytes需要被分成几个段
* 2、然后进行byte的拆分和保存
* 3、只有所有的段都保存成功了,才进行返回(同步的,连续性的)
* */
if(StringUtils.isEmpty(imageURL) || imagebytes == null) {
throw new BusinessException("参数错误,请检查!", BusinessCode._404);
}
// 1、======确定分段
Integer maxLen = imagebytes.length;
Integer splitNum = maxLen / IImageEffectsCacheService.PERPATCH_IMAGE_SIZE;
Integer remainLen = maxLen % IImageEffectsCacheService.PERPATCH_IMAGE_SIZE;
if(remainLen != 0) {
splitNum++;
}
// 开始构造key
String key[] = new String[splitNum];
for(int index = 0 ; index < splitNum ; index++) {
key[index] = imageURL + "|" + index;
}
String lenkey = imageURL + "|size";
......
// 保存长度信息到缓存系统
binaryJedisCluster.set(lenkey, maxLen.toString().getBytes());
for(int index = 0 ; index < splitNum ; index++) {
byte[] values = null;
Integer valuesLen = null;
// 确定本次要添加的分片长度
if(index + 1 == splitNum) {
valuesLen = remainLen == 0?IImageEffectsCacheService.PERPATCH_IMAGE_SIZE:remainLen;
} else {
valuesLen = IImageEffectsCacheService.PERPATCH_IMAGE_SIZE;
}
values = new byte[valuesLen];
// 复制byte信息
// System.arraycopy是操作系统级别的复制操作,比arraybyte stream快
System.arraycopy(imagebytes, index * IImageEffectsCacheService.PERPATCH_IMAGE_SIZE, values, 0, valuesLen);
binaryJedisCluster.set(key[index], values , "NX" , "EX" , redisProperties.getKeyExpiredTime());
}
}
......有的读者指出这里可以在Redis Cluster Client部分使用线程池,同时读取多个Value部分,并通过CountDownLatch控制所有Value读取完成后再进行合并。但实际上这种读取方式在Redis Cluster节点较少的时候对于单个Client来说意义不大。主要还是因为Redis服务节点工作在单线程状态下,完全依靠操作系统的多路复用I/O模型、自身实现的事件分离器、全内存态数据存储和内部的数据结构实现来保证吞吐性能。但是随着Redis Cluster中Master节点的增多,以上所描述的Client多线程方式就有性能优势了,这是因为通过Jedis Client CRC16 Hash算法,同一个图片的不同byte段会分配到更多不同的Redis节点上进行存储,这样就能够实现同一张图片不同byte段的同时读取了。

